引言
在生成式 AI 浪潮的推动下,推荐系统领域正经历深刻变革。传统的深度学习推荐模型 (DLRMs) 虽已展现出一定效果,但在捕捉用户兴趣偏好和动态行为序列变化时,常面临可扩展性挑战。生成式推荐系统 (Generative Recommenders, GRs) 的出现,为这一领域带来了全新思路与机遇。
本文将介绍 NVIDIA recsys-examples 中针对生成式推荐场景设计的高效实践参考。博客内容共分为上下两篇,本篇将整体介绍 recsys-examples 的设计和功能,下篇将对核心模块进行深入的解析。
GitHub repo: https://github.com/NVIDIA/recsys-examples
生成式推荐系统的崛起
Meta Research 的最新研究表明,生成式推荐系统通过将推荐问题重构为生成式建模框架下的序列 transduction 任务,展现出显著优势:
-
更个性化的推荐:能够深入挖掘用户独特的行为模式与偏好。
-
更强的上下文感知能力:能够更好地捕捉上下文序列信号,满足序列建模的模型需求
以 Meta 提出的 HSTU (Hierarchical Sequential Transduction Units) 为例,其在推荐场景中性能超越传统 Transformer 模型,且推理速度更快。
大规模训练的挑战与应对方案
然而,基于类 Transformer 架构的生成式推荐系统,因上下文长度增加和计算需求提升,在大规模训练与部署时面临严峻的计算和架构挑战。为解决这些难题,NVIDIA 开发了 recsys-examples 参考实现,旨在展示大规模生成式推荐系统中训练和推理的最优实践。
NVIDIA recsys-examples 中的
深度优化
NVIDIA recsys-examples 目前主要包含以下特性:
-
混合并行分布式训练:基于 TorchRec(处理 sparse 部分的模型并行)和 NVIDIA Megatron Core(适用于 dense 部分的数据并行与模型并行),优化多 GPU 分布式训练流程,实现 sparse 和 dense 部分多种并行的高效协同。
-
高效 HSTU 注意力算子:通过 NVIDIA CUTLASS 实现高性能的 HSTU 注意力算子,提升计算效率。
-
动态 embedding 功能:结合 NVIDIA Merlin HKV 和 TorchRec,支持无冲突哈希、embedding eviction 及 CPU offloading 等动态 embedding 能力,适配大规模训练场景。
当前,recsys-examples 中提供了基于 HSTU 排序和召回模型的大规模训练示例,方便用户快速使用和参考。
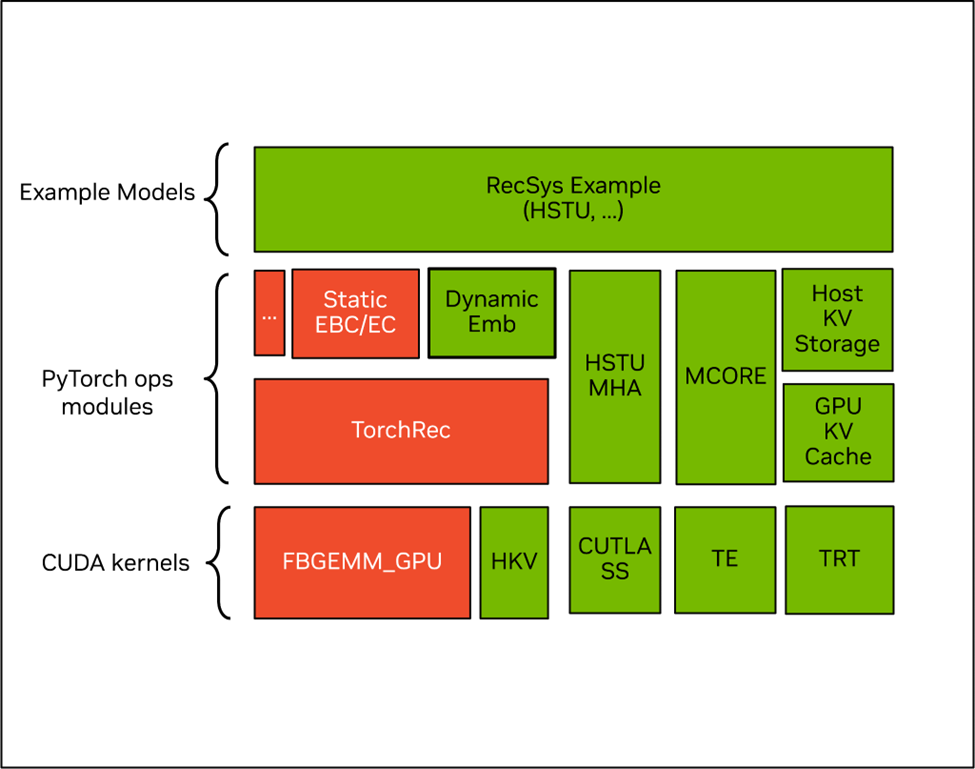
图 1:NVIDIA recsys-examples 的软件架构,其中绿色部分是 NVIDIA 开源组件,红色部分是社区开源组件
一、高效的 HSTU 内核
HSTU (Hierarchical Sequential Transduction Unit) 注意力结构是论文中提出的一种针对推荐系统优化的高效注意力机制。与标准的多头注意力 (Multi-head Attention) 相比,HSTU 注意力做了以下关键改进:
-
Normalization 改进:用 SiLU 替代 softmax,提升模型表达能力。
-
引入相对位置偏置:通过 Relative Attention Bias (RAB) 捕获序列中的相对位置/时间信息。
在 recsys-examples 中,我们基于 NVIDIA CUTLASS 库实现了高性能的 HSTU 注意力算子,并针对训练和推理场景分别进行了优化。目前实现也已经合并到 FBGEMM 中,用户可以直接通过 FBGEMM 使用。
1、训练优化技术
-
Kernel Fusion 计算融合:借鉴 Flash Attention 的思想,将多个连续操作融合为单个 GPU 内核
-
灵活掩码和 RAB 机制:支持可定制的 mask tensor 以及 RAB tensor,适应不同推荐场景下的序列建模需求
2、推理优化技术
-
简化计算逻辑:使用 RAB (Relative Attention Bias) 作为负无穷替代传统的 mask 操作,减少计算复杂度和内存访问,提升推理速度
-
稀疏目标优化:针对推荐系统中常见的稀疏 target 计算模式进行优化,减少内存占用,并支持大规模目标的批量推理
在 NVIDIA Hopper 架构上,我们的 HSTU 注意力算子相比与 Triton 实现的版本,在各个问题尺寸上都有超过 3.5x 的加速比,并且在序列增长的情况下,加速比进一步提升。

图 2:CUTLASS Kernel 在 NVIDIA Hopper 架构上与 Triton 的前向性能对比
图 3:CUTLASS Kernel 在 NVIDIA Hopper 架构上与 Triton 的后向性能对比
二、动态 embedding 与
TorchRec 的无缝集成
TorchRec 目前对动态 embedding 的支持有两种,分别是 contrib / dynamic_embedding 通过外挂 CPU redis 集群和在 ManagedCollision 模块中通过额外的排序步骤来支持,两者都会在原有 TorchRec 训练流程的基础上,增加额外的训练时间开销。
在 recsys-examples 中,我们引入 NVIDIA Merlin HierarchicalKV 作为底层存储,并与 TorchRec 团队合作基于 TorchRec 官方插件接口,直接替换 TorchRec 中原本的 FBGEMM 静态存储,支持了动态 embedding 支持能力。这一方案可在大规模推荐系统训练场景中:
-
支持无冲突哈希映射
-
支持基于频率或时间或自定义的 embedding 淘汰策略
-
提供 CPU offloading 机制来实现超大规模 embedding 存储
-
支持 incremental dump 功能,根据用户的需求只 dump 在过去一段时间内训练过的 embedding
-
保持与原生 TorchRec 分布式训练流程的无缝集成
相比 contrib / dynamic_embedding 中的实现,NVIDIA recsys-examples 能够大幅度减少 CPU 上的操作开销,在大规模训练中能有超过 20 倍的加速效果。
更多详细内容您可观看 "RecSys Examples 中的训练与推理优化实践——以 HSTU 模型为例":
视频地址:
https://www.bilibili.com/video/BV1msMwzpE5B/
美团应用
NVIDIA recsys-examples 实践
在过去几个月中,我们与美团紧密合作,助力其加速基于 HSTU 架构的推荐模型在离线和在线试验中的应用。在美团外卖场景下,通过引入 GR 模型结构,CTR 和 CTCVR 指标均实现了显著提升(详情参考 MTGR 博客)。
图 4:美团业务引入 GR 后的收益。
该图片来源于 MTGR:美团外卖生成式推荐 Scaling Law 落地实践一文,若您有任何疑问或需要使用该图片,请联系美团
我们的优化版 HSTU 算子,在训练中,端对端吞吐提升 85%;在推理中,通过 TRT plugin 封装,在 TRT 中引入了 HSTU fp16 算子,相比 TRT fp32 算子时延降低 50%,端对端耗时减少 30%。
总结与展望
NVIDIA recsys-examples 将生成式推荐(如 “Actions Speak Louder than Words” 论文中提出的技术)与分布式训练(借由 TorchRec 增强)及优化训练推理相结合,助力开发和部署能够提供高度个性化用户体验的复杂推荐模型。我们诚挚邀请研究人员和从业者试用该工具,并期待与您共同推动生成式推荐系统的技术演进。
相关资源
TorchRec 官方文档:
https://docs.pytorch.org/torchrec/
Meta HSTU 论文:
https://arxiv.org/abs/2402.17152
MTGR 博客:MTGR: 美团外卖生成式推荐 Scaling Law 落地实践:
https://mp.weixin.qq.com/s/JiDOqD-ThU0Upp6xnNg3Nw
Add HSTU in fbgemm_gpu/experimental/:
https://github.com/pytorch/FBGEMM/pull/4090
enable customized emb lookup kernel for TorchRec:
https://github.com/pytorch/torchrec/pull/2887
作者
刘仕杰
2020 年加入 NVIDIA DevTech 团队,专注于 NVIDIA GPU 的性能优化及推荐系统加速领域。
张俊杰
来自 NVIDIA DevTech 团队,从事企业用户 GPU 加速计算支持工作,目前主要负责推荐系统训练端到端优化工作。
姚家树
来自 NVIDIA DevTech 团队,从事企业用户 GPU 加速计算支持工作,目前主要负责推荐系统 Embedding 存储的开发和性能优化工作。
康晖
2022 年加入 NVIDIA DevTech 工程师团队,目前从事机器人仿真加速相关工作,之前参加过 HugeCTR,SOK,recsys example 等项目开发和优化。
柴斌
来自 NVIDIA DevTech 团队,从事企业用户 GPU 加速计算支持工作。目前主要负责搜广推链路的性能调优和 kernel 开发。
陈乔瑞
来自 NVIDIA DevTech 团队,从事企业用户 GPU 加速计算支持工作,目前主要负责 HPC 程序的开发和 kernel 性能优化。
孙佳钰
来自 NVIDIA DevTech 团队,从事企业用户 GPU 加速计算支持工作。
张琪
来自 NVIDIA DevTech 团队,从事企业用户 GPU 加速计算支持工作,目前主要负责 CUTLASS 在推荐系统、LLM 等相关应用场景的性能优化与开发工作。
点击“阅读原文”或扫描下方海报二维码,观看 NVIDIA CEO 黄仁勋 GTC 巴黎主题演讲回放!
转载请注明:NVIDIA recsys-examples: 生成式推荐系统大规模训练推理的高效实践(上篇) | AI工具大全&导航
相关文章
