
摘要
大型语言模型(LLMs)已经彻底改变了基于自然语言处理(NLP)的应用,包括自动化文本生成、问答系统、聊天机器人等。然而,它们面临一个重大挑战:产生幻觉,即模型生成听起来合理但实际上错误的内容。这削弱了信任,并限制了LLMs在不同领域的适用性。另一方面,知识图谱(KGs)提供了结构化的互联事实集合,以实体(节点)及其关系(边)表示。在最近的研究中,KGs已被用于提供上下文,可以填补LLMs在理解某些话题时的空白,提供了一种缓解LLMs幻觉的有前途的方法,增强了它们的可靠性和准确性,同时受益于它们广泛的适用性。尽管如此,它仍然是一个非常活跃的研究领域,存在许多未解决的开放性问题。在本文中,我们讨论了这些未解决的挑战,涵盖了最新的数据集和基准测试,以及知识整合和评估幻觉的方法。在我们的讨论中,我们考虑了当前大型语言模型(LLMs)在LLM系统中的使用,并针对每个挑战确定了未来的方向。
核心速览
研究背景
- 研究问题
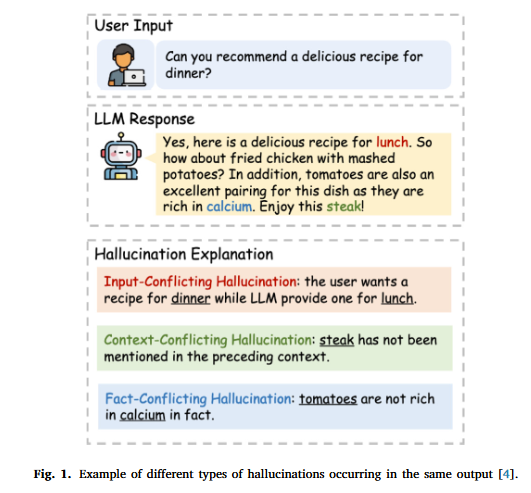
:这篇文章要解决的问题是大型语言模型(LLMs)在生成文本时容易出现的事实不一致现象,即“幻觉”。这种幻觉会损害用户对AI系统的信任,并在某些情况下生成误导性信息。 - 研究难点
:该问题的研究难点包括:幻觉的多面性(如世界知识、自相矛盾、与提示指令或给定上下文的幻觉)、评估幻觉的复杂性(需要评估输出的语义一致性)以及现有数据集和基准测试的局限性。 - 相关工作
:该问题的研究相关工作有:利用知识图谱(KGs)提供结构化的事实信息来缓解LLMs的幻觉问题、现有的幻觉检测方法和知识整合模型。
研究方法
这篇论文提出了利用知识图谱(KGs)来缓解LLMs的幻觉问题。具体来说,
-
知识图谱的利用:KGs是一种结构化的知识表示形式,由实体(节点)和它们之间的关系(边)组成。通过将KGs的信息整合到LLMs中,可以在推理或生成过程中提供事实基础,从而提高输出的一致性和准确性。
-
知识整合模型的分类:根据其底层架构,可以将不同的知识整合模型进行分类。论文提出了一个分类框架,展示了在不同阶段加入额外信息以增强事实性的可能性。
-
幻觉检测方法:GraphEval提出了一种两阶段的幻觉检测和缓解方法,通过从LLMs输出中提取原子断言并与给定文本上下文进行比较来进行检测。其他方法如KGR、Fleek等也采用了类似的方法,但都存在一些局限性。
-
多提示评估:DefAn数据集通过为每个问答数据点提供15个不同的问题重述,来评估LLMs的鲁棒性和一致性。
实验设计
- 数据集
:论文评估了多个幻觉检测和数据集,包括Shroom SemEval 2024、MuShroom SemEval 2025、MedHalt、HaluEval、TruthfulQA、FELM、HaluBench、DefAn、SimpleQA等。这些数据集覆盖了多个领域和任务类型,如法律、政治、医学、科技、艺术、金融等。 - 评估指标
:使用了多种评估指标,如准确率、校准、F1值等,来评估幻觉检测模型的性能。对于知识整合方法,还使用了BERTScore和BARTScore等语义相似度度量。 - 实验设置
:实验设置包括对每个数据集的划分(训练、验证、测试)、子任务的定义以及外部知识的来源(如文本上下文、网页等)。
结果与分析
- 幻觉检测效果
:现有的幻觉检测方法在识别和处理幻觉方面取得了一定的进展,但仍存在一些问题。例如,多阶段管道方法的鲁棒性和可扩展性有限,且高度依赖于LLMs的提示。 - 知识整合效果
:通过将KGs信息整合到LLMs中,可以显著提高输出的一致性和准确性。然而,现有的知识整合方法在快速知识更新和避免提示脆弱性方面仍存在挑战。 - 多提示评估
:DefAn数据集的评估结果表明,多提示方法可以提高LLMs的鲁棒性和一致性,但仍需要进一步的研究来验证其在不同场景下的有效性。
总体结论
这篇论文总结了利用知识图谱(KGs)来缓解LLMs幻觉问题的现状和挑战。尽管已有方法取得了一定的进展,但幻觉缓解仍然是一个持续的研究问题。论文提出了未来研究的方向,包括大规模数据集、多语言和多任务的评估、细粒度的幻觉检测、减少对文本提示的依赖以及混合使用不同的幻觉缓解方法。通过这些研究方向,论文希望为LLMs的幻觉问题提供更有效的解决方案。
论文评价
优点与创新
- 全面性
:论文详细讨论了知识图谱(KGs)在缓解大型语言模型(LLMs)生成幻觉现象中的潜力,涵盖了当前的研究现状、局限性以及未来的研究方向。 - 分类方法
:提出了基于架构的知识集成模型分类方法,并总结了不同阶段额外信息加入的类别。 - 资源梳理
:梳理了现有的评估幻觉的数据集和基准测试,提供了详细的资源概览。 - 多维度评估
:强调了多维度评估的重要性,包括多语言、多任务和多角度的评估方法。 - 细粒度检测
:提出了细粒度的幻觉检测方法,如句子级和段落级的检测,以更好地捕捉幻觉的细节。 - 未来方向
:提出了多个未来研究方向,包括大规模数据集、鲁棒评估、细粒度幻觉检测、非文本提示的知识集成方法以及混合不同方法的探索。
不足与反思
- 数据集限制
:大多数现有数据集缺乏高质量的知识图谱三元组作为外部知识,限制了知识集成模型的参数化方法的发展。 - 评估方法局限
:当前的评估方法主要依赖于单一的提示和多语言评估的缺乏,未能全面评估系统的鲁棒性和泛化能力。 - 方法依赖性
:许多方法仍然依赖于文本提示,存在提示脆弱性和高计算成本的问题。 - 知识图谱的局限性
:现有的知识图谱在数据完整性、准确性和多语言覆盖方面存在局限性,可能影响幻觉缓解的效果。 - 未来研究建议
:需要进一步研究如何在参数化设置中集成知识,减少对文本提示的依赖,并探索不同方法的有效组合。
关键问题及回答
问题1:论文中提到的知识图谱(KGs)在缓解LLMs幻觉问题中的具体应用有哪些?
- 预训练阶段
:将KG triples作为训练数据的一部分,通过掩码实体预测任务将KG triples与原始文本输入融合。例如,Ernie 3.0模型通过大规模的知识增强预训练来提升语言理解和生成能力。 - 推理阶段
:通过提示(prompting)将KG triples与查询结合,形成输入对(P={mathcal{K},mathcal{Q}}),用于检索增强生成(RAG)任务。例如,使用BERTscore和BARTScore等语义相似度度量来评估LLMs输出的质量。 - 生成后阶段
:在生成答案后,通过外部KG进行事实检查,并根据验证结果对原始输出进行修正。例如,GECKO方法完全依赖于KG信息进行文本生成。
问题2:论文中提到的幻觉检测方法有哪些?它们各自的优缺点是什么?
- GraphEval
:提出了一种两阶段的幻觉检测和缓解方法。第一阶段通过LLM提示提取原子断言并形成子图,第二阶段将这些子图与给定文本上下文进行比较。优点是可以提供细粒度的错误分析,缺点是依赖于LLM提示的鲁棒性。 - KGR
:通过命名实体提取KG子图,并比较源文本和生成文本之间的对齐情况。优点是能够识别具体的错误部分,缺点是可能丢失抽象概念的详细信息。 - Fleek
:通过提取结构化三元组并使用另一个LLM进行事实检查。优点是能够进行事实验证,缺点是依赖于多个LLM的推理,计算成本高。 - DefAn
:通过为每个问答数据点提供多个问题重述来评估LLMs的鲁棒性和一致性。优点是多提示评估可以提高模型的鲁棒性,缺点是需要大量的标注数据和计算资源。
问题3:论文中提到的知识整合方法在提高LLMs输出一致性和准确性方面的效果如何?存在哪些挑战?
- 效果
:通过将KGs信息整合到LLMs中,可以显著提高输出的一致性和准确性。例如,Ernie 3.0模型在大规模知识增强预训练后,情感分析任务的性能得到了显著提升。 - 挑战
:现有的知识整合方法在快速知识更新和避免提示脆弱性方面仍存在挑战。例如,基于提示的方法依赖于手工设计的模板,容易受到格式和内容限制的影响。此外,多阶段管道方法的鲁棒性和可扩展性也有限,高度依赖于LLMs的提示。
参考文献
-
OpenTCM:基于GraphRAG的传统中医药知识检索与诊断问答图谱增强大模型系统 - 香港中文大学
-
Agentic GraphRAG?" data-itemshowtype="0" linktype="text" data-linktype="2">如何构建医疗健康等复杂场景下的Agentic GraphRAG?
-
MedRAG:利用知识图谱引导推理提升医疗Copilot的RAG能力 - 新加坡南洋理工等
-
基于GraphRAG的妊娠期糖尿病管理本地大模型
-
HyperGraphRAG:基于超图结构知识表示的新版GraphRAG - 北邮、安贞医院等
-
KnowNET:通过知识图谱集成大模型引导健康信息抽取
-
医疗保健知识图谱&大模型综述:资源、应用与前景-Emory,Michigan大学等
-
[2025最新综述解读]定制化大模型的GraphRAG - 香港理工&吉林大学等
-
[2025论文解读]基于知识图谱的思考:一种知识增强的泛癌症问答大模型框架 - 中科院&广州国家实验室等
-
[VLDB24 KG+LLM论文]利用多模态和知识图谱增强大模型以实现无幻觉的开放集物体识别 - 河海大学等
-
论文浅尝 | 从大型语言模型进行情境化提炼以完成知识图谱(ACL2024)
-
(88页)知识图谱增强大模型GraphRAG 2025年最新调研综述 - 密歇根大学、Adobe、Meta、亚马逊等
-
Stardog Voicebox智能体: 知识图谱&LLM双轮驱动、释放自动化的创造力
-
“大模型+知识图谱”双轮驱动的见解、技术和评估 - 英伟达的GraphRAG
-
大模型能自动创建高质量知识图谱吗?可行性及人机协同机制 - WhyHow.AI
-
GraphRAG和轻量级LightRAG技术及应用案例深度解析
-
RAG框架演进之路及带来的一些思考" data-itemshowtype="11" linktype="text" data-linktype="2">微软GraphRAG框架演进之路及带来的一些思考
-
LazyGraphRAG:微软重磅推出高性价比下一代GraphRAG
-
提升大型语言模型结果:何时使用GraphRAG
-
微软GraphRAG最新动态:通过动态社区选择改善全球搜索
-
GraphRAG产业化应用落地挑战和探索:知易行难 - 企业大模型独角兽Glean实践之四
-
GraphRAG从研发到上线的挑战-硅谷企业级大模型知识库独角兽Glean系列之三
-
企业级知识库为什么要用GraphRAG - 硅谷企业级ChatGPT独角兽Glean系列之二
-
企业智能知识库企业Glean利用GraphRAG融资2.6亿美元
-
重磅 - 微软官宣正式在GitHub开源GraphRAG
-
开源GraphRAG解读:微软的人工智能驱动知识发现方法
-
GraphRAG工程落地成本详细解读和实例分析
-
GraphRAG类型、限制、案例、使用场景详细解析
-
引入GraphRAG的场景条件分析
-
不适用生成式人工智能的场景
-
知识图谱增强大模型GraphRAG全面综述解读 - 蚂蚁集团、北大、浙大、人大等
-
5个知识图谱KG和RAG系统的误解 — 构建和使用RAG原生图谱
-
OpenKG-SIG | SIGData兴趣组:利用大模型构建LLM需要的知识图谱
-
关于大模型和知识图谱、本体的一场讨论
-
什么时候(不)用GraphRAG
-
GraphRAG工程落地成本详细解读和实例分析
-
Structured-GraphRAG知识增强框架——足球游戏数据案例研究
-
StructRAG: 下一代GraphRAG - 中科院&阿里
-
KG RAG vs. Vector RAG:基准测试、优化杠杆和财务分析示例 - WhyHow.AI实践
-
知识图谱增强RAG流水线Use Case-WhyHow.AI
-
“大模型+知识图谱”双轮驱动的医药数智化转型新范式-OpenKG TOC专家谈
-
知识图谱(KG)和大模型(LLMs)双轮驱动的企业级AI平台构建之道
相关文章
