这篇内容只想解决一个问题:现在市面上那么多大模型,在我们的工作场景中该如何选择?
这里分享一个 OpenRouter 的大模型排行榜:
https://openrouter.ai/rankings
AI爱好者对 OpenRouter 一定都不陌生,它是一个AI大模型聚合平台,汇集了来自OpenAI、Anthropic、Google、DeepSeek等众多厂商的顶尖大模型。
它的排行榜是以每个模型的 prompt and completion tokens 的总和,然后使用 GPT-4 tokenizer 进行标准化后来做比较。
啥意思?
prompt and completion tokens 就是用户输入给模型的提示词token数 和 大模型生成回复的token数的总和。
那么这个 token数的计算统一使用 GPT-4 tokenizer,它是一种计算token的统一标准。
下图就是 GPT-4 tokenizer,输入任何内容就可以显示出对应的token数。
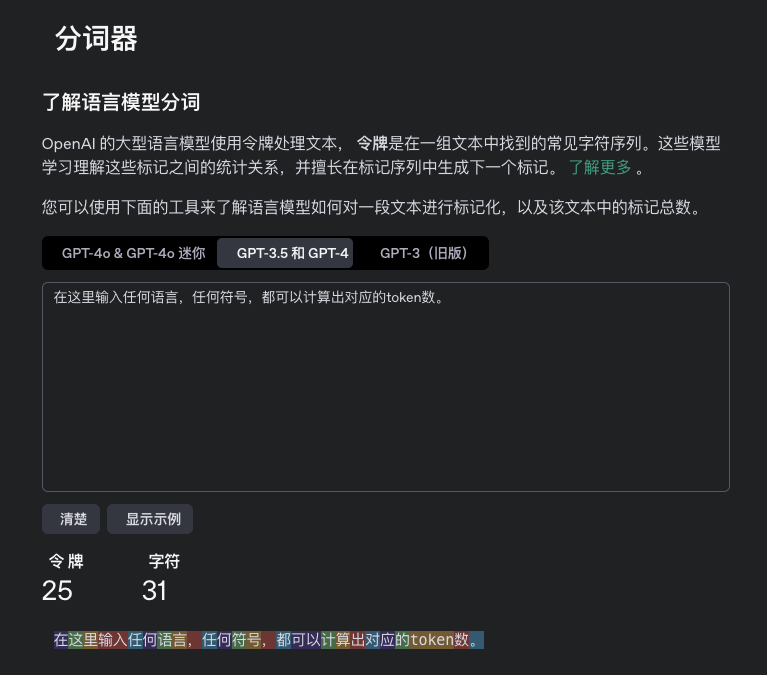
网址:https://platform.openai.com/tokenizer
并且 OpenRouter 排行榜的统计数据每10分钟就更新一次,
这么做实际上就是为了保证公平性。
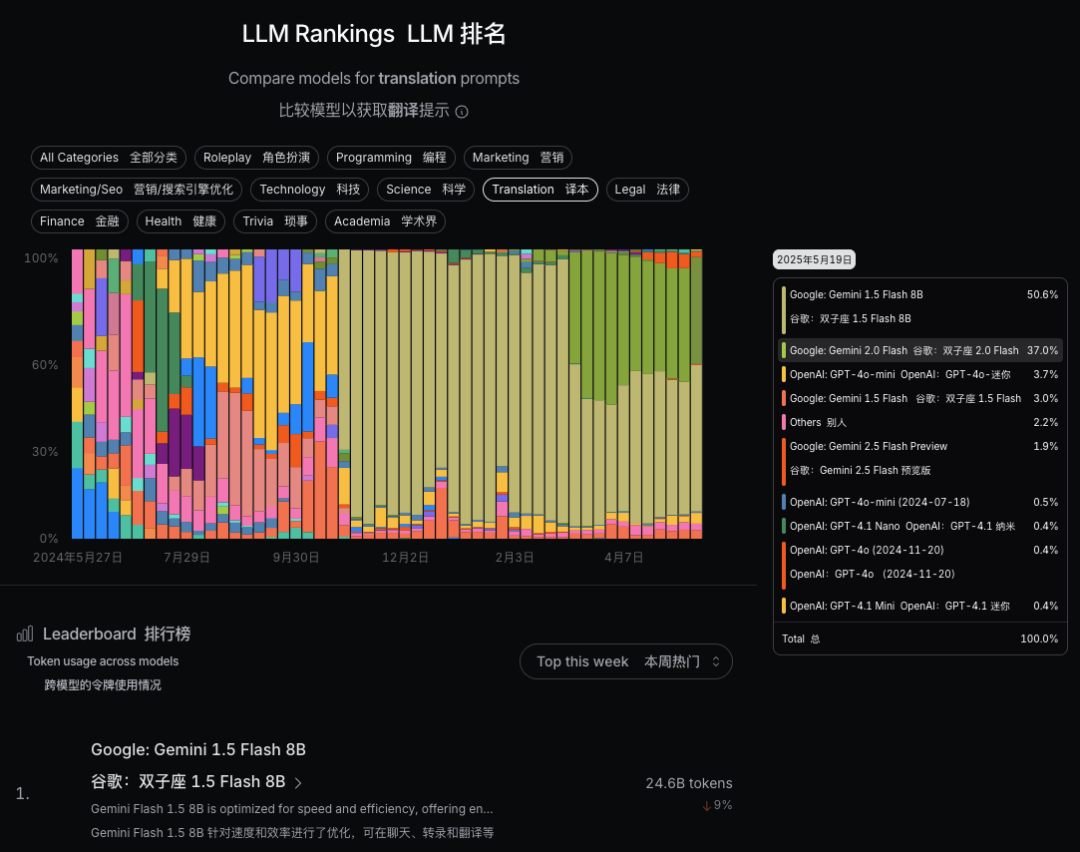
下面我们看一下这个排行榜,做了13个使用场景分类。
柱状图可以清晰地展示不同模型的使用占比。
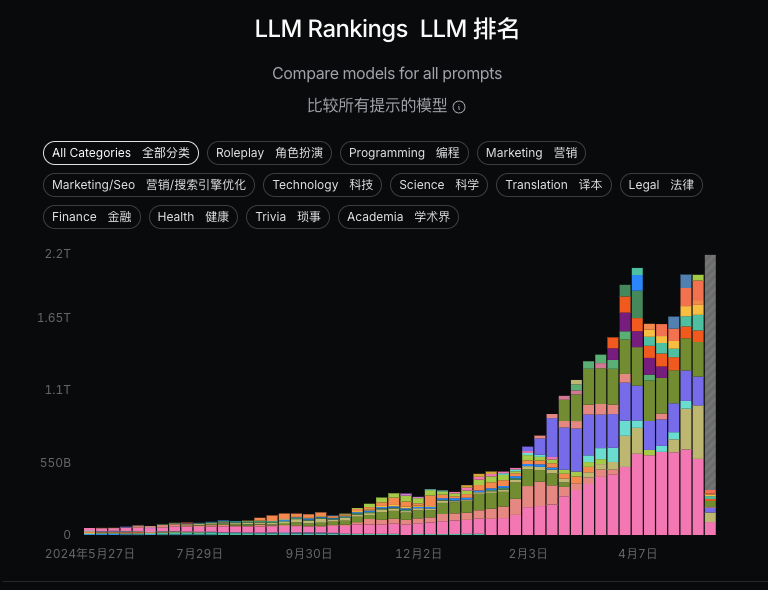
注意,它并非是大模型性能排名,而是大模型token使用量排名。
可以看到在各个领域,大家更愿意使用哪款大模型,以及使用量的变化情况。
比方说在 编程(Programming)领域,被使用最多的不是 Claude-3.7-sonnet,也不是刚刚登基的新王 Gemini-2.5-pro,而是 GPT-4o-mini,因为在用户的真实使用场景中,并不一定是哪个模型最强就用哪个,还要考虑价格、使用便利程度、场景适用度等因素。
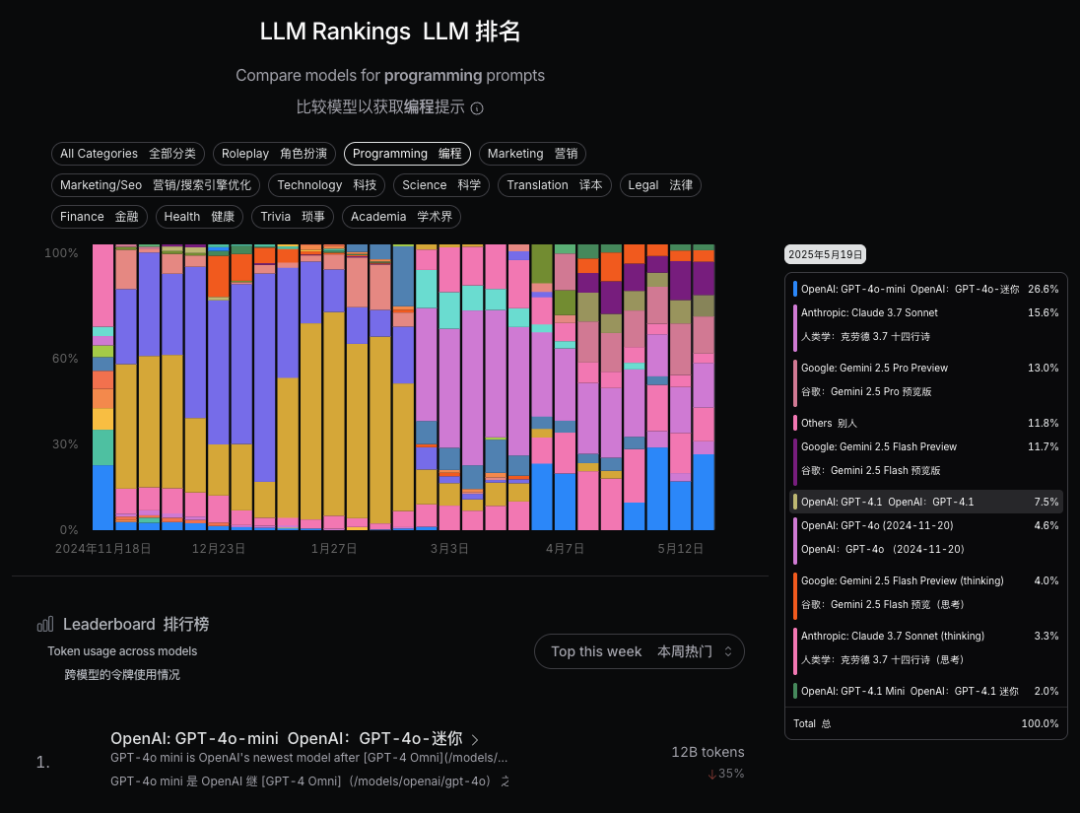
在编程领域里,主流大模型等使用情况差距不大,但是如果我们看 科技(Technology)和科学(Science)领域,GPT-4o-mini 一家独大,占了88.5%,
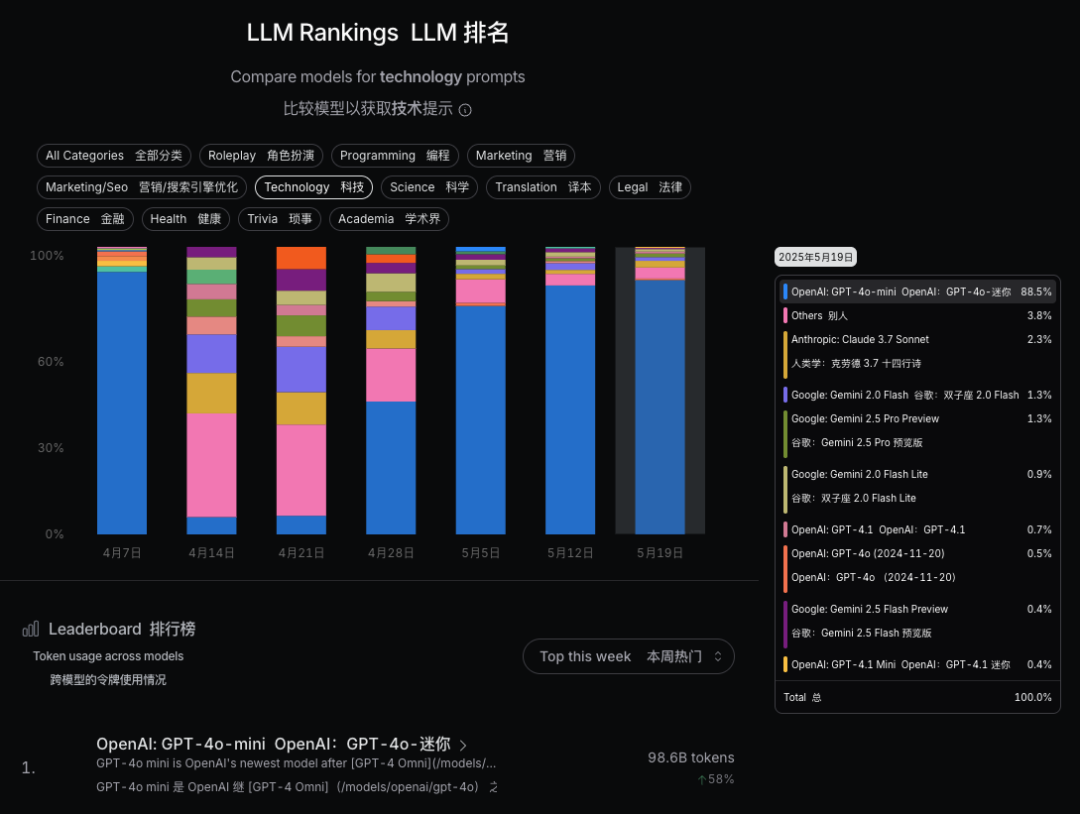
那如果你是科学研究工作者,肯定是要优先使用 GPT-4o-mini 看看效果,再试其他的大模型。
还有在经常需要用到的 翻译(Translation)场景,可以看到 Gemini-1.5-Flash-8B 是用得最多的,最近两个月 Gemini-2.0-Flash 的使用量也在增加,大概占了40%左右。
现在各种大模型实在太多了,在自己的工作场景下选择合适的大模型,比选择性能最强的模型更有性价比。
OpenRouter LLM Rankings 在我们选择大模型时是一个很好的做参考指标。
⬇️【阅读原文】
相关文章
