导读
 (另外,值得一提的是,本篇论文的一作,正是如今国内最火的大模型创业公司月之暗面创始人杨植麟;其并列一作戴子航则是马斯克成立的xAI中的华人中坚力量)
(另外,值得一提的是,本篇论文的一作,正是如今国内最火的大模型创业公司月之暗面创始人杨植麟;其并列一作戴子航则是马斯克成立的xAI中的华人中坚力量)
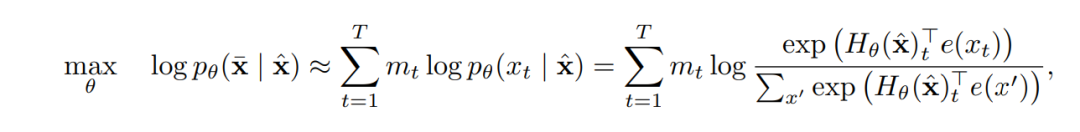
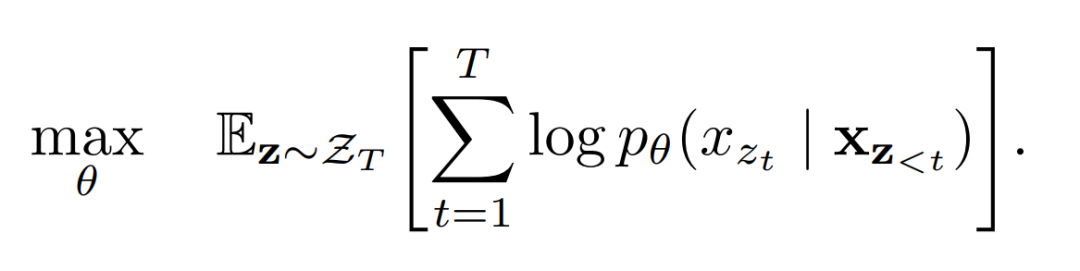
-
表示序列长度为的所有可能排列的集合,这意味着 XLNet 在训练时,不会以固定顺序(如从左到右)来预测单词,而是会考虑序列的每一种可能的重排方式。
-
和 <分别代表排列的第个元素和前个元素,这意味着模型会根据排列中位于之前的 token,来预测位置的 token,而不管这些token在原始序列中的顺序。
03
XLNet 在基准测试中的性能表现
排列语言建模和 Transformer-XL 的结合,使 XLNet 在多个 NLP 基准测试中超越了之前的模型。以下是一些关键结果的解析:
1、SQuAD 2.0(斯坦福问答数据集)
在 SQuAD 2.0 基准测试中,XLNet 的 Exact Match (EM) 得分为 87.9%,而 BERT 的得分为 80.0%。这表明 XLNet 在处理复杂问答任务时,具有更强的能力,尤其是在需要理解长篇文章,和判断问题是否可以回答的任务中表现更好。
2、GLUE 基准测试
通用语言理解评估(GLUE) 基准测试,衡量模型在多种语言理解任务中的表现,包括情感分析(SST-2)、释义检测(MRPC)和自然语言推理(MNLI)。在多项 GLUE 任务中,XLNet 的表现都比 BERT 好,凸显了其在处理各种 NLP 挑战时的多功能性。
3、RACE 数据集
RACE 阅读理解数据集包含考试风格的问题,要求模型从长篇文章中提取信息,并进行跨句推理。XLNet 通过排列建模方法,有效地捕捉文章中的复杂依赖关系,在多句推理和推断问题上,表现出更高的准确性,从而超越了 BERT 等之前的模型。
04
XLNet 在 NLP 中的实际应用
XLNet 的创新,使其适用于多种自然语言处理任务:
1、增强型问答系统
XLNet 的深度上下文理解能力,成为构建复杂问答系统的最佳选择。它能够建模双向上下文和长距离依赖关系,确保生成准确且符合上下文的答案。
示例:在客户服务聊天机器人中,当用户提问 “How do I return an item?”(如何退货?)时,XLNet 可以考虑整个对话历史,生成一个详细的回答,提供更准确和有用的答案。
2、文本摘要和生成
XLNet 捕捉长距离依赖关系的能力,使其在文本摘要和生成任务中表现很好。通过理解文档的完整上下文,XLNet 能够生成简洁且连贯的长文本摘要。
示例:如果需要对一篇长篇新闻文章进行总结,XLNet 可以准确捕捉关键点,同时保持原始上下文的连贯性。
3、情感分析
在情感分析任务中,XLNet 的排列语言建模,可以捕捉主体与观点之间的微妙关系,从而可以高效地从文本中提取情感信息。
示例:在分析产品评论时,XLNet 可以检测出间接或复杂语言中隐含的情绪,例如沮丧或满意。
05
实践:XLNet +Milvus,构建高效检索推荐系统
除了在经典的 NLP 任务中表现很好外,XLNet 生成稠密向量 embedding 的能力,为可扩展的搜索和检索系统提供了新的可能性,尤其是在与强大的向量数据库(如 Milvus)集成时,可以在文档检索和推荐系统等任务中发挥强大作用。
在向量 embedding 环节,当 XLNet 处理一个句子或文档时,会在高维空间中,生成一个代表文本语义的高维向量。语义相似的文本会生成相似的向量表示,并在向量空间中相邻排列,从而支持基于语义而非精确关键词匹配的高效检索。
示例:对于句子 “The cat sat on the mat” 和 “The dog lay on the rug”,尽管单词不同,但它们的语义相似。XLNet 生成的向量embedding,会使这两个句子在向量空间中彼此相邻,从而使搜索引擎在查询语义相关的短语时,能够同时检索到这两个句子。
在此基础上,我们可以引入Milvus 开源向量数据库,Milvus 专为存储和查询高维向量(如 XLNet 生成的向量)而生,能够处理数百万乃至数十亿级的向量数据,并支持混合检索、全文检索等一众特性需求,是 GitHub 上最受欢迎的向量数据库。以下是 Milvus 如何增强 XLNet 能力的具体解读:
1、混合搜索(Hybrid Search):Milvus 允许将向量相似性搜索与传统过滤相结合,从而支持语义相似性和元数据的复杂查询。例如,在法律文档搜索系统中,Milvus 可以检索与查询语义相关的文档,同时根据案件类型或管辖区域进行过滤。
2、高效的高维索引(Efficient High-dimensional Indexing):Milvus 使用先进的索引方法,支持高效查询高维向量,这对于处理 XLNet 生成的embedding至关重要。这种索引能力确保了即使在海量向量中也能快速检索。
3、可扩展性(Scalability):Milvus 设计时用了水平扩展,能够处理数十亿条向量。这种可扩展性使其非常适合大规模应用,特别是使用 XLNet embedding 的产品环境。
4、实时更新(Real-time Updates):Milvus 支持实时插入和更新,使新生成的 XLNet embedding 能够立即用于查询。这使系统能够在不做大变动的情况下不断更新。
06
尾声
XLNet 通过克服自回归模型和自编码模型的局限性,带来了NLP技术的重大进展。它的排列语言建模可以捕捉双向上下文信息,同时 Transformer-XL 可以处理长距离语义挖掘。这些创新使 XLNet 在问答、文档检索等多种任务中表现出色。
将 XLNet 与 Milvus 集成,我们可以构建出可扩展、高效的系统,它们可以通过稠密向量 embedding 来完成搜索和检索任务。随着 NLP 研究的不断推进,XLNet 的影响力可能会进一步扩大,为更强大、适应性更强的语言理解系统铺平道路。
如对以上案例感兴趣,或想对milvus做进一步了解,欢迎扫描文末二维码交流进步。
相关文章
最实用、最热门的AI 工具大全AI 工具导航,帮助你在工作与学习上更轻松有效率。在网路上众多 AI 与 ChatGPT 工具中,我们亲自试用并挑选了最有有用的,分成 20多个大类别,让你轻松找到所需的 AI 工具。
