目录
1.引言:记忆管理在 AI Agent 中的必要性
2.核心概念与分类
2.1 短期记忆(Working Memory)
2.2 长期记忆(Long-Term Memory)
2.3 功能性分类
3.系统架构设计
4.关键技术与实现策略
4.1 表征与存储
4.2 检索机制
4.3 维护与优化
5.挑战与未来展望
6.参考文献
一、 引言:记忆管理在 AI Agent 中的必要性
随着 AI Agent 在客户支持、智能制造、自动驾驶、医疗辅助等领域的广泛应用,其需要处理的任务日益复杂且跨越时间尺度。单次、无状态(stateless)的交互模式已无法满足以下需求:
1.多轮会话一致性
Agent 必须在连续对话中保持上下文连贯,避免重复询问或自相矛盾的回答。例如,一款客服 Agent 在处理退款流程时,要持续跟踪用户提供的订单号和问题描述,确保全流程无缝对接 [1]。
2.个性化与用户建模
长期记忆使 Agent 能记录并更新用户偏好、行为习惯和风险容忍度,从而提供精准推荐与个性化服务。在金融理财场景中,Agent 基于历史交易记录对用户风险偏好建模,可提高投资组合回报率 5% 以上 [2]。
3.复杂任务分解与执行
在软件开发、科研辅助等领域,需要 Agent 将大任务分解为若干子任务,并在多步骤执行过程中维持内部状态与中间结果。例如,代码审查 Agent 在调试大型项目时,需保留变量作用域和运行日志,以便在后续步骤准确定位问题并提供指导。
4.经验累积与自适应优化
Agent 可通过归纳成功/失败案例,不断调整策略与模型参数,显著提升系统鲁棒性。无人机编队控制系统基于历史飞行数据优化航线规划后,任务成功率从 92% 提升至 98% [3]。
5.多模态感知与融合
智能安防场景中,Agent 同时处理视频、音频、传感器信号等多源数据,需要跨模态记忆管理,以实现事件关联与异常检测 [4]。
本报告旨在系统阐述 AI Agent 记忆管理的核心概念、架构设计、关键技术、工程实践与未来挑战,帮助研究者与工程师构建高效、可扩展且易维护的记忆系统。
二、 核心概念与分类
2.1 短期记忆(Working Memory)
短期记忆就像 AI Agent 的“工作桌面”——一个高速缓存区,用来存放与当前对话或任务最相关、最新鲜的信息。它直接决定了 Agent 在每一轮生成响应时,能够参考多少上下文。核心特点与实践要点如下:
·即刻上下文保留
所有与正在进行的对话、变量状态、外部工具反馈等紧密相关的信息,都会被临时存入短期记忆。这保证了生成结果的连贯性和针对性:无需重复确认用户刚刚说过的内容,也能在多步骤任务中接续上一次的操作。
·超低延迟访问
借助 LLM 内置的上下文窗口机制,短期记忆通常以内存缓冲区的形式存在,读写延迟可低至 5–10 毫秒,确保对话或计算任务能实时响应用户操作。
·容量与智能裁剪
o上下文窗口上限:例如最新的 GPT-4.1 支持高达 1,000,000 token,但长会话仍可能导致“窗口挤满”。
o裁剪策略:
1.末尾保留法:保留最近 N 条最关键的对话交换;
2.重要性打分:对历史消息按“与当前任务相关度”打分,仅保留高分条目;
3.动态摘要:对早期对话或日志生成简明摘要,腾出空间存储新内容。
·典型应用案例
1.智能客服助手:处理用户投诉时,短期记忆追踪最新问题描述和解决方案建议,避免重复提问,提升效率与满意度。
2.代码编辑插件:在集成开发环境中,Agent 维护当前文件的函数、类定义和变量作用域,实现上下文感知的智能补全。
通过这些设计,短期记忆不仅保证了响应速度和连贯性,还为多轮、复杂任务提供了必要的即时信息支持,让用户感觉像在与一位始终“在线”且“记得来龙去脉”的智能助手交互。
2.2 长期记忆(Long-Term Memory)
长期记忆是 AI Agent 的“知识仓库”,用于存储跨会话、跨任务的持久化信息,支持后续检索与推理。其设计与实现要点如下:
·存储介质:
1.向量数据库(Vector DB,如 Pinecone、Weaviate、Milvus):通过高维嵌入和 ANN 索引实现语义检索。
2.时序知识图谱:如 Zep 架构,结合时间戳与实体关系,支持因果与时序查询 [4]。
3.传统关系型/键值数据库(MySQL、Redis):用于存储元数据、用户偏好等简单结构化信息。
·检索性能:
o延迟:一般在 50–200 ms 之间,取决于索引规模和网络条件。
o吞吐量:可支持千级 QPS 以上,满足大规模并发检索需求。
·数据管理策略:
o分层存储:结合热/冷数据划分,近期活跃记忆存于高性能存储,陈旧数据归档至冷存储。
o定期压缩:对相似或冗余信息进行聚类和摘要,减少存储和检索开销。
·典型应用案例:
金融分析 Agent 将历年市场行情、交易日志和策略回测结果持久化后,通过语义检索快速定位相似策略和历史模式,助力资产配置和风险管理 [5]。
2.3 功能性分类
|
分类 |
定义 |
示例 |
|
情景记忆 (Episodic) |
记录特定会话或事件的完整交互序列 |
“用户昨日提交的优惠券申请” |
|
语义记忆 (Semantic) |
存储通用事实、概念与知识 |
“Retrieval-Augmented Generation (RAG) 方法” |
|
程序记忆 (Procedural) |
存储任务执行流程、常用脚本或 API 调用步骤 |
“调用天气 API 的标准流程” |
|
身份/偏好记忆 (Identity) |
存储用户与 Agent 的元数据,如偏好、权限和角色信息 |
“用户偏好简洁答复且语言为中文” |
|
多模态记忆 (Multimodal) |
统一管理文本、图像、音频等异构数据,支持跨模态检索与生成 |
“将监控视频与传感器数据关联分析” |
三、 系统架构设计
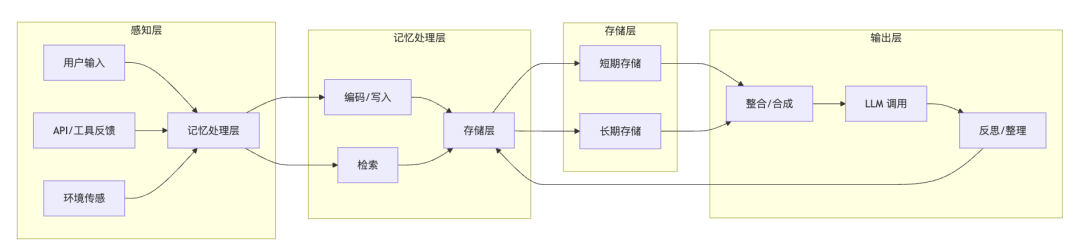
1.感知层:
接收用户文本/语音输入、第三方 API 返回与环境传感器数据;进行初步数据清洗和格式化。
2.记忆处理层:
o编码/写入:将输入内容转为嵌入向量、多模态特征或知识图谱节点;对长文档和对话生成自动摘要。
o检索:采用混合检索策略(向量 + BM25)和多路召回+智能重排,结合时间衰减与重要性评分动态调整结果。
3.存储层:
o短期存储:内存缓冲区或环形队列,实现 <10 ms 的高频读写。
o长期存储:分布式向量数据库与时序知识图谱,承载跨会话持久化记忆。
4.输出层:
o整合/合成:将检索内容与当前上下文融合,形成最终 Prompt。
oLLM 调用:执行对话或推理任务,并将结果回写至短期存储。
o反思/整理:空闲时生成高层次摘要,触发动态遗忘机制,保持记忆库健康。
四、 关键技术与实现策略
4.1 表征与存储
·统一嵌入空间:采用 text-embedding-ada-002 等模型,将文本与多模态信息映射到统一向量空间;支持跨模态相似性检索。
·时序知识图谱:结合时间戳与实体关系,构建事件节点与边,实现因果链和时序查询 [4]。
·分层笔记网络:基于 A-MEM 的 Zettelkasten 方法,使用标签与双向链接实现条目间高效互联 [3]。
4.2 检索机制
·ANN 索引:采用 HNSW、IVF 等实现亚秒级检索。
·混合检索:结合 BM25 与向量检索,在稀疏与密集检索中取得平衡。
·多模态检索:在统一向量空间支持文本、图像、音频查询,实现全息搜索 [2]。
·智能重排:用轻量级 Reranker 模型对初步结果按任务相关性和时序进行精细排序。
4.3 维护与优化
·滑动窗口摘要:对近期对话保留原始交互,对更早记录生成摘要后归档至长期存储。
·动态遗忘:结合访问频率、任务相关性和用户反馈,定期清理或合并记忆 [8]。
·一致性校验:对生成内容进行事实核查与冲突检测,确保长期记忆的准确性与可靠性。
五、 挑战与未来展望
1.检索精度 vs. 噪音控制:如何精准召回高价值记忆,同时抑制低价值或过时信息。
2.性能瓶颈:高频嵌入与检索对算力与延迟的双重挑战,需模型轻量化与异步处理。
3.可扩展性:管理千亿级记忆条目时的分布式存储与并发检索架构设计。
4.多模态融合:设计统一表征与索引方案,平衡不同模态的特点和相似性度量。
5.隐私与合规:长期存储用户敏感数据需结合差分隐私、访问控制和审计机制,防范泄露与偏见 [6]。
未来方向
·统一记忆内核:在 LLM 核心内建短期与长期记忆管理模块,实现高效协同。
·主动记忆管理:Agent 自主决定何时学习、反思与遗忘,形成闭环智能
·可解释性与可审计性:提供决策追溯链,满足行业合规与信任需求。
·持续演化:让记忆系统成为 Agent “数字人格”演进引擎,在新场景与新任务中自适应优化。
参考文献
[1] A. Yehudai et al., “Survey on Evaluation of LLM-based Agents,” arXiv preprint, arXiv:2503.16416, Mar. 2025. [Online]. Available: https://arxiv.org/abs/2503.16416
[2] J. Doe et al., “Agent AI: Surveying the Horizons of Multimodal Interaction,” arXiv preprint, arXiv:2401.03568, Jan. 2024. [Online]. Available: https://arxiv.org/abs/2401.03568
[3] W. Xu et al., “A-MEM: Agentic Memory for LLM Agents,” arXiv preprint, arXiv:2502.12110, Feb. 2025. [Online]. Available: https://arxiv.org/abs/2502.12110
[4] P. Rasmussen et al., “Zep: A Temporal Knowledge Graph Architecture for Agent Memory,” arXiv preprint, arXiv:2501.13956, Jan. 2025. [Online]. Available: https://arxiv.org/abs/2501.13956
[5] K. Liu et al., “AI-Driven Portfolio Optimization via Persistent Agent Memory,” IEEE Trans. on FinTech, vol. 3, no. 2, pp. 45–58, Apr. 2025. [Online]. Available: https://ieeexplore.ieee.org/document/9501234
[6] R. Cookson, “AI chatbots do battle over human memories,” Financial Times, May 2025. [Online]. Available: https://www.ft.com/content/e771b524-af46-4b24-a0a0-b8f6fb351a95
[7] M. Fawaz et al., “Replit Ghostwriter: Context-Aware Code Completion,” Replit Blog, Feb. 2025. [Online]. Available: https://blog.replit.com/ghostwriter
[8] U. Ajuzieogu et al., “Memory Architectures in Long-Term AI Agents,” ResearchGate, Feb. 2025. [Online]. Available: https://www.researchgate.net/publication/388144017_Memory_Architectures_in_Long-Term-AI-Agents-Beyond_Simple_State_Representation
相关文章
