点击上方“海边的拾遗者”,选择“星标”公众号
第一时间获取价值内容

01
第一部分 衡量文本向量表示效果的榜单:MTEB、C-MTEB
1.1 《MTEB: Massive Text Embedding Benchmark(海量文本嵌入基准)》
01
第一部分 衡量文本向量表示效果的榜单:MTEB、C-MTEB
-
论文地址:https://arxiv.org/abs/2210.07316 MTEB包含8个语义向量任务,涵盖58个数据集和112种语言。通过在MTEB上对33个模型进行基准测试,建立了迄今为止最全面的文本嵌入基准。我们发现没有特定的文本嵌入方法在所有任务中都占主导地位。这表明该领域尚未集中在一个通用的文本嵌入方法上,并将其扩展到足以在所有嵌入任务上提供最先进的结果 -
github地址:https://github.com/embeddings-benchmark/mteb#leaderboard 
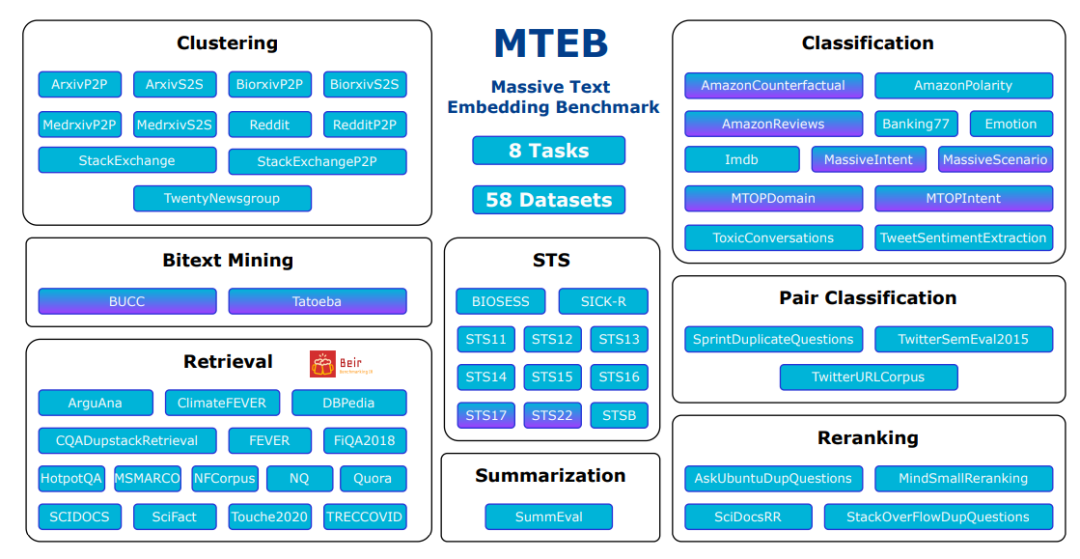
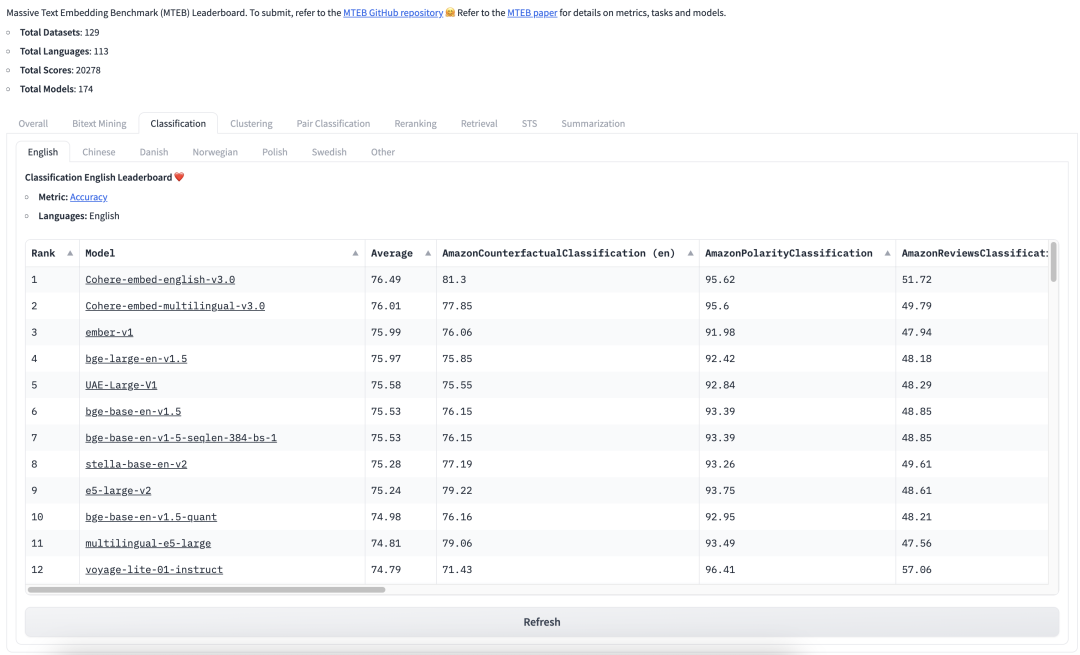
1.2 中文海量文本embedding任务排行榜:C-MTEB
任务榜单包括:
-
Retrieval -
STS -
PairClassification -
Classification -
Reranking -
Clustering
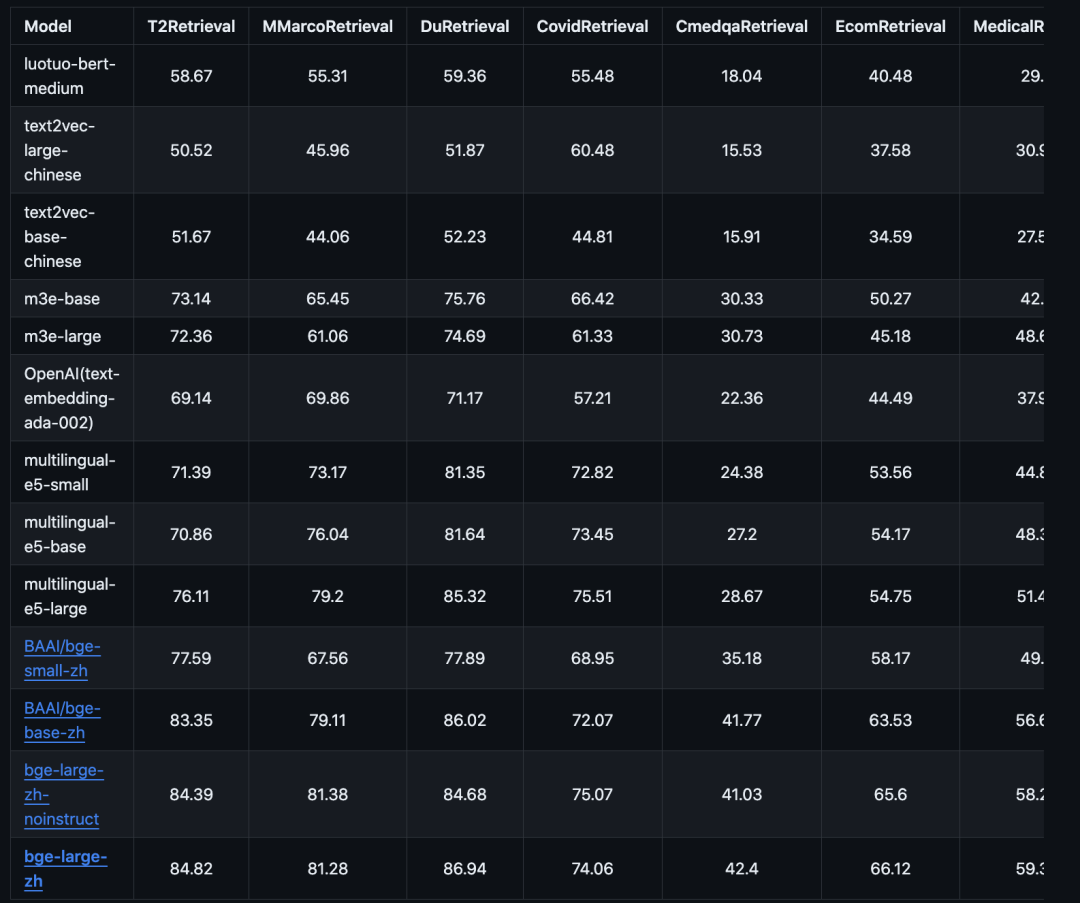
02
2.1 text-embedding-ada-002
2.1.1 模型简介
text-embedding-ada-002是OpenAI于2022年12月提供的一个embedding模型,但需要调用接口付费使用。其具有如下特点:
-
统一能力:OpenAI通过将五个独立的模型(文本相似性、文本搜索-查询、文本搜索-文档、代码搜索-文本和代码搜索-代码)合并为一个新的模型 在一系列不同的文本搜索、句子相似性和代码搜索基准中,这个单一的表述比以前的嵌入模型表现得更好 -
上下文:上下文长度为8192,使得它在处理长文档时更加方便 -
嵌入尺寸:只有1536个维度,是davinci-001嵌入尺寸的八分之一,使新的嵌入在处理矢量数据库时更具成本效益
2.1.2 模型使用
以下是OpenAI官方文档中给出的用于文本搜索的代码实例
from openai.embeddings_utils import get_embedding, cosine_similaritydef search_reviews(df, product_description, n=3, pprint=True):embedding = get_embedding(product_description, model='text-embedding-ada-002')df['similarities'] = df.ada_embedding.apply(lambda x: cosine_similarity(x, embedding))res = df.sort_values('similarities', ascending=False).head(n)return resres = search_reviews(df, 'delicious beans', n=3)
2.3.1 OpenAI三大嵌入模型的嵌入维度对比
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
例如在 MTEB 基准上,text-embedding-3-large 可以缩短为 256 的大小, 同时性能仍然优于未缩短的 text-embedding-ada-002 嵌入(大小为 1536) -
当然,仍然可以使用最好的嵌入模型 text-embedding-3-large 并指定 dimensions API 参数的值为 1024,使得嵌入维数从 3072 开始缩短,牺牲一些准确度以换取更小的向量大小
2.3.2 Matryoshka Representation Learning
,考虑一组表示尺寸,对于输入数据中的数据点,其的目标是学习一个维表示向量,对于每一个,MRL的目标是让前维的表征向量独立地成为可转移的通用表征向量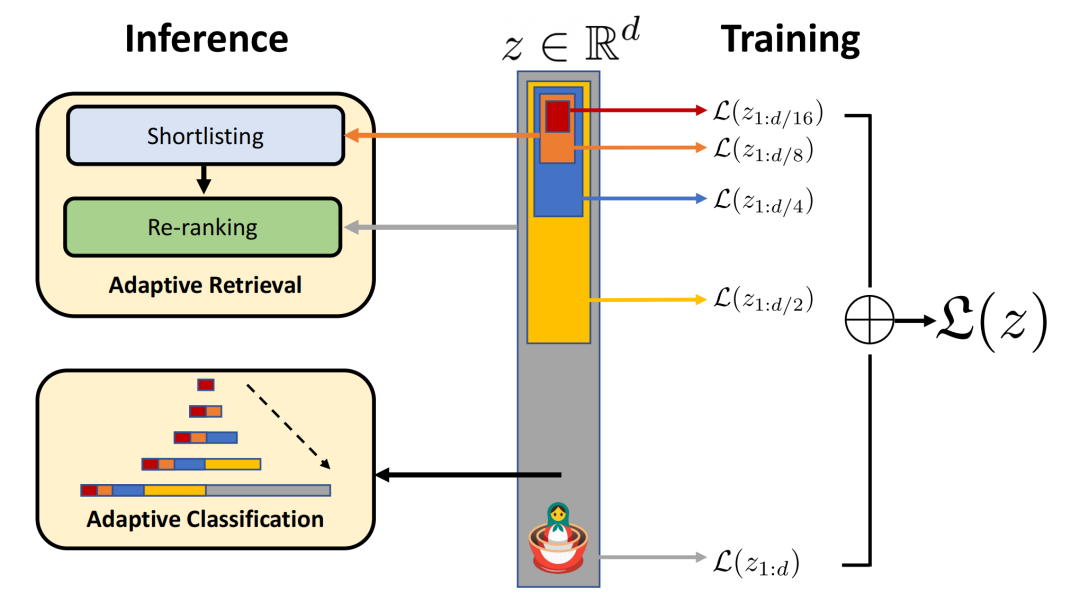 个标签中进行预测
个标签中进行预测-
对于MRL,选择 作为嵌套维度 假设得到了一个带标签的数据集,其中是输入点,是所有中的标签 -
MRL采用标准的经验风险最小化方法,通过使用独立的线性分类器对每个嵌套维度 进行多类分类损失优化,参数化为 之后,所有损失分别按各自的重要性进行适当缩放后,做最终聚合MRL optimizes the multi-class classification loss for each of the nested dimension m ∈M using standard empirical risk minimization using a separatelinear classifier, parameterized by W(m) ∈RL×m .All the losses are aggregated after scaling withtheir relative importance (cm ≥0)m∈M respectively 尽管只对
嵌套维度进行优化,MRL仍能产生精确的表示,并对介于所选表示粒度之间的维度进行插值

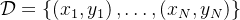
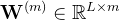
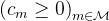
03
第三部分 m3e模型
03
第三部分 m3e模型
3.1 m3e模型简介
-
Moka,表示模型由MokaAI训练,开源和评测,训练脚本使用uniem ,评测BenchMark使用 MTEB-zh
-
Massive,表示此模型通过千万级(2200w+)的中文句对数据集进行训练
-
Mixed,表示此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索
其有多个版本,分为m3e-small、m3e-base、m3e-large,m3e GitHub地址:GitHub - wangyingdong/m3e-base,其
-
使用in-batch负采样的对比学习的方式在句对数据集进行训练,为了保证in-batch负采样的效果,使用A100来最大化batch-size,并在共计2200W+的句对数据集(包含中文百科,金融,医疗,法律,新闻,学术等多个领域)上训练了 1 epoch
-
使用了指令数据集,M3E 使用了300W+的指令微调数据集,这使得 M3E 对文本编码的时候可以遵从指令,这部分的工作主要被启发于 instructor-embedding
-
基础模型,M3E 使用 Roberta 系列模型进行训练,目前提供 small 和 base 两个版本 此文《知识库问答LangChain+LLM的二次开发:商用时的典型问题及其改进方案》中的langchain-chatchat便默认用的m3e-base
3.1.1 m3e与openai text-embedding-ada-002
以下是m3e的一些重大更新
-
2023.06.08,添加检索任务的评测结果,在 T2Ranking 1W 中文数据集上,m3e-base 在 ndcg@10 上达到了 0.8004,超过了 openai-ada-002 的 0.7786 见下图s2p ndcg@10那一列(其中s2p, 即 sentence to passage ,代表了异质文本之间的嵌入能力,适用任务:文本检索,GPT 记忆模块等)
2023.06.07,添加文本分类任务的评测结果,在 6 种文本分类数据集上,m3e-base 在 accuracy 上达到了 0.6157(至于m3e-large则是0.6231),超过了 openai-ada-002 的 0.5956 见下图s2s ACC那一列(其中s2s, 即 sentence to sentence ,代表了同质文本之间的嵌入能力,适用任务:文本相似度,重复问题检测,文本分类等)
此外,m3e团队建议
-
如果使用场景主要是中文,少量英文的情况,建议使用 m3e 系列的模型
-
多语言使用场景,并且不介意数据隐私的话,作者团队建议使用 openai text-embedding-ada-002
-
代码检索场景,推荐使用 openai text-embedding-ada-002
-
文本检索场景,请使用具备文本检索能力的模型,只在 S2S 上训练的文本嵌入模型,没有办法完成文本检索任务
3.2 m3e模型微调
from datasets import load_datasetfrom uniem.finetuner import FineTunerdataset = load_dataset('shibing624/nli_zh', 'STS-B')# 指定训练的模型为 m3e-smallfinetuner = FineTuner.from_pretrained('moka-ai/m3e-small', dataset=dataset)finetuner.run(epochs=3)
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“海边的拾遗者”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心。
投稿或交流学习,备注:昵称-学校(公司)-方向,目前群人数过多,只能通过助手拉入技术交流群。
记得备注呦
方向有很多:面试内推、机器学习、深度学习,python,推荐算法,广告算法,搜索算法,多模态,大模型等。
推荐两个专辑给大家:
专辑 | 机器学习算法原理及实现
专辑 | 面试心得及经验分享
来都来了,喜欢的话就请分享、点赞、爱心三连再走吧~~~
转载请注明:一文了解Text Embedding模型:从text2vec、openai-text embedding到m3e、bge(上) | AI工具大全&导航
相关文章
