❝
本文 5W字符 将剖析单代理与多代理架构的差异,详解多代理系统中的多种模式,如并行、顺序等,还会探讨代理间的通信机制。
更过agent系列文章:
1. AI 智能体,颠覆还是赋能?一文读懂!
2. 1W8000字 解锁 AI 高效运作密码:工作流与智能体如何协同?
3. 万字深度剖析 AI 代理:类型、应用及优势与局限全解析
4. 1W5000字 深度剖析大模型Agent框架
5. Agent系列 1W字用Python从零搭建AI智能体
6. 万字深度剖析 AI 代理:类型、应用及优势与局限全解析
一、引言
在人工智能领域,代理是一类借助大语言模型(LLM)来决定应用程序控制流的系统。随着开发的推进,这类系统往往会变得愈发复杂,给管理和扩展带来诸多难题。比如,你可能会遭遇以下状况:
-
工具选择困境:代理可调用的工具繁多,导致在决策下一步使用哪个工具时表现欠佳。 -
上下文管理难题:上下文信息过于繁杂,单个代理难以有效追踪和处理。 -
专业领域需求多样:系统内需要涵盖多个专业领域,像规划师、研究员、数学专家等角色。
为化解这些问题,一种有效的策略是把应用程序拆分成多个较小的独立代理,进而组合成多代理系统。这些独立代理的复杂程度差异较大,简单的可能仅涉及一个提示和一次LLM调用,复杂的则可能像ReAct代理那般(甚至更复杂!)。
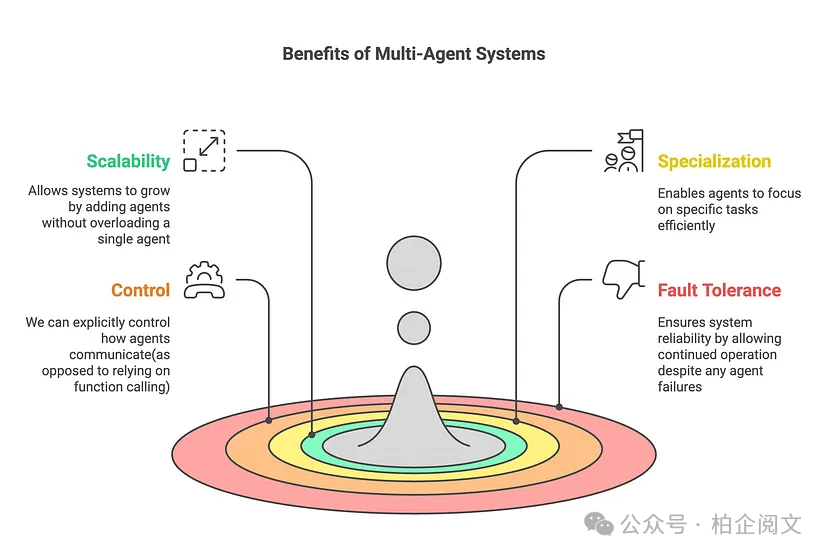
随着代理框架的蓬勃发展,众多公司纷纷构建自己的多代理系统,期望找到解决所有代理任务的通用方案。两年前,研究人员设计出一款名为ChatDev的多代理协作系统。ChatDev宛如一家虚拟软件公司,通过各类智能代理来运作,这些代理分别承担着首席执行官、首席产品官、美工、编码器、审阅者、测试人员等不同角色,与常规的软件工程公司极为相似。

所有这些代理协同作业、相互通信,成功开发出一款视频游戏。这一成果让不少人认为,任何软件工程任务都能借助这种多代理架构完成,其中每个AI都有着独特的分工。然而,实际的实验表明,并非所有问题都能靠同一架构解决。在某些情形下,更为简单的架构反而能提供更高效、成本效益更好的解决方案。
1.1 单代理与多代理架构
起初,单代理方法看似可行(即一个人工智能代理能处理从浏览器导航到文件操作等所有事务)。但随着时间推移,任务复杂度攀升,工具数量增多,单代理模式便开始面临挑战。
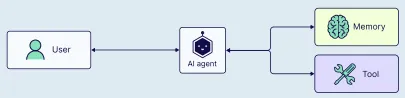
当代理出现异常行为时,我们会察觉到一些影响,这可能源于以下因素:
-
工具过载:工具数量过多,使得代理在选择工具及其使用时机时陷入困惑。 -
上下文臃肿:代理的上下文窗口不断扩大,其中包含的工具数量过多。 -
错误频发:由于职责范围过宽,代理开始产生次优甚至错误的结果。
当我们着手自动化多个不同的子任务(如数据提取、报告生成)时,或许就该考虑划分职责了。通过采用多个AI代理,每个代理专注于自身的领域和工具包,这样不仅能提升解决方案的清晰度和质量,还能简化代理的开发流程。
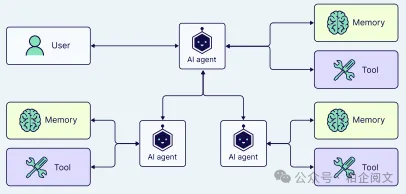
二、多智能体架构
正如您所看到的,单代理和多代理架构既有优势也有劣势。当任务简单且定义明确,并且没有特定资源限制时,单代理架构是理想之选。另一方面,当用例复杂且动态,需要更专业的知识和协作,或者具有可扩展性和适应性要求时,多代理架构则能发挥很大的作用。
2.1 多智能体系统中的模式
在多代理系统中,连接代理的方式有好几种:
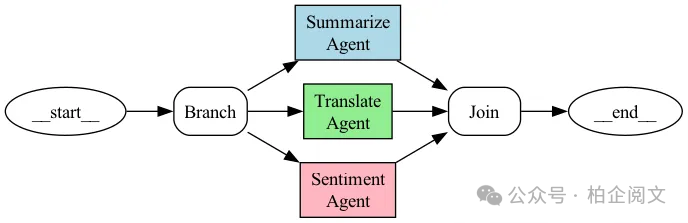
2.1.1 并行
多个代理同时处理任务的不同部分。
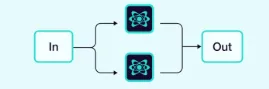
示例:我们希望使用3个代理同时对给定文本进行总结、翻译和情感分析。
代码:
from typing import Dict, Any, TypedDict
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableConfig
from textblob import TextBlob
import re
import time
class AgentState(TypedDict):
text: str
summary: str
translation: str
sentiment: str
summary_time: float
translation_time: float
sentiment_time: float
def summarize_agent(state: AgentState) -> Dict[str, Any]:
print("Summarization Agent: Running")
start_time = time.time()
try:
text = state["text"]
ifnot text.strip():
return {
"summary": "No text provided for summarization.",
"summary_time": 0.0
}
time.sleep(2)
sentences = re.split(r'(?<=[.!?]) +', text.strip())
scored_sentences = [(s, len(s.split())) for s in sentences if s]
top_sentences = [s for s, _ in sorted(scored_sentences, key=lambda x: x[1], reverse=True)[:2]]
summary = " ".join(top_sentences) if top_sentences else"Text too short to summarize."
processing_time = time.time() - start_time
print(f"Summarization Agent: Completed in {processing_time:.2f} seconds")
return {
"summary": summary,
"summary_time": processing_time
}
except Exception as e:
return {
"summary": f"Error in summarization: {str(e)}",
"summary_time": 0.0
}
def translate_agent(state: AgentState) -> Dict[str, Any]:
print("Translation Agent: Running")
start_time = time.time()
try:
text = state["text"]
ifnot text.strip():
return {
"translation": "No text provided for translation.",
"translation_time": 0.0
}
time.sleep(3)
translation = (
"El nuevo parque en la ciudad es una maravillosa adición. "
"Las familias disfrutan de los espacios abiertos, y a los niños les encanta el parque infantil. "
"Sin embargo, algunas personas piensan que el área de estacionamiento es demasiado pequeña."
)
processing_time = time.time() - start_time
print(f"Translation Agent: Completed in {processing_time:.2f} seconds")
return {
"translation": translation,
"translation_time": processing_time
}
except Exception as e:
return {
"translation": f"Error in translation: {str(e)}",
"translation_time": 0.0
}
def sentiment_agent(state: AgentState) -> Dict[str, Any]:
print("Sentiment Agent: Running")
start_time = time.time()
try:
text = state["text"]
ifnot text.strip():
return {
"sentiment": "No text provided for sentiment analysis.",
"sentiment_time": 0.0
}
time.sleep(1.5)
blob = TextBlob(text)
polarity = blob.sentiment.polarity
subjectivity = blob.sentiment.subjectivity
sentiment = "Positive"if polarity > 0else"Negative"if polarity < 0else"Neutral"
result = f"{sentiment} (Polarity: {polarity:.2f}, Subjectivity: {subjectivity:.2f})"
processing_time = time.time() - start_time
print(f"Sentiment Agent: Completed in {processing_time:.2f} seconds")
return {
"sentiment": result,
"sentiment_time": processing_time
}
except Exception as e:
return {
"sentiment": f"Error in sentiment analysis: {str(e)}",
"sentiment_time": 0.0
}
def join_parallel_results(state: AgentState) -> AgentState:
return state
def build_parallel_graph() -> StateGraph:
workflow = StateGraph(AgentState)
parallel_branches = {
"summarize_node": summarize_agent,
"translate_node": translate_agent,
"sentiment_node": sentiment_agent
}
for name, agent in parallel_branches.items():
workflow.add_node(name, agent)
workflow.add_node("branch", lambda state: state)
workflow.add_node("join", join_parallel_results)
workflow.set_entry_point("branch")
for name in parallel_branches:
workflow.add_edge("branch", name)
workflow.add_edge(name, "join")
workflow.add_edge("join", END)
return workflow.compile()
def main():
text = (
"The new park in the city is a wonderful addition. Families are enjoying the open spaces, "
"and children love the playground. However, some people think the parking area is too small."
)
initial_state: AgentState = {
"text": text,
"summary": "",
"translation": "",
"sentiment": "",
"summary_time": 0.0,
"translation_time": 0.0,
"sentiment_time": 0.0
}
print("nBuilding new graph...")
app = build_parallel_graph()
print("nStarting parallel processing...")
start_time = time.time()
config = RunnableConfig(parallel=True)
result = app.invoke(initial_state, config=config)
total_time = time.time() - start_time
print("n=== Parallel Task Results ===")
print(f"Input Text:n{text}n")
print(f"Summary:n{result['summary']}n")
print(f"Translation (Spanish):n{result['translation']}n")
print(f"Sentiment Analysis:n{result['sentiment']}n")
print("n=== Processing Times ===")
processing_times = {
"summary": result["summary_time"],
"translation": result["translation_time"],
"sentiment": result["sentiment_time"]
}
for agent, time_taken in processing_times.items():
print(f"{agent.capitalize()}: {time_taken:.2f} seconds")
print(f"nTotal Wall Clock Time: {total_time:.2f} seconds")
print(f"Sum of Individual Processing Times: {sum(processing_times.values()):.2f} seconds")
print(f"Time Saved by Parallel Processing: {sum(processing_times.values()) - total_time:.2f} seconds")
if __name__ == "__main__":
main()
输出:
Building new graph...
Starting parallel processing...
Sentiment Agent: Running
Summarization Agent: Running
Translation Agent: Running
Sentiment Agent: Completed in 1.50 seconds
Summarization Agent: Completed in 2.00 seconds
Translation Agent: Completed in 3.00 seconds
=== Parallel Task Results ===
Input Text:
The new park in the city is a wonderful addition. Families are enjoying the open spaces, and children love the playground. However, some people think the parking area is too small.
Summary:
Families are enjoying the open spaces, and children love the playground. The new park in the city is a wonderful addition.
Translation (Spanish):
El nuevo parque en la ciudad es una maravillosa adición. Las familias disfrutan de los espacios abiertos, y a los niños les encanta el parque infantil. Sin embargo, algunas personas piensan que el área de estacionamiento es demasiado pequeña.
Sentiment Analysis:
Positive (Polarity: 0.31, Subjectivity: 0.59)
=== Processing Times ===
Summary: 2.00 seconds
Translation: 3.00 seconds
Sentiment: 1.50 seconds
Total Wall Clock Time: 3.01 seconds
Sum of Individual Processing Times: 6.50 seconds
Time Saved by Parallel Processing: 3.50 seconds
并行模式特点:
-
并行性:三个任务(总结、翻译、情感分析)同时运行,减少了总处理时间。 -
独立性:每个代理独立处理输入文本,执行过程中无需代理间通信。 -
协调性:队列确保结果被安全收集并按顺序显示。 -
实际用例:总结、翻译和情感分析是常见的自然语言处理(NLP)任务,并行处理对较大文本特别有益。
2.1.2 顺序
任务按顺序依次处理,前一个代理的输出成为下一个代理的输入。
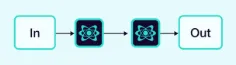
示例:多步审批流程。
代码:
from typing import Dict
from langgraph.graph import StateGraph, MessagesState, END
from langchain_core.runnables import RunnableConfig
from langchain_core.messages import HumanMessage, AIMessage
import json
def team_lead_agent(state: MessagesState, config: RunnableConfig) -> Dict:
print("Agent (Team Lead): Starting review")
messages = state["messages"]
proposal = json.loads(messages[0].content)
title = proposal.get("title", "")
amount = proposal.get("amount", 0.0)
ifnot title or amount <= 0:
status = "Rejected"
comment = "Team Lead: Proposal rejected due to missing title or invalid amount."
goto = END
else:
status = "Approved by Team Lead"
comment = "Team Lead: Proposal is complete and approved."
goto = "dept_manager"
print(f"Agent (Team Lead): Review complete - {status}")
messages.append(AIMessage(
content=json.dumps({"status": status, "comment": comment}),
additional_kwargs={"agent": "team_lead", "goto": goto}
))
return {"messages": messages}
def dept_manager_agent(state: MessagesState, config: RunnableConfig) -> Dict:
print("Agent (Department Manager): Starting review")
messages = state["messages"]
team_lead_msg = next((m for m in messages if m.additional_kwargs.get("agent") == "team_lead"), None)
proposal = json.loads(messages[0].content)
amount = proposal.get("amount", 0.0)
if json.loads(team_lead_msg.content)["status"] != "Approved by Team Lead":
status = "Rejected"
comment = "Department Manager: Skipped due to Team Lead rejection."
goto = END
elif amount > 100000:
status = "Rejected"
comment = "Department Manager: Budget exceeds limit."
goto = END
else:
status = "Approved by Department Manager"
comment = "Department Manager: Budget is within limits."
goto = "finance_director"
print(f"Agent (Department Manager): Review complete - {status}")
messages.append(AIMessage(
content=json.dumps({"status": status, "comment": comment}),
additional_kwargs={"agent": "dept_manager", "goto": goto}
))
return {"messages": messages}
def finance_director_agent(state: MessagesState, config: RunnableConfig) -> Dict:
print("Agent (Finance Director): Starting review")
messages = state["messages"]
dept_msg = next((m for m in messages if m.additional_kwargs.get("agent") == "dept_manager"), None)
proposal = json.loads(messages[0].content)
amount = proposal.get("amount", 0.0)
if json.loads(dept_msg.content)["status"] != "Approved by Department Manager":
status = "Rejected"
comment = "Finance Director: Skipped due to Dept Manager rejection."
elif amount > 50000:
status = "Rejected"
comment = "Finance Director: Insufficient budget."
else:
status = "Approved"
comment = "Finance Director: Approved and feasible."
print(f"Agent (Finance Director): Review complete - {status}")
messages.append(AIMessage(
content=json.dumps({"status": status, "comment": comment}),
additional_kwargs={"agent": "finance_director", "goto": END}
))
return {"messages": messages}
def route_step(state: MessagesState) -> str:
for msg in reversed(state["messages"]):
goto = msg.additional_kwargs.get("goto")
if goto:
print(f"Routing: Agent {msg.additional_kwargs.get('agent')} set goto to {goto}")
return goto
return END
builder = StateGraph(MessagesState)
builder.add_node("team_lead", team_lead_agent)
builder.add_node("dept_manager", dept_manager_agent)
builder.add_node("finance_director", finance_director_agent)
builder.set_entry_point("team_lead")
builder.add_conditional_edges("team_lead", route_step, {
"dept_manager": "dept_manager",
END: END
})
builder.add_conditional_edges("dept_manager", route_step, {
"finance_director": "finance_director",
END: END
})
builder.add_conditional_edges("finance_director", route_step, {
END: END
})
workflow = builder.compile()
def main():
initial_state = {
"messages": [
HumanMessage(
content=json.dumps({
"title": "New Equipment Purchase",
"amount": 40000.0,
"department": "Engineering"
})
)
]
}
result = workflow.invoke(initial_state)
messages = result["messages"]
proposal = json.loads(messages[0].content)
print("n=== Approval Results ===")
print(f"Proposal Title: {proposal['title']}")
final_status = "Unknown"
comments = []
for msg in messages[1:]:
if isinstance(msg, AIMessage):
try:
data = json.loads(msg.content)
if"status"in data:
final_status = data["status"]
if"comment"in data:
comments.append(data["comment"])
except Exception:
continue
print(f"Final Status: {final_status}")
print("Comments:")
for comment in comments:
print(f" - {comment}")
if __name__ == "__main__":
main()
输出(金额 = 40,000美元):
Agent (Team Lead): Starting review
Agent (Team Lead): Review complete - Approved by Team Lead
Routing: Agent team_lead set goto to dept_manager
Agent (Department Manager): Starting review
Agent (Department Manager): Review complete - Approved by Department Manager
Routing: Agent dept_manager set goto to finance_director
Agent (Finance Director): Starting review
Agent (Finance Director): Review complete - Approved
Routing: Agent finance_director set goto to __end__
=== Approval Results ===
Proposal Title: New Equipment Purchase
Final Status: Approved
Comments:
- Team Lead: Proposal is complete and approved.
- Department Manager: Budget is within limits.
- Finance Director: Approved and feasible.
顺序执行特点:
-
顺序执行:代理按顺序运行:团队领导 → 部门经理 → 财务总监。 -
中断机制:如果任何一个代理拒绝,循环将中断,跳过剩余代理。 -
对象修改:每个代理修改共享的提案对象,更新状态和评论。
协调方式:
-
结果存储在列表中,但提案对象在代理之间传递状态。 -
不使用多进程,确保单线程、有序的工作流程。
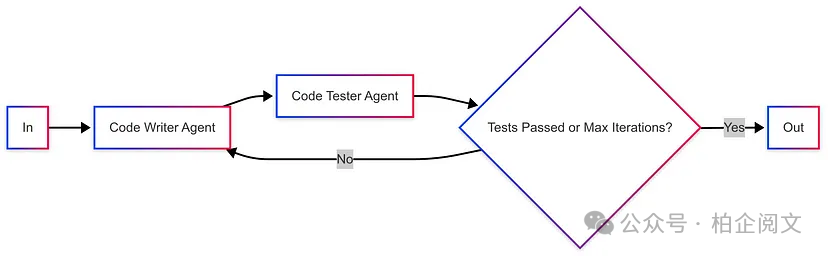
2.1.3 循环
代理以迭代循环的方式运作,基于其他代理的反馈持续改进它们的输出。
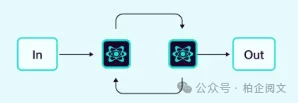
示例:评估用例,如代码编写与代码测试。
代码:
from typing import Dict, Any, List
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableConfig
import textwrap
class EvaluationState(Dict[str, Any]):
code: str = ""
feedback: str = ""
passed: bool = False
iteration: int = 0
max_iterations: int = 3
history: List[Dict] = []
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.setdefault("code", "")
self.setdefault("feedback", "")
self.setdefault("passed", False)
self.setdefault("iteration", 0)
self.setdefault("max_iterations", 3)
self.setdefault("history", [])
def code_writer_agent(state: EvaluationState, config: RunnableConfig) -> Dict[str, Any]:
print(f"Iteration {state['iteration'] + 1} - Code Writer: Generating code")
print(f"Iteration {state['iteration'] + 1} - Code Writer: Received feedback: {state['feedback']}")
iteration = state["iteration"] + 1
feedback = state["feedback"]
if iteration == 1:
code = textwrap.dedent("""
def factorial(n):
result = 1
for i in range(1, n + 1):
result *= i
return result
""")
writer_feedback = "Initial code generated."
elif"factorial(0)"in feedback.lower():
code = textwrap.dedent("""
def factorial(n):
if n == 0:
return 1
result = 1
for i in range(1, n + 1):
result *= i
return result
""")
writer_feedback = "Fixed handling for n=0."
elif"factorial(-1)"in feedback.lower() or"negative"in feedback.lower():
code = textwrap.dedent("""
def factorial(n):
if n < 0:
raise ValueError("Factorial not defined for negative numbers")
if n == 0:
return 1
result = 1
for i in range(1, n + 1):
result *= i
return result
""")
writer_feedback = "Added error handling for negative inputs."
else:
code = state["code"]
writer_feedback = "No further improvements identified."
print(f"Iteration {iteration} - Code Writer: Code generated")
return {
"code": code,
"feedback": writer_feedback,
"iteration": iteration
}
def code_tester_agent(state: EvaluationState, config: RunnableConfig) -> Dict[str, Any]:
print(f"Iteration {state['iteration']} - Code Tester: Testing code")
code = state["code"]
try:
test_cases = [
(0, 1),
(1, 1),
(5, 120),
(-1, None),
]
namespace = {}
exec(code, namespace)
factorial = namespace.get('factorial')
ifnot callable(factorial):
return {"passed": False, "feedback": "No factorial function found."}
feedback_parts = []
passed = True
for input_val, expected in test_cases:
try:
result = factorial(input_val)
if expected isNone:
passed = False
feedback_parts.append(f"Test failed: factorial({input_val}) should raise an error.")
elif result != expected:
passed = False
feedback_parts.append(f"Test failed: factorial({input_val}) returned {result}, expected {expected}.")
except ValueError as ve:
if expected isnotNone:
passed = False
feedback_parts.append(f"Test failed: factorial({input_val}) raised ValueError unexpectedly: {str(ve)}")
except Exception as e:
passed = False
feedback_parts.append(f"Test failed: factorial({input_val}) caused error: {str(e)}")
feedback = "All tests passed!"if passed else"n".join(feedback_parts)
print(f"Iteration {state['iteration']} - Code Tester: Testing complete - {'Passed' if passed else 'Failed'}")
history = state["history"]
history.append({
"iteration": state["iteration"],
"code": code,
"feedback": feedback,
"passed": passed
})
return {
"passed": passed,
"feedback": feedback,
"history": history
}
except Exception as e:
print(f"Iteration {state['iteration']} - Code Tester: Failed")
return {"passed": False, "feedback": f"Error in testing: {str(e)}"}
def should_continue(state: EvaluationState) -> str:
if state["passed"] or state["iteration"] >= state["max_iterations"]:
print(f"Iteration {state['iteration']} - {'Loop stops: Tests passed' if state['passed'] else 'Loop stops: Max iterations reached'}")
return"end"
print(f"Iteration {state['iteration']} - Loop continues: Tests failed")
return"code_writer"
workflow = StateGraph(EvaluationState)
workflow.add_node("code_writer", code_writer_agent)
workflow.add_node("code_tester", code_tester_agent)
workflow.set_entry_point("code_writer")
workflow.add_edge("code_writer", "code_tester")
workflow.add_conditional_edges(
"code_tester",
should_continue,
"code_writer": "code_writer",
"end": END
)
app = workflow.compile()
def main():
initial_state = EvaluationState()
result = app.invoke(initial_state)
print("n=== Evaluation Results ===")
print(f"Final Status: {'Passed' if result['passed'] else 'Failed'} after {result['iteration']} iteration(s)")
print(f"Final Code:n{result['code']}")
print(f"Final Feedback:n{result['feedback']}")
print("nIteration History:")
for attempt in result["history"]:
print(f"Iteration {attempt['iteration']}:")
print(f" Code:n{attempt['code']}")
print(f" Feedback: {attempt['feedback']}")
print(f" Passed: {attempt['passed']}n")
if __name__ == "__main__":
main()
输出:
Iteration 1 - Code Writer: Generating code
Iteration 1 - Code Writer: Received feedback:
Iteration 1 - Code Writer: Code generated
Iteration 1 - Code Tester: Testing code
Iteration 1 - Code Tester: Testing complete - Failed
Iteration 1 - Loop continues: Tests failed
Iteration 2 - Code Writer: Generating code
Iteration 2 - Code Writer: Received feedback: Test failed: factorial(-1) should raise an error.
Iteration 2 - Code Writer: Code generated
Iteration 2 - Code Tester: Testing code
Iteration 2 - Code Tester: Testing complete - Passed
Iteration 2 - Loop stops: Tests passed
=== Evaluation Results ===
Final Status: Passed after 2 iteration(s)
Final Code:
def factorial(n):
if n < 0:
raise ValueError("Factorial not defined for negative numbers")
if n == 0:
return 1
result = 1
for i in range(1, n + 1):
result *= i
return result
Final Feedback:
All tests passed!
Iteration History:
Iteration 1:
Code:
def factorial(n):
result = 1
for i in range(1, n + 1):
result *= i
return result
Feedback: Test failed: factorial(-1) should raise an error.
Passed: False
Iteration 2:
Code:
def factorial(n):
if n < 0:
raise ValueError("Factorial not defined for negative numbers")
if n == 0:
return 1
result = 1
for i in range(1, n + 1):
result *= i
return result
Feedback: All tests passed!
Passed: True
综合反馈:代码测试器现在会报告所有测试失败的情况,确保代码编写器拥有逐步修复问题所需的信息。
正确的反馈处理:代码编写器优先处理修复(先处理零的情况,然后是负输入的情况),确保逐步改进。
循环终止:当测试通过时,循环会正确退出,而不会不必要地运行全部3次迭代。
2.1.4 路由器
一个中央路由器根据任务或输入来决定调用哪些代理。
示例:客户支持工单路由。
代码:
from typing import Dict, Any, TypedDict, Literal
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableConfig
import re
import time
class TicketState(TypedDict):
ticket_text: str
category: str
resolution: str
processing_time: float
def router_agent(state: TicketState) -> Dict[str, Any]:
print("Router Agent: Analyzing ticket...")
start_time = time.time()
ticket_text = state["ticket_text"].lower()
if any(keyword in ticket_text for keyword in ["billing", "payment", "invoice", "charge"]):
category = "Billing"
elif any(keyword in ticket_text for keyword in ["technical", "bug", "error", "crash"]):
category = "Technical"
elif any(keyword in ticket_text for keyword in ["general", "question", "inquiry", "info"]):
category = "General"
else:
category = "Unknown"
processing_time = time.time() - start_time
print(f"Router Agent: Categorized as '{category}' in {processing_time:.2f} seconds")
return {
"category": category,
"processing_time": processing_time
}
def billing_team_agent(state: TicketState) -> Dict[str, Any]:
print("Billing Team Agent: Processing ticket...")
start_time = time.time()
ticket_text = state["ticket_text"]
resolution = f"Billing Team: Reviewed ticket '{ticket_text}'. Please check your invoice details or contact our billing department for further assistance."
processing_time = time.time() - start_time
time.sleep(1)
print(f"Billing Team Agent: Completed in {processing_time:.2f} seconds")
return {
"resolution": resolution,
"processing_time": state["processing_time"] + processing_time
}
def technical_team_agent(state: TicketState) -> Dict[str, Any]:
print("Technical Team Agent: Processing ticket...")
start_time = time.time()
ticket_text = state["ticket_text"]
resolution = f"Technical Team: Reviewed ticket '{ticket_text}'. Please try restarting your device or submit a detailed error log for further investigation."
processing_time = time.time() - start_time
time.sleep(1.5)
print(f"Technical Team Agent: Completed in {processing_time:.2f} seconds")
return {
"resolution": resolution,
"processing_time": state["processing_time"] + processing_time
}
def general_team_agent(state: TicketState) -> Dict[str, Any]:
print("General Team Agent: Processing ticket...")
start_time = time.time()
ticket_text = state["ticket_text"]
resolution = f"General Team: Reviewed ticket '{ticket_text}'. For more information, please refer to our FAQ or contact us via email."
processing_time = time.time() - start_time
time.sleep(0.8)
print(f"General Team Agent: Completed in {processing_time:.2f} seconds")
return {
"resolution": resolution,
"processing_time": state["processing_time"] + processing_time
}
def manual_review_agent(state: TicketState) -> Dict[str, Any]:
print("Manual Review Agent: Processing ticket...")
start_time = time.time()
ticket_text = state["ticket_text"]
resolution = f"Manual Review: Ticket '{ticket_text}' could not be categorized. Flagged for human review. Please assign to the appropriate team manually."
processing_time = time.time() - start_time
time.sleep(0.5)
print(f"Manual Review Agent: Completed in {processing_time:.2f} seconds")
return {
"resolution": resolution,
"processing_time": state["processing_time"] + processing_time
}
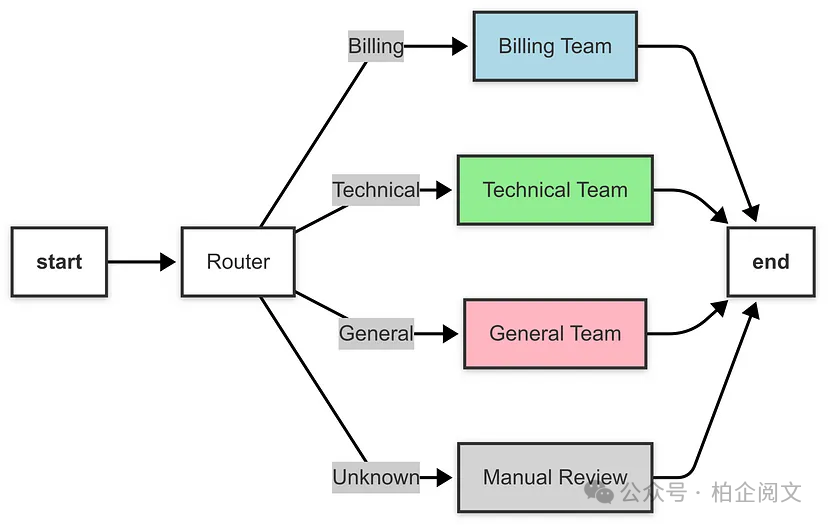
def route_ticket(state: TicketState) -> Literal["billing_team", "technical_team", "general_team", "manual_review"]:
category = state["category"]
print(f"Routing: Ticket category is '{category}'")
if category == "Billing":
return"billing_team"
elif category == "Technical":
return"technical_team"
elif category == "General":
return"general_team"
else:
return"manual_review"
def build_router_graph() -> StateGraph:
workflow = StateGraph(TicketState)
workflow.add_node("router", router_agent)
workflow.add_node("billing_team", billing_team_agent)
workflow.add_node("technical_team", technical_team_agent)
workflow.add_node("general_team", general_team_agent)
workflow.add_node("manual_review", manual_review_agent)
workflow.set_entry_point("router")
workflow.add_conditional_edges(
"router",
route_ticket,
"billing_team": "billing_team",
"technical_team": "technical_team",
"general_team": "general_team",
"manual_review": "manual_review"
)
workflow.add_edge("billing_team", END)
workflow.add_edge("technical_team", END)
workflow.add_edge("general_team", END)
workflow.add_edge("manual_review", END)
return workflow.compile()
def main():
test_tickets = [
"I have a billing issue with my last invoice. It seems I was overcharged.",
"My app keeps crashing with a technical error. Please help!",
"I have a general question about your services. Can you provide more info?",
"I need assistance with something unrelated to billing or technical issues."
]
for ticket_text in test_tickets:
initial_state: TicketState = {
"ticket_text": ticket_text,
"category": "",
"resolution": "",
"processing_time": 0.0
}
print(f"n=== Processing Ticket: '{ticket_text}' ===")
app = build_router_graph()
start_time = time.time()
result = app.invoke(initial_state, config=RunnableConfig())
total_time = time.time() - start_time
print("n=== Ticket Results ===")
print(f"Category: {result['category']}")
print(f"Resolution: {result['resolution']}")
print(f"Total Processing Time: {result['processing_time']:.2f} seconds")
print(f"Total Wall Clock Time: {total_time:.2f} seconds")
print("-" * 50)
if __name__ == "__main__":
main()
输出:
=== Processing Ticket: 'I have a billing issue with my last invoice. It seems I was overcharged.' ===
Router Agent: Analyzing ticket...
Router Agent: Categorized as 'Billing'in 0.00 seconds
Routing: Ticket category is 'Billing'
Billing Team Agent: Processing ticket...
Billing Team Agent: Completed in 0.00 seconds
=== Ticket Results ===
Category: Billing
Resolution: Billing Team: Reviewed ticket 'I have a billing issue with my last invoice. It seems I was overcharged.'. Please check your invoice details or contact our billing department for further assistance.
Total Processing Time: 0.00 seconds
Total Wall Clock Time: 1.03 seconds
--------------------------------------------------
=== Processing Ticket: 'My app keeps crashing with a technical error. Please help!' ===
Router Agent: Analyzing ticket...
Router Agent: Categorized as 'Technical'in 0.00 seconds
Routing: Ticket category is 'Technical'
Technical Team Agent: Processing ticket...
Technical Team Agent: Completed in 0.00 seconds
=== Ticket Results ===
Category: Technical
Resolution: Technical Team: Reviewed ticket 'My app keeps crashing with a technical error. Please help!'. Please try restarting your device or submit a detailed error logfor further investigation.
Total Processing Time: 0.00 seconds
Total Wall Clock Time: 1.50 seconds
--------------------------------------------------
=== Processing Ticket: 'I have a general question about your services. Can you provide more info?' ===
Router Agent: Analyzing ticket...
Router Agent: Categorized as 'General'in 0.00 seconds
Routing: Ticket category is 'General'
General Team Agent: Processing ticket...
General Team Agent: Completed in 0.00 seconds
=== Ticket Results ===
Category: General
Resolution: General Team: Reviewed ticket 'I have a general question about your services. Can you provide more info?'. For more information, please refer to our FAQ or contact us via email.
Total Processing Time: 0.00 seconds
Total Wall Clock Time: 0.80 seconds
--------------------------------------------------
=== Processing Ticket: 'I need assistance with something unrelated to billing or technical issues.' ===
Router Agent: Analyzing ticket...
Router Agent: Categorized as 'Billing'in 0.00 seconds
Routing: Ticket category is 'Billing'
Billing Team Agent: Processing ticket...
Billing Team Agent: Completed in 0.00 seconds
=== Ticket Results ===
Category: Billing
Resolution: Billing Team: Reviewed ticket 'I need assistance with something unrelated to billing or technical issues.'. Please check your invoice details or contact our billing department for further assistance.
Total Processing Time: 0.00 seconds
Total Wall Clock Time: 1.00 seconds
--------------------------------------------------
动态路由:router_agent 确定工单类别,route_ticket 函数使用 add_conditional_edges 将工作流程导向相应的节点。
基于条件的流程:与并行模式(多个节点同时运行)不同,路由器模式根据条件(类别)仅执行一条路径。
可扩展性:您可以通过扩展节点并更新 route_ticket 函数以处理新类别,来添加更多的支持团队。
2.1.5 聚合器(或合成器)
多个智能体各自贡献输出,由一个聚合智能体收集这些输出,并将其合成为最终结果。
示例:社交媒体情感分析聚合器
代码:
from typing import Dict, Any, TypedDict, List
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableConfig
from textblob import TextBlob
import time
from typing_extensions import Annotated
from operator import add
# Step 1: Define the State
class SocialMediaState(TypedDict):
twitter_posts: List[str]
instagram_posts: List[str]
reddit_posts: List[str]
twitter_sentiment: Dict[str, float]
instagram_sentiment: Dict[str, float]
reddit_sentiment: Dict[str, float]
final_report: str
processing_time: Annotated[float, add]
# Step 2: Define the Post Collection Agents
def collect_twitter_posts(state: SocialMediaState) -> Dict[str, Any]:
print("Twitter Agent: Collecting posts...")
start_time = time.time()
posts = [
"Loving the new product from this brand! Amazing quality.",
"Terrible customer service from this brand. Very disappointed."
]
time.sleep(1) # Simulate processing time
processing_time = time.time() - start_time # Include time.sleep in processing_time
print(f"Twitter Agent: Completed in {processing_time:.2f} seconds")
return {
"twitter_posts": posts,
"processing_time": processing_time
}
def collect_instagram_posts(state: SocialMediaState) -> Dict[str, Any]:
print("Instagram Agent: Collecting posts...")
start_time = time.time()
posts = [
"Beautiful design by this brand! #loveit",
"Not impressed with the latest release. Expected better."
]
time.sleep(1.2) # Simulate processing time
processing_time = time.time() - start_time
print(f"Instagram Agent: Completed in {processing_time:.2f} seconds")
return {
"instagram_posts": posts,
"processing_time": processing_time
}
def collect_reddit_posts(state: SocialMediaState) -> Dict[str, Any]:
print("Reddit Agent: Collecting posts...")
start_time = time.time()
posts = [
"This brand is awesome! Great value for money.",
"Had a bad experience with their support team. Not happy."
]
time.sleep(0.8) # Simulate processing time
processing_time = time.time() - start_time
print(f"Reddit Agent: Completed in {processing_time:.2f} seconds")
return {
"reddit_posts": posts,
"processing_time": processing_time
}
# Step 3: Define the Sentiment Analysis Agents
def analyze_twitter_sentiment(state: SocialMediaState) -> Dict[str, Any]:
print("Twitter Sentiment Agent: Analyzing sentiment...")
start_time = time.time()
posts = state["twitter_posts"]
polarities = [TextBlob(post).sentiment.polarity for post in posts]
avg_polarity = sum(polarities) / len(polarities) if polarities else0.0
time.sleep(0.5) # Simulate processing time
processing_time = time.time() - start_time
print(f"Twitter Sentiment Agent: Completed in {processing_time:.2f} seconds")
return {
"twitter_sentiment": {"average_polarity": avg_polarity, "num_posts": len(posts)},
"processing_time": processing_time
}
def analyze_instagram_sentiment(state: SocialMediaState) -> Dict[str, Any]:
print("Instagram Sentiment Agent: Analyzing sentiment...")
start_time = time.time()
posts = state["instagram_posts"]
polarities = [TextBlob(post).sentiment.polarity for post in posts]
avg_polarity = sum(polarities) / len(polarities) if polarities else0.0
time.sleep(0.6) # Simulate processing time
processing_time = time.time() - start_time
print(f"Instagram Sentiment Agent: Completed in {processing_time:.2f} seconds")
return {
"instagram_sentiment": {"average_polarity": avg_polarity, "num_posts": len(posts)},
"processing_time": processing_time
}
def analyze_reddit_sentiment(state: SocialMediaState) -> Dict[str, Any]:
print("Reddit Sentiment Agent: Analyzing sentiment...")
start_time = time.time()
posts = state["reddit_posts"]
polarities = [TextBlob(post).sentiment.polarity for post in posts]
avg_polarity = sum(polarities) / len(polarities) if polarities else0.0
time.sleep(0.4) # Simulate processing time
processing_time = time.time() - start_time
print(f"Reddit Sentiment Agent: Completed in {processing_time:.2f} seconds")
return {
"reddit_sentiment": {"average_polarity": avg_polarity, "num_posts": len(posts)},
"processing_time": processing_time
}
# Step 4: Define the Aggregator Agent
def aggregate_results(state: SocialMediaState) -> Dict[str, Any]:
print("Aggregator Agent: Generating final report...")
start_time = time.time()
twitter_sentiment = state["twitter_sentiment"]
instagram_sentiment = state["instagram_sentiment"]
reddit_sentiment = state["reddit_sentiment"]
total_posts = (twitter_sentiment["num_posts"] +
instagram_sentiment["num_posts"] +
reddit_sentiment["num_posts"])
weighted_polarity = (
twitter_sentiment["average_polarity"] * twitter_sentiment["num_posts"] +
instagram_sentiment["average_polarity"] * instagram_sentiment["num_posts"] +
reddit_sentiment["average_polarity"] * reddit_sentiment["num_posts"]
) / total_posts if total_posts > 0else0.0
overall_sentiment = ("Positive"if weighted_polarity > 0else
"Negative"if weighted_polarity < 0else"Neutral")
report = (
f"Overall Sentiment: {overall_sentiment} (Average Polarity: {weighted_polarity:.2f})n"
f"Twitter Sentiment: {twitter_sentiment['average_polarity']:.2f} (Posts: {twitter_sentiment['num_posts']})n"
f"Instagram Sentiment: {instagram_sentiment['average_polarity']:.2f} (Posts: {instagram_sentiment['num_posts']})n"
f"Reddit Sentiment: {reddit_sentiment['average_polarity']:.2f} (Posts: {reddit_sentiment['num_posts']})"
)
time.sleep(0.3) # Simulate processing time
processing_time = time.time() - start_time
print(f"Aggregator Agent: Completed in {processing_time:.2f} seconds")
return {
"final_report": report,
"processing_time": processing_time
}
# Step 5: Build the Graph with an Aggregator Pattern
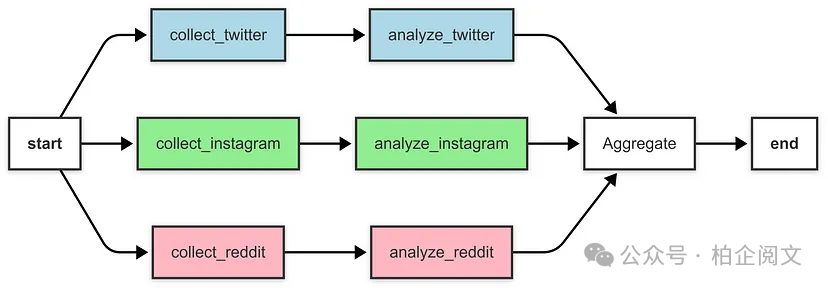
def build_aggregator_graph() -> StateGraph:
workflow = StateGraph(SocialMediaState)
# Add nodes for collecting posts
workflow.add_node("collect_twitter", collect_twitter_posts)
workflow.add_node("collect_instagram", collect_instagram_posts)
workflow.add_node("collect_reddit", collect_reddit_posts)
# Add nodes for sentiment analysis
workflow.add_node("analyze_twitter", analyze_twitter_sentiment)
workflow.add_node("analyze_instagram", analyze_instagram_sentiment)
workflow.add_node("analyze_reddit", analyze_reddit_sentiment)
# Add node for aggregation
workflow.add_node("aggregate", aggregate_results)
# Add a branching node to trigger all collection nodes in parallel
workflow.add_node("branch", lambda state: state)
# Set the entry point to the branch node
workflow.set_entry_point("branch")
# Add edges from branch to collection nodes (parallel execution)
workflow.add_edge("branch", "collect_twitter")
workflow.add_edge("branch", "collect_instagram")
workflow.add_edge("branch", "collect_reddit")
# Add edges from collection to sentiment analysis
workflow.add_edge("collect_twitter", "analyze_twitter")
workflow.add_edge("collect_instagram", "analyze_instagram")
workflow.add_edge("collect_reddit", "analyze_reddit")
# Add edges from sentiment analysis to aggregator
workflow.add_edge("analyze_twitter", "aggregate")
workflow.add_edge("analyze_instagram", "aggregate")
workflow.add_edge("analyze_reddit", "aggregate")
# Add edge from aggregator to END
workflow.add_edge("aggregate", END)
return workflow.compile()
# Step 6: Run the Workflow
def main():
initial_state: SocialMediaState = {
"twitter_posts": [],
"instagram_posts": [],
"reddit_posts": [],
"twitter_sentiment": {"average_polarity": 0.0, "num_posts": 0},
"instagram_sentiment": {"average_polarity": 0.0, "num_posts": 0},
"reddit_sentiment": {"average_polarity": 0.0, "num_posts": 0},
"final_report": "",
"processing_time": 0.0
}
print("nStarting social media sentiment analysis...")
app = build_aggregator_graph()
start_time = time.time()
config = RunnableConfig(parallel=True)
result = app.invoke(initial_state, config=config)
total_time = time.time() - start_time
print("n=== Sentiment Analysis Results ===")
print(result["final_report"])
print(f"nTotal Processing Time: {result['processing_time']:.2f} seconds")
print(f"Total Wall Clock Time: {total_time:.2f} seconds")
if __name__ == "__main__":
main()
输出:
Starting social media sentiment analysis...
Instagram Agent: Collecting posts...
Reddit Agent: Collecting posts...
Twitter Agent: Collecting posts...
Reddit Agent: Completed in 0.80 seconds
Twitter Agent: Completed in 1.00 seconds
Instagram Agent: Completed in 1.20 seconds
Instagram Sentiment Agent: Analyzing sentiment...
Reddit Sentiment Agent: Analyzing sentiment...
Twitter Sentiment Agent: Analyzing sentiment...
Reddit Sentiment Agent: Completed in 0.40 seconds
Twitter Sentiment Agent: Completed in 0.50 seconds
Instagram Sentiment Agent: Completed in 0.60 seconds
Aggregator Agent: Generating final report...
Aggregator Agent: Completed in 0.30 seconds
=== Sentiment Analysis Results ===
Overall Sentiment: Positive (Average Polarity: 0.15)
Twitter Sentiment: -0.27 (Posts: 2)
Instagram Sentiment: 0.55 (Posts: 2)
Reddit Sentiment: 0.18 (Posts: 2)
Total Processing Time: 4.80 seconds
Total Wall Clock Time: 2.13 seconds
并行执行
收集和分析节点并行运行,与各个处理时间的总和(3.8秒)相比,总耗时(2.1秒)有所减少。
聚合
聚合节点将情感分析结果整合到最终报告中,计算整体情感倾向,并按平台进行细分。
2.1.6 网络(或横向)架构
智能体之间以多对多的方式直接通信,形成一个去中心化的网络。
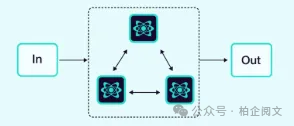
这种架构适用于不存在明确智能体层级关系,或对智能体调用顺序没有特定要求的问题场景。
from typing import Literal
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START, END
model = ChatOpenAI()
def agent_1(state: MessagesState) -> Command[Literal["agent_2", "agent_3", END]]:
response = model.invoke(...)
return Command(
goto=response["next_agent"],
update={"messages": [response["content"]]}
)
def agent_2(state: MessagesState) -> Command[Literal["agent_1", "agent_3", END]]:
response = model.invoke(...)
return Command(
goto=response["next_agent"],
update={"messages": [response["content"]]}
)
def agent_3(state: MessagesState) -> Command[Literal["agent_1", "agent_2", END]]:
...
return Command(
goto=response["next_agent"],
update={"messages": [response["content"]]}
)
builder = StateGraph(MessagesState)
builder.add_node(agent_1)
builder.add_node(agent_2)
builder.add_node(agent_3)
builder.add_edge(START, "agent_1")
network = builder.compile()
优点:支持分布式协作和群体驱动的决策模式。即使部分智能体出现故障,系统仍能保持运行。
缺点:管理智能体之间的通信颇具挑战。频繁的通信可能导致效率降低,还可能出现智能体重复工作的情况。
2.1.7 交接
在多智能体架构中,智能体可被视作图的节点。每个智能体节点执行自身步骤,并决定是结束执行流程,还是路由到其他智能体,甚至有可能路由回自身(比如在循环中运行)。在多智能体交互里,一种常见的模式是交接,即一个智能体将控制权转交给另一个智能体。交接过程中,你能够指定:
-
目的地:要导航至的目标智能体(比如,要前往的节点名称) -
有效负载:传递给该智能体的信息(例如,状态更新)
在LangGraph中实现交接功能时,智能体节点可以返回Command对象,通过它能同时实现控制流和状态更新:
def agent(state) -> Command[Literal["agent", "another_agent"]]:
goto = get_next_agent(...)
return Command(
goto=goto,
update={"my_state_key": "my_state_value"}
)
在更为复杂的场景中,每个智能体节点自身就是一个图(即子图),某个智能体子图中的节点可能需要导航到不同的智能体。例如,你有两个智能体alice和bob(属于父图中的子图节点),如果alice需要导航到bob,那么可以在Command对象中设置graph=Command.PARENT:
def some_node_inside_alice(state):
return Command(
goto="bob",
update={"my_state_key": "my_state_value"},
graph=Command.PARENT
)
注意如果你需要支持使用Command(graph=Command.PARENT)进行通信的子图的可视化,就需要用带有Command注释的节点函数来包装它们。例如,不要直接这样写:
builder.add_node(alice)
而是需要这样做:
def call_alice(state) -> Command[Literal["bob"]]:
return alice.invoke(state)
builder.add_node("alice", call_alice)
交接作为工具
最常见的智能体类型之一是ReAct风格的工具调用智能体。对于这类智能体而言,一种常见的模式是将交接操作包装在工具调用中,例如:
def transfer_to_bob(state):
"""Transfer to bob."""
return Command(
goto="bob",
update={"my_state_key": "my_state_value"},
graph=Command.PARENT
)
这是通过工具更新图状态的一种特殊情况,除了进行状态更新外,还涵盖了控制流的变更。
重要提示
如果你想使用返回Command的工具,可以选择使用预构建的create_react_agent/ToolNode组件,或者自行实现一个工具执行节点,该节点负责收集工具返回的Command对象,并返回这些对象的列表。例如:
def call_tools(state):
...
commands = [tools_by_name[tool_call["name"]].invoke(tool_call) for tool_call in tool_calls]
return commands
现在,让我们进一步深入了解不同的多智能体架构。
2.1.8 监督者模式
在这种架构中,我们将各个智能体定义为节点,并添加一个监督者节点(由大语言模型构成),它负责决定接下来应该调用哪些智能体节点。我们依据监督者的决策,使用Command将执行过程路由到合适的智能体节点。这种架构也很适合并行运行多个智能体,或者采用映射 - 归约(map-reduce)模式。
from typing import Literal
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START, END
model = ChatOpenAI()
def supervisor(state: MessagesState) -> Command[Literal["agent_1", "agent_2", END]]:
response = model.invoke(...)
return Command(goto=response["next_agent"])
def agent_1(state: MessagesState) -> Command[Literal["supervisor"]]:
response = model.invoke(...)
return Command(
goto="supervisor",
update={"messages": [response]}
)
def agent_2(state: MessagesState) -> Command[Literal["supervisor"]]:
response = model.invoke(...)
return Command(
goto="supervisor",
update={"messages": [response]}
)
builder = StateGraph(MessagesState)
builder.add_node(supervisor)
builder.add_node(agent_1)
builder.add_node(agent_2)
builder.add_edge(START, "supervisor")
supervisor = builder.compile()
2.1.9 监督者(工具调用)模式
在这种监督者架构的变体中,我们将单个智能体定义为工具,并在监督者节点中使用一个调用工具的大语言模型。这可以被实现为一个具有两个节点的ReAct风格的智能体——一个大语言模型节点(监督者)和一个执行工具(在这种情况下即智能体)的工具调用节点。
from typing import Annotated
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import InjectedState, create_react_agent
model = ChatOpenAI()
def agent_1(state: Annotated[dict, InjectedState]):
response = model.invoke(...)
return response.content
def agent_2(state: Annotated[dict, InjectedState]):
response = model.invoke(...)
return response.content
tools = [agent_1, agent_2]
supervisor = create_react_agent(model, tools)
2.1.10 分层(或垂直)架构
智能体按照树状结构进行组织,较高级别的智能体(监督智能体)负责管理较低级别的智能体。
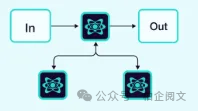
随着你向系统中添加越来越多的智能体,监督智能体管理所有这些智能体可能会变得极为困难。监督智能体可能会在决定下一步调用哪个智能体时做出欠佳决策,而且对于单个监督智能体来说,上下文可能会变得过于复杂而难以追踪。换句话说,最终你会面临最初促使采用多智能体架构的那些相同问题。
为解决这一问题,你可以对系统进行分层设计。例如,你可以创建由不同监督智能体管理的独立、专门的智能体团队,再设置一个顶级监督智能体来管理这些团队。
from typing import Literal
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.types import Command
model = ChatOpenAI()
def team_1_supervisor(state: MessagesState) -> Command[Literal["team_1_agent_1", "team_1_agent_2", END]]:
response = model.invoke(...)
return Command(goto=response["next_agent"])
def team_1_agent_1(state: MessagesState) -> Command[Literal["team_1_supervisor"]]:
response = model.invoke(...)
return Command(goto="team_1_supervisor", update={"messages": [response]})
def team_1_agent_2(state: MessagesState) -> Command[Literal["team_1_supervisor"]]:
response = model.invoke(...)
return Command(goto="team_1_supervisor", update={"messages": [response]})
team_1_builder = StateGraph(Team1State)
team_1_builder.add_node(team_1_supervisor)
team_1_builder.add_node(team_1_agent_1)
team_1_builder.add_node(team_1_agent_2)
team_1_builder.add_edge(START, "team_1_supervisor")
team_1_graph = team_1_builder.compile()
class Team2State(MessagesState):
next: Literal["team_2_agent_1", "team_2_agent_2", "__end__"]
def team_2_supervisor(state: Team2State):
...
def team_2_agent_1(state: Team2State):
...
def team_2_agent_2(state: Team2State):
...
team_2_builder = StateGraph(Team2State)
...
team_2_graph = team_2_builder.compile()
builder = StateGraph(MessagesState)
def top_level_supervisor(state: MessagesState) -> Command[Literal["team_1_graph", "team_2_graph", END]]:
response = model.invoke(...)
return Command(goto=response["next_team"])
builder = StateGraph(MessagesState)
builder.add_node(top_level_supervisor)
builder.add_node("team_1_graph", team_1_graph)
builder.add_node("team_2_graph", team_2_graph)
builder.add_edge(START, "top_level_supervisor")
builder.add_edge("team_1_graph", "top_level_supervisor")
builder.add_edge("team_2_graph", "top_level_supervisor")
graph = builder.compile()
优点:不同层级的智能体之间,角色和职责划分明确。通信流程得到简化,适合具有结构化决策流的大型系统。
缺点:上层智能体出现故障可能会扰乱整个系统的运行。下层智能体的独立性较为有限。
2.1.11 自定义多智能体工作流程
每个智能体仅与部分智能体进行通信。工作流的部分环节是确定的,只有部分智能体能够决定接下来调用哪些其他智能体。
在这种架构中,我们把单个智能体作为图节点添加进来,并在自定义工作流中提前定义好智能体的调用顺序。在LangGraph中,工作流有两种定义方式:
-
显式控制流(普通边):LangGraph支持你通过普通图边,清晰明确地定义应用程序的控制流(即智能体之间的通信顺序)。这是上述架构中最具确定性的一种变体——我们总能提前知晓下一个被调用的智能体是哪个。 -
动态控制流(Command):在LangGraph里,你可以让大语言模型(LLM)参与决定应用程序控制流的部分环节。这可以通过使用 Command来实现。主管工具调用架构就是一个典型例子,在这种情况下,为主管智能体提供支持的工具调用LLM会对工具(即智能体)的调用顺序做出决策。
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START
model = ChatOpenAI()
def agent_1(state: MessagesState):
response = model.invoke(...)
return {"messages": [response]}
def agent_2(state: MessagesState):
response = model.invoke(...)
return {"messages": [response]}
builder = StateGraph(MessagesState)
builder.add_node(agent_1)
builder.add_node(agent_2)
builder.add_edge(START, "agent_1")
builder.add_edge("agent_1", "agent_2")
3. 智能体之间的通信
构建多智能体系统时,最重要的是确定智能体之间的通信方式。这涉及到几个不同的考量因素:
-
智能体是通过图状态进行通信,还是通过工具调用进行通信? -
如果两个智能体的状态模式不同,该如何处理? -
如何通过共享消息列表进行通信?
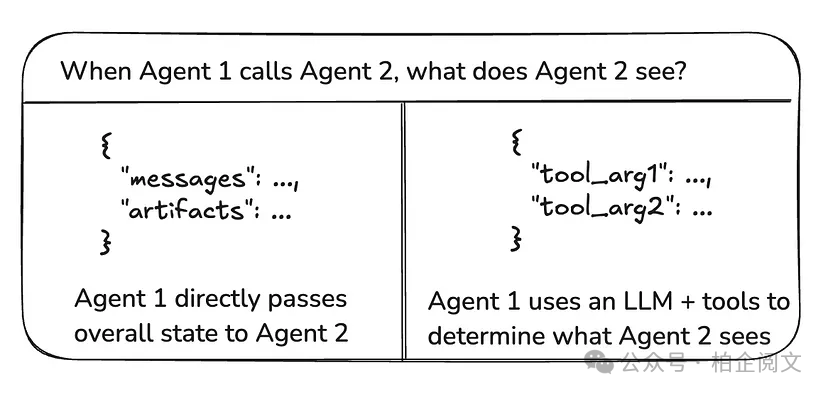
3.1 图状态与工具调用
在智能体之间传递的 “有效载荷” 是什么呢?在上述讨论的大多数架构中,智能体是通过图状态进行通信的。而在主管工具调用架构中,有效载荷则是工具调用的参数。
-
图状态:要通过图状态进行通信,需要将单个智能体定义为图节点。这些节点既可以作为函数添加,也可以作为完整的子图添加。在图执行的每一步,智能体节点接收图的当前状态,执行智能体代码,然后将更新后的状态传递给下一个节点。通常情况下,智能体节点共享单一的状态模式。不过,你可能也希望设计具有不同状态模式的智能体节点。
3.2 不同的状态模式
某个智能体可能需要与其他智能体拥有不同的状态模式。比如,搜索智能体可能只需要跟踪查询内容和检索到的文档。在LangGraph中,有两种方式可以实现这一点:
-
定义具有独立状态模式的子图智能体。如果子图和父图之间没有共享的状态键(通道),添加输入/输出转换至关重要,这样父图才能知道如何与子图进行通信。 -
定义具有私有输入状态模式的智能体节点函数,该模式与整体图状态模式不同。这使得仅在执行特定智能体时所需的信息得以传递。
3.3 共享消息列表
智能体之间最常见的通信方式是通过共享状态通道,通常是一个消息列表。这基于一个前提,即状态中始终至少存在一个被所有智能体共享的通道(键)。当通过共享消息列表进行通信时,还有一个额外的考量因素:智能体应该共享其完整的思考过程,还是仅共享最终结果呢?
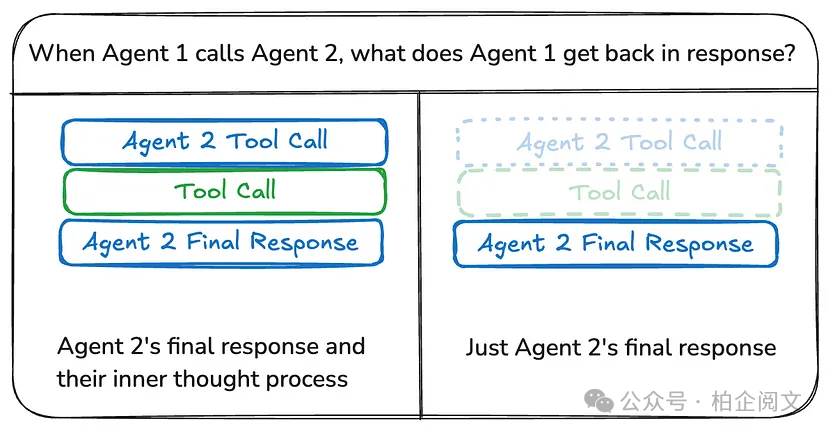
共享完整思考过程
智能体可以与其他所有智能体共享其完整的思考过程(即 “便签本”),这个 “便签本” 通常呈现为一个消息列表的形式。共享完整思考过程的好处在于,它有助于其他智能体做出更优决策,进而提升整个系统的推理能力。然而,其弊端是,随着智能体数量的增多以及复杂性的增加,“便签本” 的规模会迅速膨胀,这可能需要额外的内存管理策略来应对。
共享最终结果
智能体可以拥有自己的私有 “便签本”,仅将最终结果与其他智能体共享。这种方式对于包含大量智能体或智能体较为复杂的系统可能更为适用。在这种情况下,你需要定义具有不同状态模式的智能体。
对于作为工具被调用的智能体,主管会依据工具模式来确定其输入。此外,LangGraph允许在运行时将状态传递给各个工具,因此,如果有需要,从属智能体可以访问父状态。
4. 结论
正如本文所探讨的,多智能体大语言模型(LLM)系统通过利用诸如并行、顺序、路由和聚合器工作流等多样化的架构模式,为处理复杂任务提供了强大的范例。
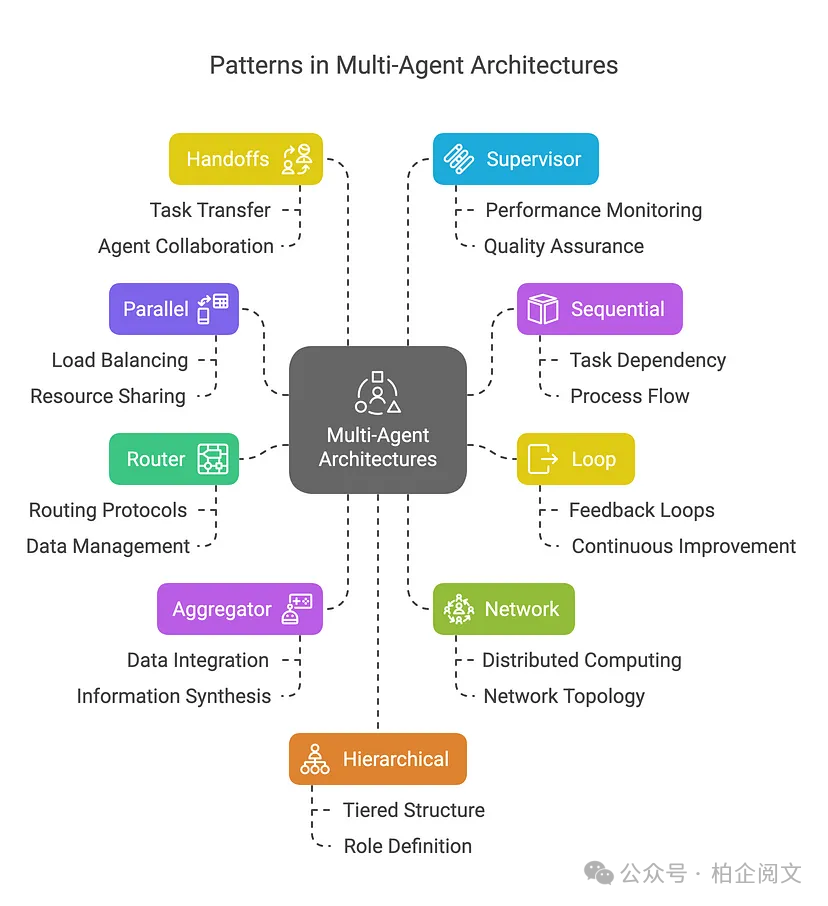
通过对共享状态、消息列表和工具调用等通信机制的详细研究,我们了解到智能体是如何协作以实现无缝协调的。
推荐阅读
1. DeepSeek-R1的顿悟时刻是如何出现的? 背后的数学原理
2. 微调 DeepSeek LLM:使用监督微调(SFT)与 Hugging Face 数据
3. 使用 DeepSeek-R1 等推理模型将 RAG 转换为 RAT
4. DeepSeek R1:了解GRPO和多阶段训练
5. 深度探索:DeepSeek-R1 如何从零开始训练
6. DeepSeek 发布 Janus Pro 7B 多模态模型,免费又强大!
相关文章
