本公众号主要关注NLP、CV、LLM、RAG、Agent等AI前沿技术,免费分享业界实战案例与课程,助力您全面拥抱AIGC。
一、现有方案的局限性
现有的文档图像解析解决方案主要分为两大类:基于集成的方法和端到端的方法。
-
基于集成的方法通过将多个专家模型组装到一个多阶段的流水线中来实现文档解析,这些方法虽然在特定任务上表现出色,但需要对每个模型进行独立优化,并且在组件间协调方面面临挑战。 -
端到端的方法则利用通用或专家视觉语言模型(VLMs)直接自回归地生成页面级内容,虽然能够捕捉页面级语义,但在解析长文档和复杂布局时,常常会遇到布局结构退化和效率瓶颈的问题。
Dolphin案例展示
-
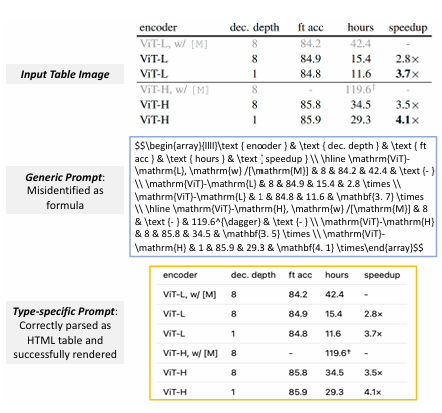
版式识别、阅读顺序识别 


-
公式识别

-
给定box区域提取区域的内容

-
复杂的表格可以轻松转出markdown

-
无线表格轻松拿捏
二、Dolphin解决方案
Dolphin (Document Image Parsing via Heterogeneous Anchor Prompting)采用了一种分析-解析范式(analyze-then-parse),将文档解析过程分解为两个阶段:
-
第一阶段进行页面级布局分析,生成自然阅读顺序的布局元素序列; -
第二阶段则利用这些元素作为锚点,结合任务特定的提示,进行并行的内容解析。
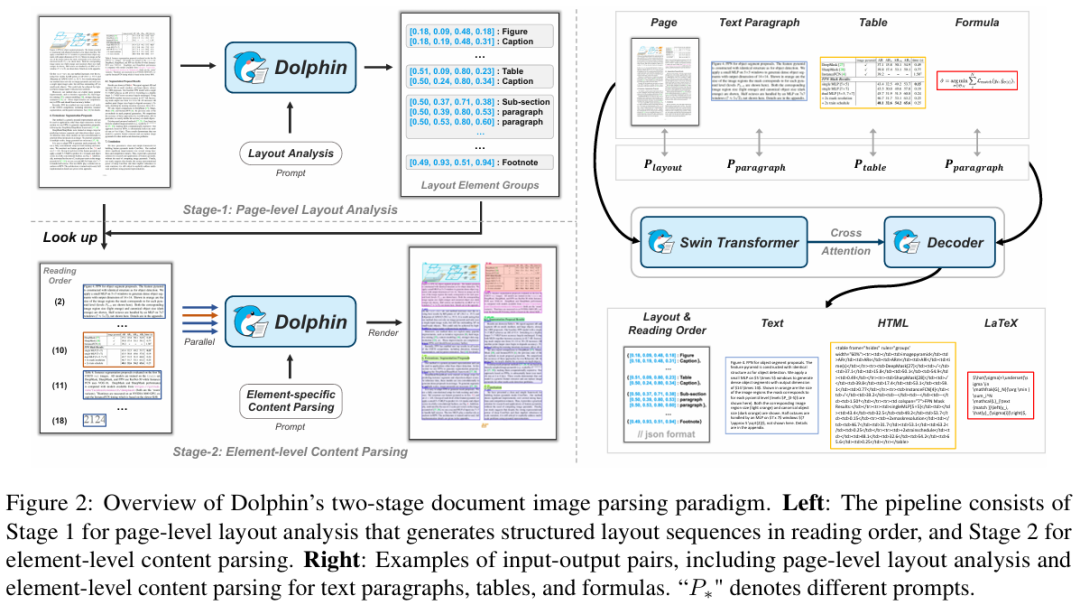
这种两阶段的设计既避免了传统集成方法中多模型协调的复杂性,又克服了端到端方法在复杂布局和长文档解析中的效率瓶颈,还能通过轻量级架构和并行解析机制实现优越的运行效率。
-
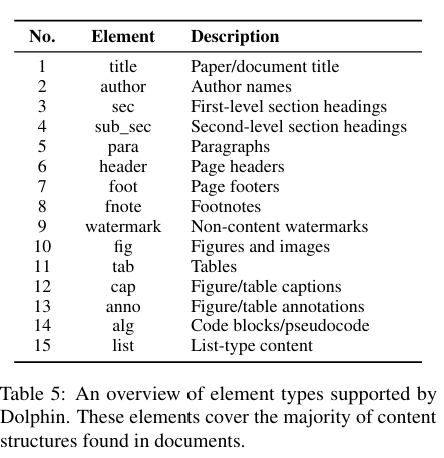
Dolphin支持的布局元素
2.1. 页面级布局分析阶段
-
页面图像编码 -
Dolphin 使用 Swin Transformer 作为视觉编码器,将输入的页面图像编码为视觉嵌入序列。 -
Swin Transformer 的层次化设计能够同时捕捉全局布局模式和局部文本细节。 -
输入图像在编码前会被调整并填充到固定大小,以保持其宽高比,避免文本失真。 -
布局序列生成 -
在布局序列生成过程中,解码器以布局分析提示(Playout)为引导,通过交叉注意力机制关注编码后的视觉特征。 -
解码器采用 mBart 架构,能够识别并按顺序排列文档元素,同时保留结构关系(例如图表与标题的配对、表格与标题的关联以及章节标题与段落的层次结构)。 -
最终生成的布局元素序列 包含每个元素的类型(如图表、标题、表格、段落)和边界框信息,这些元素将作为第二阶段的锚点。 L = {l1, l2, ..., ln}
2.2 元素级内容解析阶段
-
元素图像编码 -
对于第一阶段识别出的每个布局元素 li -
Dolphin 从原始图像中裁剪出对应的区域,形成局部视图 Ii。 -
这些局部视图通过相同的 Swin Transformer 并行编码,生成元素特定的视觉特征。 -
并行内容解析 -
在并行内容解析阶段,Dolphin 利用类型特定的提示来指导不同元素的解析。 -
例如,表格使用专用的表格提示(Ptable)来解析其 HTML 格式 -
而公式则与文本段落共享相同的提示(Pparagraph),因为它们通常在段落上下文中以行内和显示模式出现,尽管它们的标记格式为 LaTeX。 -
给定局部视图 Ii 的视觉特征及其对应的提示 pi,解码器能够并行生成解析后的内容。这种并行处理策略结合元素特定的提示,确保了计算效率,同时保持了准确的内容识别。
训练方案
-
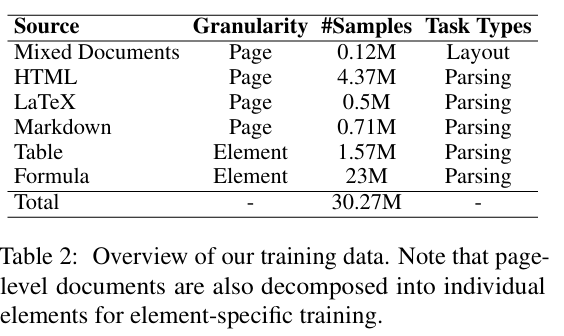
构建数据集 -
包含超过 3000 万个样本的大规模数据集,涵盖了页面级文档和元素级组件。 -
数据集的来源包括混合文档、HTML 文档、LaTeX 文档、Markdown 文档、表格和公式等。 -
这些数据通过不同的方式进行了处理和标注,以满足模型训练的不同需求。
-
训练过程中 -
Dolphin 采用了动态任务选择策略,根据训练样本的可用标注随机选择适用的任务,从而构建问题-答案对。 -
这种策略能够提高模型的泛化能力,使其能够处理多种类型的文档解析任务。 -
还采用了预训练权重初始化的方法,通过在 Donut 模型的基础上进行指令调优,扩展了模型对多样化提示的理解和执行能力。
Dolphin实战
通过这个链接可以免费试用
http://115.190.42.15:8888/dolphin/
Dolphin 提供了两个推理框架,支持两个解析粒度:
-
页面级解析:将整个文档图像解析为结构化的 JSON 和 Markdown 格式
-
元素级解析:解析单个文档元素(文本、表格、公式)
-
页面解析
import argparse
import glob
import os
import cv2
import torch
from PIL import Image
from transformers import AutoProcessor, VisionEncoderDecoderModel
from utils.utils import *
class DOLPHIN:
def __init__(self, model_id_or_path):
"""Initialize the Hugging Face model
Args:
model_id_or_path: Path to local model or Hugging Face model ID
"""
# Load model from local path or Hugging Face hub
self.processor = AutoProcessor.from_pretrained(model_id_or_path)
self.model = VisionEncoderDecoderModel.from_pretrained(model_id_or_path)
self.model.eval()
# Set device and precision
self.device = "cuda"if torch.cuda.is_available() else"cpu"
self.model.to(self.device)
self.model = self.model.half() # Always use half precision by default
# set tokenizer
self.tokenizer = self.processor.tokenizer
def chat(self, prompt, image):
"""Process an image or batch of images with the given prompt(s)
Args:
prompt: Text prompt or list of prompts to guide the model
image: PIL Image or list of PIL Images to process
Returns:
Generated text or list of texts from the model
"""
# Check if we're dealing with a batch
is_batch = isinstance(image, list)
if not is_batch:
# Single image, wrap it in a list for consistent processing
images = [image]
prompts = [prompt]
else:
# Batch of images
images = image
prompts = prompt if isinstance(prompt, list) else [prompt] * len(images)
# Prepare image
batch_inputs = self.processor(images, return_tensors="pt", padding=True)
batch_pixel_values = batch_inputs.pixel_values.half().to(self.device)
# Prepare prompt
prompts = [f"<s>{p} <Answer/>"for p in prompts]
batch_prompt_inputs = self.tokenizer(
prompts,
add_special_tokens=False,
return_tensors="pt"
)
batch_prompt_ids = batch_prompt_inputs.input_ids.to(self.device)
batch_attention_mask = batch_prompt_inputs.attention_mask.to(self.device)
# Generate text
outputs = self.model.generate(
pixel_values=batch_pixel_values,
decoder_input_ids=batch_prompt_ids,
decoder_attention_mask=batch_attention_mask,
min_length=1,
max_length=4096,
pad_token_id=self.tokenizer.pad_token_id,
eos_token_id=self.tokenizer.eos_token_id,
use_cache=True,
bad_words_ids=[[self.tokenizer.unk_token_id]],
return_dict_in_generate=True,
do_sample=False,
num_beams=1,
repetition_penalty=1.1
)
# Process output
sequences = self.tokenizer.batch_decode(outputs.sequences, skip_special_tokens=False)
# Clean prompt text from output
results = []
for i, sequence in enumerate(sequences):
cleaned = sequence.replace(prompts[i], "").replace("<pad>", "").replace("</s>", "").strip()
results.append(cleaned)
# Return a single result for single image input
if not is_batch:
return results[0]
return results
def process_page(image_path, model, save_dir, max_batch_size=None):
"""Parse document images with two stages"""
# Stage 1: Page-level layout and reading order parsing
pil_image = Image.open(image_path).convert("RGB")
layout_output = model.chat("Parse the reading order of this document.", pil_image)
# Stage 2: Element-level content parsing
padded_image, dims = prepare_image(pil_image)
recognition_results = process_elements(layout_output, padded_image, dims, model, max_batch_size)
# Save outputs
json_path = save_outputs(recognition_results, image_path, save_dir)
return json_path, recognition_results
def process_elements(layout_results, padded_image, dims, model, max_batch_size=None):
"""Parse all document elements with parallel decoding"""
layout_results = parse_layout_string(layout_results)
# Store text and table elements separately
text_elements = [] # Text elements
table_elements = [] # Table elements
figure_results = [] # Image elements (no processing needed)
previous_box = None
reading_order = 0
# Collect elements to process and group by type
for bbox, label in layout_results:
try:
# Adjust coordinates
x1, y1, x2, y2, orig_x1, orig_y1, orig_x2, orig_y2, previous_box = process_coordinates(
bbox, padded_image, dims, previous_box
)
# Crop and parse element
cropped = padded_image[y1:y2, x1:x2]
if cropped.size > 0:
if label == "fig":
# For figure regions, add empty text result immediately
figure_results.append(
{
"label": label,
"bbox": [orig_x1, orig_y1, orig_x2, orig_y2],
"text": "",
"reading_order": reading_order,
}
)
else:
# Prepare element for parsing
pil_crop = Image.fromarray(cv2.cvtColor(cropped, cv2.COLOR_BGR2RGB))
element_info = {
"crop": pil_crop,
"label": label,
"bbox": [orig_x1, orig_y1, orig_x2, orig_y2],
"reading_order": reading_order,
}
# Group by type
if label == "tab":
table_elements.append(element_info)
else: # Text elements
text_elements.append(element_info)
reading_order += 1
except Exception as e:
print(f"Error processing bbox with label {label}: {str(e)}")
continue
# Initialize results list
recognition_results = figure_results.copy()
# Process text elements (in batches)
if text_elements:
text_results = process_element_batch(text_elements, model, "Read text in the image.", max_batch_size)
recognition_results.extend(text_results)
# Process table elements (in batches)
if table_elements:
table_results = process_element_batch(table_elements, model, "Parse the table in the image.", max_batch_size)
recognition_results.extend(table_results)
# Sort elements by reading order
recognition_results.sort(key=lambda x: x.get("reading_order", 0))
return recognition_results
def process_element_batch(elements, model, prompt, max_batch_size=None):
"""Process elements of the same type in batches"""
results = []
# Determine batch size
batch_size = len(elements)
if max_batch_size is not None and max_batch_size > 0:
batch_size = min(batch_size, max_batch_size)
# Process in batches
for i in range(0, len(elements), batch_size):
batch_elements = elements[i:i+batch_size]
crops_list = [elem["crop"] for elem in batch_elements]
# Use the same prompt for all elements in the batch
prompts_list = [prompt] * len(crops_list)
# Batch inference
batch_results = model.chat(prompts_list, crops_list)
# Add results
for j, result in enumerate(batch_results):
elem = batch_elements[j]
results.append({
"label": elem["label"],
"bbox": elem["bbox"],
"text": result.strip(),
"reading_order": elem["reading_order"],
})
return results
def main():
parser = argparse.ArgumentParser(description="Document processing tool using DOLPHIN model")
parser.add_argument("--model_path", default="./hf_model", help="Path to Hugging Face model")
parser.add_argument("--input_path", type=str, default="./demo", help="Path to input image or directory of images")
parser.add_argument(
"--save_dir",
type=str,
default=None,
help="Directory to save parsing results (default: same as input directory)",
)
parser.add_argument(
"--max_batch_size",
type=int,
default=16,
help="Maximum number of document elements to parse in a single batch (default: 16)",
)
args = parser.parse_args()
# Load Model
model = DOLPHIN(args.model_path)
# Collect Document Images
if os.path.isdir(args.input_path):
image_files = []
for ext in [".jpg", ".jpeg", ".png", ".JPG", ".JPEG", ".PNG"]:
image_files.extend(glob.glob(os.path.join(args.input_path, f"*{ext}")))
image_files = sorted(image_files)
else:
if not os.path.exists(args.input_path):
raise FileNotFoundError(f"Input path {args.input_path} does not exist")
image_files = [args.input_path]
save_dir = args.save_dir or (
args.input_path if os.path.isdir(args.input_path) else os.path.dirname(args.input_path)
)
setup_output_dirs(save_dir)
total_samples = len(image_files)
print(f"nTotal samples to process: {total_samples}")
# Process All Document Images
for image_path in image_files:
print(f"nProcessing {image_path}")
try:
json_path, recognition_results = process_page(
image_path=image_path,
model=model,
save_dir=save_dir,
max_batch_size=args.max_batch_size,
)
print(f"Processing completed. Results saved to {save_dir}")
except Exception as e:
print(f"Error processing {image_path}: {str(e)}")
continue
if __name__ == "__main__":
main()
-
元素级解析
import argparse
import glob
import os
import torch
from PIL import Image
from transformers import AutoProcessor, VisionEncoderDecoderModel
from utils.utils import *
class DOLPHIN:
def __init__(self, model_id_or_path):
"""Initialize the Hugging Face model
Args:
model_id_or_path: Path to local model or Hugging Face model ID
"""
# Load model from local path or Hugging Face hub
self.processor = AutoProcessor.from_pretrained(model_id_or_path)
self.model = VisionEncoderDecoderModel.from_pretrained(model_id_or_path)
self.model.eval()
# Set device and precision
self.device = "cuda"if torch.cuda.is_available() else"cpu"
self.model.to(self.device)
self.model = self.model.half() # Always use half precision by default
# set tokenizer
self.tokenizer = self.processor.tokenizer
def chat(self, prompt, image):
"""Process an image with the given prompt
Args:
prompt: Text prompt to guide the model
image: PIL Image to process
Returns:
Generated text from the model
"""
# Prepare image
pixel_values = self.processor(image, return_tensors="pt").pixel_values
pixel_values = pixel_values.half()
# Prepare prompt
prompt = f"<s>{prompt} <Answer/>"
prompt_ids = self.tokenizer(
prompt,
add_special_tokens=False,
return_tensors="pt"
).input_ids.to(self.device)
decoder_attention_mask = torch.ones_like(prompt_ids)
# Generate text
outputs = self.model.generate(
pixel_values=pixel_values.to(self.device),
decoder_input_ids=prompt_ids,
decoder_attention_mask=decoder_attention_mask,
min_length=1,
max_length=4096,
pad_token_id=self.tokenizer.pad_token_id,
eos_token_id=self.tokenizer.eos_token_id,
use_cache=True,
bad_words_ids=[[self.tokenizer.unk_token_id]],
return_dict_in_generate=True,
do_sample=False,
num_beams=1,
)
# Process the output
sequence = self.tokenizer.batch_decode(outputs.sequences, skip_special_tokens=False)[0]
sequence = sequence.replace(prompt, "").replace("<pad>", "").replace("</s>", "").strip()
return sequence
def process_element(image_path, model, element_type, save_dir=None):
"""Process a single element image (text, table, formula)
Args:
image_path: Path to the element image
model: HFModel model instance
element_type: Type of element ('text', 'table', 'formula')
save_dir: Directory to save results (default: same as input directory)
Returns:
Parsed content of the element and recognition results
"""
# Load and prepare image
pil_image = Image.open(image_path).convert("RGB")
pil_image = crop_margin(pil_image)
# Select appropriate prompt based on element type
if element_type == "table":
prompt = "Parse the table in the image."
label = "tab"
elif element_type == "formula":
prompt = "Read text in the image."
label = "formula"
else: # Default to text
prompt = "Read text in the image."
label = "text"
# Process the element
result = model.chat(prompt, pil_image)
# Create recognition result in the same format as the document parser
recognition_result = [
{
"label": label,
"text": result.strip(),
}
]
# Save results if save_dir is provided
if save_dir:
save_outputs(recognition_result, image_path, save_dir)
print(f"Results saved to {save_dir}")
return result, recognition_result
def main():
parser = argparse.ArgumentParser(description="Element-level processing using DOLPHIN model")
parser.add_argument("--model_path", default="./hf_model", help="Path to Hugging Face model")
parser.add_argument("--input_path", type=str, required=True, help="Path to input image or directory of images")
parser.add_argument(
"--element_type",
type=str,
choices=["text", "table", "formula"],
default="text",
help="Type of element to process (text, table, formula)",
)
parser.add_argument(
"--save_dir",
type=str,
default=None,
help="Directory to save parsing results (default: same as input directory)",
)
parser.add_argument("--print_results", action="store_true", help="Print recognition results to console")
args = parser.parse_args()
# Load Model
model = DOLPHIN(args.model_path)
# Set save directory
save_dir = args.save_dir or (
args.input_path if os.path.isdir(args.input_path) else os.path.dirname(args.input_path)
)
setup_output_dirs(save_dir)
# Collect Images
if os.path.isdir(args.input_path):
image_files = []
for ext in [".jpg", ".jpeg", ".png", ".JPG", ".JPEG", ".PNG"]:
image_files.extend(glob.glob(os.path.join(args.input_path, f"*{ext}")))
image_files = sorted(image_files)
else:
if not os.path.exists(args.input_path):
raise FileNotFoundError(f"Input path {args.input_path} does not exist")
image_files = [args.input_path]
total_samples = len(image_files)
print(f"nTotal samples to process: {total_samples}")
# Process images one by one
for image_path in image_files:
print(f"nProcessing {image_path}")
try:
result, recognition_result = process_element(
image_path=image_path,
model=model,
element_type=args.element_type,
save_dir=save_dir,
)
if args.print_results:
print("nRecognition result:")
print(result)
print("-" * 40)
except Exception as e:
print(f"Error processing {image_path}: {str(e)}")
continue
if __name__ == "__main__":
main()
https://github.com/bytedance/Dolphin
https://arxiv.org/pdf/2505.14059
https://huggingface.co/ByteDance/Dolphin
对多模态感兴趣的粉丝,点赞送书哦!
答谢粉丝!点赞送《多模态大模型: 算法、应用于微调》
相关文章
最实用、最热门的AI 工具大全AI 工具导航,帮助你在工作与学习上更轻松有效率。在网路上众多 AI 与 ChatGPT 工具中,我们亲自试用并挑选了最有有用的,分成 20多个大类别,让你轻松找到所需的 AI 工具。
