今年是 DeepSeek-R1 系列模型深入千行百业,助力企业全面拥抱AI变革的关键一年!
在企业级场景下,采用模型集群方案至关重要,大模型推理是计算密集型任务,所以每个用户任务采用单线程处理,这就使推理性能和并发能力受到了限制。
并行模型与多线程
尽管每个单独的推理请求通常是单线程的,但 多模型并行处理 是一种常见的做法:
为了高效地为多个用户提供服务,通常会引入 负载均衡,将用户请求分发到多个模型实例或多台服务器上:
- 水平扩展:多个模型实例并行工作,每个实例处理一个请求。
- GPU 优化:多个并发请求可以在不同的 GPU 上同时运行。
多GPU、多实例部署方案
1、一个Docker对应一个Ollama服务,一个Ollama服务对应一个DeepSeek-R1-32B量化模型。
2、一个Docker对应GPU
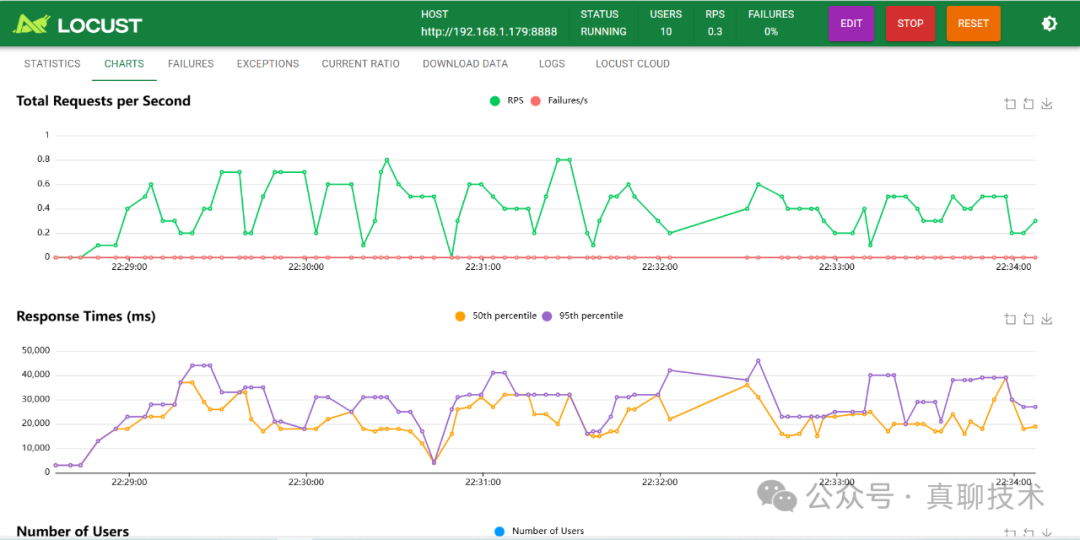
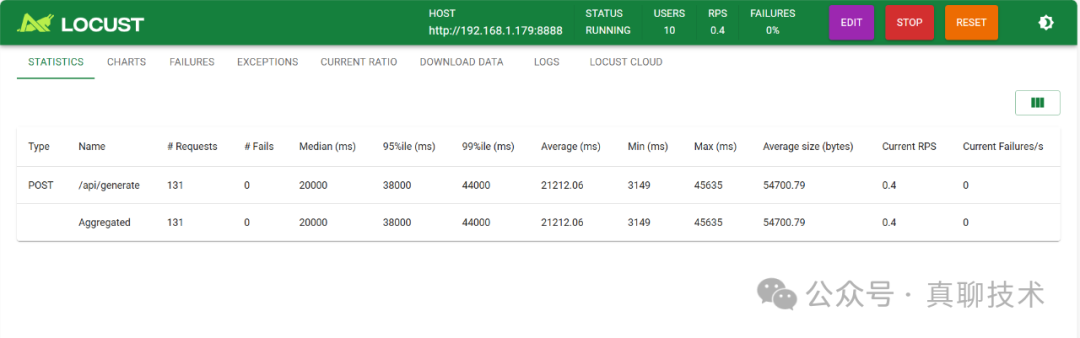
如果是2块GPU,理论上并发就是2个。
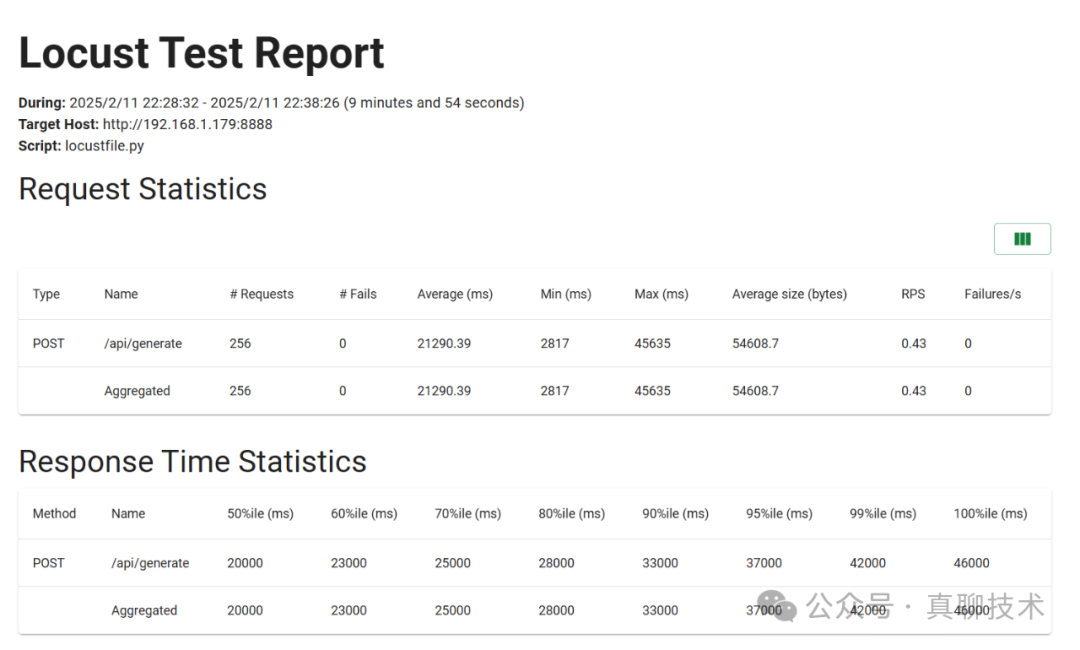
压测工具与压测方法
pip install locust
/api/generate,该接口接收一个 JSON 请求并返回生成的内容。以下是一个简单的 Locust 脚本示例:from locust import HttpUser,task, betweenimport jsonclass LLMUser(HttpUser): wait_time = between(1, 2) # 每个用户请求的间隔时间 @task def generate_text(self): headers = {"Content-Type":"application/json"} data = { "model": "deepseek-r1:32b", "prompt": "简单介绍一下北京", "stream": True } self.client.post("/api/generate", headers=headers, json=data, timeout=60)
locust -f locustfile.py --host http://192.168.1.10:8888
[2025-02-11 10:35:28,056] user/INFO/locust.main: Starting Locust 2.x.x[2025-02-11 10:35:28,057] user/INFO/locust.main: Starting web interface at http://127.0.0.1:8089

版权声明:charles 发表于 2025年2月13日 am10:18。
转载请注明:压测篇 | Ollama+Nginx+4090打造DeepSeek-R1-32B高可用大模型集群,助力企业拥抱AI时代 | AI工具大全&导航
转载请注明:压测篇 | Ollama+Nginx+4090打造DeepSeek-R1-32B高可用大模型集群,助力企业拥抱AI时代 | AI工具大全&导航
相关文章
最实用、最热门的AI 工具大全AI 工具导航,帮助你在工作与学习上更轻松有效率。在网路上众多 AI 与 ChatGPT 工具中,我们亲自试用并挑选了最有有用的,分成 20多个大类别,让你轻松找到所需的 AI 工具。
