本文假设你已掌握以下基础知识,不再赘述:
-
#LLM -
#提示词工程 -
#FunctionCalling -
#Python
MCP是什么
#MCP 是一个开放协议,它规范了应用程序向 LLM 提供上下文的方式。MCP 就像 AI 应用程序的 USB-C 端口一样。正如 USB-C 提供了一种标准化的方式将您的设备连接到各种外围设备和配件一样,MCP 也提供了一种标准化的方式将 AI 模型连接到不同的数据源和工具。
MCP 可帮助您在 LLM 之上构建代理和复杂的工作流。LLM 通常需要与数据和工具集成,而 MCP 可提供以下功能:
-
越来越多的预建集成可供你的 LLM 直接插入 -
在 LLM 提供商和供应商之间切换的灵活性 -
保护基础架构内数据的最佳实践
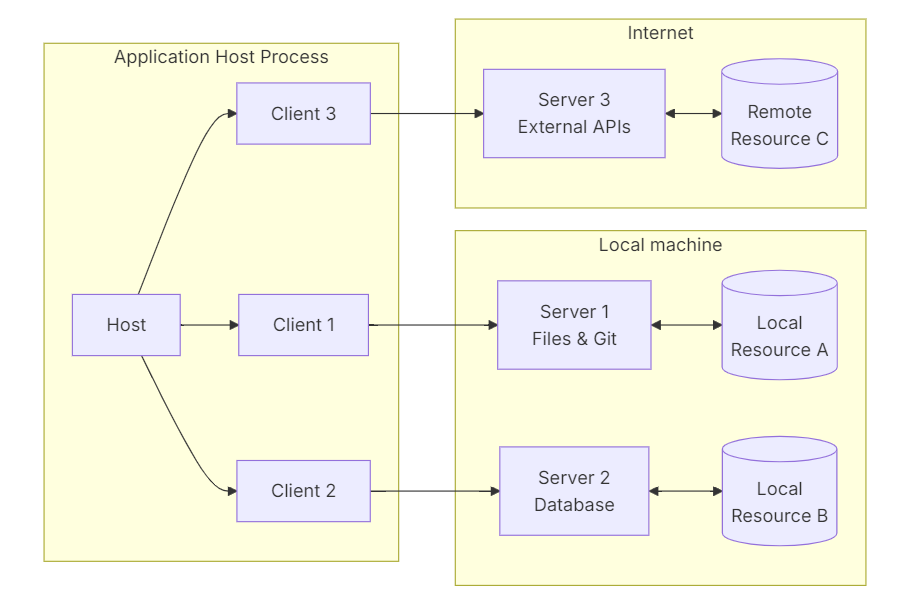
以上内容摘自MCP官方文档,我觉得已经说的非常清晰直观了,但还是很多人误以为MCP是一个神奇的工具,拥有执行命令、读取文件、查询数据等等功能。
不不不,MCP只是一个协议,LLM通过这个协议来使用各个工具。不管是执行命令、读取文件、查询数据,如果你有了这些工具,没有MCP也可以使用工具;反过来说,如果没有这些工具,光有MCP什么也做不了。
MCP的意义是LLM能够使用“远程工具”:这些工具可以使用不同语言、部署在不同设备、具有不同的功能,通过MCP把它们集成一起,供LLM选用;同样的,如果你已经有一批工具,那么也可以MCP把它们提供给任何一个LLM。
总而言之,MCP像USB一样,提供了各个LLM和各个工具之间的快速接入。
MCP底层原理
规范版本:2025-03-26
传输协议:
-
stdio (优先,仅本地) -
SSE (弃用) -
Streamable HTTP
鉴权方式:
-
OAuth 2.1 (仅HTTP)
如果MCP是在自己电脑里用,不用考虑鉴权什么的,那么stdio就够了,简单快捷。
如果你的MCP Server打算通过网络分享出去,基于HTTP则更加方便。此前MCP使用SSE来进行远程传输,在新的规范中则鼓励使用Streamable HTTP ,同时也支持了鉴权更加地安全。
报文内容:
-
JSON-RPC (UTF-8)
经典的方案,这个没什么好说的,如果你不是打算重新实现MCP Client的话,暂时不需要关注报文内容的细节。
生命周期(重点):
-
申明能力:server端定义工具、资源等能力 -
初始化:client连接server端,协商版本和能力 -
操作:(双向多轮)
-
client使用server的能力(如工具) -
server使用client的LLM
前期有一个“握手”的阶段,这样Client 才能知道Server有哪些工具,进而提供给LLM进行使用。
有意思的是MCP为Server约定了一个采样(sampling)的能力:使用LLM进行内容生成,也就说LLM也被Client 提供给了Server进行使用。
不过当前版本的SDK中暂时没有实现采样,具体用法还要再等更新。
MCP应用实战
安装依赖
pip install mcp openai-Agents
mcp 是MCP官方提供的SDK,内置了MCP Server 和 MCP Client实现,开箱即用
openai-agents是OpenAI开源的 #Agent 框架简化了LLM的操作细节
MCP Server声明能力
# server.py
import os
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("MCP Demo")
@mcp.tool()
def add(a: int, b: int) -> int:
"""返回a和b相加结果"""
return a + b
@mcp.tool()
def ls():
"""列出目录中的文件名"""
return os.listdir(".")
if __name__ == '__main__':
mcp.run() # 默认使用 stdio 传输
MCP Client初始化
# client.py
from mcp import ClientSession, StdioServerParameters, types
from mcp.client.stdio import stdio_client
# stdio 启动参数
server_params = StdioServerParameters(
command="python",
args=["server.py"],
)
async def run():
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# 初始化
await session.initialize()
# 查询支持的工具
result = await session.list_tools()
print("支持的工具有:",)
for tool in result.tools:
print(f" {tool.name} {tool.description}")
# 调用工具
result = await session.call_tool("add", arguments={"a": 1, "b":10})
print('add的调用结果:', result.content[0].text)
if __name__ == "__main__":
import asyncio
asyncio.run(run())
执行结果(可以发现工具和使用工具):
Processing request of type ListToolsRequest
Processing request of type CallToolRequest
支持的工具有:
add 返回a和b相加结果
ls 列出目录中的文件名
add的调用结果: 11
LLM使用远程工具
使用MCP加载工具之前
# llm.py
from agents import Agent, Runner
agent = Agent(
name="AI助手",
instructions="使用合适的工具,生成合适的响应", # 系统提示词
)
result = Runner.run_sync(agent,'当前目录有几个文件?')
print(result.final_output)
执行结果(无法完成,开始聊天):
请提供更具体的信息,例如:
* **操作系统:** 您使用的是 Windows, macOS, 还是 Linux?
* **您想在哪里查看文件数量?** 是在命令行 (Terminal/CMD) 还是在文件管理器中?
因为不同的操作系统和方法,查看文件数量的命令和操作方式会不同。
例如:
* **在 Linux/macOS 命令行中使用 `ls` 和 `wc` 命令:**
```bash
ls -l | grep -v ^d | wc -l
```
这个命令会列出当前目录下的所有文件 (不包括目录),并统计它们的数量。
* **在 Windows 命令行中使用 `dir` 和 `find` 命令:**
```cmd
dir /a-d | find /c "<DIR>"
```
这个命令会列出当前目录下的所有文件,并统计它们的数量。
一旦您提供了更多信息,我可以给出更准确的答案。
使用MCP加载工具之后
# llm.py
from agents import Agent, Runner
from agents.mcp import MCPServerStdio
async def run():
async with MCPServerStdio(
name="基于stdio的mcp服务器",
params={
"command": "python",
"args": ["server.py"],
},
) as mcp_server:
agent = Agent(
name="AI助手",
instructions="使用合适的工具,生成合适的响应",
mcp_servers=[mcp_server, ]
)
result = await Runner.run(agent, '当前目录有几个文件?')
print(result.final_output)
if __name__ == '__main__':
import asyncio
asyncio.run(run())
为了使用MCP,这里改用异步写法,对于Agent来说和之前相比只是多了一个mcp_servers参数
agent = Agent(
name="AI助手",
instructions="使用合适的工具,生成合适的响应",
++ mcp_servers=[mcp_server, ]
)
执行结果(调用工具完成任务,并输出结果):
Processing request of type ListToolsRequest
Processing request of type CallToolRequest
当前目录有 4 个文件。
实际上,我对Server能力中的资源、提示词还不太了解,鉴权也没有尝试。还有很多细节内容比如:错误处理、进度跟踪、接口测试等,都没有深入。
今天先写个快速入门,后面有新收获会再进行分享。
相关文章
