“ 最近这几天,李飞飞团队又把世界模型推向了巅峰,国内都流程一股世界模型热的风气,各大媒体中都可以看到世界模型的身影!然而,世界模型并不是什么全新的东西,它里面使用到的一些技术已经趋近成熟。 你有没有想象过与一个你非常钦佩的角色进行身临其境的面对面交谈?不仅通过言语对话,而且通过互动,你可以观察到它微妙的面部表情、自然的肢体语言,甚至短暂的情绪变化。在本文中,作者实现了一个端到端的社交VLA模型SOLAMI。该模型建立在仅使用解码器的LLM骨干上,将用户语音和运动的输入处理成离散表示,并生成响应的语音和运动令牌,然后将其解码为角色的语音和动作。SOLAMI使用户能够通过端到端的社会语言动作模型,在沉浸式VR环境中通过语音和肢体语言与3D自主角色进行交互。”
01-社交大模型发展历程
2024年,Zhongang Cai, Jianping Jiang等人提出“Autonomous 3d characters with social intelligence”算法。本文提出了数字生活项目,这是一个利用语言作为通用媒介来构建自主3D角色的框架,这些角色能够参与社交互动,并通过铰接的身体动作来表达,从而模拟数字环境中的生活。该框架包括两个主要组成部分:1)Socio Mind:一个精心制作的数字大脑,用系统的少镜头示例来模拟个性,结合基于心理学原理的反思过程,并通过发起对话主题来模拟自主性;2) MoMat MoGen:一种文本驱动的运动合成范式,用于控制角色的数字身体。它将运动匹配(一种经过验证的行业技术,可确保运动质量)与运动生成的尖端技术相结合,以实现多样性。
01.02-Anygpt算法简介
2024年,Jun Zhan, Junqi Dai等人提出“Anygpt: Unified multimodal LLM with discrete sequence modeling”算法。本文介绍AnyGPT,这是一种任意到任意的多模态语言模型,它利用离散表示来统一处理各种模态,包括语音、文本、图像和音乐。AnyGPT可以稳定地训练,而无需对当前的大型语言模型(LLM)架构或训练范式进行任何更改。相反,它完全依赖于数据级预处理,促进了新模式与LLM的无缝集成,类似于新语言的整合。作者构建了一个多模态文本中心数据集,用于多模态对齐预训练。实验结果表明,AnyGPT能够促进任何对任何多模态对话,同时在所有模态上实现与专用模型相当的性能,证明离散表示可以有效方便地统一语言模型中的多种模态。
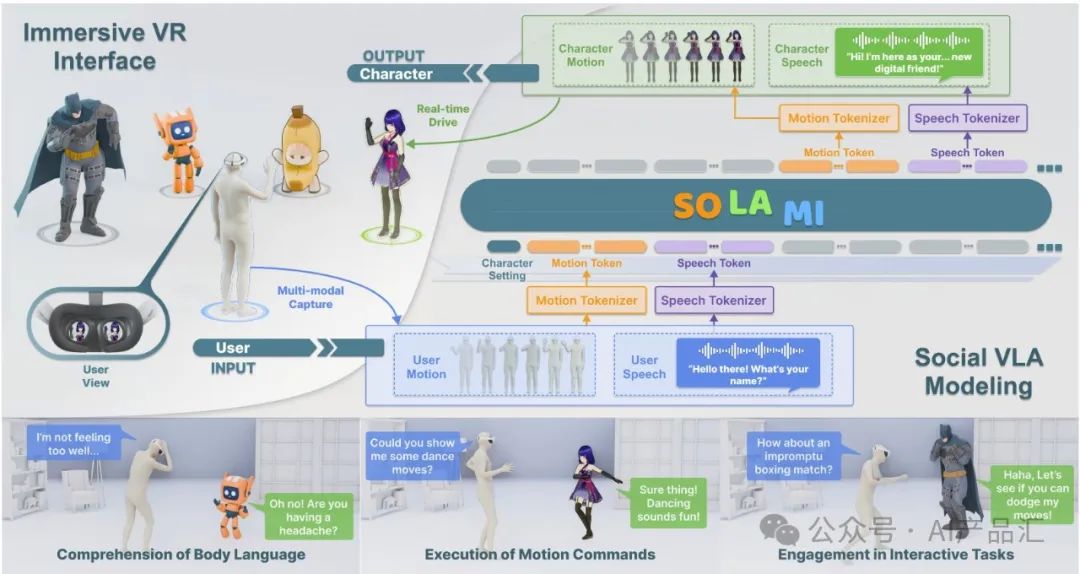
03-SOLAMI算法简介
LLM代理框架可以处理规划任务,但对于低级操作任务,基于LLM构建的端到端视觉语言动作(VLA)模型显示出卓越的性能。作者认为,数字化身本质上是具有虚拟人形化身的机器人。因此,构建一个用于与用户进行社交互动的VLA模型是一个有前景的方向。
在本文中,作者实现了一个端到端的社交VLA模型SOLAMI。该模型建立在仅使用解码器的LLM骨干上,将用户语音和运动的输入处理成离散表示,并生成响应的语音和运动令牌,然后将其解码为角色的语音和动作。这种建模方法可以有效地学习跨运动和语音模式的角色行为模式,并提供低延迟。
尽管已经有许多与人类社会行为相关的数据集,但全面的多模态交互数据集仍然很少。因此,作者引入了一种数据合成方法,该方法利用现有的文本运动数据集以低成本自动构建多模态交互数据。利用其广泛策划的主题(5.3 K)、统一处理的运动数据库(46 K)和迭代脚本细化管道,作者开发了SynMSI,这是一个包含6.3 K个多回合多模式对话项目的数据集。为了评估该方法的有效性,作者开发了一个VR界面,用户可以在其中与各种3D角色进行沉浸式交互。定量实验结果和用户研究分析表明,该方法能够以较低的延迟产生更精确、更自然的社交互动体验。
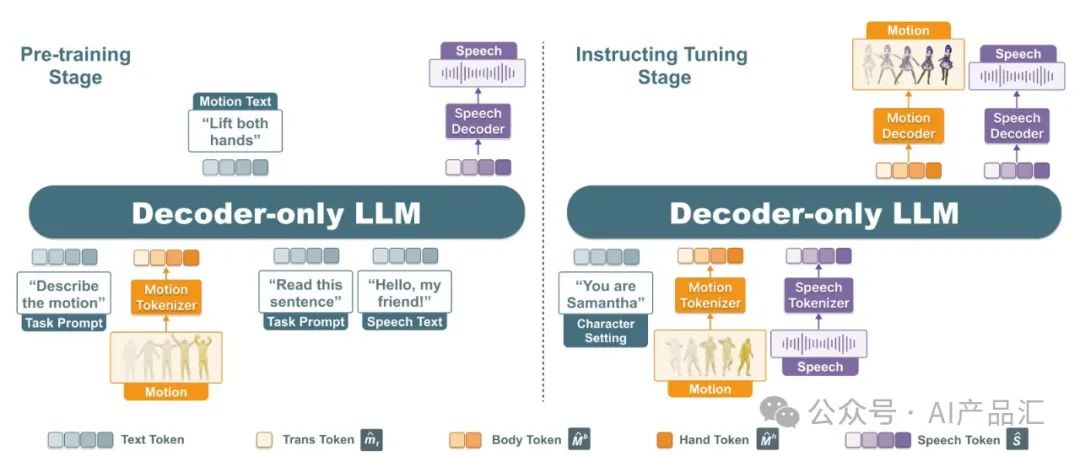
上图展示了SOLAMI算法的整体训练流程。整个训练过程包含三个阶段。
-
阶段1-训练令牌生成器。运动标记器的训练方法使用与Motiongpt相同的方法。
-
阶段2-预训练阶段,作者利用运动文本和语音文本相关任务训练模型,实现运动和文本之间以及语音和文本之间的模态对齐。这是必要的,因为运动数据稀缺,对多模态交互数据的直接训练会导致次优模型。
-
阶段3-指令调整阶段,作者使用社交多模态多轮交互数据训练该模型,使其能够生成与角色设置和主题背景相一致的多模态响应。
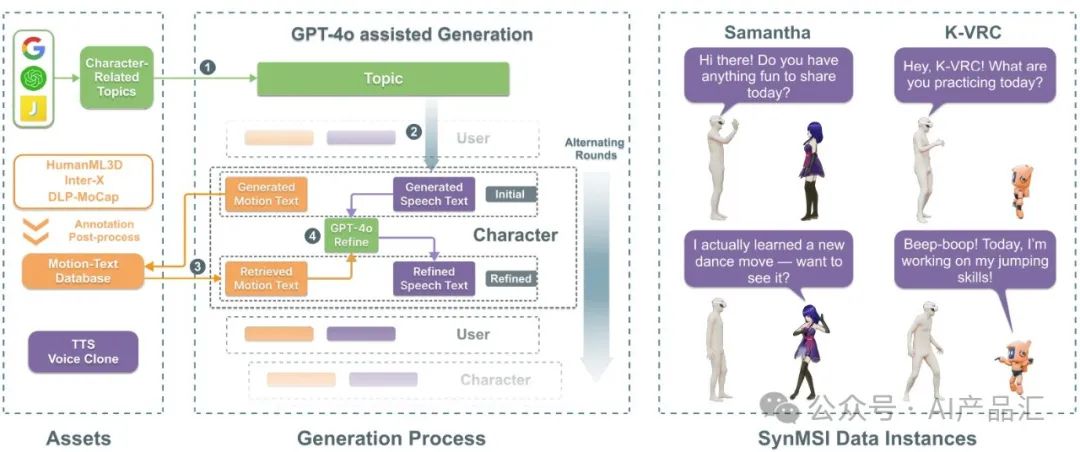

从数据来源的角度来看,作者收集的数据有三个来源:互联网视频、沉浸式VR平台和现有的不完整运动捕捉数据集。
-
从互联网视频中收集--移动设备的发展导致了视频内容的爆炸式增长,研究人员自然希望该模型能够从互联网视频中学习知识和能力。
-
从VR平台收集--构建一个VR交互平台来直接收集用户交互数据是最直接的方法。
-
从现有的不完整数据集中收集--由于该任务比较新,没有完全符合其需求的数据集。
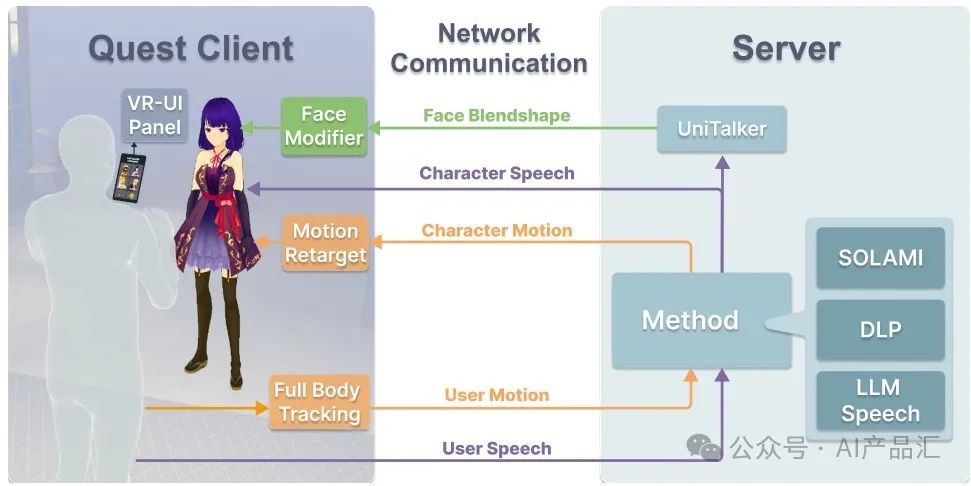
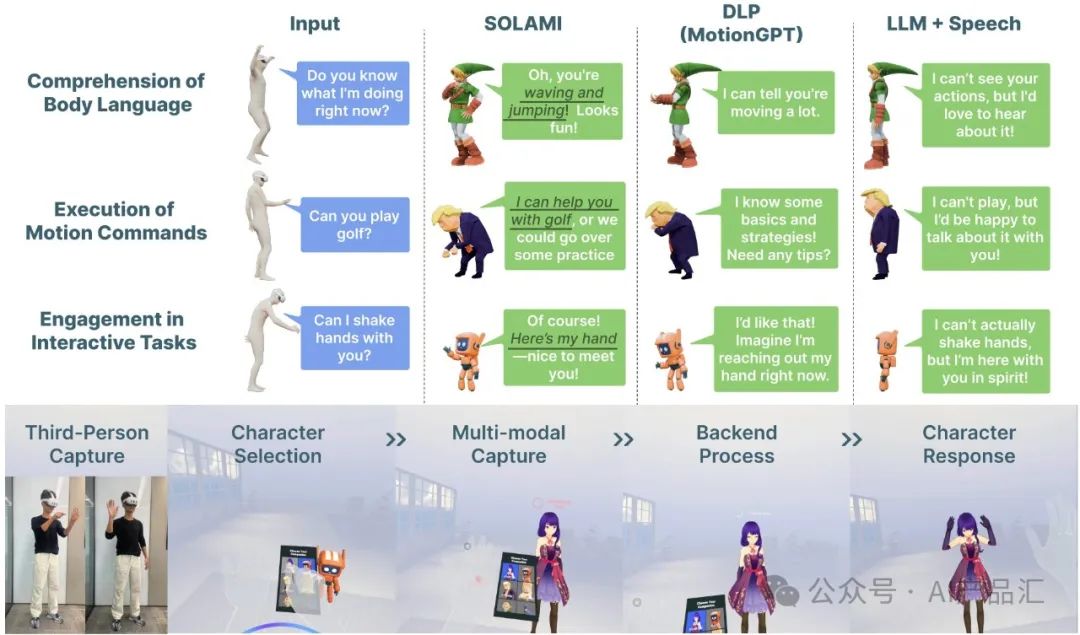
上图展示了VR接口的架构细节。该VR项目由Quest 3客户端和服务器组成。Quest客户端用来捕获用户身体运动和语音并将其传输到服务器。然后,服务器根据所选方法生成角色的语音、身体动作和面部混合形状参数。最后,将响应发送回Quest客户端用来驱动角色。

上表展示了该算法与多个SOTA的方法(LLM+Speech、AnyGPT、DLP)在SynMSI数据集上面的多项指标评估结果。通过观察与分析,我们可以发现:与其它模型相比,全参数的SOLAMI模型在多项评估指标上都获得了最佳的得分,与其它基线算法拉开了较大的差距!
利用更高效的学习方法:尽管数据集SynMSI试图收集大规模的运动数据,但人体运动固有的长尾分布导致一些行为的发生频率非常低。特别是,3D角色签名动作的数据量本身是有限的。虽然像GPT-3这样的模型已经证明了非凡的少镜头学习能力,但目前在数字人类领域所需的数据密集型训练是不可持续的。
相关文章
