本文将为你理清头绪,建立一个基本框架,搞清楚在什么情景下用什么AI。
(本文不会讲具体工具的使用方法,也不会做技术培训,只讲思维框架)
AI是工具,但也不同于以往任何工具,善加利用,AI会表现出独一无二的自主性、智能性。
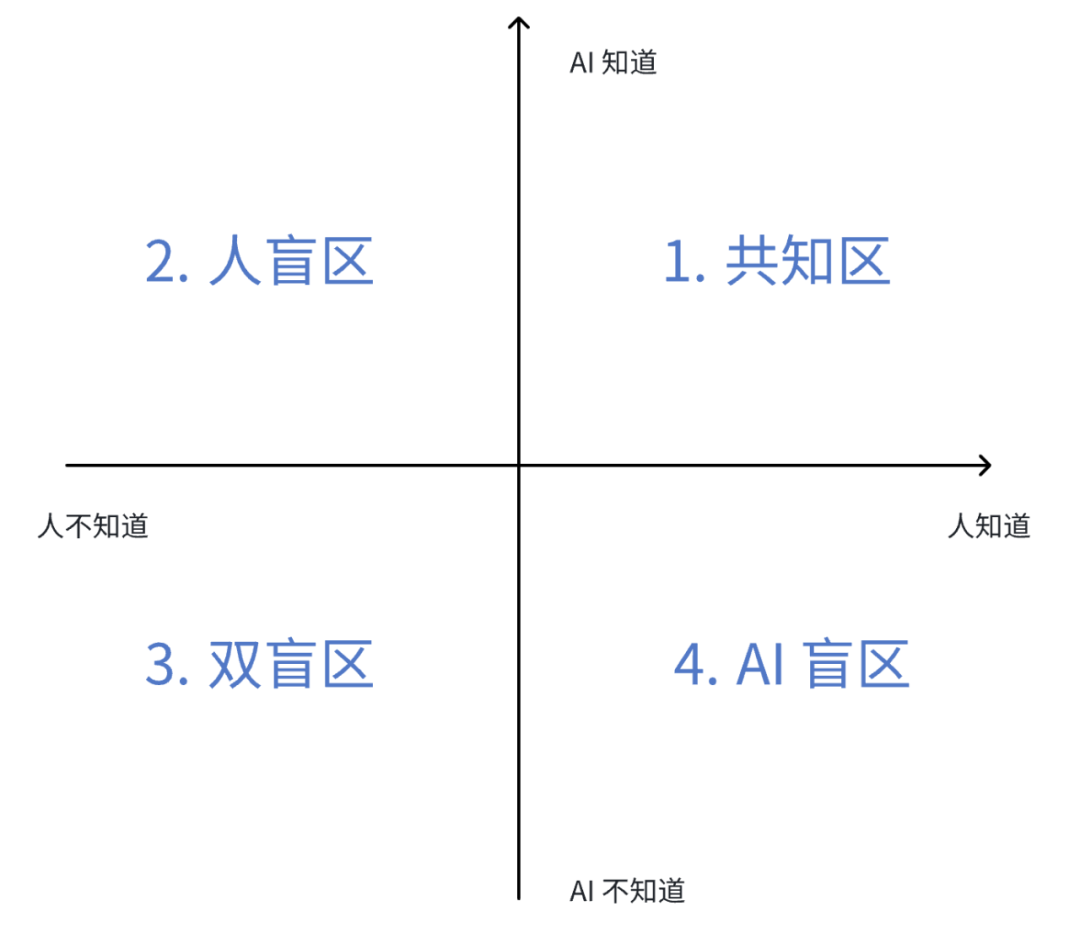
所谓 “善用”,本质上是个沟通乃至认知问题。我们先来画个象限图 (注1):
使用AI时,根据双方对谈话涉及内容(数据、信息、知识、经验)的了解程度,我们可以得到4种沟通语境:
-
-
-
-
身处不同语境区域,当然要遵循不同的沟通原则与方法。
第一象限的特点是:人与AI能够共享明确、透明的信息。
那么企业场景里,有哪些是AI和人都能获取到的信息?无外乎:
-
-
内部:文档与企业数据(财务、运营、营销.....)
显然,对于双方都知道的内容,去“考问”AI 是否知道只能算是猎奇性的举动,并不能产生额外的收益。
这个区域最适合“偷懒”型应用,也就是用AI当助理,帮你提效。
就是某项工作,人也能做,但是重复、繁琐、耗费大量时间精力、低附加值。
需要一个任劳任怨、不知疲倦的助手,而这正是拥有强大算力的AI所擅长的工作。
• 数据库数据查询(前提是AI可以访问数据库接口)出报表
-
数据质量,对于AI大模型而言,依旧是garbage-in-garbage-out,所以提供给AI的数据要做到全面、准确、及时更新;
-
数据获取,即企业是否将内部信息“包装”得当(比如数据库接口是否开放,内部服务是否有类似MCP协议封装),总之,要能让AI从容获取访问。
第二象限的特点是:AI掌握的数据或能力,超出了人的认知范围。
面对一个“无所不知”的强大 AI ,当然应该把它用作老师,而且真正是随叫随到、诲人不倦。
比如门外汉的你,想投资光伏电站,那么让DeepSeek为你基于PEST框架快速描述一下该行业,并给出最新发展动向等等,会比找人问或者自己查快捷得多。
再比如,你不懂编程,但是有个很好的创意想要做一款App,那么大可不必上来就花钱建团队,可以先借助cursor这样的AI编程工具,快速实现产品原型,验证一下用户反馈。
这个区域还适合用AI做 “检察官”,AI 可以事无巨细、铁面无私地查找人类的疏漏或是没有意识到的地方,避免主观偏见,比如:
-
用豆包对文章稿件做有条件的润色,调整修改不通顺的地方
-
-
搭建工作流,从大量的工作任务单中排查冲突点、遗漏点
当然,本象限运用AI有个大问题:就是AI的答案是否可信?
我们都知道,AI是有幻觉和不确定性的,那么如何通过工程化手段,让AI回答的内容尽可能正确且有据可查,是这一象限落地应用的关键。
第三象限的特点是:人与AI都不知道的、尚未发现的能力
比起前两个象限,这个区域适合创作、预测或是科研探索类的应用。
对于文娱创意类企业,可以充分利用AI的“幻觉”,比如给deepseek一个标题,让它发挥想象创意,写科幻小说;设计提示词文生图或视频(不存在的虚拟世界)
除了创作,还可以利用推理模型的能力,通过提供海量数据,让大模型在数据中发现问题,预测潜在风险,诸如:
很多预测场景除了语言大模型,还需要用到机器/深度学习模型。
科研探索的应用会相对更多,比如Alphafold预测未知蛋白质结构,NASA用AI发现新的星系。
企业在双盲区,可以充分利用AI的探索能力,激发人的创意、拓展思路,比如:
-
-
利用AI头脑风暴,实现组合式、跨界创新,由于没有人那么多经验桎梏,AI的脑洞很大,有时可以提出意想不到的创新idea。
双盲区的AI应用要点主要在于:别让人类的局限性限制AI发挥,另外高质量的提示词也是激发模型能力的关键。
第四象限的特点是:这里的数据和信息AI无法直接获取,比如很多企业私域知识、行业垂直领域know how,通用的大模型都是无从知晓的,你直接去问AI模型私域知识,很可能会收获一大篇一本正经的胡说八道。
在AI盲区,你是无法与其有效沟通的。与人盲区正相反,这里我们人类是AI的老师,我们要把它当成小孩子,想方设法的给他“喂”数据。
联系前面提到的共知区象限,企业内部数据如果“不干净”或者AI难以直接访问,那你以为的共知实际上就是AI的盲区。
这时我们就需要数据清洗、用RAG知识库或者微调大模型的方式,让私域知识面向AI开放,将AI盲区转化为共知区。
?
AI 盲区关键词:知识库、微调➡️缩小盲区,扩大共知区。
企业用好AI的核心是沟通。在恰当的场景使用恰当的AI能力,才能收获相应的价值。
1️⃣ 共知区(助理提效):处理重复工作,需保障数据质量与访问。
2️⃣ 人盲区(老师查漏):AI辅助决策,警惕幻觉风险。
3️⃣ 双盲区(创意探索):激发创新预测,优化提示词。
4️⃣ AI盲区(知识转化):清洗数据或微调模型,变私域为共享。
希望越来越多的企业都能善用AI,有任何AI大模型落地应用的问题也欢迎找我交流、探讨。
注1:文中提到的四象限,引用自 乔·哈里窗口(Johari Window),是一种关于沟通和自我认知的理论模型,由美国心理学家约瑟夫·卢夫特(Joseph Luft)和哈里·英格拉姆(Harry Ingham)在20世纪50年代提出。它通过将人际沟通的信息划分为四个区域,帮助人们更好地理解自己与他人的互动关系,并改善沟通效果。
-
-
特点:这是沟通中最直接、最透明的区域。例如,你的姓名、职业、部分经历、兴趣爱好等。
-
-
示例:在职场中,通过自我介绍或日常交流,同事之间会逐渐了解彼此的基本信息。
-
-
特点:这是个人保留的秘密或未分享的部分。例如,个人的感受、秘密、隐私、某些想法等。
-
作用:适度保留隐秘区是正常的,但过度隐藏可能导致他人误解或关系疏远。
-
示例:一个人可能隐瞒自己对某项工作的不满,直到压力积累到无法承受。
-
-
特点:这些可能是他人的反馈中发现的盲点,例如性格缺陷、习惯性行为或他人对自己的看法。
-
作用:盲目区越大,越容易陷入“自我认知偏差”。通过接受他人反馈可以缩小这一区域。
-
示例:一个领导可能认为自己很亲和,但下属却觉得他过于严厉。
-
-
特点:这是未被开发的潜能或尚未被发现的能力。例如,潜在的才能、未知的情绪反应或隐藏的疾病。
-
-
示例:一个人可能从未意识到自己擅长演讲,直到在一次活动中意外表现出色。
相关文章