BERT,英文名字来自:Bidirectional Encoder Representations from Transformers 简写,翻译过来就是:基于 Transformer 的双向编码器表示法。BERT是由Google早在2018年提出的一种预训练语言模型,到目前为止,它几乎革新了自然语言处理领域。尤其是在深度学习的背景下,如其名字,核心通过引入双向编码器表示,极大地提升了多种NLP任务的效果。
与传统的单向语言模型不同,BERT使用了双向Transformer的编码器结构来预训练文本表示,它可以同时考虑一个词左边和右边的上下文信息,从而生成更准确、语义更丰富的词表示。其实BERT也是基于2017年提出的Transformer架构而来,这个架构抛弃了以往序列模型中常用的递归神经网络(RNN),转而完全依赖于 自注意力机制,使得模型能够并行处理整个句子,并且更好地捕捉长距离依赖关系。
BERT的基本原理是基于Transformer的自编码语言模型。它首先通过将输入的token、segment和position进行embedding,然后将这些 embedding 相加以形成输入层。接下来,使用 Transformer 做 encoder,对输入的序列进行预训练处理。
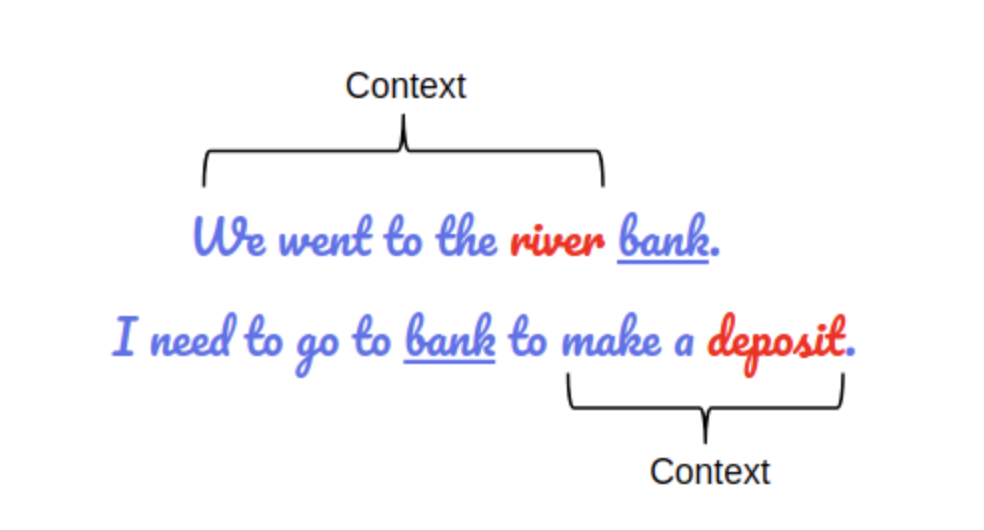
BERT的预训练涉及两个主要任务:翻译过来可以概括为 掩码语言模型 和 下一句预测,大佬们一般习惯叫 MLM 和 NSP。掩码语言其实类似我们以前做的完形填空,通过在输入序列中的某些单词被随机遮蔽(通常用特殊标记 [MASK] 替换),然后模型尝试根据上下文预测这些被遮蔽的单词。这种方式迫使模型理解句子的双向上下文,而不是简单地从左到右或从右到左进行预测。
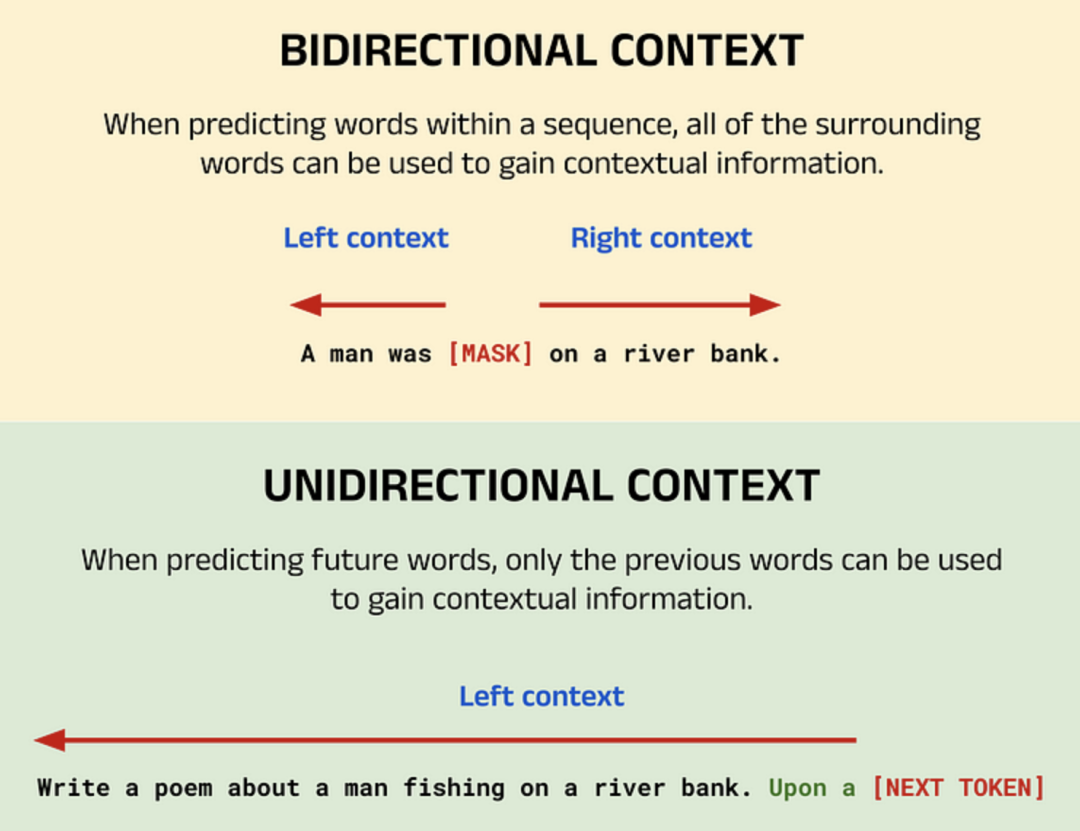
这一点与 GPT 等纯解码器模型形成鲜明对比,GPT的目标是一次预测一个新词,以生成新的输出序列,每个预测的单词只能利用前面的单词(左语境)提供的语境,因为后面的单词(右语境)还尚未生成,这种模型也被称为单向模型。
其次,BERT还训练了一个二分类任务,即判断给定的两个句子是否是连续的。例如,给出句子A和句子B,模型需要判断B是否紧接在A之后出现。说到这里,我们能联想到这种训练,对问答系统、自然语言推理等任务其实特别有用。
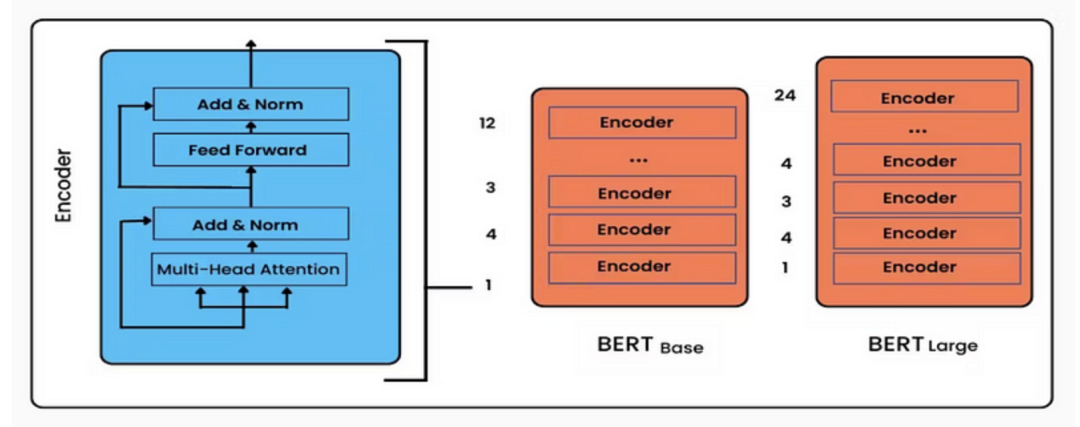
BERT模型的核心架构包含的是这个编码器(Encoder),该编码器由多个 Transformer层堆叠而成。每个Transformer 层包含多头自注意力机制和前馈神经网络,并且还引入了位置编码,来表示单词在句子中的位置信息。另外,它还有2个变种,分别是Bert Base 和 Bert Large。BERT-BASE 在编码器堆栈中有 12 层,而 BERT-LARGE 在编码器堆栈中有 24 层,相比原始论文中建议的 Transformer 架构,BERT具有更大的前馈网络和更多的注意力头。
目前,BERT 模型在自然语言处理领域已有着广泛的应用场景,比如:文本分类、命名实体识别、问答系统、语义相似度计算、文本生成和机器翻译等众多领域。BERT 模型作为一种强大的自编码语言模型,在自然语言处理领域取得了显著的成果,但在实际应用中,也需要考虑其模型庞大、资源消耗高等问题,并进行适当的优化和剪枝。
相关文章
