近年来,RAG 框架从最初的朴素设计,逐步演化出各类高级变体,诸如 GraphRAG、HippoRAG 等结构越来越复杂。作为一名实际使用者,我在应用过程中也愈发感受到这种复杂性带来的沉重负担。起初,RAG 似乎只是为了解决上下文窗口不足的问题引入的一种检索增强手段;但如今,它逐渐变成了一个需要精心构建索引、划分片段、设计路由与重排机制的系统工程。这让我不禁反思:科技树是不是点歪了?怎么就没有一点大力出奇迹的感觉呢?
毕竟,人类在学习知识时并不会将信息切割成一块块“片段”去记忆或理解。我们更倾向于逐页阅读、逐章总结,从而建立起系统性的认知结构。在这一过程中,我们会提取关键概念,更新旧有知识,并在长期记忆中形成跨章节、跨主题的理解链接。
然而,当前大语言模型(LLM)在处理超长文档时(如小说、论文、会议纪要等)仍受到上下文窗口和计算资源的双重限制,难以模拟出这种连续、系统、可回溯的阅读过程。谷歌 DeepMind 团队近期提出的一项非常有意思的工作《A Human-Inspired Reading Agent with Gist Memory of Very Long Contexts》[1],尝试以人类阅读行为为启发,构建一个具备“要点记忆”和“回查能力”的阅读代理 ReadAgent,为 LLM 如何高效处理长文本提供了一种新的方向。
简直完美契合我的想法,不知道非常令人惊艳的谷歌 NotebookLM 是否基于该形式构建,因为看不到他是采用 RAG 的痕迹。
为什么需要人类启发的阅读代理
当前主流的大模型在处理长度达到数万 token 的文本时,即便模型架构已具备长上下文能力,实际效果依旧不尽如人意。常见的处理方式包括裁剪、窗口滑动、摘要生成和基于切片、(抽取)嵌入、检索的 RAG 等方法,但这些方法通常面临 3 个问题:
-
固定切分可能会打断语义单位(如一个论点或故事情节),导致信息缺失; -
即便全文输入模型,由于注意力分布稀疏,也会导致模型“关注不到”关键细节; -
切片生成的嵌入可能带来语义匹配问题。
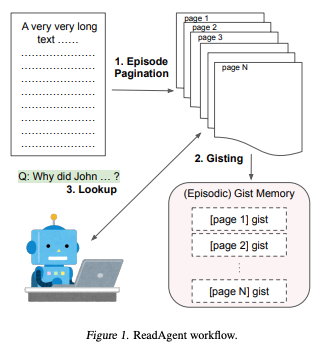
ReadAgent 的核心思路是模拟人类阅读长文时的行为:先通读部分内容形成要点记忆(gist),之后根据问题再返回查阅原文。这一策略通过构建一个“摘要 + 回查”的阅读流程,避免了直接处理整段长文本所带来的效率与质量双重瓶颈。
ReadAgent 系统结构概述
ReadAgent 并不是一个独立模型,而是一个围绕现有大模型构建的模块化阅读代理。整个流程包括三个核心组成部分:
1. 划段策略(Episode Pagination)
与固定窗口或人工切分不同,ReadAgent 采用一种交互式划段方式:每当模型处理一定内容后,会自主判断是否需要“停止阅读”,形成一个 episode。这种划分策略更贴近人类阅读时按语义块理解的习惯,有助于提高记忆压缩质量。
-
连续读取文档的一部分内容(比如几段或几页);
-
判断是否“该停下来总结了”;
-
生成当前阅读内容的“gist memory”(要点记忆);
-
存储该 memory,进入下一段阅读(下一 episode)。
这就像人类在读一本书时,读完一章或几个段落后会停下来思考:“我刚才读了什么?核心观点是什么?”,然后继续下一部分阅读。划段策略使用如下 Prompt:

2. 要点记忆(Memory Gisting)
每个划分出的 episode 会被模型压缩为一段要点记忆“gist memory”,即对该部分内容的关键总结。这些要点记忆与传统摘要不同,它更短、更结构化,强调“记住主旨”而非复述全文。该过程由 LLM 本身完成,通过专门设计的提示词引导其抽取每段的核心信息。

3. 交互式回查(Interactive Look-up)
在回答用户问题或执行下游任务时,如果 gist memory 无法提供充分支持,ReadAgent 会根据记忆线索回到原始文本中进行“精读”,提取具体细节。这一查阅行为并非事先定义,而是根据问题和 memory 动态触发,从而在保持处理效率的同时保证细节完整性。论文研究了并行查阅和串行查阅两种方式。ReadAgent-P使用如下 Prompt 并行查找所有分页,更强调效率,大模型如果对某部分要点记忆感兴趣,就返回对应的 page,然后程序将对应 page 内容替换掉之前的要点记忆,来尝试回答问题。

而 ReadAgent-S 则是串行查阅,在这种策略中,模型每次请求一页文档,最多可请求若干页。在顺序查阅中,模型在决定要展开哪一页之前,可以查看之前已经展开的页面内容。相比并行查阅方式,顺序查阅允许模型获取更多信息,因此在某些任务中可能带来更好的性能。然而,顺序查阅会显著增加与模型交互的次数,从而提升计算开销。因此,该策略应仅用于那些能够从中显著受益的任务。


实验验证与性能表现
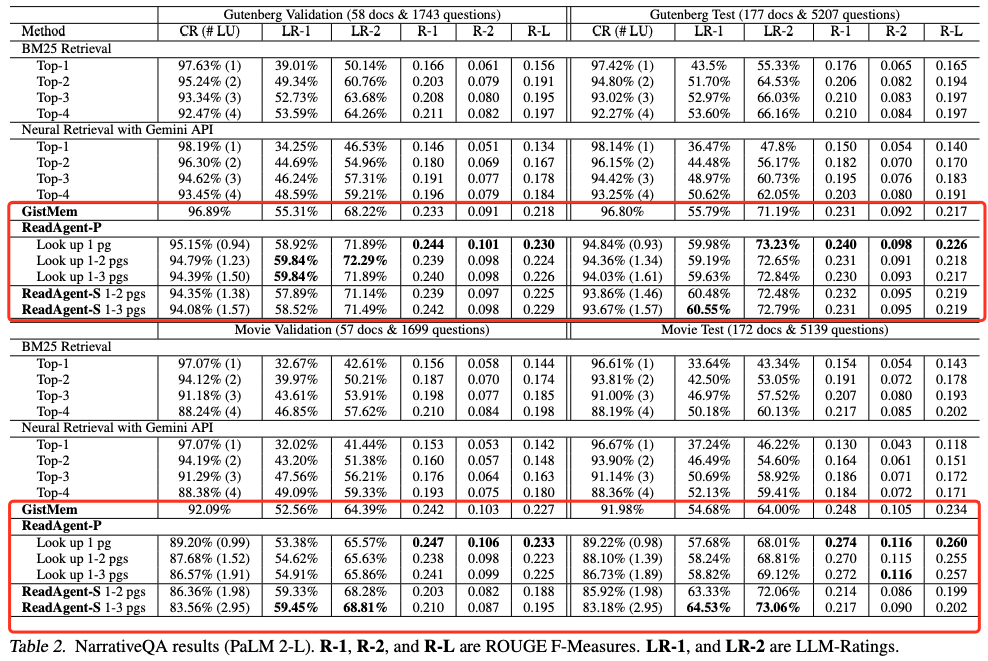
作者在多个真实场景下评估了 ReadAgent 的性能,涵盖了问答(QuALITY、NarrativeQA)和摘要(QMSum)等典型长文本任务。在与以下几类基线模型对比中:
-
直接输入全文 -
检索增强的 LLM -
仅使用 gist memory 无查阅机制
ReadAgent 均表现出更高的准确率、召回率或摘要质量。尤其在 NarrativeQA 和 QMSum 中,能够有效提升模型对事件顺序、因果关系等复杂结构的理解能力。作者还指出,ReadAgent 能将 LLM 的“有效上下文处理长度”扩展至原先的 3 至 20 倍以上。
理论基础与启发
ReadAgent 的设计并非空中楼阁,其理论基础来自心理学对人类记忆系统的研究。根据经典理论,人类在处理信息时主要采用两种记忆方式:
-
Verbatim memory:逐字记忆,强调信息细节; -
Gist memory:提取主旨,保留关键内容,忽略冗余。
ReadAgent 正是以 gist memory 为核心,通过结构化提示引导模型构建主旨记忆,并在任务需要时重新激活 verbatim memory。这一双轨记忆机制在 LLM 中的引入,为模拟人类阅读与理解流程提供了新的范式。
实践价值与未来方向
从工程和应用的角度看,ReadAgent 有几个明显优势:
-
无需修改模型结构:完全基于提示工程(prompt engineering)即可实现,便于集成到现有系统。 -
模块可组合:可根据任务需求灵活选择是否使用划段、摘要或回查模块。 -
跨任务适应性强:除标准 QA 和摘要外,还可用于网页导航、搜索引导等多种上下文驱动任务。
当然,该方法仍存在一些亟待优化的问题:
-
摘要质量不稳定,压缩不当可能遗漏关键信息; -
片段划分目前依赖规则或弱监督,未来可引入强化学习等机制优化划段策略; -
在极端长文本(如上百万字档案)场景下的查阅成本与实时性仍需进一步平衡。
我认为这类方法有一个最大的缺点就是缺乏有效存储于检索的手段,每次都需要查阅整个文本的要点记忆来检索相关内容。不知道如果进一步将要点记忆做成嵌入,是否可以在牺牲少量精度的情况下有效减少检索时间?但是对于一些不要求时间,只要求精度的场景可能是非常合适的
结语
ReadAgent 展示了一种以人类认知机制为蓝本的长文本理解方法,其将“记住主旨 + 按需查阅”这一经典的学习策略成功迁移至 LLM 系统,在多个任务中实现性能突破。随着长文本处理需求的不断上升,这类结构化、模块化、认知启发的方法或将成为大模型未来的重要发展方向。甚至如果结合时下流行的强化检索,或许能够进一步增强这类新型的 RAG。如果你正在探索如何让语言模型更智能地处理论文、小说或报告等结构复杂的信息源,ReadAgent 提供了一个值得借鉴的解决思路。
本文代码已经开源,不过是个 Demo:
https://github.com/read-agent/read-agent.github.io/blob/main/assets/read_agent_demo.ipynb
同时还有 HuggingFace 的 Demo 可测试:
https://huggingface.co/spaces/ReadAgent/read-agent
最后,其实有一个开源项目叫做PageIndex,看起来就是模拟谷歌 DeepMind 团队的工作,不过做了一半只有构建摘要部分,没有检索部分。
开源地址:https://github.com/VectifyAI/PageIndex
转载请注明:拒绝碎片化 RAG,谷歌 DeepMind 推出 ReadAgent:模拟人类阅读长文本,或是NotebookLM底层技术? | AI工具大全&导航
相关文章
