OpenAI 的 o1 系列模型率先通过增加推理过程中思维链(Chain-of-Thought, CoT)的长度,引入了推理时扩展,在数学、编程和科学推理等各种推理任务中取得了显著的改进。先前的多项研究探索了不同的方法,包括基于过程的奖励模型、强化学习,以及蒙特卡洛树搜索和 Beam Search 等搜索算法。然而,这些方法均未能在通用推理性能上达到与 OpenAI 的 o1 模型相当的水平。
DeepSeek-AI 使用纯强化学习(RL)方法提升语言模型推理能力,探索大语言模型(LLMs)在没有任何监督数据的情况下发展推理能力的潜能,重点关注它们通过纯 RL 过程的自我进化。基于这一方法,DeepSeek-AI 发布了其第一代推理模型 DeepSeek-R1-Zero 和 DeepSeek-R1。其中,DeepSeek-R1 在推理任务上的表现与 OpenAI-o1-1217 相当,如下图所示。
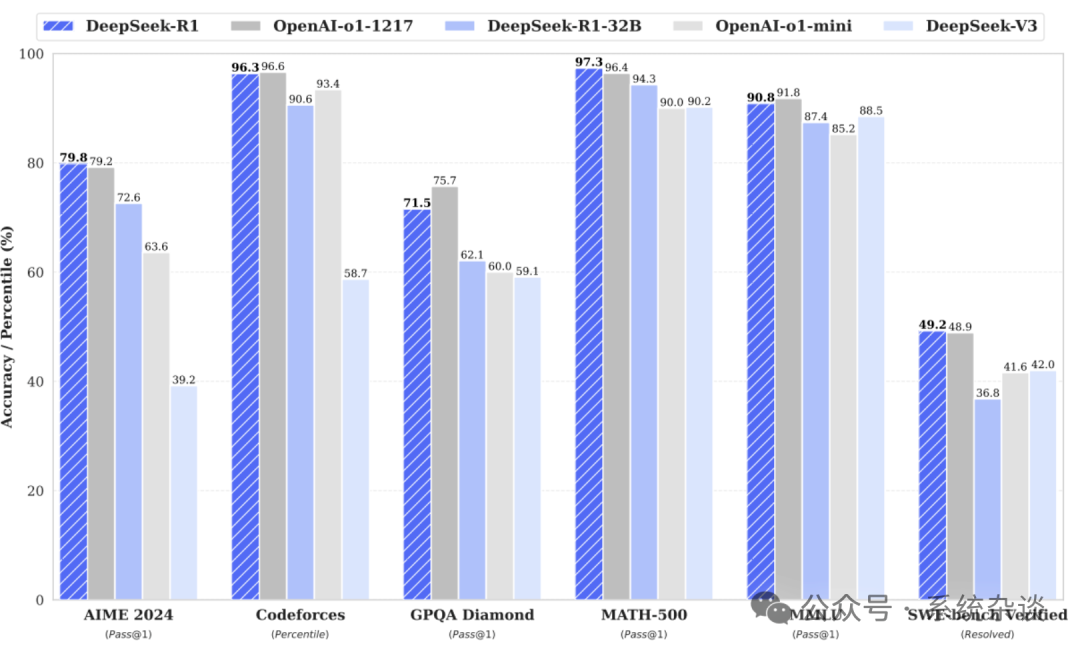
DeepSeek-R1-Zero 只通过强化学习 (RL) 训练,未经过监督微调 SFT) ,但展现出非凡的推理能力。然而,它面临着诸如可读性差和语言混杂等挑战。DeepSeek-R1,在 RL 之前加入了多阶段训练和冷启动数据,以解决这些问题并进一步提高推理性能,在推理任务上取得与 OpenAI-o1-1217 相当的性能。
如何训练 DeepSeek-R1-Zero
DeepSeek-R1-Zero 使用 DeepSeek-V3-Base 作为基础模型,并采用组相对策略优化(Group Relative Policy Optimization, GRPO)作为 RL 框架来提升模型的推理性能。
GRPO 通过组评分来估算基准,从而省略了通常与策略模型大小相同的价值模型。具体而言,对于每个问题 ,GRPO 从旧的策略 中采样一组输出 ,然后通过最大化以下目标来优化策略模型 :
其中, 和 是超参数, 是优势函数,通过使用与每组输出对应的奖励组 计算:
DeepSeek-R1-Zero 采用了一种基于规则的奖励系统,主要由两种类型的奖励组成:
-
• 准确性奖励:准确性奖励模型评估响应是否正确。 -
• 格式奖励:格式奖励模型强制模型将其思维过程放置在‘<think>’和‘</think>’标签之间。
下图展示了 DeepSeek-R1-Zero 在 AIME 2024 基准测试中的性能轨迹,随着强化学习(RL)训练的进行,DeepSeek-R1-Zero 的表现持续稳步提升。值得注意的是,AIME 2024 上的平均 pass@1 得分显著上升,从初始的 15.6% 跃升至 71.0%,达到了与 OpenAI-o1-0912 相当的性能水平。这一显著的提升突显了 RL 算法在优化模型性能方面的有效性。

那么 RL 是如何有效泛化模型的呢?DeepSeek-R1-Zero 的自我进化过程展示了 RL 如何推动模型自主提升其推理能力。通过直接从基础模型启动 RL,可以密切监控模型的进展,而不受监督微调阶段的影响。这种方法提供了清晰的视角,展示了模型随时间的演变,特别是在处理复杂推理任务的能力方面。

如上图所示,DeepSeek-R1-Zero 的思考时间在整个训练过程中持续改进。这种改进不是外部调整的结果,而是模型内部的固有发展。DeepSeek-R1-Zero 通过延长测试时计算的时间,从生成数百到数千个推理标记,逐步提高了解决越来越复杂推理任务的能力,使得模型能够深入探索和优化其思维过程。
自我进化过程中最显著的一个方面是,当测试时计算增加时,模型表现出复杂的行为。例如,模型会进行反思——回顾并重新评估其之前的步骤——并探索解决问题的替代方法。这些行为并非显式编程产生,而是模型与强化学习环境互动的结果。这种自发的发展显著提升了 DeepSeek-R1-Zero 的推理能力,使其能够以更高的效率和准确性解决更具挑战性的任务。
DeepSeek-R1-Zero 的“顿悟时刻”(aha moment):在训练 DeepSeek-R1-Zero 时,观察到一个特别有趣的现象,即发生了一个“顿悟时刻”,如下图所示。在这个阶段,DeepSeek-R1-Zero 学会了通过重新评估其初始方法,将更多的思考时间分配给一个问题。这一行为不仅证明了模型推理能力的增长,还生动展现了强化学习如何带来意想不到且复杂的结果。

如何训练 DeepSeek-R1
DeepSeek-R1-Zero 面临可读性差和语言混杂等挑战。DeepSeek-R1 结合了少量的冷启动数据和多阶段训练流程,解决这些问题并进一步增强推理性能。DeepSeek-R1 训练策略包括四个阶段:冷启动、面向推理的强化学习、拒绝采样与监督微调,以及面向全场景的强化学习。
冷启动
与 DeepSeek-R1-Zero 不同,为避免基于原始模型的强化学习(RL)训练初期不稳定的冷启动阶段,DeepSeek-R1 构建并收集了少量长思维链数据,用于微调模型并作为初始的 RL actor。
DeepSeek-R1 收集了数千条冷启动数据,以微调 DeepSeek-V3-Base 作为 RL 的起点。与 DeepSeek-R1-Zero 相比,冷启动数据的优势包括:
-
• 可读性:DeepSeek-R1-Zero 的内容通常不适合阅读,例如多语言混杂或缺少 Markdown 格式使答案难以突出。相比之下,在为 DeepSeek-R1 创建冷启动数据时,设计了包含每条回复总结的可读模式,并筛选掉不够友好的回复。 -
• 性能潜力:通过结合人类经验精心设计冷启动数据模式,观察到相比 DeepSeek-R1-Zero 更优的性能。因此认为迭代训练是用于推理模型的更佳训练方法。
面向推理的强化学习
在冷启动数据上微调 DeepSeek-V3-Base 后,采用与 DeepSeek-R1-Zero 相同的 RL 训练过程,增强模型在推理任务中的能力,例如代码、数学、科学及逻辑推理等具有清晰解答的良好定义的问题。训练过程中观察到,思维链(CoT)中常出现语言混杂现象,尤其当 RL 提示涉及多种语言时。为缓解这一问题,在 RL 训练中引入了语言一致性奖励,该奖励通过计算思维链中目标语言词汇的比例得出。尽管消融实验显示此类对齐导致模型性能轻微下降,但这种奖励更符合人类偏好,使输出更具可读性。最终,将推理任务的准确性与语言一致性奖励相加,形成最终的奖励,并对微调模型进行强化学习,直至推理任务收敛。
拒绝采样与监督微调
当面向推理的 RL 收敛后,使用所得的检查点(checkpoint)生成 SFT 数据进行下一轮训练。与主要关注推理的冷启动数据不同,本阶段加入了其他领域的数据以增强模型在写作、角色扮演及其他通用任务中的能力。具体而言,数据生成与模型微调过程如下:
-
• 推理数据 精心挑选推理提示,并通过对上述强化学习(RL)训练检查点执行拒绝采样来生成推理轨迹。在之前的阶段中,仅包含可通过基于规则的奖励评估的数据;然而,在本阶段,通过引入额外数据来扩展数据集,其中一部分数据使用生成式奖励模型,即将真实答案和模型预测输入 DeepSeek-V3 进行判断。此外,由于模型输出有时混乱难读,过滤掉了混合语言、长段落及代码块的思维链。对每个提示,采样多个回复,并仅保留正确的答案。最终,总计收集了约 60 万条与推理相关的训练样本。 -
• 非推理数据 对于写作、事实问答、自我认知及翻译等非推理数据,采用 DeepSeek-V3 过程并复用部分 DeepSeek-V3 的 SFT 数据集。对于某些非推理任务,在回答问题前通过提示生成潜在的思维链。然而对于更简单的查询(如“你好”),则不提供 CoT。最终,共收集约 20 万条与推理无关的训练样本。
使用上述约 80 万条样本对 DeepSeek-V3-Base 进行两轮微调。
面向全场景的强化学习
为了进一步使模型符合人类偏好,实施了一个次级强化学习阶段,旨在提升模型的有用性和无害性,同时进一步优化其推理能力。具体而言,通过结合奖励信号与多样化的提示分布来训练模型。对于推理数据,遵循 DeepSeek-R1-Zero 中的方法论,利用基于规则的奖励信号,引导模型在数学、代码和逻辑推理领域的学习过程。对于通用数据,采用奖励模型,捕捉复杂场景中人类的偏好。在此基础上,扩展了 DeepSeek-V3 流水线,沿用类似的偏好对(preference pairs)分布和训练提示分布。对于有用性,专注于生成内容的最终总结部分,确保评估侧重于回答的实用性和相关性,同时尽量减少对底层推理过程的干扰。对于无害性,对模型生成的整个响应(包括推理过程和总结)进行全面审查,识别并缓解可能存在的风险、偏见或潜在有害内容。最终,通过奖励信号与多样化数据分布的结合,成功训练出了一种在推理能力上表现卓越,同时优先保证有用性和无害性的模型。
蒸馏:赋予小型模型推理能力
为了使更高效的小型模型具备与 DeepSeek-R1 类似的推理能力,直接使用 DeepSeek-R1 精选的 80 万条样本微调开源模型,如 Qwen 和 Llama。研究结果表明,这种简单的蒸馏方法显著增强了小型模型的推理能力。
对于蒸馏后的模型,仅进行了监督微调(SFT),并未包含强化学习(RL)阶段,尽管引入 RL 可能会显著提升模型性能,因为此研究的主要目标是展示蒸馏技术的有效性。
以 Qwen2.5-32B 作为基础模型,直接从 DeepSeek-R1 进行的蒸馏超越了对其应用 RL 的效果。这表明,较大基础模型发现的推理模式对提升推理能力至关重要。

相关文章
