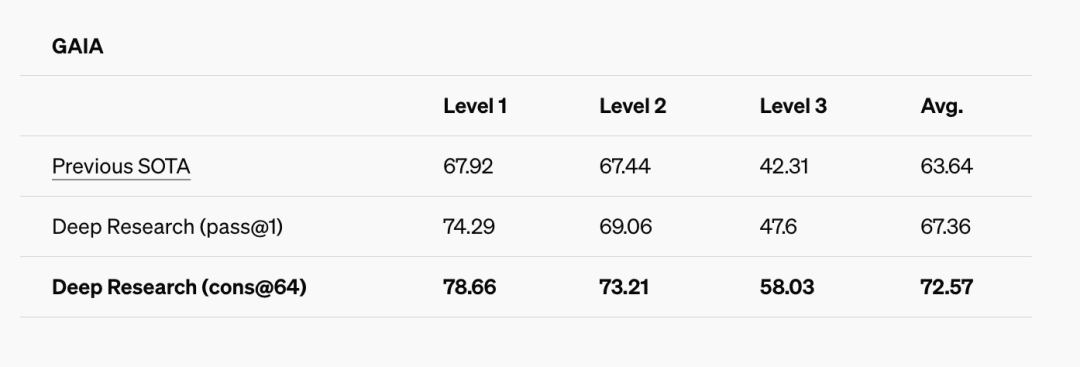
在这个测试中,会发现 Open Research 取得了较为不错的成绩,在 pass@1 和 cons@64 的标准下,均取得了比以往更好的成绩。这里做一个信息的补充,有关 pass@1 以及 cons@64:
-
pass@1:AI 在首次尝试时直接给出正确答案的概率,可以用来衡量一个 AI 是否直接可用
-
cons@64:这是 AI 在 生成 64 个答案后,正确答案出现在这 64 个答案中的概率,可以用来评估 AI 的覆盖率和潜力
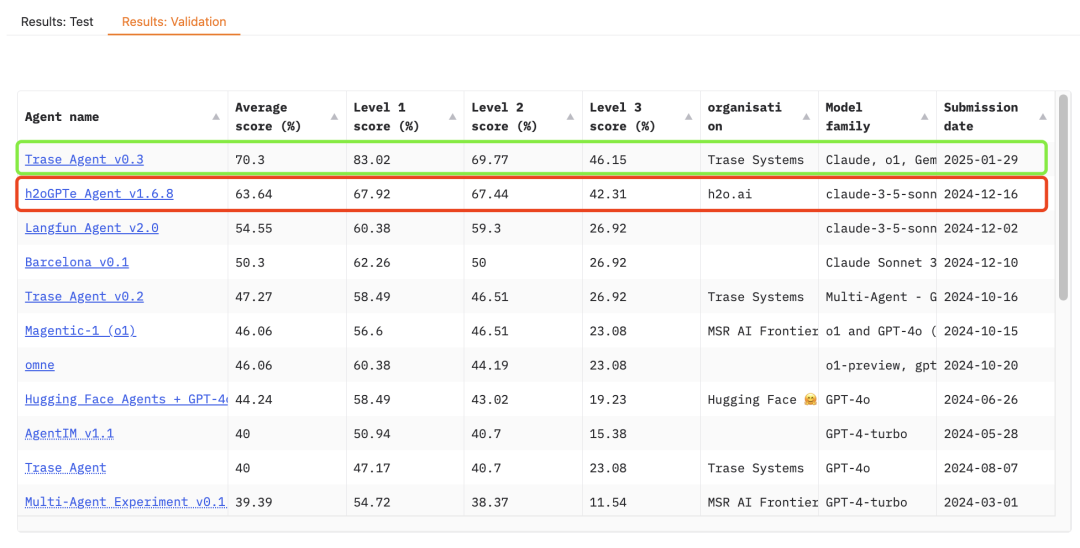
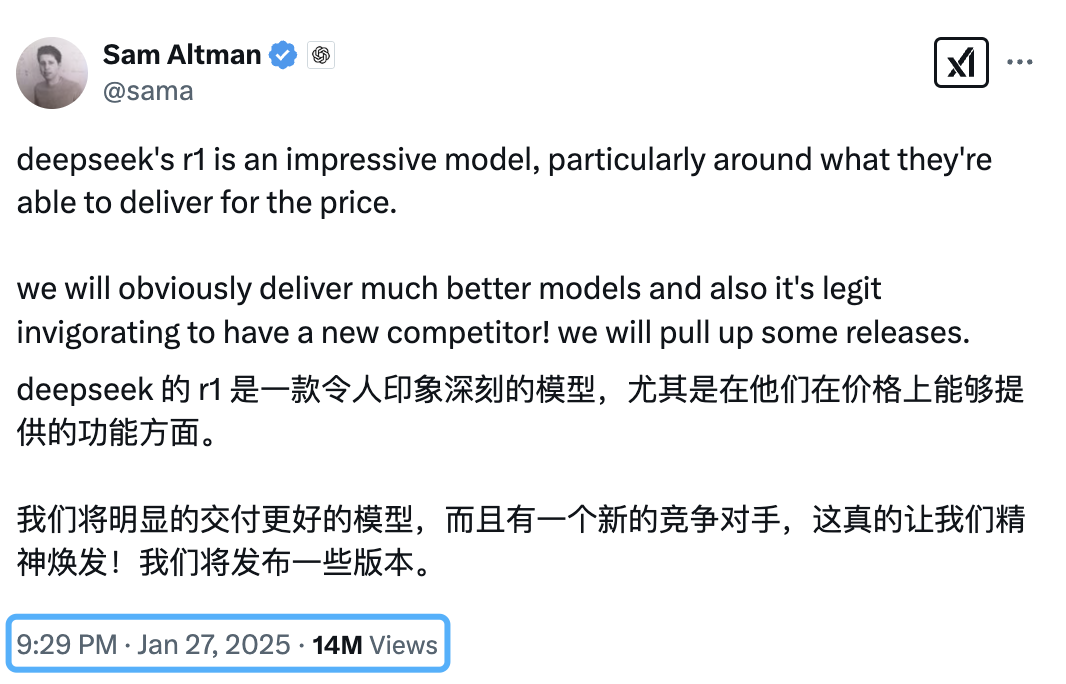
可以发现,OpenAI 发布的“以往最佳”的成绩,是 h2o 做到的,记录时间为 24年12月16日。而更新的记录则是由 Trase Systems 于 1月29日(大年初一) 发布的。也就是说,OpenAI 应该在 1月29号之前就 Ready 了这个项目。哈哈~刚好和奥特曼的 Twitter 对应上了:
对于「例子3」,ahhhhhh,我希望 用 Deep Research 来「写一篇有关 OpenAI Deep Research 的报告,你的目标受众是 AI 从业者、投资人和相关研究人员」
5分钟后,获得了这么一份报告:

可上下滑动
大家可以来评一评这篇报告:
-
觉得写得好,请在评论区,夸我是个大聪明;
-
觉得写得烂,请在评论区,骂 OpenAI 是个大聪明
实际上,这是 Deep Research 的第 4 次输出:在前三次中,它的输出堪称「胡说八道,离题万里」:

而在第四次中,我重新修改了提示词,加上了一些背景介绍,并且重复测试了2次,才获得较为满意的结果。这是我在第四次中,用到的提示词:「就在刚刚,OpenAI 新出了一个功能,叫做「Deep Research」,那么请你就「OpenAI Deep Research」写一篇分析报告,你的目标受众是 AI 从业者、投资人和相关研究人员」
通过上面的几个例子,发现这次 OpenAI 的发布确实可圈可点,上限很高。但在实际的体验中,也蕴藏着一些问题,包括不仅限于:
-
非常不稳定
-
如果任务没有被描述的非常清楚,它的理解&执行可能会有比较大的偏差,就比如 OpenAI Deep Research 报告(你并无机会在中途修正)
-
任务一旦开始,就无法人工干预(包括提前结束)
-
无法读取用户提供的链接(至少不读取公众号链接)
-
限额过于低:即便是 Pro 用户,每个月也只有 100 次的额度
-
...
对于限额问题,官方也说到:“All paid users will soon get significantly higher rate limits when we release a faster, more cost-effective version of deep research powered by a smaller model that still provides high quality results.”
翻译成中文,便是:“很快,我们会推出一款更省算力的小模型,给 Deep Research 来用,那时,所有的付费用户都可以有更多的使用额度了。”
一时不知是喜是忧。
既然:
OpenAI 已经发布了 Deep Research
那么:
DeepSeek 何时发布 Open Research
相关文章
