
点击关注“有赞coder”
获取更多技术干货哦~

部门:数据中台
一、背景
-
各服务间指标口径不一致 -
数据服务复用率低 -
数据服务开发效率低,维护成本高 -
数据链路不清晰,问题排查链路长
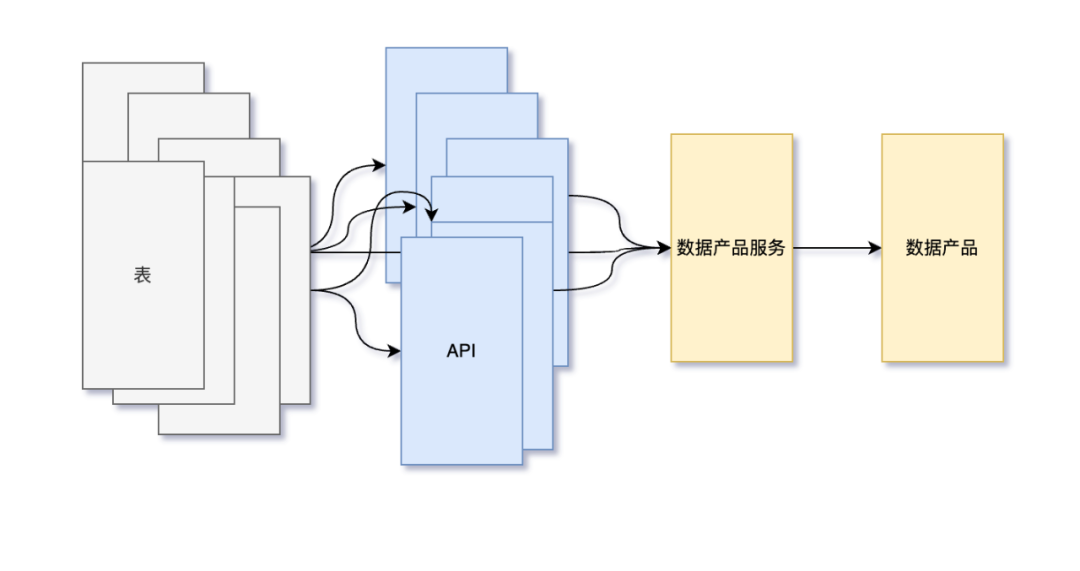
充满各种血缘关系的烟囱式数据服务
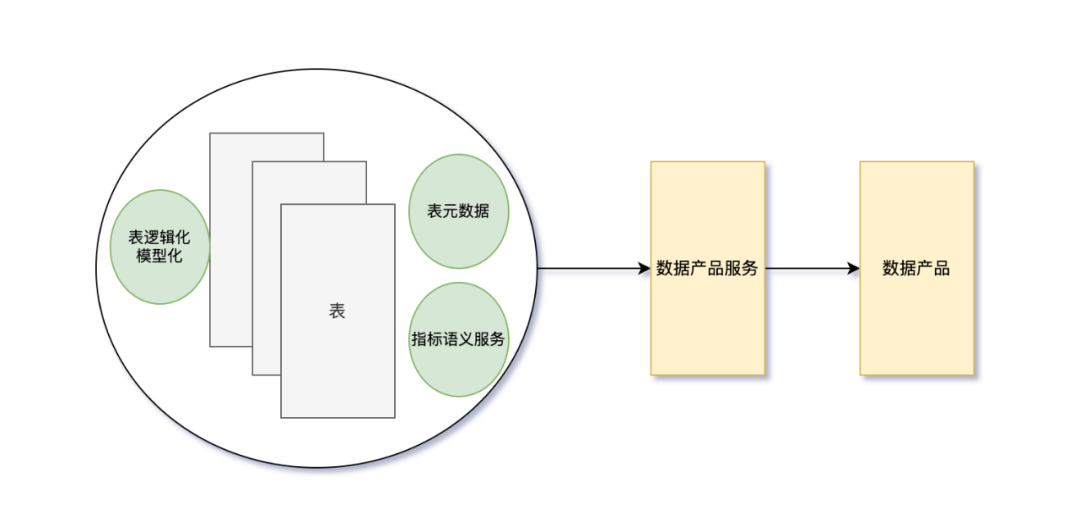
对此我们设计了一套新的数据服务,设计的目标为
-
各数据服务指标一致性
-
指标的可复用:指标定义一次即可多次复用
-
数据模型可复用:相同粒度的数据指标不再重复定义与建设
-
数据服务开发的效率提升与可扩展性
-
可为AI提供元数据与灵活数据查询的指标型数据服务

统一的指标查询服务斩断万千表、API关联关系的麻绳
本文会从历史的数据服务架构、新的数据服务如何演进且如何在业务上产生效果这三方面进行分享。
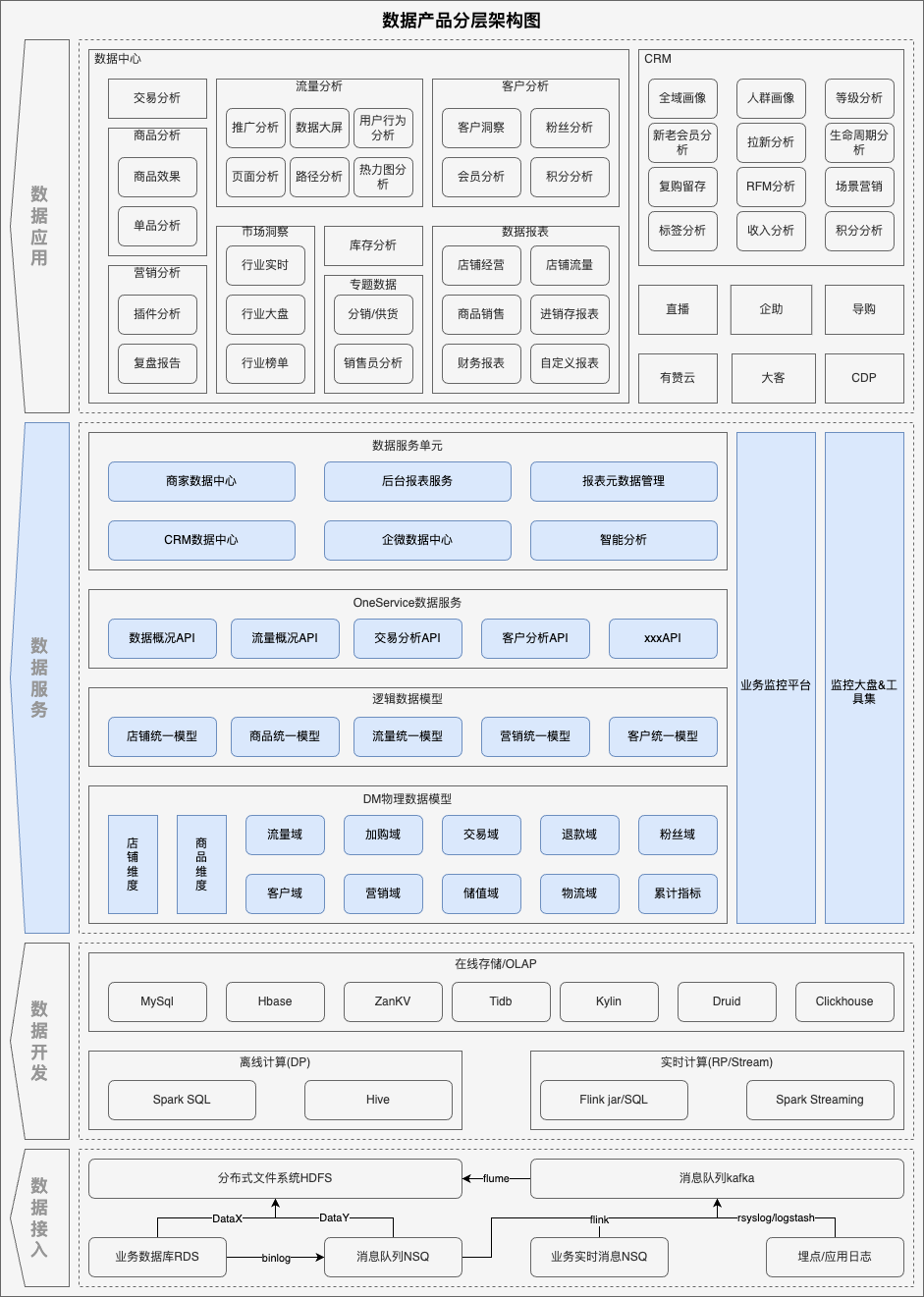
二、当前数据服务架构
-
OneService数据服务:以mybatis模板为核心的表级别数据服务,下文简称为OS数据服务 -
数据服务单元:为具体某个数据产品提供服务,根据业务流程串联多个OS数据服务的产品级数据服务
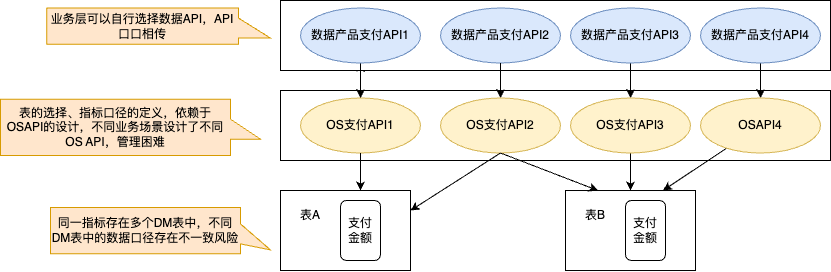
2.1 表级别数据服务的缺点
2.1.1 Mybatis模板服务示例
指标口径与数据源选择绑定在模板代码中的OS数据服务
selectsum(xxx) AS PV,count(DISTINCT xxx) AS UV,count(distinct xxx) AS NEW_UV,sum(xxx) AS STAY_TIME_AVG,sum(xxx) * 1.0 / count(DISTINCT xxx) AS PER_CAPITA_BROWSING,count(DISTINCT xxx) AS SHARE_TOTAL_UV,count(DISTINCT xxx) AS ADD_CART_UV,count(DISTINCT xxx) AS ORDER_UV,sum(xxx) as ORDER_AMOUNT,sum(xxx) as PAY_AMOUNT,count(distinct xxx) as PAY_CNT,count(distinct xxx) as ORDER_CNTfromdm.xxxxwherepartition >= #{startDay}andpartition <= #{endDay}andteam_id = ${teamId}<if test="firstChannel != null ">and first_channel=#{firstChannel}</if><if test = "secondChannel">and second_channel=#{secondChannel}</if><if test = "thirdChannel">and third_channel=#{thirdChannel}</if><if test = "fourthChannel">and fourth_channel=#{fourthChannel}</if>
2.1.2 以OS为核心的数据服务开发流程
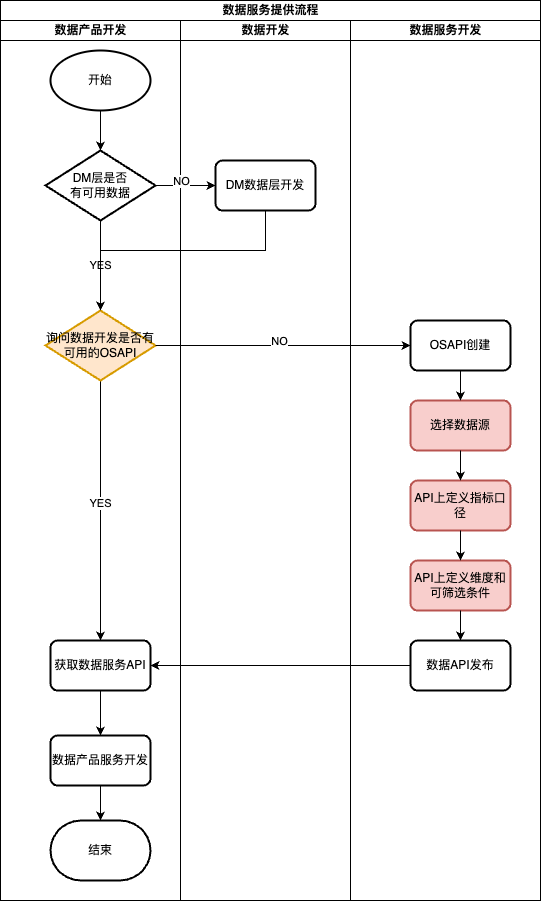
上述流程对于开发同学会有以下的疑问和痛点

2.1.3 表级别服务缺点
-
没有指标级别数据血缘,无法快速定位某个指标取自哪张表,口径是什么 -
模型变更上层服务也要相应进行变更,对于一张一对多的数据表,模型的变更将会连带多个数据服务都进行变更
三、业务视角下的数据服务需求
-
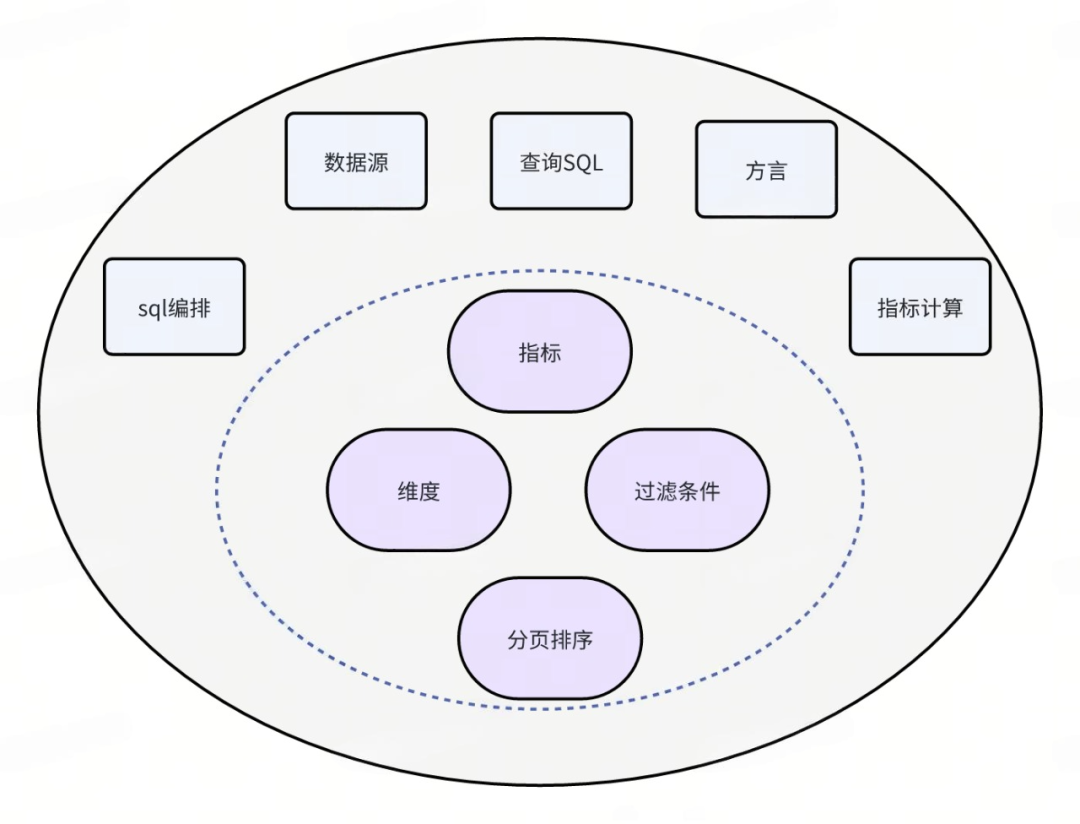
我们要观察的事物:指标,用于衡量事物发展程度帮助业务做出决策 -
我们观察事物的角度:维度 -
我们观察事物的限定条件:过滤条件
四、指标服务设计
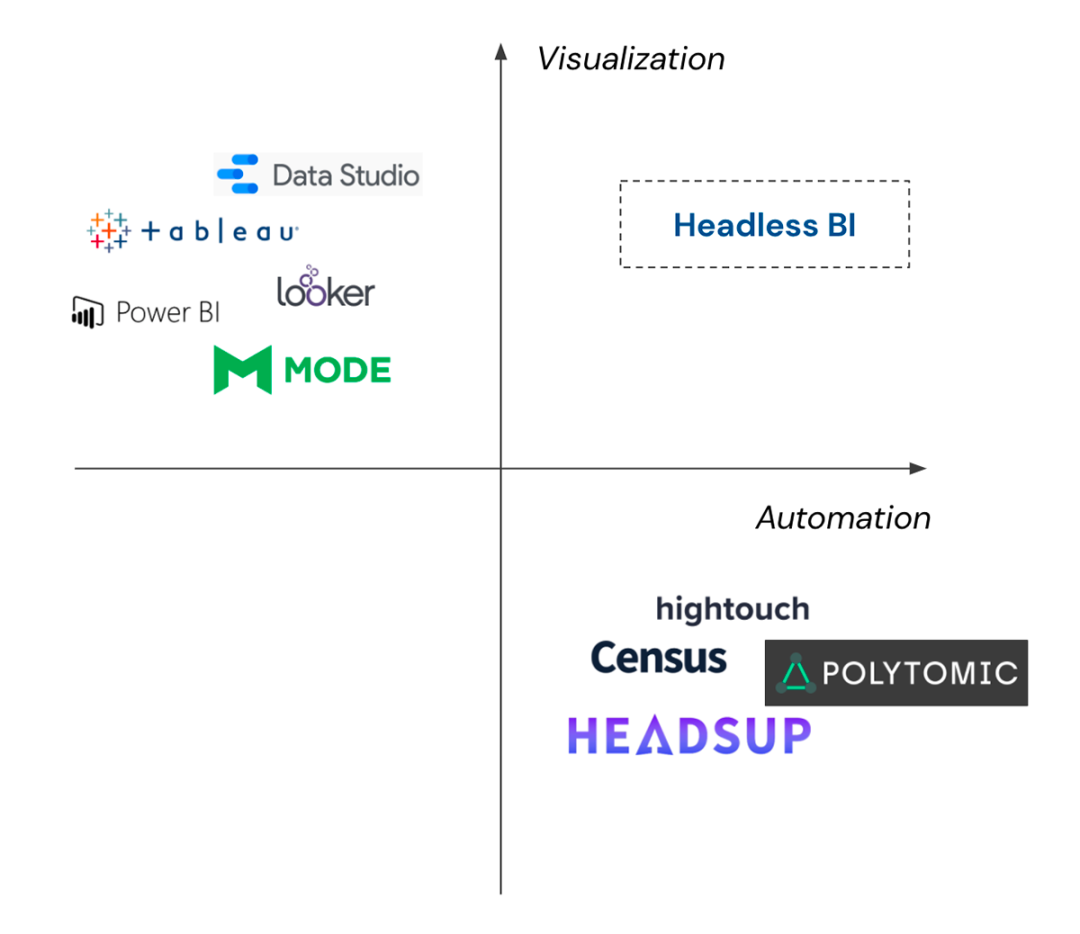
4.1 Headless BI
4.1.1 BI的语义层
常见的BI工具通常包含一层语义层,它将物理数据模型转化为逻辑模型,定义模型的维度和度量,并在此基础上创建指标。

逻辑模型构建
模型定义
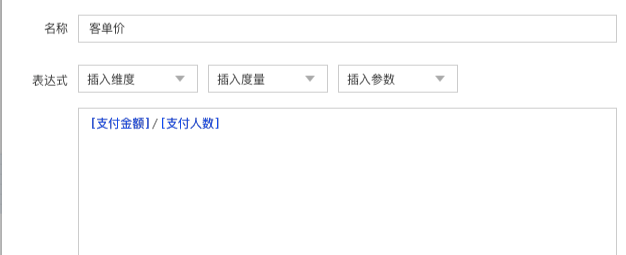
指标上下文感知
4.1.2 Headless BI
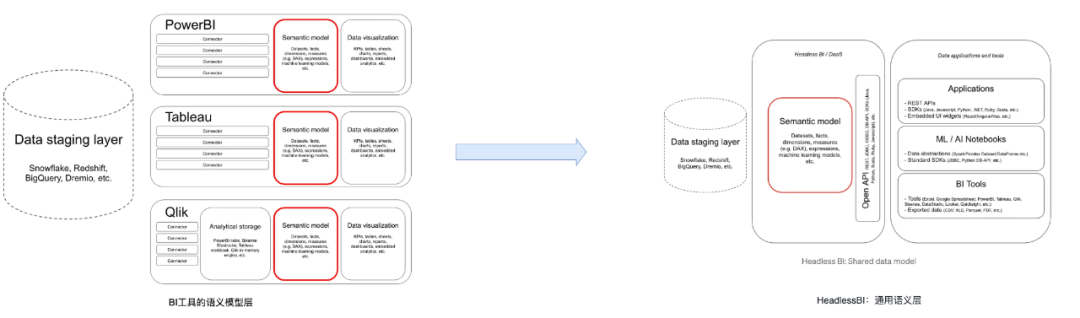
4.2 基于Headless BI的数据模型虚拟化的指标服务
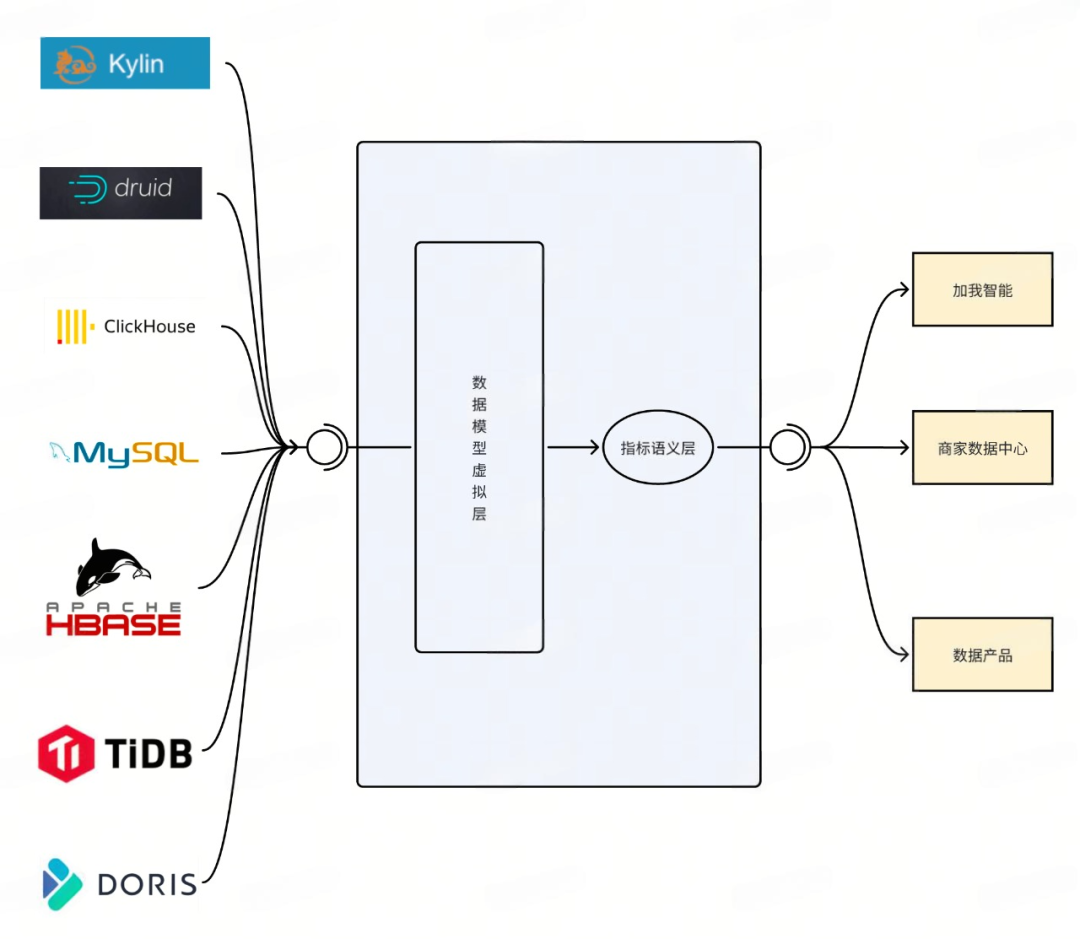
4.2.1 元数据管理
-
公共度量、维度管理
-
模型管理与定义
模型管理主要负责对物理模型进行建模和管理,包含以下几个方面:
-
模型数据源:维护和管理数据模型的数据源。
-
模型数据时效性:配置模型是否包含实时数据、是否包含离线数据等。
-
模型字段管理:将模型字段与公共度量和维度进行映射。
-
模型优先级配置:支持手动设置模型的优先级。
-
指标定义
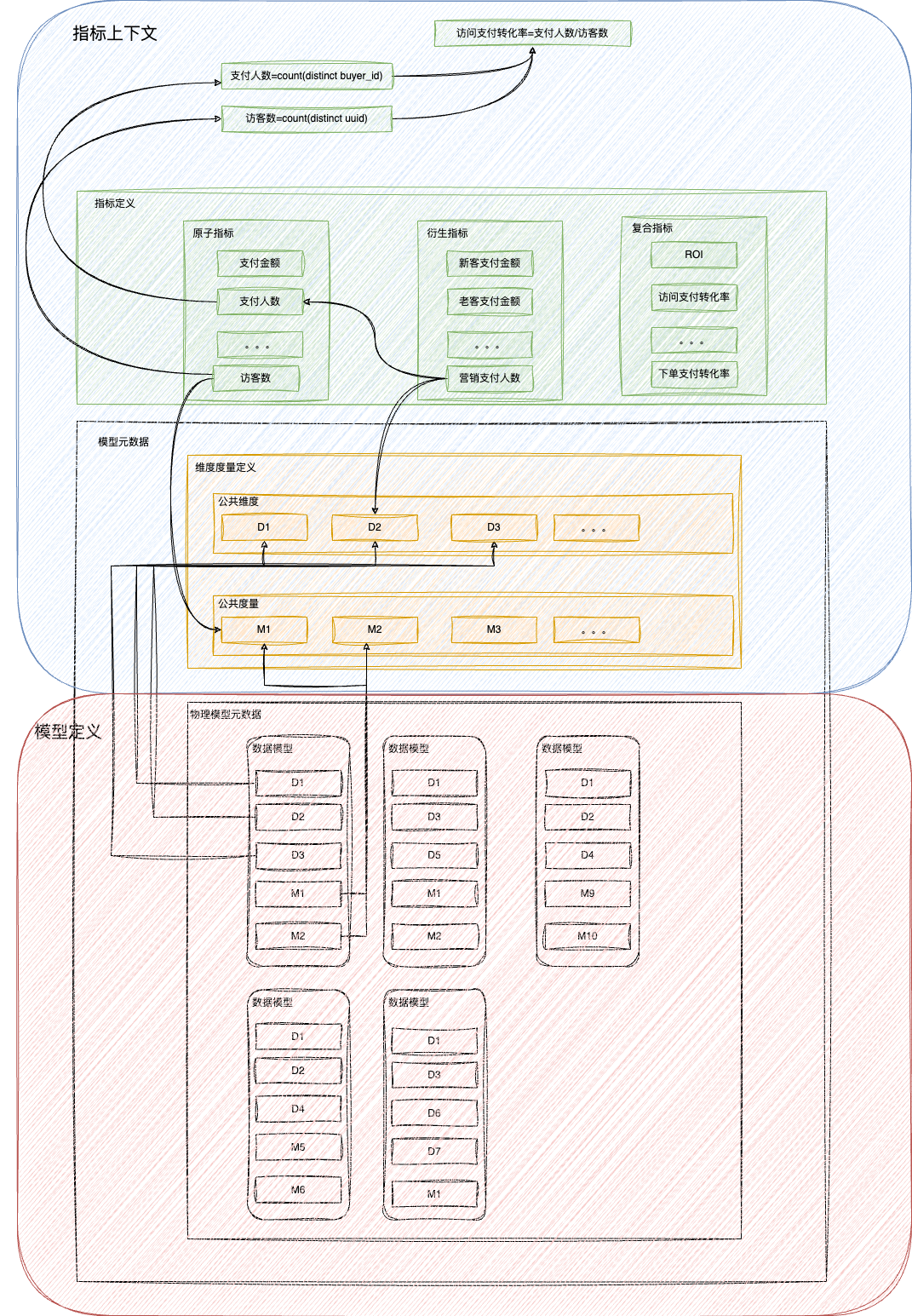
指标上下文
-
原子指标 指标口径由公共度量和算子组成。为了消除同义不同名的问题,原子指标的公共度量+算子具有唯一性。 -
派生指标
派生指标引用原子指标+公共维度过滤条件作为指标口径的定义。派生指标引用的原子指标+过滤条件具有唯一性。
-
复合指标 复合指标引用原子/派生指标进行四则运算。复合指标的计算表达式具有唯一性。
除了指标定义外,我们还将指标相关知识录入到系统中,比如指标公式的拆解、指标所属业务节点等,为后续指标波动自动化识别提供基础业务知识。
4.2.2 数据模型虚拟化与数据查询实现
上文介绍了元数据管理模块,这一小节会介绍如何对有赞数据模型进行虚拟化以及查询流程的实现。
1、设计思路
在介绍数据模型虚拟化之前我们先简单回顾下数据集市层数据模型的建设,数仓为了有效管理数据,对数据按主题域进行组织,划分到各个表中。
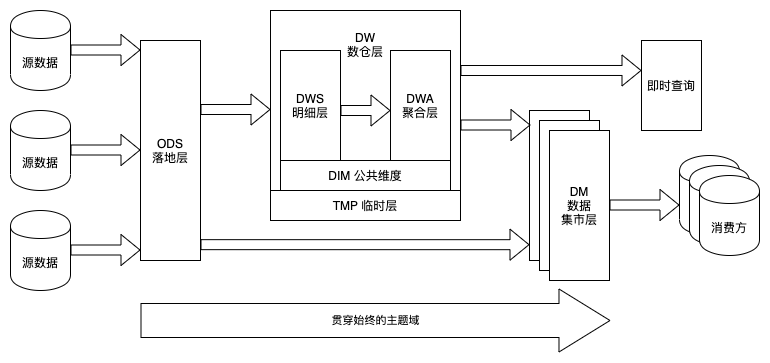
有赞数仓架构
传统的数据集市设计是基于业务分析场景进行数据加工,对跨域的指标进行整合生成集市层的宽表,再选择合适的OLAP组件进行加速,最终基于OLAP上进行数据服务的提供。然而,这种设计存在一些缺点:
-
指标重复建设:指标被不断地复制,复制过程中可能存在特殊逻辑的加工导致各个数据集市的指标不统一,数据集市中很多字段会被重复建设。
-
数据模型管理复杂:由于不断复制,导致数据集市层的数据模型无序增长,管理复杂。
-
指标下钻分析复杂:同一指标的不同粒度、不同维度可能会散落在不同的表,下钻需要自行维护指标和表的血缘关系。
-
缺乏跨数据源查询能力:无法进行跨数据源的查询。
-
宽表自身问题:木桶问题、扩展性差。
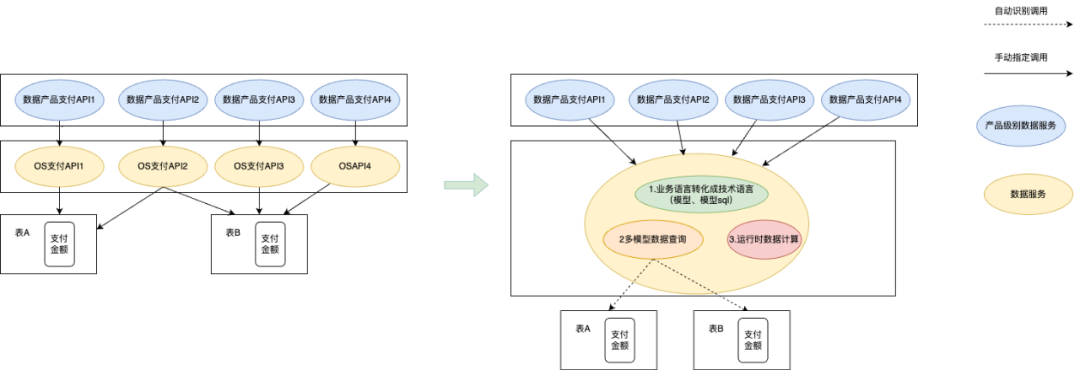
为了提升指标定义的作用范围,降低指标下钻分析的复杂度,消除数据集市中重复建设问题,我们在逻辑表的基础之上构建了虚拟数据模型层。虚拟数据模型层以公共维度和公共度量作为表元数据对外提供服务,屏蔽底层物理数据模型,根据公共维度和公共度量与物理模型之间的映射关系,构建出虚拟的包含全域数据的超大宽表。
在查询时,虚拟的超大宽表会根据查询条件自动选择出匹配查询的数据模型列表,然后根据元数据关系构建出逻辑表,通过逻辑表进行数据查询。这种通过模型血缘关系实现数据模型自动选择的方式,有效提升了数据模型的复用,保证了数据指标查询时查询执行的唯一性,从而保证指标口径的一致性。同时,由于底层复用逻辑表的能力,实现物理数据源的语法适配和统一逻辑层跨数据源数据查询以及查询优化等能力,在宽表的易用性、高性能和扩展性之间取得了平衡。
基于数据虚拟化的查询流程
2、数据模型设计录入与选择逻辑
2.2 查询时数据模型选择逻辑
通过解析查询的DSL参数和指标元数据,我们可以确定当前查询所需的维度和度量组合。解析完成后,对物理数据模型进行筛选,将符合条件的物理模型按照度量分组。接下来,根据物理表的元数据信息计算查询代价,并结合部分人工配置的规则条件,对模型列表进行排序,最终在每个分组中选出最优的数据模型,将这些模型映射到逻辑表中。
3、可执行的逻辑表生成
对于刚才筛选出来的最优数据模型组合我们将其元数据根据逻辑表规范映射出一张逻辑表,并将逻辑SQL提交给逻辑表执行。逻辑表可以认为是一种根据元数据的关联关系自动生成的数据库视图,但不仅仅是视图,包含以下核心能力
-
跨引擎的查询能力
-
多数据源方言适配、并发物理查询
-
查询优化,按需构建查询视图,物理查询下推, order by查询优化等能力
-
同维指标合并,逻辑宽表结果返回,屏蔽跨域模型设计带来的查询复杂性
4、查询编排
-
累计指标在进行范围时间查询时仅需要查询结束时间 -
同环比数据查询并合并按指标进行合并、趋势数据查询 -
分页数据询时对分页结果进行趋势数据查询
4.2.3 指标服务接口
基于上述分析的业务要素,我们设计了一套DSL定义,用于构建统一的指标服务接口。业务方根据约定传入指标、过滤条件等,同时会将同环比、趋势等常见分析进行连带查询和数据结果合并。
商品指标查询入参
指标结果返回
4.2.4 新的服务整体架构
五、新的指标服务在有赞的应用
5.1 数据报表
5.1.1 报表应用
基于新的指标服务平台,我们可以快速创建数据报表。通过使用预定义的指标和维度,简单数据报表的构建速度提升了数倍。原先需要两三人日才能完成的数据报表服务,现在缩减到小时级别即可构建完成。
数据报表
5.1.2 自助取数
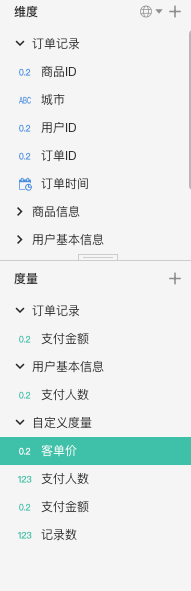
我们基于指标服务构建了一套自助取数产品,对外屏蔽了底层物理模型。商家可以自行配置所需的指标和维度进行数据导出,极大地提升了数据获取的自主性和灵活性。
维度选择
指标选择
样例数据展示
5.1.3 收益
-
指标可复用性强,指标口径强收敛,各报表间指标口径统一
-
指标维度扩展性强,元数据驱动,增加维度时不再需要调整数据服务API
-
开发提效,简单数据报表服务构建速度提升数倍
数据开发流程提效
5.2 大模型的Tools,帮助大模型取数
5.2.1 大模型接入
为了提升商家获取数据的能力,我们提供了对话式的数据指标查询服务。一种经典的实现方案是通过LLM(大型语言模型)解析自然语言查询(NLQ),将其转换为SQL(NL2SQL),然后交由底层数据库执行。
然而,这种方案存在以下问题:
-
指标口径不准确:在处理复杂指标查询时,LLM可能无法准确理解指标口径,从而导致错误的指标结果。
-
LLM幻觉:LLM有时会基于自身的知识生成错误的SQL查询,在某些场景下会出现幻觉。
-
不具备复杂指标计算的能力:对于跨域等指标难以拆分查询逻辑并对查询结果二次计算能力差,计算不准确。
为了解决上述问题,我们采用新的技术方案:让LLM对接指标服务语义层,以指标、维度这些大模型擅长解析的语义内容作为DSL的参数,模型的选择、指标口径、查询SQL生成等收敛在指标服务中,避免LLM产生幻觉并且便捷地获取口径准确的数据指标,降低LLM的取数难度。
DSL查询示例:
5.2.2 应用案例
-
自由看数
-
诊断分析
5.3 数据洞察
六、展望和总结
相关文章
