
点击蓝字 关注我们

在金融领域,大模型的 “聪明程度” 直接关乎风险控制、合规审查等核心场景的落地效果。
但面对复杂的财务报表计算、监管规则匹配,甚至客服对话中的合规性检测,传统大模型常常 “卡壳”—— 要么算错数,要么漏掉关键规则,更有人工智能团队为了提升准确性,不得不依赖多轮对话的 “代理接力”,导致效率大打折扣。
有没有一种方法,能让大模型既 “算得准” 又 “想得全”,还能 “一步到位” 解决复杂推理?
阿里通义点金团队最新研究成果 DianJin-R1 给出了答案:通过定制化数据集、结构化推理训练和强化学习优化,其单轮推理性能在真实金融场景中超越了需要多次调用的多代理系统,为金融 AI 落地打开了新想象空间。
【论文链接】https://arxiv.org/pdf/2504.15716v1
源码见文末
摘要
在金融领域,有效的推理仍然是LLMs面临的核心挑战,该领域的任务通常需要特定领域的知识、精确的数值计算以及严格遵守合规规则。
背景
LLMs的发展引发了人们对提升其推理能力的兴趣,已有研究表明对推理过程进行显式建模可提升复杂任务的性能。
贡献
-
构建高质量推理数据集点金R1 Data,结合多个数据源并通过验证确保数据质量,为模型训练提供支持。
-
提出基于Qwen2.5系列模型微调的点金R17B和点金R132B模型,并使用结构化输出格式生成推理过程和答案。
-
应用GRPO算法,通过双重奖励信号进一步提升模型推理质量。
点金R1数据架构
4.1 数据来源
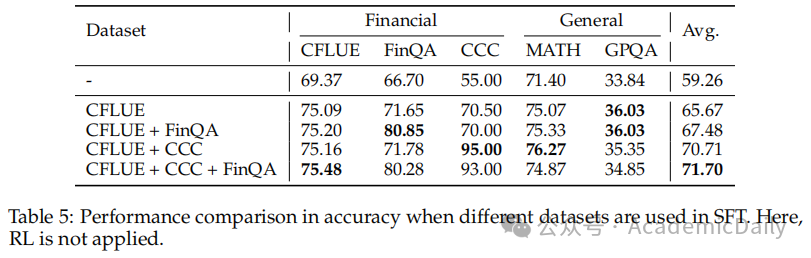
CFLUE:一个开源中文金融领域基准数据集,通过长度、难度和歧义性三步过滤,选取高质量选择题,许多题配有详细解释,作为有价值的推理注释。
FinQA:开源英文基准数据集,包含需对财务报告进行数值推理的问答对,经过与CFLUE相同的长度和难度过滤,得到高质量子集。
CCC:内部数据集,用于检测中国金融客服对话中的合规违规情况,数据来自实际客服操作的在线质检系统,经过人工审核确保标注准确,采样保证合规和违规案例分布大致平衡。
4.2 推理数据集构建
CFLUE问题推理生成:将CFLUE选择题转换为开放式问题。
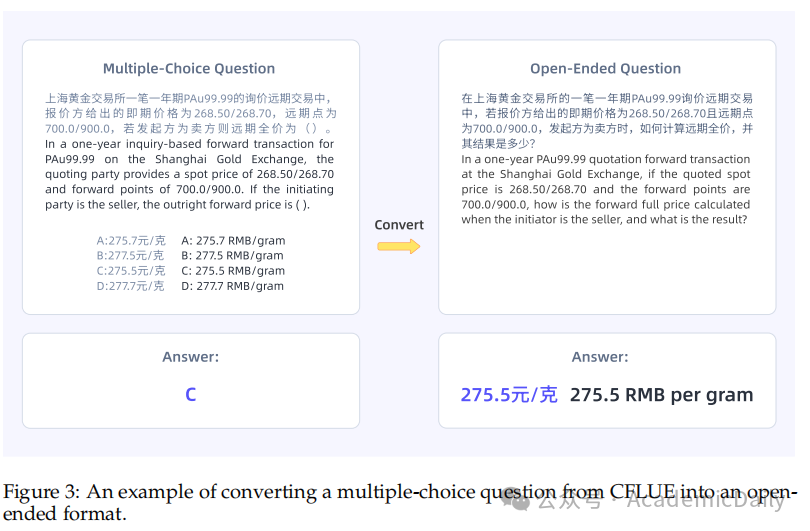
利用DeepSeek-R1为样本生成推理链和预测答案,再用GPT4o验证,满足条件的作为有效推理样本,否则重试或作为非推理样本(图3)。
FinQA问题推理生成:FinQA的问答对已是开放式格式,采用与CFLUE开放式问题相同的推理生成流程,得到推理增强数据集和非推理数据集。

CCC对话推理生成:基于合规指南开发工作流,使用基于大语言模型的智能体为CCC对话生成中间推理链和答案,若最终答案与正确答案匹配,用GPT4o合并中间推理链得到最终统一推理链,否则重试(图1)。
4.3 模型训练
监督微调学习推理:利用推理数据集对大语言模型进行微调,让模型学习生成推理链和最终答案(图2)。
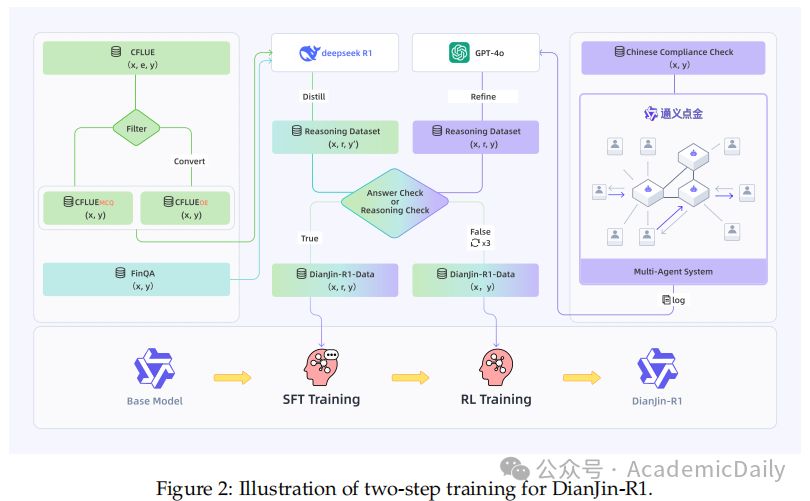
强化学习提升推理:采用GRPO算法,进行强化学习,通过格式奖励确保输出结构合理,通过准确率奖励促进答案正确。
实验结果
总体上,融入推理的模型通常优于非推理模型。
在三个金融测试集上,点金R1模型显著超越基础模型,点金R132B在这些任务上取得最高准确率。
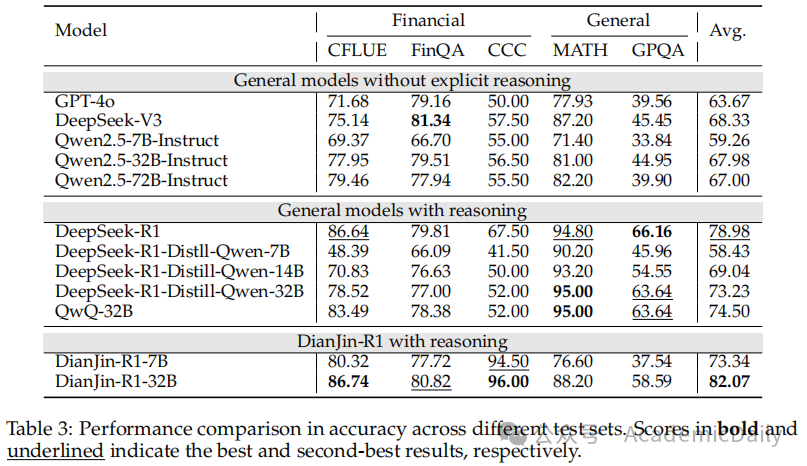
在两个通用领域测试集上,点金R1模型相比基础模型也有性能提升,但由于训练未涉及通用领域推理数据集,其性能仍低于更大参数规模或在通用推理数据上微调的模型(性能对比见表3)。
讨论
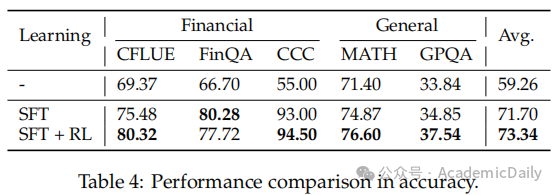
强化学习的影响:监督微调显著提升模型性能,强化学习在除FinQA外的数据集上进一步提升性能,推测FinQA的例外可能是因为强化学习使用的实例为中文,而FinQA为英文(表4)。
监督微调中不同数据集的影响:CFLUE对模型性能影响最大,单独使用CFLUE能显著提升性能,结合多个数据集进行监督微调可获得最佳整体性能(表5)。
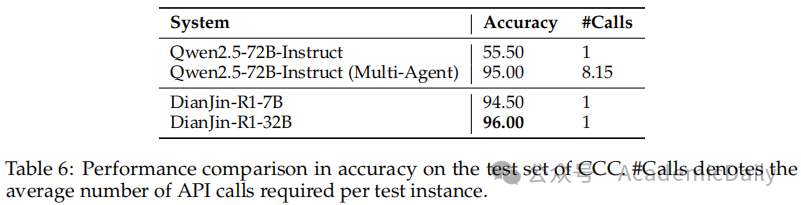
不同系统在CCC上的影响:基于多智能体的大语言模型系统可提高CCC任务的准确率,但成本较高。
点金R17B和点金R132B模型仅通过单次API调用就达到了可比甚至更优的性能(表6)。
结论
本文提出点金R1,这是一个用于金融领域大语言模型的推理增强框架。
【源码链接】
https://github.com/aliyun/qwen-dianjin

END
朋友们!

往期推荐阅读

ICLR 2025 | 告别呆板3D模型,新方法让虚拟物体活起来!
一觉醒来,理想汽车开源大模型研究了。
南大LAMDA李宇峰 | 突破40%性能瓶颈!自我回溯技术让LLMs推理能力飞跃
万字详解DeepSeek-R1,引爆AI圈的又一力作,大模型爆发势不可挡!
最强开源媲美闭源 | 万字详解 DeepSeek-V3 技术报告!
超强12边形选手!阿里通义提出实时语音交互大模型MinMo!
相关文章
