今天,豆包全新基础模型 Doubao-1.5-pro 正式发布,模型能力全面升级,融合并进一步提升了多模态能力。
模型使用 MoE 架构,并通过训练-推理一体化设计,探索模型性能和推理性能之间的极致平衡。Doubao-1.5-pro 仅用较小激活参数,即可比肩一流超大稠密预训练模型的性能,并在多个评测基准上取得优异成绩。值得注意的是,通过模型结构和训练算法优化,我们将 MoE 模型的性能杠杆提升至 7 倍,此前,业界的普遍水平为不到 3 倍。
此外,团队还构建了高度自主的数据生产体系,坚持不走捷径,不使用任何其他模型的数据,确保数据来源的独立性和可靠性。
-
如何用较小参数激活的 MoE 模型,达到世界一流模型的性能
-
如何在保证模型性能的前提下,将推理成本压缩到极致
-
如何构建高度自主的数据生产体系
-
多模态能力的提升及表现
完整版 Blog ,可在豆包大模型团队官网查看:
https://team.doubao.com/doubao_1_5_pro
综合能力领先
多基准表现优异
此次更新,Doubao-1.5-pro 基础模型能力全面提升,在多个公开评测基准上表现优异。
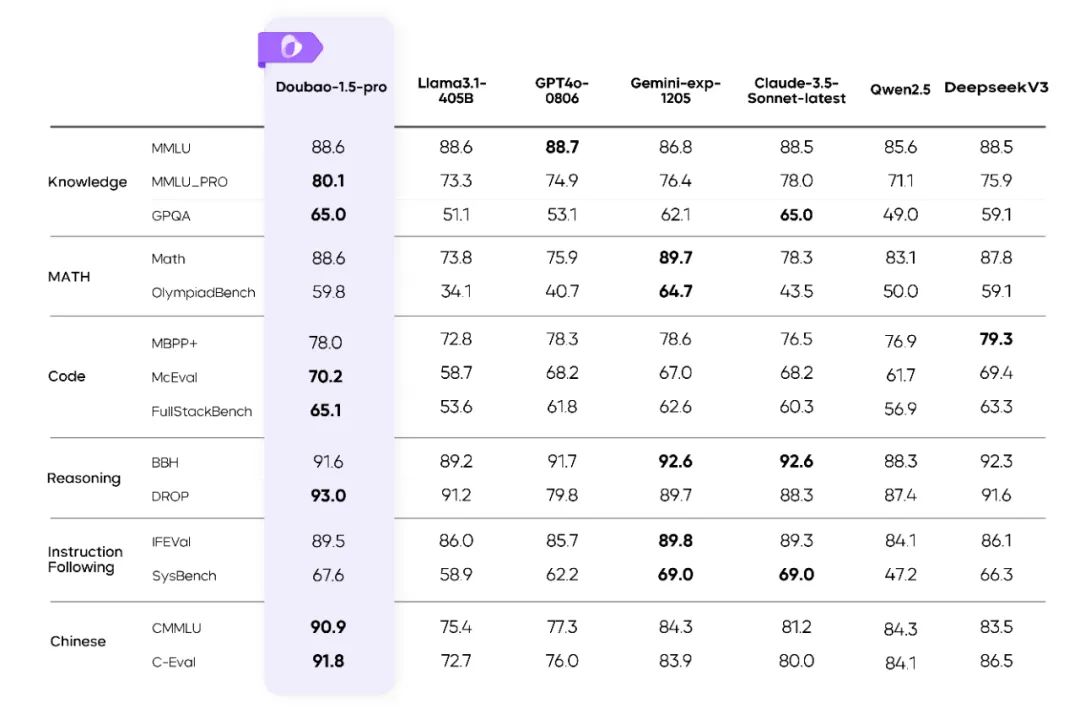 Doubao-1.5-pro 在多个基准上的评测结果
Doubao-1.5-pro 在多个基准上的评测结果
-
其它模型的评测指标来自官方评测结果,官方评测结果中不含的部分来自内部评测平台结果
-
GPT4o-0806 在语言模型公开评测指标中显著优于 GPT4o 其他版本
高效 MoE 模型结构
 训练 loss 图Performance 对比图
训练 loss 图Performance 对比图-
Doubao-Dense、Doubao-MoE 均为 9T tokens 数据的阶段性结果,数据分布完全相同;MoE 模型的性能略优于整体参数量为 MoE 激活参数量 7 倍的稠密模型
-
Llama3.1-405B 为 15T tokens 的最终结果,数据分布和 Doubao 模型不同,Doubao 稠密模型的参数量也远小于 Llama3.1-405B ,从结果上可以看到 Doubao 预训练的数据质量和训练超参更优
-
MoE 模型完整训练后的性能比 9T tokens 数据的中间版本有更大提升
在预训练模型基础上,算法团队还设计了一系列模型参数动态调整算法。可以基于具体应用对模型性能的需求,从模型深度、宽度、MoE 专家数、激活专家数、隐藏 token 推理等不同维度,对模型参数进行扩增和缩小,达到模型能力和推理成本的最优平衡。同时,较小的预训练模型提高了团队迭代开发的效率,可以并发支持多个产品线。
高性能推理系统
Doubao-1.5-pro 是一个高度稀疏的 MoE 模型,在 Prefill/Decode 与 Attention/FFN 构成的四个计算象限中,呈现出显著不同的计算与访存特征。针对四个不同象限,我们采用异构硬件结合多种低精度优化的策略,在确保低延迟的同时大幅提升吞吐量,在降低总成本的同时兼顾 TTFT 和 TPOT 的最优化目标。
不同阶段的计算与访存特征整体来看,在 PD 分离的 Serving 系统上,我们实现了以下优化:
-
针对 Tensor 传输进行定制化的 RPC Backend ,并通过零拷贝、多流并行等手段优化了 TCP/RDMA 网络上的 Tensor 传输效率,进而提升 PD 分离下的 KV Cache 传输效率。 -
支持 Prefill 跟 Decode 集群的灵活配比和动态扩缩,对每种角色独立做 HPA 弹性扩容,保障 Prefill 和 Decode 都无冗余算力,两边算力配比贴合线上实际流量模式。 -
在框架上将 GPU 计算和 CPU 前后处理异步化,使得 GPU 推理第 N 步时 CPU 提前发射第 N+1 步 Kernel,保持 GPU 始终被打满,整个框架处理动作对 GPU 推理零开销。
扎实数据标注
融合视觉及语音
视觉多模态:
性能进一步提升,从容应对更复杂场景
相比于此前发布的 Doubao 视觉理解模型版本,Doubao-1.5-pro 在多模态数据合成、动态分辨率、多模态对齐、混合训练上进行了全面的技术升级,进一步增强了模型在视觉推理、文字文档识别、细粒度信息理解、指令遵循方面的能力,并让模型的回复模式变得更加精简、友好。
Doubao-1.5-pro 在多个视觉基准上的评测结果-
在评测中 GPT4o-1120 在多模态能力上要优于 GPT4o-0806
文本与视觉混合的多模态能力:为同时保障模型的视觉和语言能力,团队在 VLM 多个训练阶段都混入了一定比例的纯文本数据,并通过动态调整学习率的方法平衡视觉与语言能力,使模型的语言能力无损。
语音多模态:
理解生成一体化,情商智商在线
在语音多模态方面,我们提出了全新的 Speech2Speech 端到端框架,不仅通过原生方法将语音和文本模态进行深度融合,同时还实现了语音对话中真正意义上的语音理解生成端到端,相比传统 ASR+LLM+TTS 的级联方式,在对话效果上有质的飞跃。
Doubao-1.5-pro 不仅拥有高理解力(高智商),还具备语音高表现力与高控制力,以及模型整体在回复内容和语音上的高情绪承接能力。
探索智能边界
Doubao 深度思考模式
推理能力是智能的重要组成部分,团队致力于使用大规模 RL 的方法不断提升模型的推理能力,拓宽当前模型的智能边界。在完全不使用其他模型数据的条件下,通过 RL 算法的突破和工程优化,充分发挥 Test Time Scaling 的算力优势,完成了 RL Scaling ,研发了 Doubao 深度思考模式。
 Doubao-1.5-pro-AS1-Preview 在 AIME 上的评测结果
Doubao-1.5-pro-AS1-Preview 在 AIME 上的评测结果目前,阶段性成果 Doubao-1.5-pro-AS1-Preview 在 AIME 上已经超过 O1-preview、O1 等推理模型。并且,随着 RL 的持续,模型能力还将不断提升。在这一过程中,我们也看到了推理能力在不同领域的泛化,智能的边界正在被慢慢拓宽。
推理能力的初步泛化向智能的无限可能出发
豆包大模型团队一直以探索智能的无尽边界、解锁通用智能的无限可能为目标。同时,我们认为探索智能的边界与服务用户和行业是一体的关系,两者可以彼此增益、双向驱动。接下来,团队会继续加强对大模型基础研究的投入,挑战更长周期的、具有颠覆性的通用智能研究课题
相关文章
