
导读 本次分享题目为 OpenLake 面向 AI 时代的数据基础设施演进。
1. 背景介绍
2. 数据湖基础设施的演进
3. DLF 数据湖平台:OpenLake 的存储底座
4. DLF 数据湖平台:多模态数据湖
分享嘉宾|李劲松 阿里云 高级技术专家
编辑整理|永铮
内容校对|李瑶
出品社区|DataFun
01
背景介绍
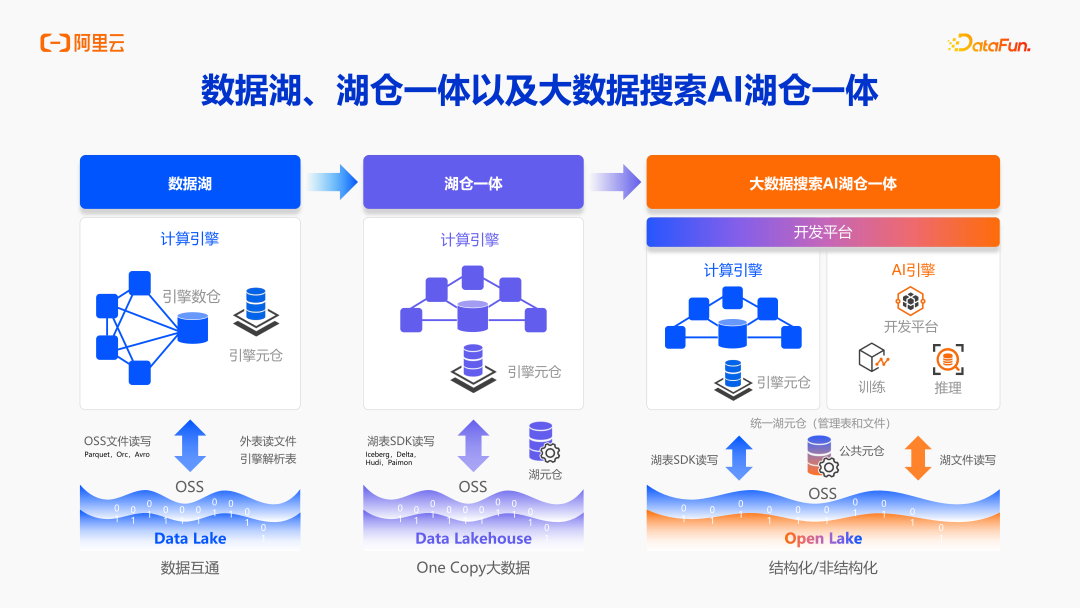
当今主要数据趋势,是从数据湖和数据仓库,融合到湖仓一体架构,包含计算引擎、元仓、统一的湖格式存储和统一对象存储 OSS。目前业界发展方向,不只是数据湖仓,而是更进一步的将 AI 数据、搜索数据等,都统一在一个更大的数据湖仓中,包括表和文件的统一管理、统一元数据体系、统一存储体系等。
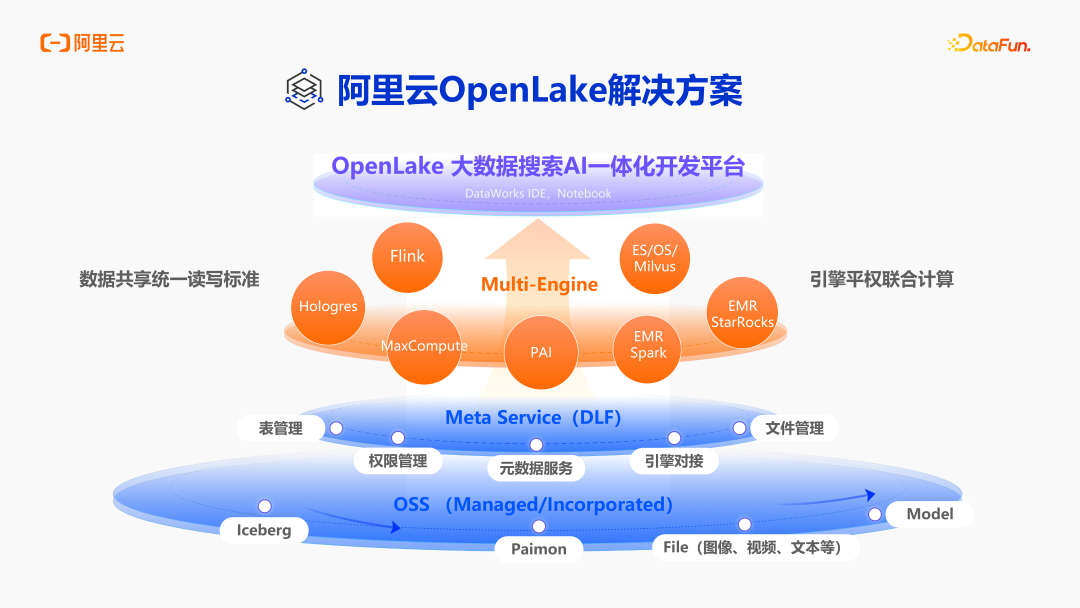
阿里云 OpenLake 解决方案定位大数据搜索 AI 一体化的开发平台,集成了众多引擎,包括自研的 Hologres、MaxCompute,开源的 Flink、Spark、StarRocks 等。OpenLake 想要打造一个基于统一元数据、统一存储的计算引擎平权的联合计算架构。计算平台主要的湖格式是 Paimon 和 Iceberg,并基于此实现了对图像、视频、文本、机器学模型等内容的管理。接下来我就和大家分享一下数据湖基础设施的演进。
02
数据湖基础设施的演进
Hive 格式,是一个 Shared File Storage for Batch Processing。Hive 存储的核心不是对数据具体的文件进行管理,而是对文件夹进行管理,比如分区有文件夹、表有文件夹,然后文件夹里面包含着 ORC、Parquet、CSV、JSON 类似的文件,Hive 通过 List 文件夹的方式来读取表中内容。所以,Hive 整体的管理是非常松散的,这也导致它的架构非常简单,处理过程也比较简单,但也导致了它对数据的处理能力非常缺失,只能完成一些非常基础的动作。常用的 Insert Overwrite,Hive 只能对它进行 Overwrite 复写,不能通过 Insert Into 增加一部分文件。Hive 的一致性保障是非常差。2019-2020 年,Iceberg 社区在快速的发展,它就聚焦 Hive 不管理文件的问题,所以 Iceberg 这样的数据湖格式,也包括 Delta Lake、Paimon,都会管理文件细粒度。
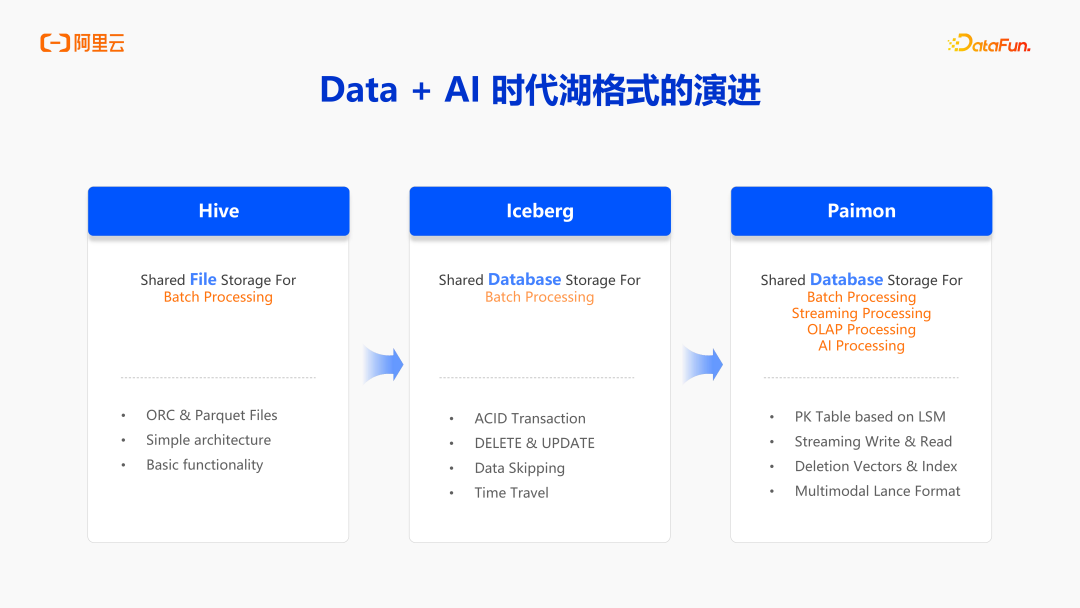
那细粒度管理起来具体有什么优势?比如说可以做 ACID Transaction,能够清楚的知道增减了多少文件。每一次 Commit 都是一个原子的操作,然后多个作业的同时Commit,也能做到冲突的检测。引入 ACID Transaction 之后最大的好处就是可以做一些细粒度的操作,比如 Delete,Update。在此之前,使用 CDC 更新的时候,只能通过全量分区加增量数据分区的方式,然后两个分区进行一个 Join 后写到一个新的分区,有了湖格式之后,整体更新就会变得更加轻量。你可以针对性地知道这次更新需要去 Rewrite 哪些文件,只需要对其做替换就可以了,生成一个新的 Snapshot 和一个新的 Commit,自然更新就会更轻量。
随着技术进一步发展,到 2022 年左右, Paimon(前身为 Flink 社区的 Flink Table Store)逐渐发展起来了,Paimon 在 Iceberg 湖格式的基础上,面向的不只是 Batch Processing,也核心增强了 Streaming Processing。追溯前面提到的更新场景,在 Iceberg 可以用 Merge Into ,或者用 Delete、Update 来更新部分数据,但依然是一个偏批式的更新,原因是 Iceberg 上的 Streaming 计算没有那么成熟。所以 Paimon 在 Iceberg 基础上核心加强了 Streaming 计算,在湖格式上支持了 Streaming 的更新和流式读取。可以把 Paimon 当做消息队列,打造流批一体架构,实现批次处理,也可以达到一个准实时的分钟级处理。除了 Streaming Processing,也核心增强了包括 OLAP Processing 和 AI Processing。基于当下这些特性,包括主键表(PK Table based on LSM)、流式写入和读取(Streaming Write&Read)、Deletion Vectors &Index,来增加流、OLAP 和 AI 场景的能力。
1. Hive 到湖格式的演化:批更新
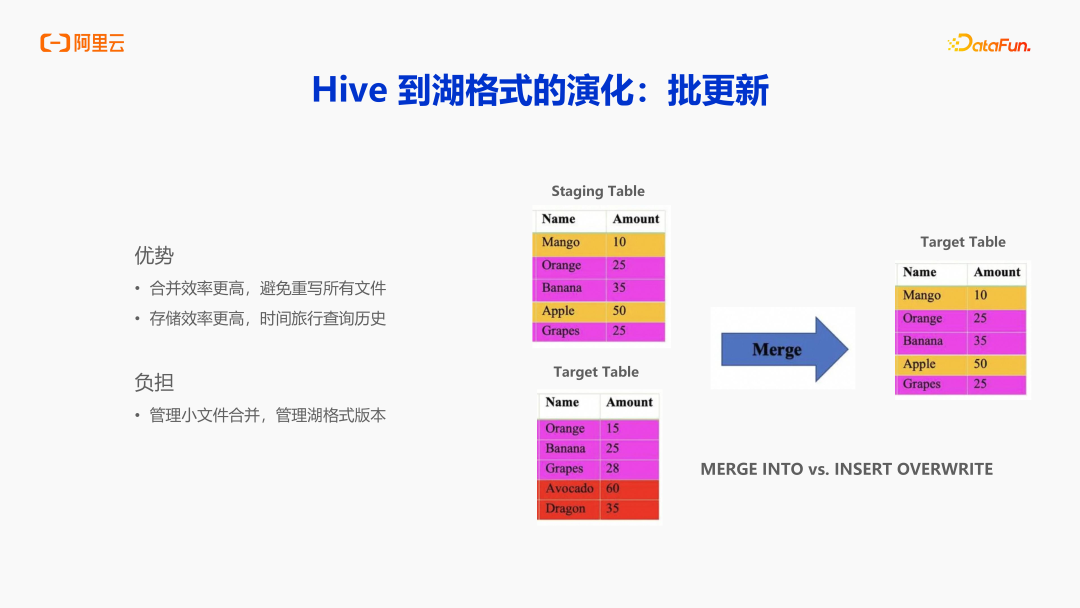
Hive 到 Iceberg 湖格式的演化,最大的变化就是批更新。在数据库场景当中,最大的诉求就是数据是带主键的,如图所示,这里的 Name 就是一个主键,核心本质诉求就是每天产生的增量数据(Staging table)Merge 到目标表中。在 Hive 中实现方式就是 Insert Overwrite,需要将 staging 表和 target 表的两个分区 Join,意味着你要读写所有的数据,会新增一个完整的副本,这样就会造成计算和存储的大量浪费。所以 Iceberg 湖格式,包括 Delta Lake、Hudi、Paimon 对业务最大的影响就是支持细粒度的 Merge Into,不需要使用 Insert Overwrite。Merge Into 语法的执行当中,它会自动检测影响了哪些文件,需要更新哪些文件,这样就可以实现更高效率的合并,避免重复读写所有文件,存储效率也会更高。可以借助湖格式的时间旅行能力,查询昨天或者前天的历史数据。所以湖格式在能替代原有 Hive 表的所有功能的同时,用更少的资源和更高的效率来完成合并。有了这些优势,湖格式也并非可以无脑的替换 Hive 表,因为湖格式本身通过细粒度的文件管理、版本管理,也带来了一些额外的负担。
这里强调一下负担,一个是湖格式本身的小文件管理,细粒度的更新可能造成比较多的小文件,如果没有做好管理或者不管理的话,对于 HDFS、Name Node 就会造成比较大的压力。也会对 OSS 对象存储,造成更大的 Cost,更慢的读取效率。另外一个就是湖格式的版本问题,需要数据使用方清晰的知道数据表有多少个版本,它就要求表的维护者把版本管理起来,做好版本淘汰动作,否则空间就会越来越大,这是无法接受的。
2. Iceberg 到 Paimon 的演化核心:流更新

如上图所示,在 Hive 演化到 Iceberg 的过程当中,把批更新通过细粒度的更新方式完成,本质还是一个天级别或者小时级别的更新。Paimon 在这上面的改进是核心增强支持了 Flink,包括从源头 Kafka 或者从 Flink CDC,流式同步到下游 Paimon 表当中。在支持的流式更新的基础上,还支持了 Schema Evolution,支持上游增加了列,下游自动增加列,并且支持一个 job 整库同步数据到下游 Paimon 表,这样的优势就是下游的 Paimon 可以实时更新、实时可见,而且同步作业是非常方便且可以自动维护的低成本的流式同步。
数据实时同步后,也带来一些新的负担。如果用过 Paimon、Iceberg 或者其他湖格式的流更新能力,你会发现非常难定义的内容——bucket,叫做桶数。需要根据数据量、数据吞吐量来定义桶数,来达到相应的性能平衡。桶数定义多了,资源消耗会非常大,合并效率也会非常低;桶数定义少了,则会造成数据消费跟不上,造成非常大的反压和数据延迟。所以挑战在于如何去定义一个合适的桶数。实时更新就需要它像 Hbase 的 LSM ,需要后台的 Compaction,如果 Compaction 发生在写入作业过程中,也有可能影响写入,并且增加资源消耗,增加调优的复杂性。
3. OpenLake 上的湖格式性能测试
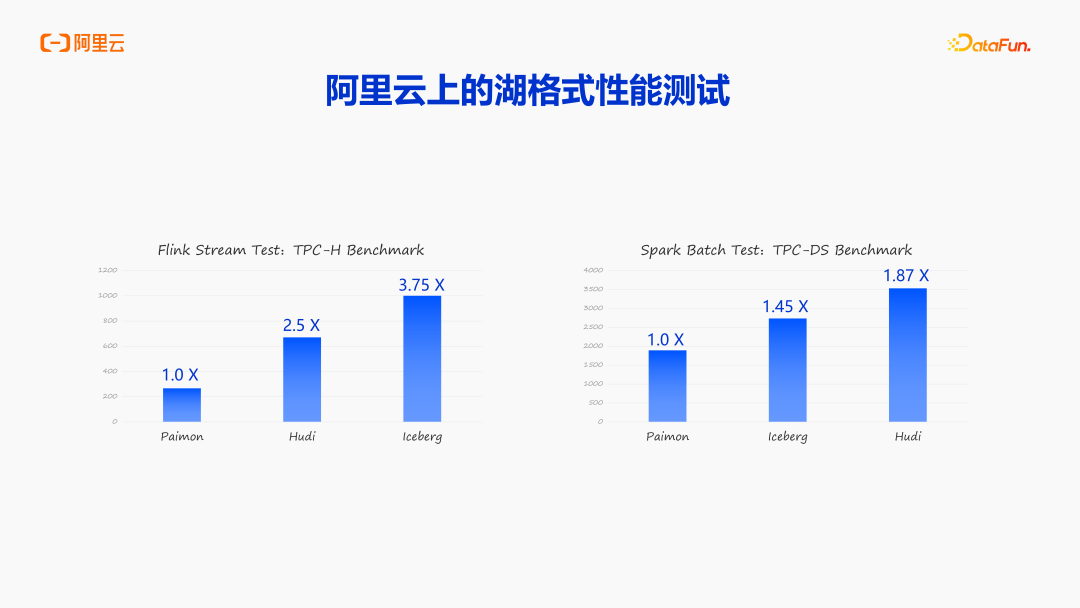
上图所示是 OpenLake 上的湖格式性能测试,其中第一组是流测试,第二组是批测试,可以看到 Paimon 在 OpenLake 上的表现,它的流更新大幅领先 Hudi 和 Iceberg,批测试的 TPC-DS Benchmark 也大幅领先 Hudi 和 Iceberg,所以在 OpenLake 上,推荐大家使用 Paimon 湖格式。
4. 数据湖时代元数据管理的演进

最后一个问题是数据库是元数据管理。刚刚讲了从 Hive 到 Iceberg 解决的最大问题是批更新,从 Iceberg 到 Paimon 解决的最大的是流更新,都聚焦在文件格式上。与此同时,还有一个非常大的问题,就是元数据管理。
在此之前,Hive MetaStore(简称 HMS)是业内的基本事实标准。HMS 是针对 Hive 设计的,与当前的湖表概念,包括 Iceberg、Delta Lake,Paimon,都有比较大的差别,权限模型绑定了 Ranger,也比较难进行统一审计、统一管理。它的元数据也基本无法理解湖表这些概念,也比较难扩展,在 HMS 上也没做到 AI 相关能力扩展。业界在方向上也有非常多的实践,包括 Snowflake 推出了 Polaris Catalog,社区推出了 Gravitino Catalog,并针对 Iceberg 的 REST API 实现了它特定的 Catalog,包括 Databricks.
开源了 Unity Catalog,Unity REST API 实现了针对 Delta 优化的一个 Catalog。
对应的 Paimon 也在 Paimon 1.1 中由 Paimon REST API 和 Catalog 提出。那么对应的元数据系统专门给 Paimon 打造的元数据系统在哪里?下面内容将围绕这个问题展开。
03
DLF 数据湖平台:OpenLake 的存储底座
了解了数据湖格式的演进过程,以及涉及到的问题之后,接下来聚焦于 DLF,也就是 OpenLake 的存储底座,它如何解决上面提到的问题?
1. Data Lake Formation 数据湖仓管理平台
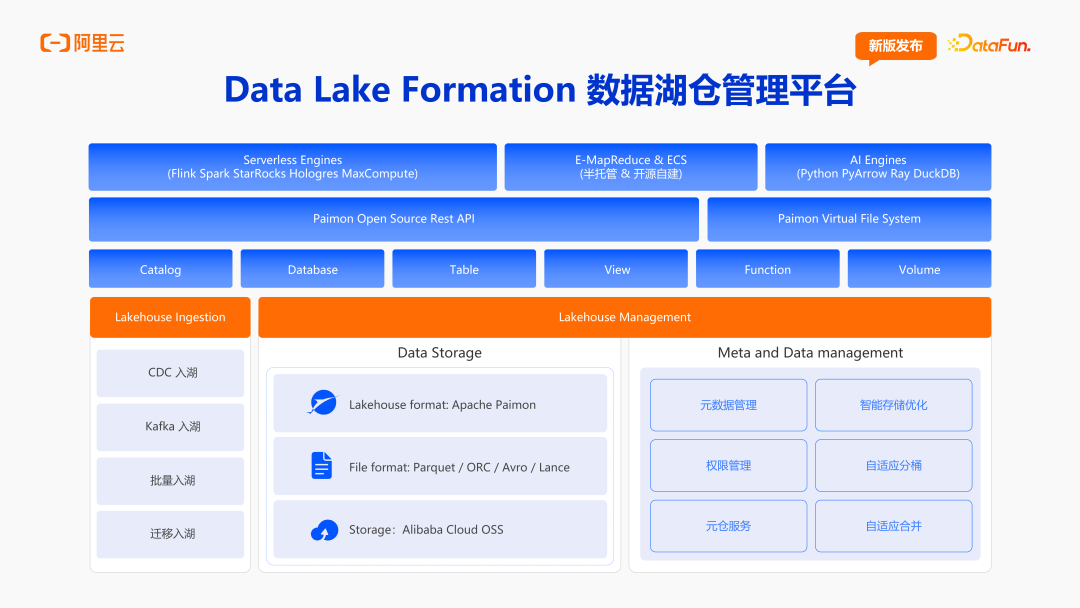
DLF(Data Lake Formation)的整体存储是建立在 OpenLake OSS 上的,上一层是 Lake Format,也就是 Apache Paimon。Paimon 支持了 Parquet、ORC、Avro 和正在集成的 Lance(Lance File Format,多模态存储结构),再往上就是各种实体,支持 Catalog、Database、Table、View、Function、Volume。DLF实现了 Paimon 开源社区的纯开源开放的 REST API,整个 Catalog 是围绕开源开放的 Paimon REST API 来进行设计。通过对接 OpenLake 的自研、开源的全托管的计算引擎,DLF 也支持 EMR & ECS 这样的半托管的引擎,也包括 Python、PyArrow、Ray、DuckDB 等 AI 引擎。
在体系上,团队核心加强了元数据管理( Metadata Management)。提供了一体化界面来管理元数据,结合 OpenLake 的 Run Role 体系来建设权限管理,后台提供了元仓服务。值得一提的是,在整个湖表管理上,OpenLake 提供了智能存储优化。智能的核心自适应分桶和自适应合并,在 OpenLakeDLF 上,基于 Paimon 构建主键表和非主键表的时候,用户不需要在意分桶和合并的问题,所有的分桶和合并都是在后台自动完成的。
2. Paimon REST Catalog API

Paimon 1.1 版本发布的 Paimon REST Catalog API,是一个标准化的开源开放的 SDK,支持跨语言对接,它让整个 Paimon 的生态,包括 Java、C++,Rust 对接变得更容易。右侧是 Paimon REST API 的一个定义,核心点就是它的 Table 的结构以及这些 API 的定义都是围绕 Paimon 来进行实现的。这种方式,能够最大化加强 Paimon 的能力,也非常有利于后续在 Paimon 中扩展能力。所以对接的整个 REST Catalog API 之后,可以让用户在任何与 Paimon 兼容的引擎和应用,通过 DLF 轻松创建更新、查询和删除表。
3. Catalog 数据层次结构
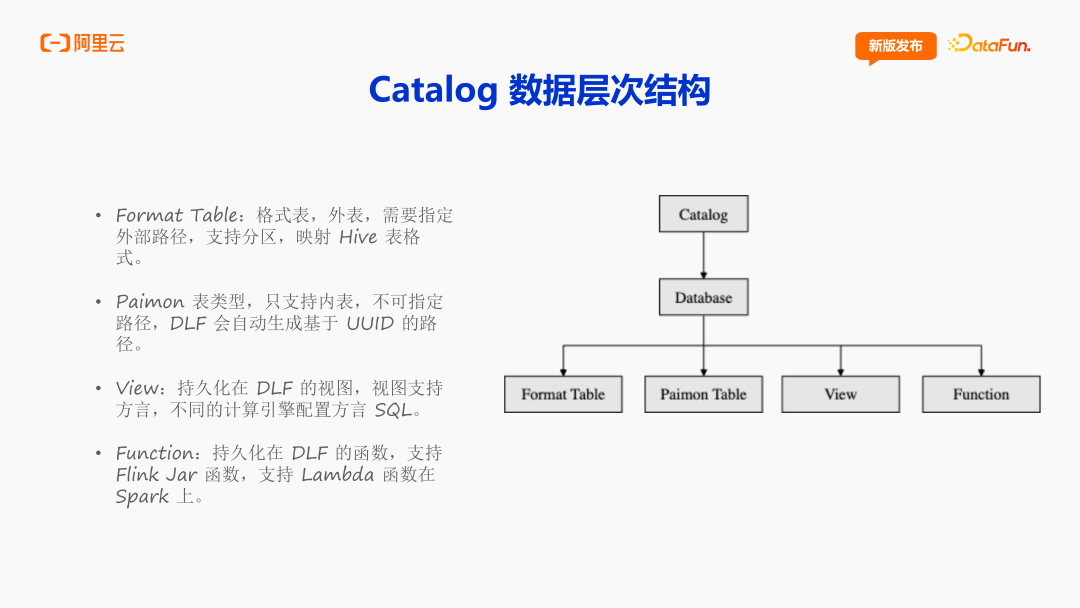
Catalog 的数据层次结构是“Catalog – Database – 各类实体”,包括 Paimon Table、Format Table、View、Function。这里的 Paimon Table 只支持内表,不可指定路径,按主键情况分为主键表和非主键表。 Format Table 就是一种外表,它其实就是映射社区 Hive 表格式的结构,可以支持分区表和非分区表,可以让用户在数据迁移的时候,在关键程序中保留一些 Hive 表。View 是持久化在 DLF 的视图,随着 Paimon 开源社区的发展,View 也支持方言的形式,意味着不同的计算引擎可以支持不同的 View 定义。在面对 Flink、Spark 或者 StarRocks 方言不一样的情况,用户可以给 DLF 同一个 View 注册不一样的方言,就可以在每个引擎都正确执行并获得正确的结果。Function 也是目前正在发展的一个实体,是持久化在 DLF 的函数,OpenLake 将支持 Flink Jar 函数,以及支持 Spark 上的 Lambda 函数。
4. DLF Paimon 智能存储优化
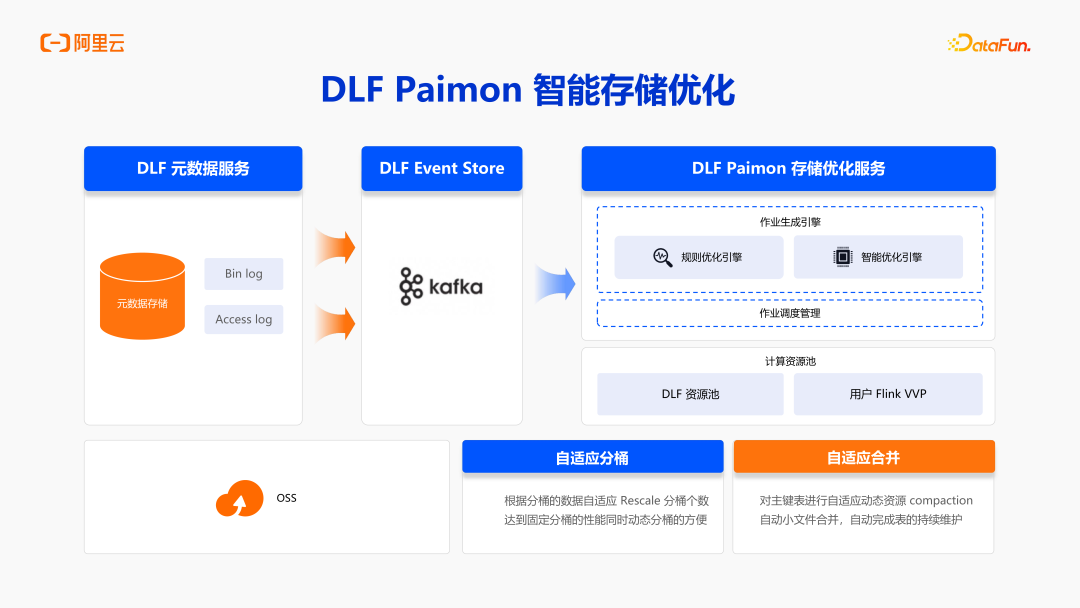
通过对湖表的使用,Compaction 可以发生在写入端,也可以成为独立任务。在DLF 上创建表,会统一关闭写入端的 Compaction,所有的写入都会注册到 DLF 的后台元数据服务中,所有事件都会传输到 Kafka 中,后台存储优化服务会实时消费 Kafka,可以明确写入 Table、分区范围以及写入数据量等。拿到这些日志之后,DLF 后台的存储优化服务,就会根据这些更改和自己的规则引擎生成对应的优化 Plan 以及 Compaction 任务,自动完成相应数据的 Compaction,用户侧无需关注整个过程。DLF 后台研发人员也大多来自于 Paimon 社区 PMC 成员,也会让优化任务足够的高效,使用的资源足够低,在最短的时间使用最少的资源完成对应的 Compaction。两个核心 Feature 就是自适应分桶和自适应合并。Paimon 后台会根据整个表的整个分区的数据来进行自适应的分桶。每一张表的每个分区可以支持不一样的 Bucket 设置,支持后台的存储优化服务自动计算。
智能存储自适应分桶
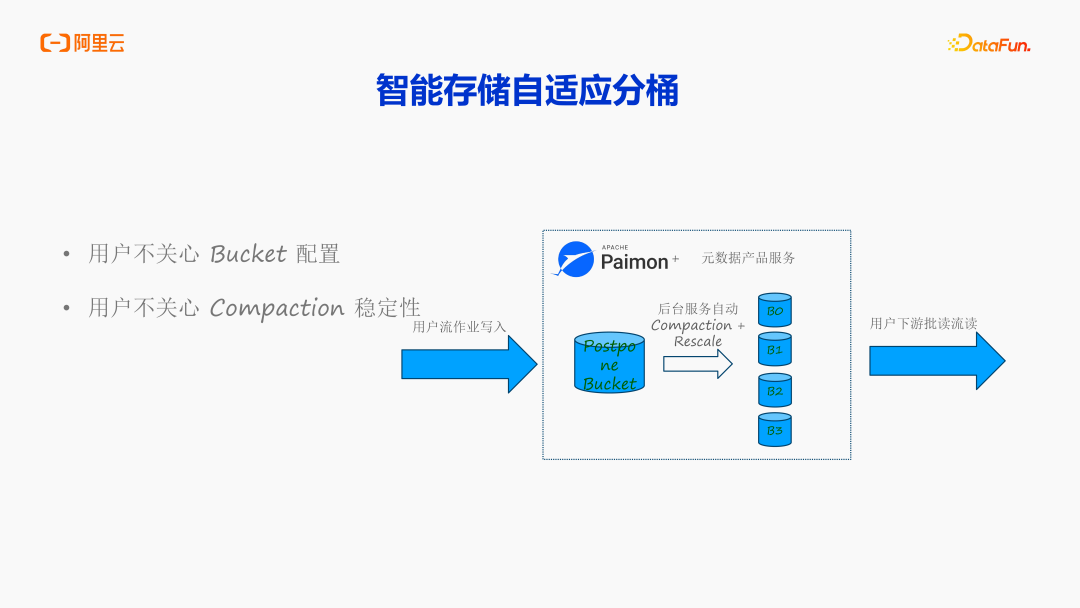
最新的 Paimon 版本支持 Postpone bucket,相当于用户的流写作业不再写入具体的分桶当中,而是统一写到临时目录。DLF 后台服务会自动地把根据临时区的数据情况,设定分桶大小和数量,把临时区的数据给写到真正的分桶当中。用户对整个过程感受就是数据在源源不断写入、不断读取。后台的 Compaction 全部由 DLF 的后台服务来自适应分桶,当前最新版本的 Hbase 支持自适应的 Range 分区,用户不用理解后台的 Compaction ,不用关心 Bucket 配置,也不用关心 Compaction 稳定性。
5. 性能对比:DLF 全托管 VS 基于 OSS 自建

接下来分享 DLF 全托管和基于 OSS 自建的性能对比。
在元数据访问方面,得益于对接了 OpenLake 最新的 Gateway Endpoint 技术,DLF 元数据访问响应能达到 10 毫秒级,对比 DLF1 访问延迟降低了 10 倍。数据访问性能,对比 OSS 自建,也有至少 15% 以上的性能优势。在智能优化上,存储成本降低了 30% 以上,查询性能平均提升了 2 倍左右。OpenLake 也提供了产品化的数据迁移, Paimon 格式完全兼容了开源存储,并且提供了一站式的迁进迁出能力。
04
DLF 数据湖平台:多模态数据湖
最后,分享一下多模态数据湖,重点讲解 OpenLake 是如何赋能多模态数据的。
1. OpenLake 是如何赋能多模态数据

在当前大数据技术架构中,Parquet 作为主流列式存储格式凭借其高效的列投影(Projection)能力、优化的数据扫描(Scan)性能以及卓越的压缩率,长期占据核心地位。然而,面对机器学习与多模态数据处理的新型需求,传统格式逐渐显现出适配局限:
大体积非结构化数据支持不足:当处理音频、视频等单文件体积达 100-200MB 的非结构化数据时,Parquet 易因内存管理机制导致 OOM(内存溢出)问题。而 TFL/TFRecord 等专用格式虽能支持大字段存储,却缺乏列式存储的固有优势。
随机访问效率瓶颈:机器学习模型的典型训练模式依赖数据集的随机采样(Random Access),而 Parquet 基于线性扫描的访问机制需全量读取后执行过滤操作,造成约 90% 的无效 IO 资源消耗。
针对上述挑战,Lance 格式通过技术创新实现了三方面突破:
原生多模态存储支持:创新设计支持大体积 Blob(二进制大对象)的高效存储,完美适配音视频等非结构化数据场景
智能随机访问优化:内置索引机制实现 O(1)时间复杂度随机采样,较传统格式数量级提升了以上 IO 效率
增量式列存储架构:支持动态列追加(Append-Only Columns)与版本控制,满足持续演进的数据管理需求
2. 如何实现
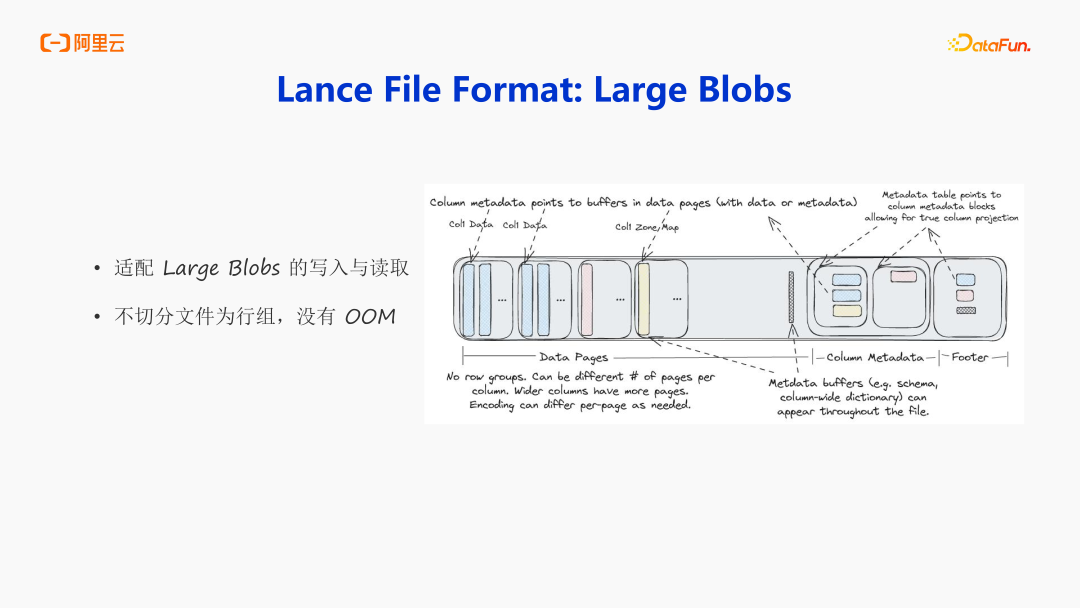
首先讲讲 Large Blobs。Parquet 底层是分 Row group 的,每次写入都会在内存中攒一个 Row Group,然后再写到磁盘中。在处理大规模二进制对象(Blob)的场景中,传统存储架构常因内存缓冲机制引发内存溢出(OOM)风险。Lance 通过创新存储引擎设计,摒弃传统行组(Row Group)分区机制,采用连续存储结构直接将数据持久化至磁盘。这种单文件原子化写入模式,在保障数据完整性的同时,从根本上规避了内存密集型操作带来的系统稳定性风险。如果写的过程中有非常大的文件,会先落一个临时盘,最终再写真正的盘中,很好的支持了大字段的读写,团队也是做了非常多大字段优先的策略来保证大字段的写入。
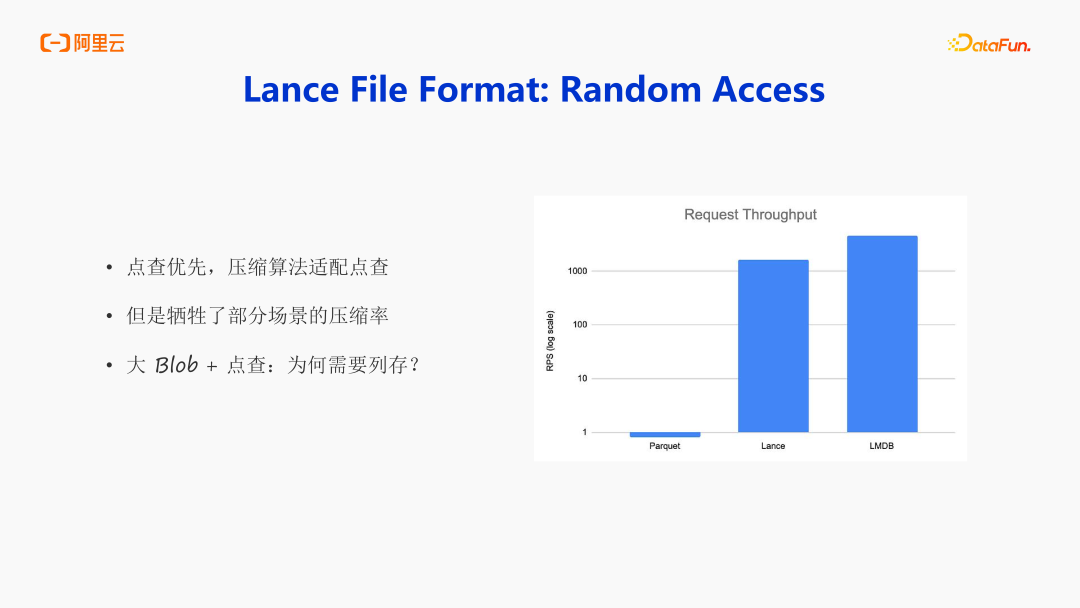
第二点是随机访问, random access,Lance 社区也做了性能 Benchmark,它在测试读的 RPS,会发现 Parquet 的性能表现非常差,Lance 的 random access 的 RPS 能达到非常的高。对相同并发的情况下,Lance 表现优异的根本原因是点查优先的设计,核心的压缩算法是字典压缩,并没有做很深层次的压缩算法。可以基于 offset 直接找到数据位置,基于全局索引找到 ID,再根据 ID 找到对应的数据,进而找到对应的 offset,直接获取即可。如果用 Parquet,会发现 Parquet 做了大量且激进的压缩,会导致用户在获取数据的时候,需要解压整个配置,甚至解压整个 Row group,会造成非常高的浪费。整体来说, Lance 的设计上是牺牲了部分场景的压缩率来完成了点查优先的一个设计。
Lance 采用列式存储架构的设计考量在于平衡多模态支持与大数据生态适配:
能力融合:在实现大 Blob 存储与高效点查的同时,继承列式存储核心优势(列压缩/列投影),突破传统行式存储在分析场景的性能局限;生态兼容:通过智能数据分区与元数据管理,保持与 Parquet 生态工具链的互操作性;架构扩展:基于列存基础构建分层存储模型,既支持非结构化数据原子操作,又维持结构化数据分析效率。该设计使 Lance 成为同时满足 OLAP(在线分析)与 OLTP(在线事务)特征的统一存储格式,实现存储范式创新。
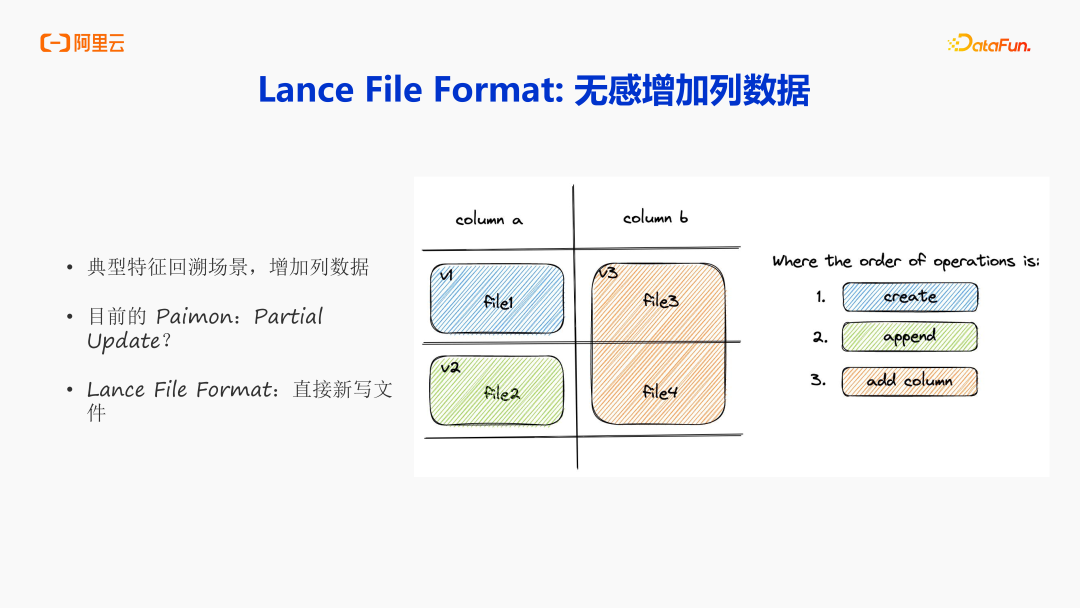
最后是无感的增加列数据。特征回溯场景是一个最典型的案例,需要增加一列,还需要补齐数据。Paimon 的 partial update 能力来完成这件事,对 partial Update 来说,虽然完成了数据写入,但仍然需要大量的资源进行 Compaction。那 Lance 是如何更自然的来解决这件事的呢?Lance 不是一个表绑定一个文件,而是一行数据可以绑定多个文件。这就意味着可以通过多个文件来存储不同的列,这样意味着在增加列数据的时候,只用写一个新的文件就能达到需求。如上图所示,通过 create-append- add column动作就可以完成,列文件和列数据的增加就变得非常的高效且高性能了。

基于 Lance 格式的技术特性,我们进一步聚焦 DLF(Data Lake Framework)实现多模态数据湖支持能力的关键路径。目前团队正在研发的是 Paimon 和 Lance File Format 的集成。除了 Parquet、ORC、Avro 之外,此版本也会支持 Lance 的 File Format。在我们的 OSS 上结合 Lance 文件格式加上 Paimon 表格式,来达到 random access 大字段的存储以及高效的列增加,通过 Paimon 面向 AI 和数据引擎。相关能力,预计会在 7 月份会有初步版本,目前新版的阿里云 DLF 新版正在邀测中,欢迎大家到官网查看详情和申请试用https://www.aliyun.com/product/bigdata/dlf


分享嘉宾
INTRODUCTION

李劲松
阿里云
高级技术专家
负责 Apache Paimon 的研发和产品,PMC Chair of Apache Paimon,PMC member of Apache Flink。先后从事分布式流计算、分布式批计算、湖存储,目前专注于流式湖仓的技术。

往期推荐
Agent真实落地场景探索!
HiAgent 2.0:让 Agent 走向生产
字节跳动Data Agent核心技术实践
零售数智化升维战:腾讯云大数据 Data+AI 驱动增长“三极”跃迁
AI时代的数据智能跃迁:数据、工具与组织的进化
CTO高峰对谈:智能体时代智能终端的颠覆与重构!
联通数科基于一体化数据平台的元数据管理实践
效率提升60倍、准确率达97%+,理想汽车NL2SQL自动化数据合成技术揭秘!
专访杨经纬:基于代码智能体的百度智能化研发落地实践
揭秘字节跳动LLM+Agent核心技术
点个在看你最好看
SPRING HAS ARRIVED
相关文章
