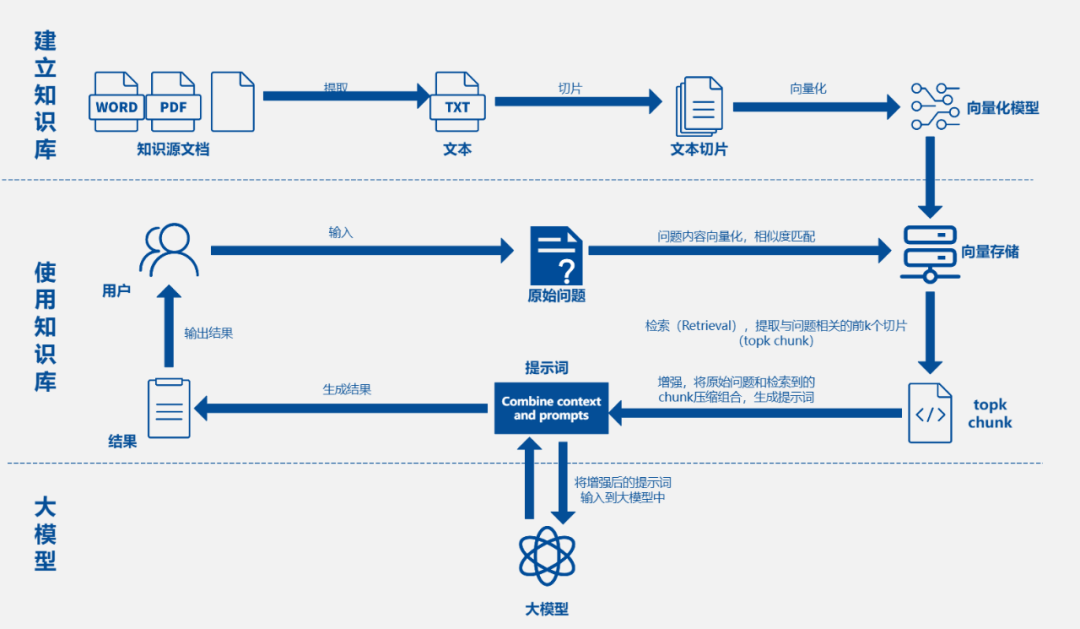
这篇文章详细解释了一张AI大模型知识问答架构图,主要内容如下:
一、整体流程概述
AI大模型知识问答架构图展示了构建和使用基于大语言模型的知识问答系统的核心流程,分为知识库构建(离线处理)和知识问答(在线使用)两大阶段。
二、知识库构建阶段
1. 知识源准备
● 以各种文档格式(如WORD、PDF、TXT等)存在的知识原材料为起始点。
2. 文本提取
● 从源文档中提取纯文本内容,去除格式信息,只保留核心文字信息(TXT)。
3. 文本切片
● 将提取出的大段文本切割成更小、语义相对完整的片段(Chunk),切片大小需平衡信息完整性和检索效率,可按段落、固定字符数或句号切分等规则进行。
4. 向量化
● 使用专门的向量化模型(如text - embedding - ada - 002等嵌入模型),将每个文本切片Chunk转换成固定长度的数值向量,该向量代表文本切片的语义信息,含义相近的文本向量在向量空间中较接近。
5. 向量存储
● 将所有文本切片对应的向量以及原始文本内容(有时还包括元数据),存储到优化的向量数据库(如ChromaDB、Faiss、Milvus、Pinecone等),这是后续高效相似性搜索的基础。
三、知识问答阶段
1. 用户提问
● 用户输入自然语言问题(原始问题)。
2. 问题向量化
● 使用与构建知识库时相同的向量化模型,将用户原始问题转换成数值向量,代表问题的语义。
3. 相似度匹配与检索
● 在向量数据库中,通过比较用户问题向量和库中所有文本切片向量的相似度(常用余弦相似度或点积),检索出与问题语义最相似的前K个文本片段(topk chunk),K为可调节参数。
4. 提示词组合与增强
● 将原始问题与检索到的topk chunk的文本内容组合,形成更丰富、上下文更清晰的提示词,此过程可能包括对检索到的文本进行精炼,去掉冗余信息后再与问题组合,称为“提示词工程”或“检索增强生成(RAG)”。
5. 大模型生成答案
● 把经过组合和增强的提示词输入大语言模型(如GPT系列、Claude系列、Llama系列等),大模型基于其强大的理解和生成能力,结合内置知识(训练时学到的),输出最终的自然语言答案。
6. 结果输出
● 大模型生成的答案返回给用户。
四、关键思想总结
1. RAG架构
● 体现检索相关知识片段(Retrieval)、用知识增强提示词(Augment)、让大模型生成答案(Generate)的核心思想,解决大模型易产生幻觉和无法引用最新/特定知识的问题。
2. 向量化与相似度搜索
● 向量化是计算机理解文本语义的关键技术,向量数据库实现海量知识中快速找到语义相关内容。
3. 模块化设计
● 清晰划分不同模块(知识库构建、文本提取、向量化、向量存储、检索、提示工程、大模型),便于技术选型和迭代,如可单独升级向量化模型或替换大模型。
4. 效率与准确性平衡
● 切片大小、检索数量、向量化模型选择、提示词构建方式等需在检索效率、内容相关性和最终答案质量之间平衡优化。
相关文章
