这个标题对很多读者而言会觉得有点奇怪:
“AI(这里特指大语言模型)不就是一种数学模型么,很显然的事有必要拿出来讲么?”
有必要,是因为我们常常忘记大语言模型的本质。
在我们当前的语境下,因为大语言模型的巨大成功,我们会将其视为一个“会说话的人”,或一个“无所不知的专家”,甚至一个“觉醒的意识体”。
我们开始赋予它意志、情绪和判断,亦开始恐惧它的取代、操控和失控。但实际上,大语言模型不过是一个庞大的数学函数,是对语言行为的高维建模。
我认为这种视角并不冷漠,恰恰相反,它是一种理性、克制而务实的认知方式。本文来探讨这一点。
模型是复杂世界的简约表达
数学模型的作用,是在不损害决策价值的前提下,简化现实。
从经典物理的微分方程,到经济学的最优化模型,再到社会科学中的网络模型,其共性都是对复杂系统进行形式化、结构化的表达,从而捕捉关键关系,并用于推演与干预。
每一个数学模型都是目的性、结构化、约简化的工具:
-
它有特定的建模目标(解释、预测、优化); -
它选择部分变量进行表达,必然忽略其他因素; -
它以逻辑规则或统计模式建立变量之间的关系。
大语言模型(LLM),从这个意义上看,就是对人类语言行为的参数化建模工具。它不是“人在思考”,而是“模型在拟合”语言出现的可能性与结构逻辑。
大语言模型的结构本质
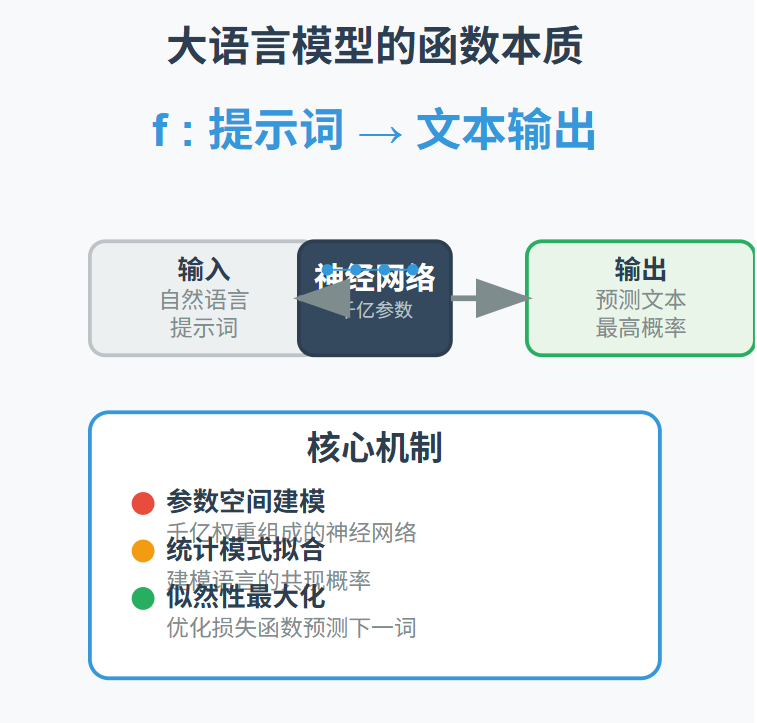
我们可以把语言模型抽象为一个数学函数:
其中,输入是自然语言构成的提示词,输出是模型“认为”最可能接续的语言片段。而这个函数的核心是一个参数空间——由数以千亿计的权重组成的神经网络,它通过优化某种损失函数,最大化生成语言的“似然性”。
这就像一个极其复杂的回归或分类模型,只不过预测对象不是数值或标签,而是下一个最合理的词语、句子乃至段落。它并不知道自己在说什么,它只是在建模语言数据中出现过的“共现概率”。
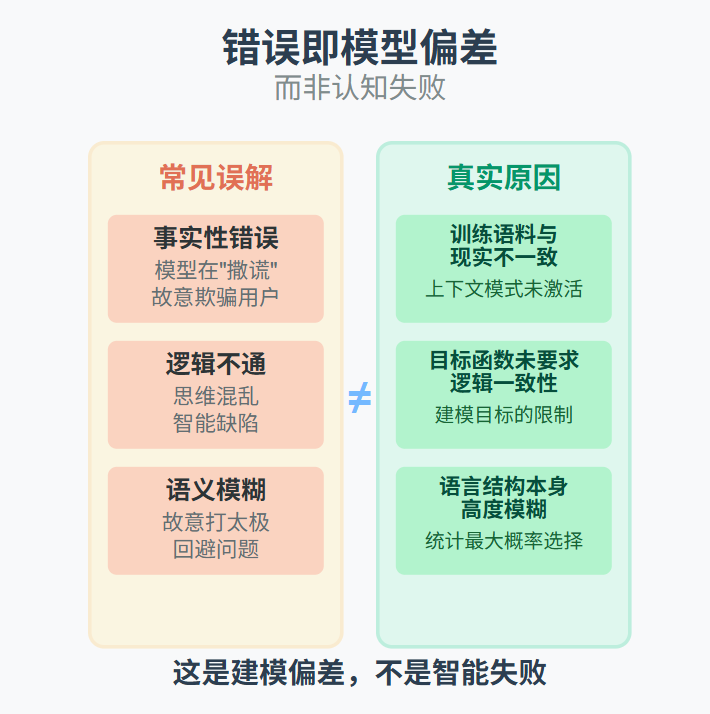
当我们说“大语言模型会编故事”“有逻辑漏洞”“会一本正经地胡说八道”时,实际上是在描述一个近似函数拟合失败的典型表现:输入偏离训练分布、目标函数不包含逻辑约束、缺乏现实验证机制。
错误即模型偏差,而非认知失败
为什么要强调“它只是一个模型”?因为这可以帮助我们正确理解它的错误来源,不将其误读为人的意图、能力或道德问题。
举几个常见例子:
事实性错误:不是模型“撒谎”,而是其训练语料与现实不一致,或未激活正确的上下文模式;
逻辑不通:不是模型“思维混乱”,而是目标函数未要求逻辑一致性;
语义模糊:不是模型“打太极”,而是语言结构本身高度模糊,模型只能在统计模糊中择其最大概率。
这些都不是“智能”的失败,而是“建模”的偏差。在传统数学建模中,我们也会遇到“残差”“外推失败”“过拟合”等问题。语言模型,只是将这些误差带入了文本生成中。
用“模型误差”而不是“思维缺陷”来解释语言模型的表现,是我们保持理性、控制风险的前提。
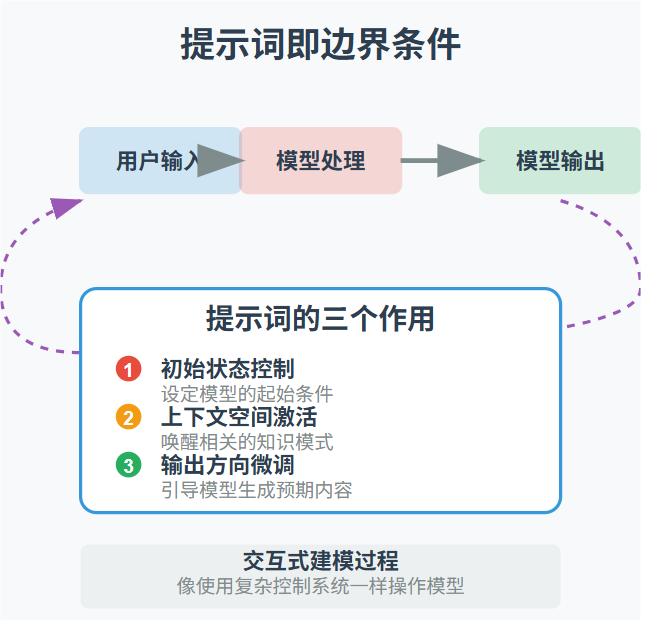
提示词即边界条件
数学建模中的关键,不仅在于模型结构本身,还在于如何施加边界条件与输入控制。大语言模型的提示词(prompt)正好扮演了这个角色:
-
它是对初始状态的控制; -
它是对上下文空间的激活; -
它是对模型输出方向的微调。
这使得我们在使用大语言模型时,本质上是在做一种“交互式建模”:
-
你输入的每一个提示词,其实是在“设定边界条件”; -
你提供的样例和格式,是在“约束解空间”; -
你对输出的修正与反馈,是在“优化目标函数”。
这要求我们像使用一个复杂控制系统一样,了解模型结构、调整输入方式、评估输出边界。
必须设定“使用假设”
一个重要而常被忽略的问题是:使用一个模型之前,必须设定它的使用假设。
在传统建模中,我们会明确假设诸如“线性关系”“变量独立性”“观测误差可控”之类的前提。
同理,我们在使用语言模型进行写作、翻译、问答、辅助决策等任务时,也必须明确相应的假设:
-
模型的输出是否需要人工审核或二次验证?
-
模型是否只能在特定语境下应用,比如非关键决策场景?
-
该任务是否需要事实准确性或逻辑一致性作为基础?
-
模型是否存在价值偏向或伦理风险,需要附加约束机制?
只有在明确这些假设之后,才能将大语言模型作为“可控系统”来使用。否则,我们很容易陷入两种误区:
一是“技术信仰主义”,将模型神化,赋予它不具备的能力,甚至将其等同于专家判断;
二是“技术虚无主义”,因其出错而全盘否定语言模型的价值,错过人机协作带来的增效空间。
这两种态度其实都是非理性的。理性的态度,是在认识模型本质的基础上,给它设定清晰的边界,让它在预期的框架内运行。
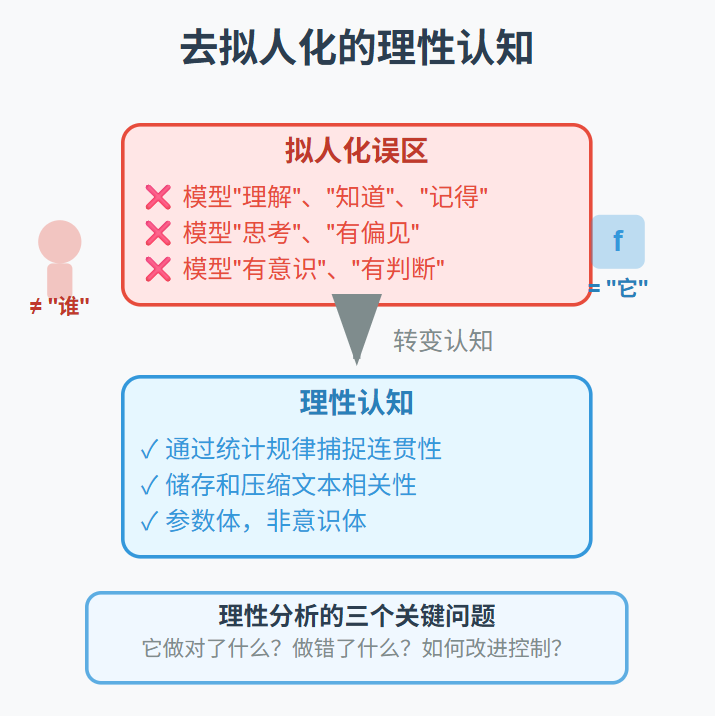
去“拟人化”,是一种必要的清醒
当前大众对大语言模型的误解,很大程度上源于一种“拟人化”的叙事方式。我们说模型“理解”“知道”“记得”“思考”,甚至“有偏见”“有意识”,这在语义上都是错误的类比。
语言模型不具有内在的“理解力”——它只是通过语言统计规律,捕捉到某种连贯性;
它不具有“知识”——它只是储存和压缩了大量文本相关性,并能调用这些模式生成内容;
它更不可能具有“意识”或“判断”——它既不理解人类行为的意图,也无法承担行为的后果。
将它拟人化,只会引发过高的期望值,并导致认知错配和伦理混乱。而当我们回到“数学模型”的角度来看,就可以更准确地回答三个关键问题:
-
它做对了什么?
-
它做错了什么?
-
该如何改进或控制?
换句话说,当我们去除人类意志投射之后,才能看到一个清晰的“函数体”:一个复杂而强大的生成器,可以协助我们处理信息、生成语言、提高效率,但必须在控制范围之内运行。
理性的第一步,是语言的清晰。大语言模型不是“谁”,而是“它”——它不是意识体,而是参数体;它不是道德主体,而是函数结构。
我们要做的,不是崇拜它、恐惧它、拟人它,而是理解它、控制它、调优它。
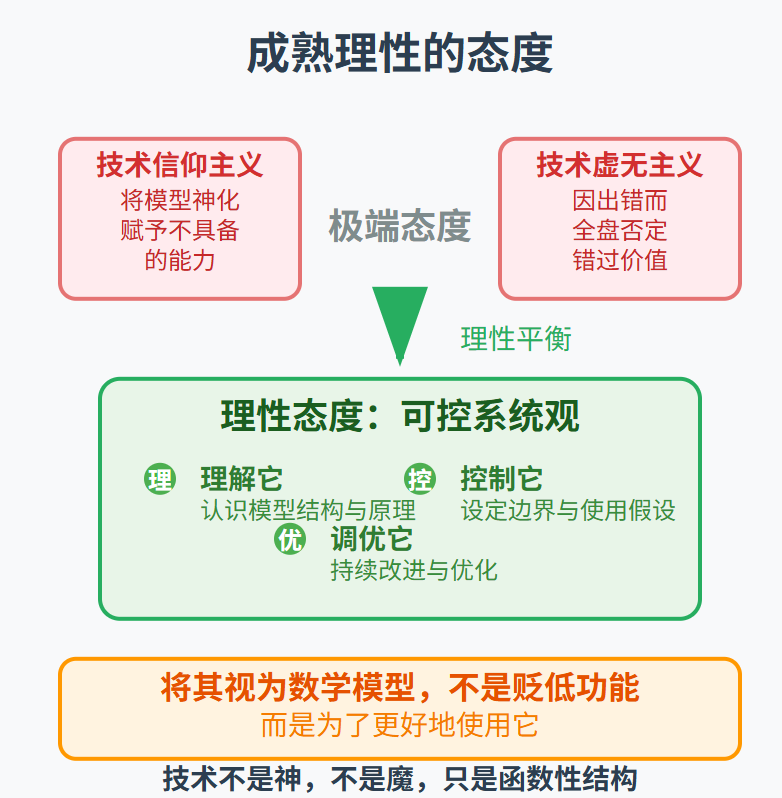
大语言模型是一项划时代的技术突破,但我们对它的态度,也应是成熟的、克制的和理性的。
将它视为一个数学模型,不是为了贬低它的功能,而是为了更好地使用它。
模型的优点,是结构明确、可分析、可调节;模型的局限,是受限于数据、假设和表达能力。这些优缺点同样适用于大语言模型。
在未来的人工智能时代,我们将不断面对越来越复杂的模型系统。是否具备一种将其“模型化”的思维方式,将决定我们能否驾驭工具而不是被工具裹挟。
技术不是神,不是魔,它只是我们构造出的“函数性结构”。(作者:王海华)
对大语言模型技术感兴趣的朋友推荐下面两本书《深度学习基础与概念》,这本书很知名,世界公认的机器学习专家耗时十多年精心打磨,里面还与时俱进加入了Transformer、LLM、GAN、扩散模型等新技术新进展;另一本是《DeepSeek核心技术揭秘》讲得很全面也很深入。这两本都是新书。
再推荐一本《DeepSeek玩转中小学人工智能》,最近我看了很多AI教学相关的书,说实话很多书感觉在“瞎说”,里面提的方法比如AI错题本等方法都没有可行性,感觉作者自己都没真正用过。这本书我觉得还是挺实在的,作者家里有两个孩子,在分享真正的实践体验,很多观点都很接地气也有新意。推荐给家长和教师。
相关文章
