
token和概念之间的关系就类似于语义与语词。
想象一个外国人在学习中文,他可能记住了每个字的读音和意思,但却无法理解“山雨欲来风满楼”这样的诗句。因为理解这句诗不仅需要认识每个字,更需要理解“山雨”、“风”与“危机感”这些概念之间的联系。
而原来通过token学习的AI就只能通过学习都不是完整表意字的token间的联系,去预测下一个token。
而这也是很多人工智能专家都不相信这种基于token的AI真正能够理解这个世界的原因。
比如Meta的另一位研究员,日内瓦大学教授Francois Fleuret也认为OpenAI现在选择的COT之路,不过是一种“对真东西(人类思维)的劣化的模仿”。


让大模型直接学概念
(SONAR的基本运作逻辑)
有了这个概念层抽象,关键问题是如何设计一个能够处理概念的模型架构。研究团队详细探索了三种方案:用更容易理解的方式表达就是:
鉴于前两种方法的劣势太明显,Meta最终采用了第三种方法:Diffusion双塔架构。这个架构包含两个主要组件:左边的塔和Basic LCM的结构一样,就像一个写文章框架的人,力求概念准确。另一座塔(Diffsuion去噪器)就像是一个编辑,负责润色和丰富用词。
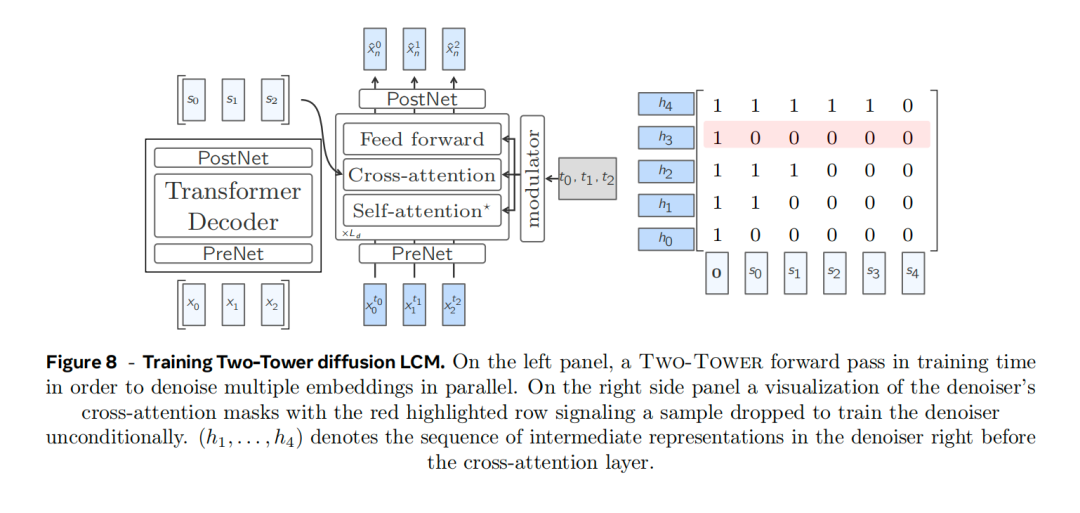 (Diffusion双塔结构示意)
(Diffusion双塔结构示意)
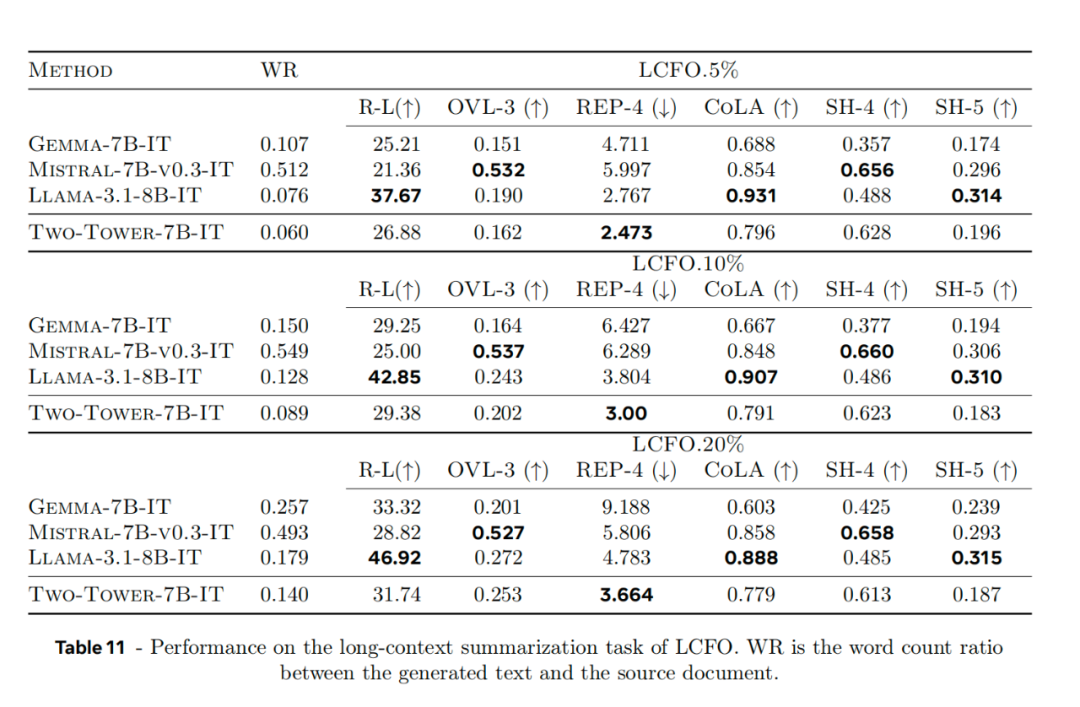
而且从推理成本和速度角度看,LCM也有很大优势。相比于同样大小的Llama 2 7B模型,LCM的推理速度大概是它的3、4倍,而成本仅为其一半。
不止LCM,Meta全方位发力潜空间
这主要是因为动态 patch 能更好地利用计算量,准确细腻的还原字节间的关系。另外, patch 比 token 本身也更容易扩展,避免了静态token词表的限制。
因为这一项研究的潜力看起来相当大,知名AI研究者Chubby评论说,2025年也许会因此成为Tokenization终结之年。
Cocunut:用想法代替语句去做推理
而在这之前,12月9日,田渊栋带领的团队则试图通过改变潜空间的表达,加强模型的推理能力。
他们采用的是另外一种路径:避免了强制将中间推理过程转换成具体的语言token,而是直接用推理状态(Meta团队称为“想法”)在潜空间里展开思维链推理。
这一方法同样是放弃了token,只不过是限制在思维链这个场景中。
在这个叫Coconut的思维链中,Meta的研究员直接利用最后一个隐藏状态(即“想法”)作为下一个输入嵌入。整个推理过程是连续可微的,可以通过梯度下降来优化。
这就像是让模型在"想法"的空间中直接推理,而不是必须把每一步都转换成具体的语言来表达。
它的逻辑训练方式也一样相对特殊,在前几步训练时,它还是采用一般思维链的方式训练,用话语和token作为要素训练模型,在之后他们逐渐加多“想法”的占比,直到最后完全用“想法”取代token形成的语句。
这一方法有效提高了大语言模型的推理能力,在部分测试项目上甚至高于传统的CoT。
相关文章
