兵马未动(DeepSeek R2 1200B未发),粮草先行(大厂重构智算中心算力布局)大厂已经掌握R2 1200B动向,已经提前布局!
特别注意:R2 1200B,虽然没发布,从大厂动作、外媒渲染以及算力百科多渠道信息交叉验证,综合判断可信度较高!
Deepseek R2 相比R1总参数和激活参数近似翻倍,对智算中心影响深远,头部大厂已在调兵遣将,行动起来,他们掌握更多信息,在做适应性的应对措施:
1)大厂调兵遣将:头部大厂技术VP基本本周已经完成应对R2的内部技术骨干对齐会,各大厂已经行动起来。有资源的朋友可以去找找他们的会议纪要,了解一下内容。
2)H设备大甩卖:大厂继退役A800设备之后,又把H100/H800摆上货架开始甩卖,比如江苏、四川、青海等几个省,节后出现二手设备甩卖H设备现象。
使用6~24个月内的H系列资源甩卖,价格140~180w之间,集群大小64~256台之间,验资-看货-测试-拉走,流程跟买卖房产类似,随时可交易,可拉走!
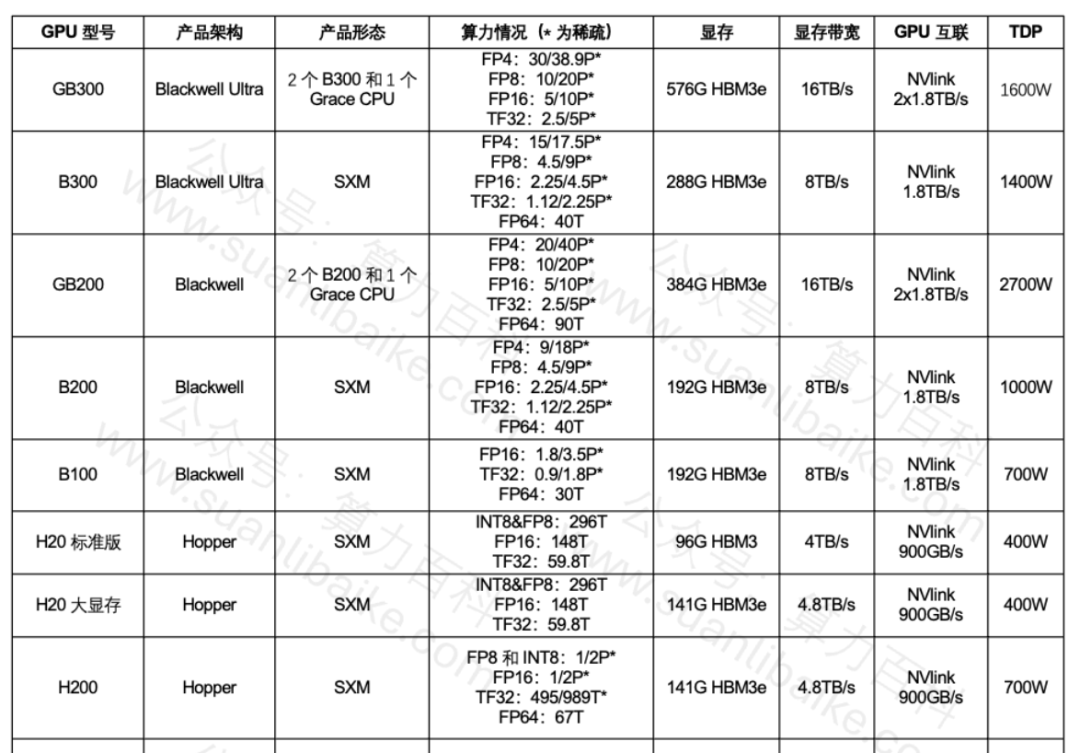
80G显存是原罪,H100/800显存80GB*8=640G显存,2台1280G显存,还是无法应对1200B原生满血版,至少要3台,瞬间没有性价比啦。
1200B R2 ,推理最好的方案,1台B200或者两台H200/H20 141G,最少也需要2台96G*8 ;
3) B系列调度行动:各大厂采购部门,本周都在密集约谈自己的御用算力供应商,商讨B系列算力资源,建设规划和供应计划;R2的绝配B200,互联网大厂技术架构师普遍认为B200和1200B是绝配的,FP8精度下192*8推理集群的性价比无敌;
4)超节点产品提前:应对R2规模参数和激活参数比R1翻倍的情况,为更好的解决多芯通信,降低延迟,算力稳定性等要求。取消PCIE接口采用板载AI节点方案成为各家选择,PCIE 成为制约全球算力产品的枷锁,加速摒弃PCIE是全球AI芯片厂商的共同心愿,英伟达推出NVLink Fusion,各国产AI芯纷纷集成2D 片上mesh,以加快摒弃PCIE的步伐;
国产AI芯片厂商都开始设计自有品牌的“超节点”方案,各大国产AI芯片已经把商用级超节点产品计划提高优先级!
超节点方案不仅仅有利于训练,用超节点做大模型推理业务,也比传统集群方案性价比更高,运营成本更低!
各个AI芯片公司都会做自己的超节点方案,超节点的好坏,绝大多数取决于AI芯片能力,其他通信芯片基本上都是采购,大差不差。
下一个周期智算中心里更换的设备是超节点,而不是只更换卡...
算力奇缺,特别是符合市场的新架构的算力《智算中心指南,算力最抢手...》
建设算力一定选择Blackwell架构(高、中、低端)都可,避免开机即淘汰的尴尬局面
《智算中心行业最新动态,大厂加速协议毁约,无人再签兜底协议...》
《过去6个月,A800算力租赁价格暴跌40%,已进入淘汰周期!》
全国首个算力和大模型工程专属服务IP
算力宝典,第二章 算力中心从入门到精通【模式篇】
相关文章