在 AI 领域,强化学习(RL)作为 LLM 的关键训练方法,已成为行业共识。其灵感来自于 AlphaGo、AlphaStar、OpenAI Dota Five 等掌握了围棋、星际争霸II 和 Dota2 等复杂游戏。
得益于在 RL-LLM 方向的不断探索,Kimi 找到了简单却又行之有效的 RL 框架和训练方式,实现了满血版多模态 o1 水平的 k1.5。在 short-CoT 模式下,大幅超越了 GPT-4o 和 Claude 3.5 Sonnet 的水平;在 long-CoT 模式下,k1.5 已达到 OpenAI o1 正式版的水平。
无独有偶,DeepSeek 借鉴 Alpha-Zero 的方式,无需人工输入,直接做了 Zero-SFT 的 RL,也取得了非常不错的成绩。两支国内顶尖团队冥冥之中走到了一起,于同日发布的技术报告,在技术路线上也做到了互相验证。对此网友表示:感觉像是诸葛亮和周瑜相视一笑,摊开掌心,都写着一个“火”字。
Kimi 的做法更新鲜一些,采用了 AlphaGo-Master 的思路,通过提示工程构建的 CoT 轨迹进行轻量级的 SFT 预热。
回想当时在 o1 出现后,无数人想要复现,而对于 o1 的复现观点很多,甚至有专门的仓库收集相关论文和博客。
https://github.com/hijkzzz/Awesome-LLM-Strawberry.
其中,基于过程奖励模型(PRM)和蒙特卡洛树搜索(MCTS)的技术实现路径被热议。
而在许多从业者的复现过程中,这条路的也慢慢被人发现难以继续。一方面是在训练数据上往往只包含正确的内容和结论,但缺少作者对结论的思考过程,更重要的是缺少作者在得到正确结论前的失败尝试和总结;另一方面,对于大多数基座模型,其本身的 Self-Critic 就是一个较难的任务;再者,在真正实现树搜索的过程中,其细节和复杂度也相当的高。
https://zhuanlan.zhihu.com/p/13872128423
回到 Kimi,研究作者 @Flood Sung 在知乎上分享了自己的心路历程:原来并不需要将 AlphaGo 的 MCTS 用到 LLM 上,真正重要的是能够让模型自行搜索。并且,o1 并没有限制模型如何思考,做各种结构化的框架会限制模型能力,Kimi 要让模型能够像人一样自由的思考。因此关键在于:
1. 要训练 LLM 通过 RL 做题,有精确 Reward;
2. 不要采取结构化的方法,最终会限制住模型的效果,要让模型自己探索思考范式;
此外,Kimi 在实际训练过程中,有一个重要的令人惊喜的发现:模型会随着训练提升 performance 也不断增加 token 数,这意味着 COT 是可以在 RL 训练过程中涌现的。
一位小特工总结性的表示:其实无论是 Kimi 还是 DeepSeek 的报告,都证明了一件事情,长的 COT 是可以自己涌现出来的,这就解决之前的一个很大假设问题,即大量的长 COT 数据要从哪里来。在这个意义上 Kimi 和 DeepSeek 同时终结了这个游戏,因为没有秘密了。
大道至简,给 AI 一个可衡量的目标,然后让其自己去探索,然后通过 RL 提升模型,仅此而已。
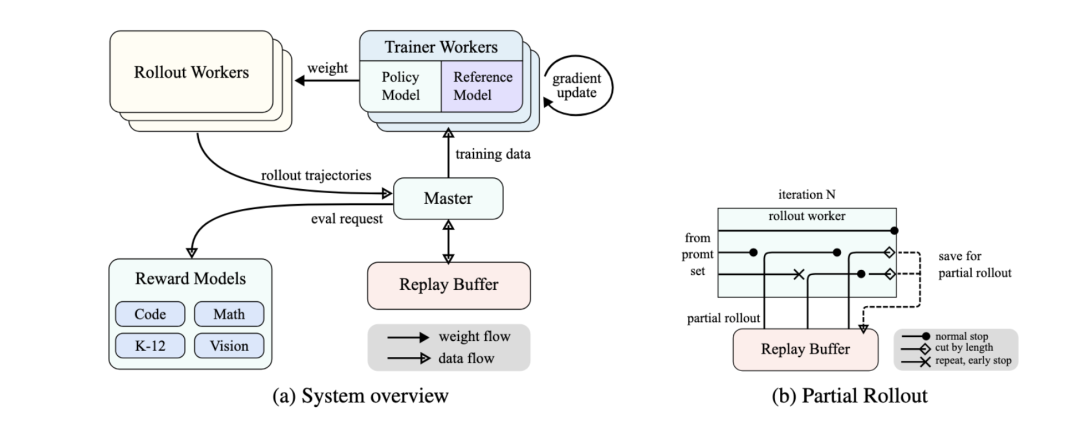
Kimi 没有依赖复杂的蒙特卡洛树搜索、价值函数或过程奖励模型等复杂技术,而是构建了一套 RL 框架(如下图)。
框架中提出了创新的 Partial rollouts 来做 Scaling,通过 Partial Rollouts 技术提升训练效率,允许模型在训练过程中复用之前的轨迹片段,避免从头生成新轨迹,从而节省计算资源。
此外,Kimi k1.5 技术报告中还包括了 long2short 技术,与训练推理混合部署框架。前者通过模型合并、DPO 等技术,将长链式思维模型里学习到的思维先验转移到短链式思维模型中,后者的混合框架则具有高效资源共享和管理,并能提升训练推理性能。由于篇幅有限,推荐可以去阅读下原报告。
https://github.com/MoonshotAI/Kimi-k1.5/blob/main/Kimi_k1.5.pdf
自 24 年下半年起,Kimi 似乎更加专注于如何实现 AGI 的技术上,k1.5 已经是 Kimi 连续第三个月带来 k 系列强化学习模型的升级。
新春佳节之际,前方捷报频传。各家在模型上做了持续的优化,这些技术上的迭代将在不远的将来转化为人人实际可用的产品。振奋人心的是,我们正一步步朝着 AGI 与 ASI 迈进。
我们即将迎来更多领域 AI 超越人类的「李世石时刻」,正如真格基金管理合伙人戴雨森说的那样:
“呵呵,那个 AI 和猴子一样聪明呢,真逗”。
“我擦,发生了什么?”
我们要越来越习惯在可以用 RL 的地方很快迎来 AI 超越人类的“李世石时刻”。
看到 Kimi k1.5 这一组数据的时候,我的第一反应是:we are running out of benchmarks。在 short-CoT 模式下,Kimi k1.5 的数学、代码、视觉多模态和通用能力,大幅超越了全球范围内短思考 SOTA 模型 GPT-4o 和 Claude 3.5 Sonnet 的水平。这在一年前绝对是难以想象的。同时 k1.5 在Long-CoT 下的表现,更加让我们看到 There is no wall,RL 还可以走很远。
是更多 DAU 和时长,还是更多智能?新时代需要新的范式,我们始终相信一小群对技术充满热情的年轻人可能改变世界。我们也始终相信 AI 对人类的意义不止于打电话和虚拟贴贴,把能量更高效变成生产力普惠人类,应该才是这个游戏的通关答案。