多模态RAG的三类图文问答实现方式,你知道多少种?

? 文章目标
本文面向 RAG 图文混合问答系统感兴趣的读者,旨在帮助大家:
-
理解图文混合问答系统的核心原理:了解嵌入型、检索型和生成型图文问答系统的基本概念和区别。 -
掌握嵌入型图文问答的实现方法:详细学习如何通过分析Markdown中的图片,结合视觉语言模型(VLM)和大型语言模型(LLM)构建一个有效的图文问答系统。 -
学习关键技术点的处理:包括图片URL提取、异步批量图片分析、图文内容融合以及如何让大模型理解并输出相关图片。
? 小提示
本次文章配套代码开源地址:https://github.com/li-xiu-qi/XiaokeAILabs/tree/main/datas/mixd_image_text
? 目录
-
? 文章目标 -
? 前言 -
三类实现图文问答的方式 -
?️ 系统架构概览 -
⚙️ 核心技术实现 -
? 1. 图片内容智能分析 -
? 2. 图片URL提取与预处理 -
⚡ 3. 批量异步图片分析 -
? 4. 图文内容融合 -
? 核心技术难点:如何让大模型知道输出哪些图片 -
? 5. 智能问答生成 -
? 系统工作流程 -
?? 技术解释 -
?️ 实际应用示例 -
原始Markdown内容 -
经过AI增强后 -
? 更多Markdown图片语法示例 -
?️ 使用方法 -
? 快速开始 -
? 1. 环境准备 -
? 2. 配置API密钥 -
?️ 3. 运行图片增强脚本 -
? 4. 启动问答界面 -
❓ 5. 试试这些问题 -
? 6. 实际效果 -
? 常见问题 -
? 往期精选
? 前言
本文围绕 嵌入型图文混合问答系统的实现 展开,核心内容包括:
-
图文问答系统的不同类型及其特点。 -
嵌入型图文问答系统的详细技术架构和工作流程。 -
图片内容智能分析、URL提取、异步处理、图文融合等关键技术的实现细节。 -
如何通过语义标注和上下文关联让大型语言模型理解并引用图片。
图文混合问答是当前AI领域的一个热门研究方向,能够让机器更好地理解和回应包含视觉信息的用户查询。本文详细介绍了一种嵌入型图文混合问答系统的实现原理与技术架构。我们将探讨如何从Markdown文档中提取图片信息,利用视觉语言模型(VLM)对图片内容进行智能分析和描述生成,并将这些视觉信息与文本内容有效融合。通过异步批量处理、正则表达式图片链接提取、AI描述增强等技术,系统能够高效处理图文混合内容。最终,大型语言模型(LLM)基于增强后的图文内容生成包含相关图片的准确回答。本文旨在为开发者提供一个清晰、可实践的嵌入型图文问答系统构建介绍。
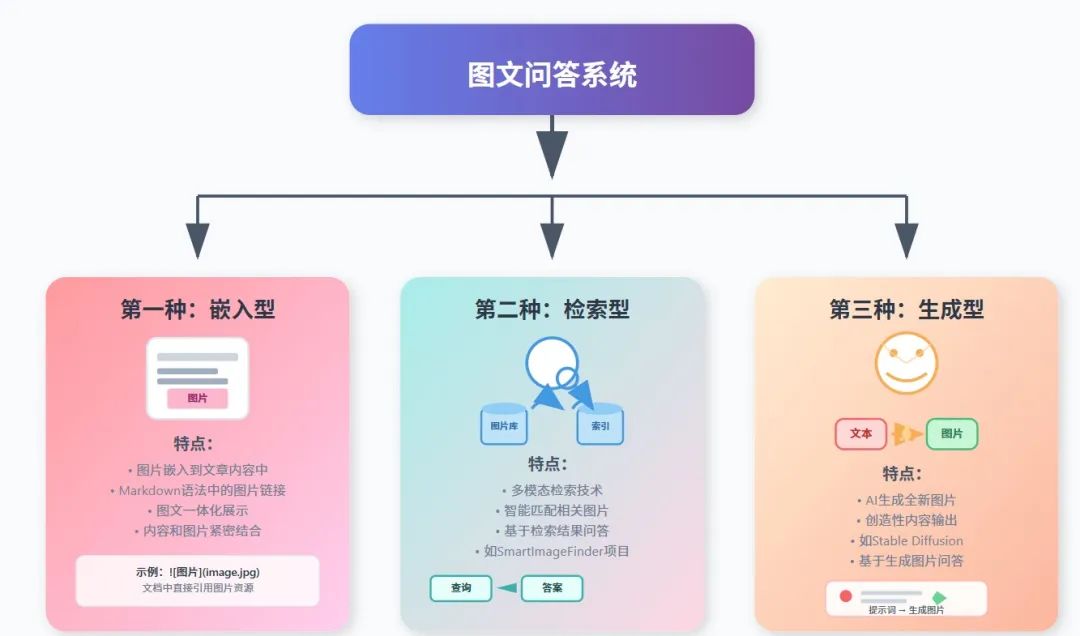
三类实现图文问答的方式
最近有群友问我:图文问答是如何实现的呢?本来我觉得过于简单了,但是对于某些人群来说,这确实是个很有意思的问题,所以本次专门准备了这篇文章来详细聊聊。
其实图文问答有多种实现方式,我可以把它分成三个主要类别:
第一种:嵌入型
嵌入型就是指图片是嵌入到文章或者说参考内容里面的,比如Markdown语法里面同时嵌入了图片链接,这就是嵌入型。本次教程使用的就是嵌入型,我们会详细讲解如何实现。
第二种:检索型
检索型可以参考我的SmartImageFinder项目,地址在:
https://github.com/li-xiu-qi/SmartlmageFinder
,本质上就是通过多模态检索的形式对图片进行检索,然后结合检索到的图片进行问答,但在这之前,也是需要对图片进行一些描述性的工作,不然效果也不太好。SmartImageFinder 是一个智能的图片搜索引擎和管理系统,能够实现精准的文本搜图、以图搜图等智能检索方式,同时提供完整的图片管理解决方案。该项目采用 FastAPI + React 技术栈,集成 Jina CLIP V2 和多模态大语言模型,为个人图片管理提供一站式解决方案。
第三种:生成型
生成型可以是类似Stable Diffusion这类图片生成模型生成的图片,再让模型基于生成的图片输出带有图片的答案,或者反过来说先生成文本,再使用大模型调用工具使得输出对应的配图,并且插入到文章里面。
其他细分
当然,嵌入型还有其他的细分实现方式:
-
比如我的SmartPaper项目,地址:https://github.com/li-xiu-qi/SmartPaper/tree/dev里面的嵌入型是另外一种实现方式。SmartPaper 是一个专为研究人员、学者和学生设计的智能学术论文处理系统,能够自动化论文获取、解析、内容提取和分析等任务。系统利用先进的 AI 模型(如 GPT 系列、Qwen 系列等)和版面分析技术,提供高效、准确的论文理解和信息提取服务。无论您是研究人员、学生还是对最新研究感兴趣的专业人士,SmartPaper 都能帮助您更高效地理解和提炼复杂的学术内容。 -
还有我最近的金融研报项目,地址:https://github.com/li-xiu-qi/financial_research_report里面的生成型也是另外一种实现方式
感兴趣的同学可以看看,但是我们不能一次性讲太多,要渐进式学习哈?
文章内容来源
顺便提一下,本次教程的核心技术其实是从我的另一个项目 Linka 中抽离出来的一个重要知识点。
Linka 是一个基于大语言模型的智能联网搜索系统,为每个回答提供详细的信息来源和引用链接,确保信息的可靠性,专注于提供准确、实时的信息检索,能够在回答中智能地插入相关图片,提供更直观的信息展示。
我们今天要讲的嵌入型图文问答系统正是 Linka 项目中的一个重要技术环节——当 Linka 从网页中提取到包含图片的内容时,就需要使用类似的技术来让大模型理解和处理这些图文混合的信息。
觉得有收获记得给我点赞、关注,转发给需要的人,作者的创作能量就差您这关键的一份鼓励,您的支持必不可少!本次教程的完整代码可以在这里找到:地址:https://github.com/li-xiu-qi/XiaokeAILabs/tree/main/datas/mixd_image_text
好了,言归正传,今天我们主要聊聊嵌入型图文问答系统的具体实现。
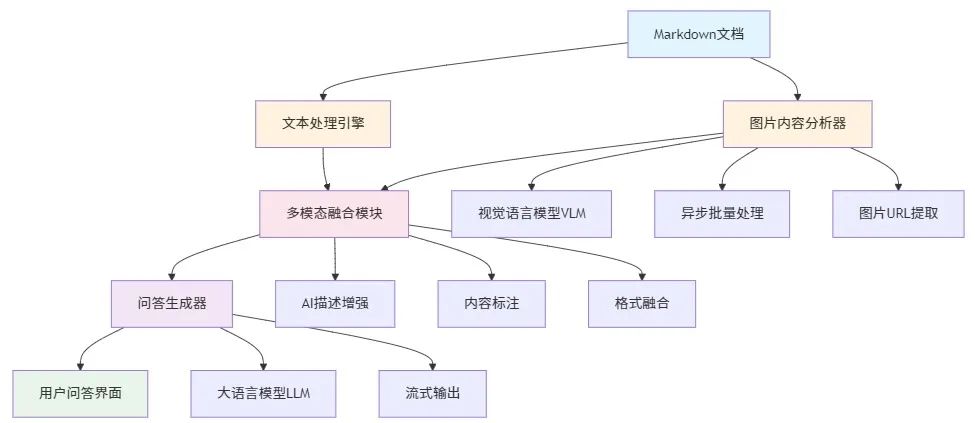
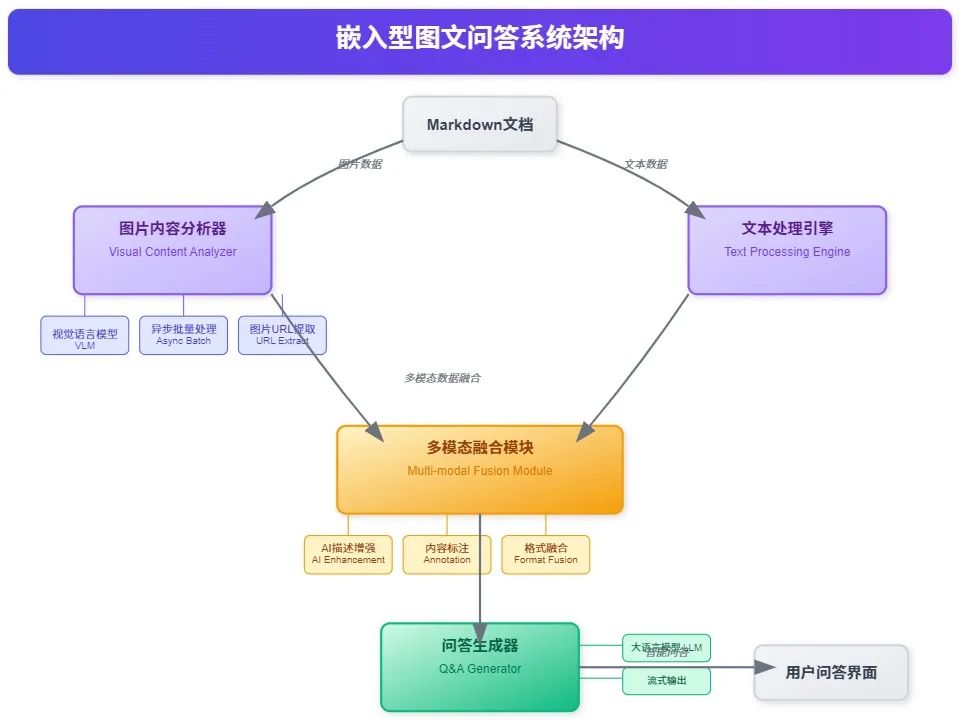
?️ 系统架构概览
图文混合问答系统主要包含以下几个核心组件:
-
图片内容分析器 - 负责提取和理解图片中的视觉信息 -
文本处理引擎 - 处理Markdown文档中的文本内容 -
多模态融合模块 - 将图片分析结果与文本内容整合 -
问答生成器 - 基于融合后的内容生成最终答案
⚙️ 核心技术实现
? 1. 图片内容智能分析
系统的第一个关键步骤是对文档中的图片进行智能分析。我们使用了基于视觉语言模型(VLM)的异步图片分析技术:
class MarkdownImageEnhancer:
def __init__(self, provider="zhipu", api_key=None, vision_model=None):
self.provider = provider
self.api_key = api_key
self.vision_model = vision_model
技术特点:
-
异步处理:支持批量图片的并发分析,大幅提升处理效率 -
多模型支持:可配置不同的视觉模型提供商(如智谱AI、OpenAI等) -
智能提取:自动识别Markdown中的图片链接并提取相关信息
? 2. 图片URL提取与预处理
系统使用正则表达式提取Markdown文档中的图片信息:
IMG_TAG_RE = re.compile(r'![([^]]*)]((https?://[^)]+))', re.IGNORECASE)
? Markdown图片和链接语法基础
在深入解析正则表达式之前,我们先回顾一下Markdown中图片和链接的基本语法:
图片语法
Markdown图片语法遵循以下格式:

语法构成:
-
!- 感叹号,区别于链接语法 -
[alt文本]- 方括号内的替代文本,当图片无法显示时展示 -
(图片URL)- 圆括号内的图片地址 -
"可选标题"- 可选的图片标题,鼠标悬停时显示
示例:

 <!-- 空的alt文本 -->
 <!-- 相对路径 -->
链接语法
Markdown链接语法格式:
[链接文本](URL "可选标题")
对比图片和链接:
|
|
|
|
|---|---|---|
|
|
 |
 |
|
|
[链接文本](URL) |
[点击这里](https://example.com) |
关键区别就是图片语法前面有感叹号!
支持的图片格式
我们的系统主要处理远程图片(HTTP/HTTPS协议),常见格式包括:
-
.jpg/.jpeg- JPEG格式 -
.png- PNG格式 -
.gif- GIF动图 -
.webp- WebP格式 -
.svg- SVG矢量图
实际应用场景
在RAG系统中,我们经常遇到这些情况:
# 技术文档示例

> 这是我们的整体系统架构,包含前端、后端和数据库三层结构。
详细的实现可以参考[官方文档](https://docs.example.com)。

> 业务处理流程从用户请求开始,经过验证、处理、存储等多个环节。
让我们详细解析这个正则表达式的构成:
正则表达式详解
整体结构:![([^]]*)]((https?://[^)]+))
-
!- 匹配感叹号,Markdown图片语法的开始标识 -
[- 匹配左方括号[,需要转义因为方括号在正则中有特殊含义 -
([^]]*)- 第一个捕获组,匹配alt文本
-
[^]]*表示匹配任意数量(包括0个)的非右方括号字符 -
外层的 ()表示这是一个捕获组,用于提取alt文本
] - 匹配右方括号],需要转义( - 匹配左圆括号(,需要转义(https?://[^)]+) - 第二个捕获组,匹配图片URL-
https?://匹配http://或https://(`?`表示s可选) -
[^)]+匹配一个或多个非右圆括号的字符 -
外层的 ()表示这是第二个捕获组,用于提取URL
) - 匹配右圆括号),需要转义 re.IGNORECASE标志的作用
re.IGNORECASE(也可以写作re.I)是一个编译标志,作用是:
-
忽略大小写:让正则表达式在匹配时不区分大小写 -
实际效果:这意味着 HTTP://、Http://、http://、HTTPS://等都能被正确匹配 -
使用场景:因为URL中的协议部分可能有不同的大小写写法,使用这个标志可以确保所有情况都能被捕获
匹配示例
 ✅ 匹配
 ✅ 匹配(大写协议)
 ✅ 匹配(空alt文本)
这个正则表达式能够:
-
匹配标准的Markdown图片语法 -
提取图片的alt文本和URL -
支持HTTP/HTTPS协议的远程图片 -
忽略协议部分的大小写差异
⚡ 3. 批量异步图片分析
为了提高处理效率,系统采用了异步批量处理机制:
async def analyze_images_batch(self, img_info_list):
async with AsyncImageAnalysis(
provider=self.provider,
api_key=self.api_key,
max_concurrent=self.max_concurrent,
) as analyzer:
image_sources = [{"image_url": info['url']} for info in img_info_list]
results = await analyzer.analyze_multiple_images(image_sources)
return results
优势:
-
并发控制:通过 max_concurrent参数控制并发数量,避免API限流 -
资源管理:使用异步上下文管理器确保资源正确释放 -
错误处理:内置错误处理机制,提高系统稳定性
? 4. 图文内容融合
系统将AI分析的图片描述与原始文本内容进行智能融合:
def replace_img_with_analysis(self, markdown, img_info_list, analysis_results):
# 使用AI分析的标题替换原始alt文本
ai_title = result.get("title", "").strip()
title = ai_title or original_alt or "图片"
# 获取AI生成的详细描述
ai_desc = result.get("description", "").strip()
# 构建增强的Markdown格式
new_img_md = f""
if ai_desc:
formatted_desc = "n".join(f"> {line}" for line in ai_desc.splitlines())
new_img_md += f"n{formatted_desc}"
融合策略:
-
标题优化:使用AI生成的图片标题 -
描述增强:在图片下方添加详细的描述信息 -
格式保持:保持Markdown的标准格式,确保兼容性
? 核心技术难点:如何让大模型知道输出哪些图片
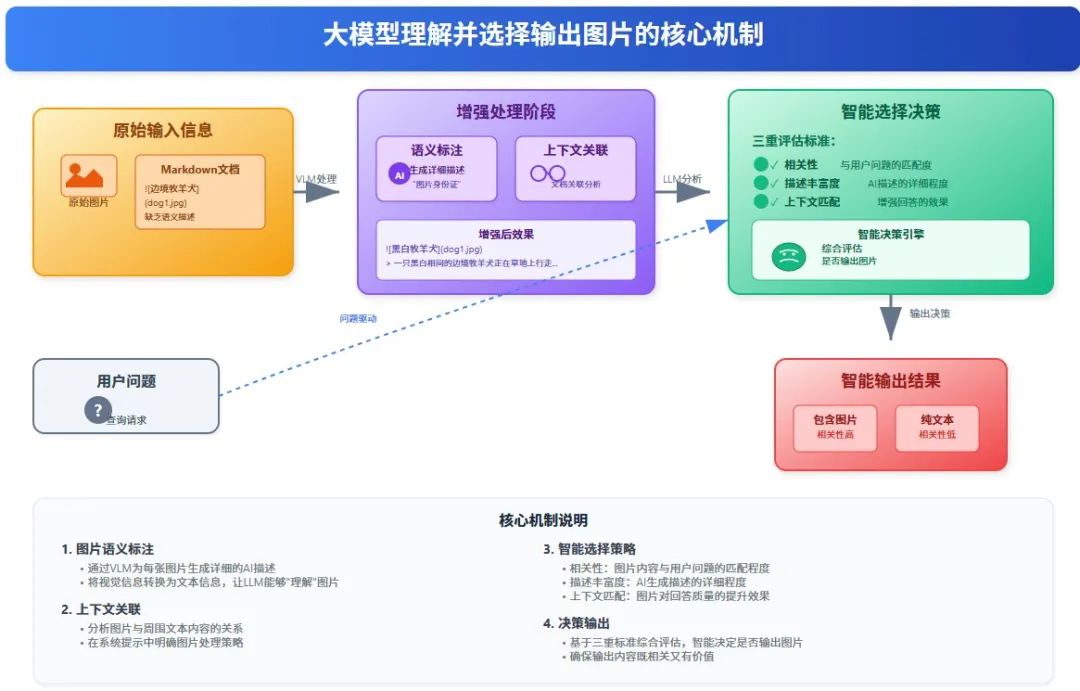
这里有个很关键的技术点,很多同学可能会忽略:如何让大模型知道什么图片是可以输出的?
本质上,大模型并不能直接"看到"图片,它只能理解文本。所以我们需要通过以下策略来解决这个问题:
1. 图片语义标注
我们为每张图片添加详细的AI生成描述,这些描述就像是"图片的自我介绍":

> 一只黑白相间的边境牧羊犬正在草地上行走,背景是绿色的植物和树木。
从而能够让语言模型能够更好的理解我们提供的参考内容。
为什么要使用多模态模型对图片进行解释呢?我们能直接输入图片链接给多模态模型进行理解吗?当然是不可以的,因为文本输入是没有图片特征的。即使是多模态模型,当我们给它传入一个http://example.com/image.jpg这样的文本链接时,它看到的只是一串字符,而不是图片的实际内容。多模态模型需要的是图片的像素数据或者图片的特征向量,而不是一个URL字符串。因此,我们必须先用视觉模型将图片内容转换为文字描述,这样后续的语言模型才能"理解"图片包含的信息,因为最终输出的还是靠文本模型,自然我们需要将图片转换成语言模型能够理解的方式进行。
2. 上下文关联
通过将图片描述与周围文本内容进行关联,让大模型理解图片在文档中的作用:
# 在系统提示中明确告知大模型如何处理图片
sys_prompt = """
你是一个人工智能助手,能够回答用户的问题,并且可以参考提供的内容。请根据用户的问题和参考内容生成准确的回答。
参考内容可能包含多个段落,请确保回答时充分利用这些信息。
如果参考内容中有图片,你可以适当选择合适的图片进行引用并使用 markdown 的语法输出到回答中。
"""
3. 图片选择策略
大模型会根据以下条件来决定是否输出某张图片:
-
相关性:图片内容是否与用户问题相关 -
描述丰富度:图片是否有足够详细的AI描述 -
上下文匹配:图片是否能增强回答的效果
这就是为什么我们需要对图片进行AI分析和描述增强的核心原因——让大模型通过文字描述来"理解"图片内容,从而做出正确的输出决策。
? 5. 智能问答生成
系统使用大语言模型(LLM)基于增强后的内容生成答案:
def call_guiji_rag_model_stream(query, chat_history=None):
reference_content = get_reference_content()
prompt = f"请根据以下参考内容回答用户的问题:{query}nn下面是参考内容:n{reference_content}"
sys_prompt = """
你是一个人工智能助手,能够回答用户的问题,并且可以参考提供的内容。请根据用户的问题和参考内容生成准确的回答。
参考内容可能包含多个段落,请确保回答时充分利用这些信息。
如果参考内容中有图片,你可以适当选择合适的图片进行引用并使用 markdown 的语法输出到回答中。
"""
? 系统工作流程
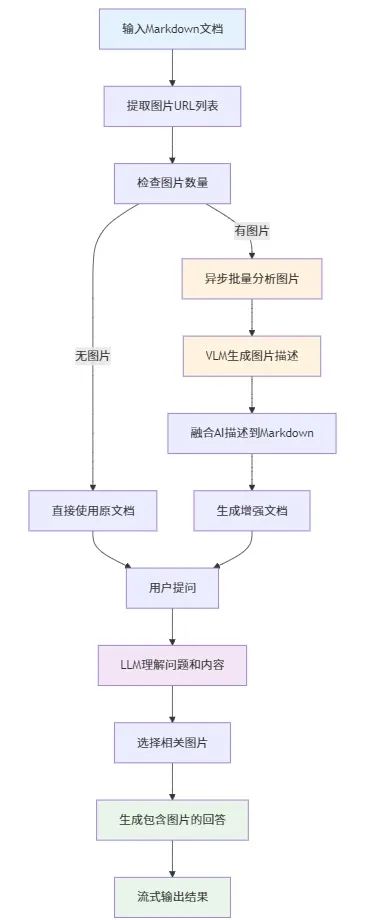
从流程图中可以看到,整个系统的工作流程采用了一个异步处理设计。当系统接收到Markdown文档后,首先会进行内容预处理,通过我们前面提到的正则表达式提取出所有图片URL。接下来进入关键的分支判断:如果文档中包含图片,系统会启动异步批量分析流程,这里我们采用了异步方案来突破Python全局解释器锁(GIL)的限制,让多个图片可以"同时"调用视觉模型API进行分析,而不是串行等待。
当VLM完成图片描述生成后,系统会将这些AI生成的描述融合到原始Markdown文档中,形成一个"增强版"的文档。这个增强过程就是我们前面详细解释的正则替换机制发挥作用的时候。最终,当用户提出问题时,大语言模型基于这个包含了丰富图片描述的增强文档来理解问题和选择相关图片,并通过流式输出的方式实时返回包含图片的完整回答。
?? 技术解释
上面为什么使用异步的方式呢?这主要是因为Python存在全局解释器锁(GIL)的限制,在处理大量图片时,如果采用传统的同步方式,程序会串行等待每个API调用完成,这样的效率是很低的。通过异步编程,我们可以巧妙地绕过GIL的限制,让程序在等待网络响应的同时可以处理其他任务,实现类似并发的效果,大幅提升了处理效率。
为什么要使用多模态模型对图片进行解释呢?我们能直接输入图片链接给多模态模型进行理解吗?当然是不可以的,因为文本输入是没有图片特征的。即使是最先进的多模态模型,当我们给它传入一个http://example.com/image.jpg这样的文本链接时,它看到的只是一串字符,而不是图片的实际内容。多模态模型需要的是图片的像素数据或者图片的特征向量,而不是一个URL字符串。因此,我们必须先用视觉模型将图片内容转换为文字描述,这样后续的语言模型才能"理解"图片包含的信息。
那么我们的正则表达式替换机制是如何起作用的呢?系统的关键在于如何将AI生成的图片描述无缝融入原始Markdown文档。我们使用正则表达式![([^]]*)]((https?://[^)]+))来定位每个圖片标签,然后通过替换函数将AI分析结果以引用格式(> 描述内容)添加到图片下方。这种设计既保持了Markdown的标准格式,又让大模型能够通过文字描述"理解"图片内容,实现了技术上的优雅融合。
?️ 实际应用示例
让我们看看这个系统在实际使用中的效果。比如有一篇关于狗狗的文章,包含了多张狗狗的图片:
原始Markdown内容

边境牧羊犬是世界上最聪明的狗品种之一...
经过AI增强后

> 一只黑白相间的边境牧羊犬正在草地上行走,背景是绿色的植物和树木。
边境牧羊犬是世界上最聪明的狗品种之一...
可以看到,系统不仅优化了图片的标题,还添加了AI生成描述,这样当用户问"这篇文章里的狗长什么样"时,大模型就能基于这些描述给出准确的回答,当然,还有另外一种方式,也就是原文当中本身就对图片进行了标注,使得语言模型明确的知道对应的图片说的内容是什么,那个时候就不需要使用这样的方式进行明确的标注,但是我们在这里对图片进行标注,在一定程度上一定是能够有效提升模型输出图片的概率。
? 更多Markdown图片语法示例
为了让大家更好地理解系统处理的各种情况,这里提供更多实际的Markdown语法示例:
基础图片语法
# 不同的图片引用方式
## 1. 标准格式(带alt文本和标题)

## 2. 只有alt文本

## 3. 空alt文本(不推荐,但系统支持)

## 4. 相对路径图片(系统不处理,但语法有效)

## 5. 不同协议的URL



系统增强后的效果对比
原始内容:

这是我们系统的整体架构设计。

数据处理的完整流程如上图所示。
AI增强后:

> 一个清晰的系统架构图,显示了前端、后端、数据库和缓存层之间的交互关系,采用微服务架构设计。
这是我们系统的整体架构设计。

> 详细的数据流程图,展示了从数据输入、处理、验证到存储的完整过程,包含多个处理节点和决策分支。
数据处理的完整流程如上图所示。
与链接语法的对比
# 图片 vs 链接语法对比
<!-- 这是图片,会被我们的系统处理 -->

<!-- 这是链接,不会被图片处理系统处理 -->
[访问 GitHub](https://github.com)
<!-- 图片链接组合(图片包装在链接中) -->
[](https://example.com/fullsize.jpg)
常见的边界情况
我们的正则表达式能够正确处理这些边界情况:
# 边界情况测试
## 1. URL中包含特殊字符

## 2. 多行格式(Markdown标准支持)

## 3. URL中的端口号

## 4. 不同的图片格式




系统不处理的情况
以下情况不在我们的处理范围内(但在完整的Markdown处理器中是有效的):
# 系统不处理的图片语法
## 1. 本地文件路径


## 2. 引用式图片
![Alt text][image-ref]
[image-ref]: https://example.com/image.jpg "图片标题"
## 3. HTML img标签
<img src="https://example.com/pic.jpg" alt="HTML图片" />
## 4. 非HTTP协议


这些详细的语法示例帮助我们理解:
-
系统的处理范围 - 主要针对HTTP/HTTPS远程图片 -
正则表达式的匹配逻辑 - 为什么要这样设计 -
实际应用中的各种情况 - 让开发者知道什么会被处理,什么不会
?️ 使用方法
使用起来非常简单,只需要几行代码:
from markdown_image_enhancer import enhance_markdown_images
# 增强Markdown内容
enhanced_content = enhance_markdown_images(
markdown_content,
provider="zhipu",
api_key="your_api_key"
)
然后就可以用增强后的内容来做问答了。
? 快速开始
想要快速体验这个图文问答系统吗?跟着下面的步骤,几分钟就能跑起来!
? 1. 环境准备
首先克隆项目代码:
git clone https://github.com/li-xiu-qi/XiaokeAILabs.git
cd XiaokeAILabs/datas/mixd_image_text
安装依赖包:
pip install streamlit openai python-dotenv asyncio aiofiles
? 2. 配置API密钥
如果没有api_key,那么请你到https://cloud.siliconflow.cn/i/FcjKykMn获取对应的key哦? 创建.env文件并配置你的API密钥:
# 智谱AI配置(用于图片分析)
ZHIPU_API_KEY=your_zhipu_api_key
ZHIPU_BASE_URL=https://open.bigmodel.cn/api/paas/v4/
ZHIPU_VISION_MODEL=glm-4v-flash
# 硅基流动配置(用于文本问答)
GUIJI_API_KEY=your_guiji_api_key
GUIJI_BASE_URL=https://api.siliconflow.cn/v1
GUIJI_TEXT_MODEL=Pro/DeepSeek-ai/DeepSeek-V3
完全使用硅基流动的也是可以的,比如配置成:
# 变量叫做智谱,只实际上指向硅基流动的key以及baseurl
ZHIPU_API_KEY=your_guiji_api_key
ZHIPU_BASE_URL=https://api.siliconflow.cn/v1
ZHIPU_VISION_MODEL=Pro/Qwen/Qwen2.5-VL-7B-Instruct
# 硅基流动配置(用于文本问答)
GUIJI_API_KEY=your_guiji_api_key
GUIJI_BASE_URL=https://api.siliconflow.cn/v1
GUIJI_TEXT_MODEL=Pro/deepseek-ai/DeepSeek-V3
?️ 3. 运行图片增强脚本
先对Markdown文档进行图片分析增强:
python data_process.py
这个脚本会:
-
读取 web_datas目录下的Markdown文件 -
调用视觉模型分析其中的图片 -
生成带有AI描述的增强版文档
? 4. 启动问答界面
运行Streamlit应用:
streamlit run main.py
然后在浏览器中打开 http://localhost:8501,就可以开始体验图文问答了!
❓ 5. 试试这些问题
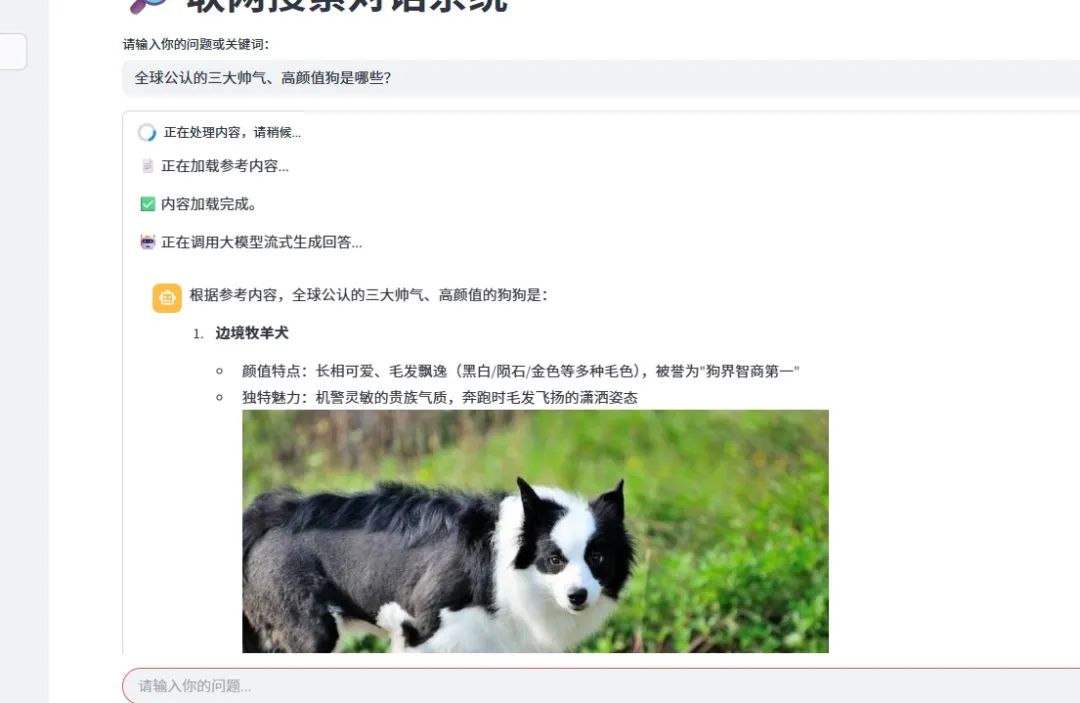
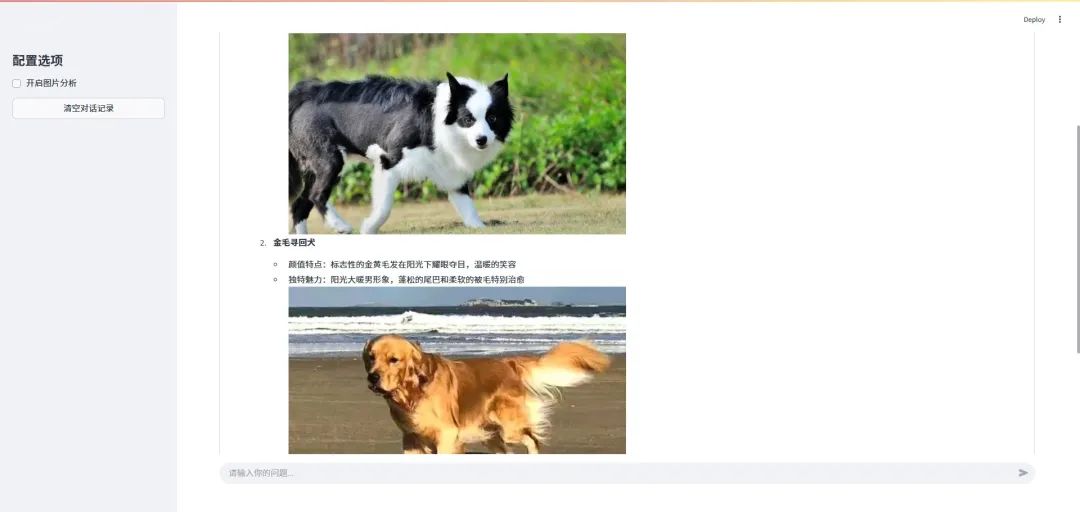
在问答界面中,你可以尝试问这些问题:
-
"这篇文章介绍了哪些狗的品种?" -
"边境牧羊犬长什么样?"
系统会基于增强后的图片描述给出包含图片的详细回答。
? 6. 实际效果
? 常见问题
Q: 如果没有API密钥怎么办?A: 你需要在智谱AI开放平台或者硅基流动注册账号获取API密钥。 硅基流动的key可以去https://cloud.siliconflow.cn/i/FcjKykMn获取。,其他平台的也可以,只需要兼容openai格式即可。Q: 可以使用其他模型吗?A: 可以!修改.env文件中的模型配置即可,系统支持多种视觉和文本模型。
Q: 图片分析很慢怎么办?A: 在markdown_image_enhancer.py中调整max_concurrent参数来控制并发数量。
? 往期精选
-
从零开始:构建你的专属Agent工具调用系统,从底层理解! -
别再做AI"黑盒"开发者!用实验了解Qwen2.5预测机制,让你更好"理解"大模型 -
Embedding模型微调:基于已有数据快速构建训练与评估数据集 -
我的RAG爬坑与进阶之路:一次元认知驱动的探索经验分享 -
摆脱Faiss束缚:sqlite-vec如何在RAG中实现SQLite的原生向量检索轻量化
相关文章
