这篇文章讲解通过致远OA上传附件到文档中心后,把文档解析成文字,再把数据用大模型转成向量入库。用AI大模型进行文档的召回和基于文档的上下文进行简单对话。
思路:OA切入点
什么是embedding?
embedding在机器学习和自然语言处理中,主要是将词汇、句子、段落甚至整个文档转换为实数向量的过程。这种转换过程允许模型在进行训练和推理过程中,能够理解和处理语言数据。这些向量能够捕捉单词语义上的相似性,例如词义相近的单词在嵌入空间中的向量会更接近。
大语言模型 LLM
LLM(Large Language Model,大语言模型)是指使用大量文本数据训练的深度学习模型,能够生成自然语言文本或理解语言文本的含义。 LLM的核心思想是通过大规模的无监督训练学习自然语言的模式和结构,模拟人类的语言认知和生成过程。这些模型通常采用Transformer架构,并通过自监督学习方法利用大量未标注文本进行训练。
LLM的使用场景非常广泛。首先,LLM可以用于文本生成,可以生成连贯的段落、文章、对话等,可以应用于自动写作、机器翻译等任务中。其次,LLM可以用于问答系统,可以回答复杂的问题,甚至进行对话式问答。再者,LLM可以用于语义理解和推理,可以进行情感分析、命名实体识别、文本分类等任务。此外,LLM还可以用于智能助理、机器人交互、自动摘要、信息提取等应用领域。
ChromaDB 向量数据库
ChromaDB 是一个轻量级向量数据库,主要用于存储和查询大规模、高维数据。它支持多种数据类型,包括文本、图像等,并且能够处理复杂的查询和大规模数据集。ChromaDB特别适用于自然语言处理(NLP)和机器学习应用,能够提供高效的向量检索和语义搜索功能。

安装大模型
1、搜索大模型,查找运行大模型的命令,
地址:https://ollama.com/search
2、运行大模型,通过命令行下载大模型,命令行格式:ollmapull modelName,如:ollma pull llama3;
3、大模型一般要几个G,需要等一会;一般运行, llama3、 qwen(通义千问),这两个都是开源免费的,英文场景 用 llama3,中文场景用 qwen;
电脑如果内存小,建议运行一个就行了,8g内存的电脑肯定,开发肯定不行,至少16g
本次运行:qwen2.5:3b 这个3b的模型小适合开发用
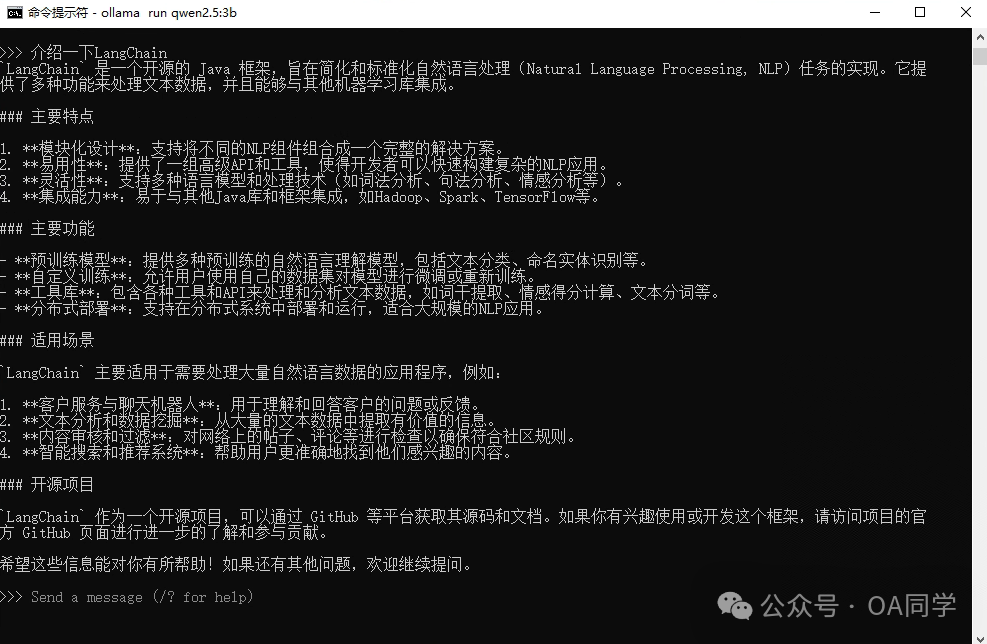
通过 ollma list 可以查看 已下载的大模型:
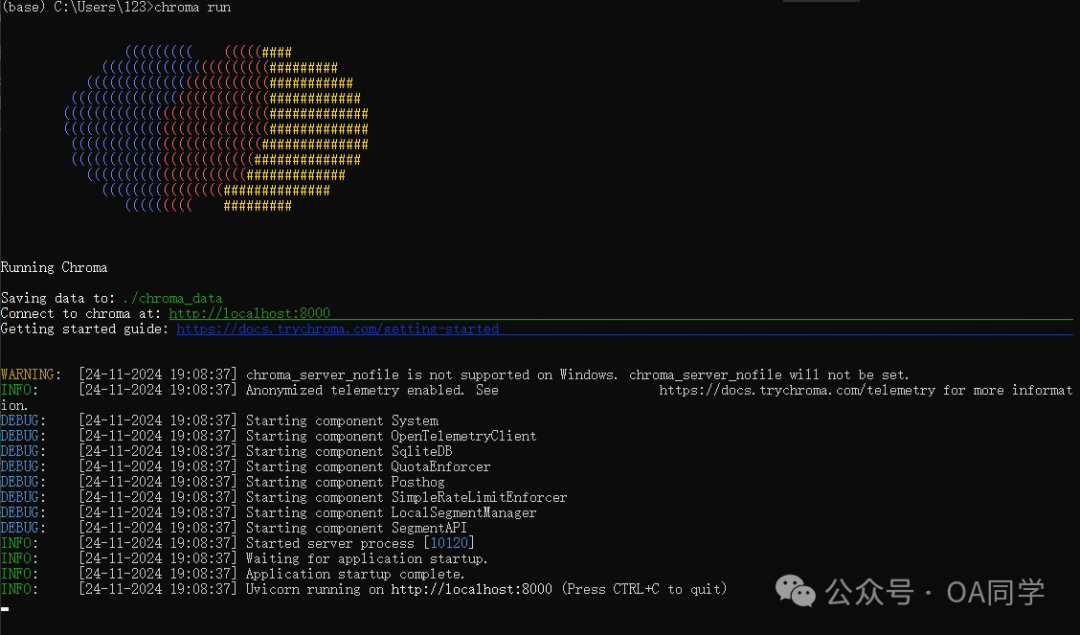
安装ChromaDB
1.安装:pip install chromadb ; 安装需要先安装Python,不要安装最新的,安装python=3.11.10 左右的版本最合适。
2.启动:chroma run :
<properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <langchain4j.version>0.34.0</langchain4j.version> </properties><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-open-ai</artifactId> <version>${langchain4j.version}</version></dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-chroma</artifactId><version>${langchain4j.version}</version></dependency><!-- ollama --><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-ollama</artifactId><version>${langchain4j.version}</version></dependency><!--chroma 向量数据库--><dependency><groupId>io.github.amikos-tech</groupId><artifactId>chromadb-java-client</artifactId><version>0.1.7</version></dependency>
/*** 〈监听附件上传〉** @author OA同学* @create 2024/11/11* @since 1.0.0*/public class RAGFileEvent {(event = FileUploadEvent.class)public void onFileUpload(FileUploadEvent evt) throws Exception {// 取得上传的文件FileItem fileItem = evt.getFileItem();String originalFilename = fileItem.getOriginalFilename();if (originalFilename.contains(".txt")) {//保存文件到临时目录String systemTempFolder = SystemEnvironment.getSystemTempFolder();String pathname = systemTempFolder + File.separator + UUIDUtil.getUUIDString() + File.separator + originalFilename;CtpFile tempFile = new CtpFile(pathname);InputStream inputStream = fileItem.getInputStream();GlobalFileUtils.saveCtpFile(inputStream, tempFile);//解析文件 DocumentDocument document = LangChainUtils.getDocument(pathname);//拆分文件内容//文本向量化//向量库存储//向量库检索//与LLM交互String chat=LangChainUtils.llmChat(message);}}}
把文件解析成langchain4j的Document对象。
public static Document getDocument(String fileName) {URL docUrl = LangChainUtils.class.getClassLoader().getResource(fileName);if (docUrl == null) {log.error("未获取到文件");}Document document = null;try {Path path = Paths.get(docUrl.toURI());document = FileSystemDocumentLoader.loadDocument(path);} catch (URISyntaxException e) {log.error("加载文件发生异常", e);}return document;}
拆分文件
//======================= 拆分文件内容=======================// 参数:分段大小(一个分段中最大包含多少个token)、重叠度(段与段之前重叠的token数)、分词器(将一段文本进行分词,得到token)DocumentByLineSplitter lineSplitter = new DocumentByLineSplitter(200, 0, new OpenAiTokenizer());List<TextSegment> segments = lineSplitter.split(document);log.info("segment的数量是: {}", segments.size());//查看分段后的信息segments.forEach(segment -> log.info("========================segment:" +segment.text()));
文本向量化并保存向量
private static final String CHROMA_DB_NAME = "rag-oa"; private static final String CHROMA_URL = "http://localhost:8000" private static final String OLLAMA_URL = "http://localhost:11434"; private static final String OLLAMA_NAME = "qwen2.5:3b"; //======================= 文本向量化=======================OllamaEmbeddingModel embeddingModel = OllamaEmbeddingModel.builder().baseUrl(Optional.ofNullable(AppContext.getSystemProperty("rag.ollama_url")).orElse(OLLAMA_URL)).modelName(Optional.ofNullable(AppContext.getSystemProperty("rag.ollama_name")).orElse(OLLAMA_NAME)).build();//======================= 向量库存储======================= //创建向量数据库EmbeddingStore<TextSegment> embeddingStore = ChromaEmbeddingStore.builder().baseUrl(Optional.ofNullable(AppContext.getSystemProperty("rag.chroma_url")).orElse(CHROMA_URL)).collectionName(Optional.ofNullable(AppContext.getSystemProperty("rag.chroma_db_name")).orElse(CHROMA_DB_NAME )).build();segments.forEach(segment -> {Embedding e = embeddingModel.embed(segment).content();embeddingStore.add(e, segment);});
向量库检索
//======================= 向量库检索=======================String qryText = "待办";Embedding queryEmbedding = embeddingModel.embed(qryText).content();EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder().queryEmbedding(queryEmbedding).maxResults(1).build();EmbeddingSearchResult<TextSegment> embeddedEmbeddingSearchResult = embeddingStore.search(embeddingSearchRequest);List<EmbeddingMatch<TextSegment>> embeddingMatcheList = embeddedEmbeddingSearchResult.matches();EmbeddingMatch<TextSegment> embeddingMatch = embeddingMatcheList.get(0);TextSegment textSegment = embeddingMatch.embedded();log.info("查询结果:" +textSegment.text());
与LLM交互
//======================= 与LLM交互=======================PromptTemplate promptTemplate = PromptTemplate.from("基于如下信息用中文回答:n" + "{{context}}n" + "提问:n" + "{{question}}");Map<String, Object> variables = new HashMap<>();//以向量库检索到的结果作为LLM的信息输入variables.put("context", textSegment.text());variables.put("question", "我总共几个待办事项");Prompt prompt = promptTemplate.apply(variables);//连接大模型OllamaChatModel ollamaChatModel = OllamaChatModel.builder().baseUrl(Optional.ofNullable(AppContext.getSystemProperty("rag.ollama_url")).orElse(OLLAMA_URL)).modelName(Optional.ofNullable(AppContext.getSystemProperty("rag.ollama_name")).orElse(OLLAMA_NAME)).build();UserMessage userMessage = prompt.toUserMessage();Response<AiMessage> aiMessageResponse = ollamaChatModel.generate(userMessage);AiMessage response = aiMessageResponse.content();log.info("大模型回答: "+ response.text());
我们写个接口测试一下:
public class AIRestResource extends BaseResource {private static final Log log = LogFactory.getLog(AIRestResource.class);public Response mesasge( String message) {//与LLM交互return ok(LangChainUtils.llmChat(message));}}
上传一个测试.txt,内容如下
在致远OA中有2个待办协同,有3个待办公文,有1个10点的会议
根据你的描述,在致远OA中你有以下几个待办事项:- 两个待办协同任务- 三个待办公文任务- 一次在10点开始的会议将这些加起来,你可以得出总共的待办事项目数是:[ 2 + 3 + 1 = 6 ]所以,你总共有 **六个** 待办事项目。
5、接下来我将用AI大模型把OA的大部分功能重做一遍。
相关文章
