

和大家分享一个好消息,最近, Zilliz Cloud 建表功能迎来了一次重要更新。本次更新在用户界面上完整对齐了 SDK 能力,并带来了全新的交互体验,希望大家在构建数据模型时,少些繁琐,多些高效。
这次更新主要包括七个方面,接下来我们来一一介绍。
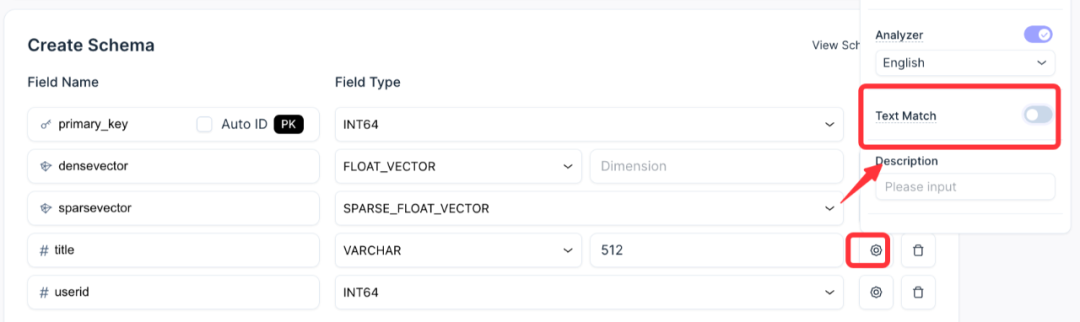
全面支持全文检索与文本匹配能力
在新版本中,全文检索会通过术语相关性对文档进行排序,显著提升 RAG 和关键词场景的准确性。它直接处理原始文本并自动生成稀疏向量,无需手动 Embedding。而文本匹配非常适合精确的词项过滤和查询。过去,用户只能在 SDK 使用全文检索功能,用户需要理解 input text field + function + output sparse field 的组合关系,步骤容易遗漏导致创建失败。在新版界面中,我们对这两项功能做了全面升级:
-
引导式全文检索配置:用户现在只需选择一个
VARCHAR列,配置 Function(支持 Standard 或 Custom Analyzer),再选择一个 Sparse Field,即可完成全文检索设置。右侧还提供对应的 SDK 示例代码,帮助用户快速理解并顺畅切换到代码模式。 -
直观的文本匹配功能:用户可以在界面中为指定字段直接启用文本匹配,满足精确匹配词语或短语的需求,提升配置效率与可用性。
简化数据组织:Partition和Partition Key概念澄清
理解 Zilliz Cloud 中 Partition 和 Partition Key 的区别,对于优化性能至关重要。Partition 是一个 Collection 的物理子集,共享相同的 Schema 但仅包含部分数据,有助于隔离数据并提升查询性能。使用 Parition Key 则能在超多租户场景中,基于某个标量字段隔离租户以优化查询性能。过去,用户只能在 SDK 中创建和管理 Parition,非常不便。同时,两者名称相似且互斥,用户容易混淆,并且配置错误后的修改成本很高(需要重新插入数据)。本次优化,我们提供了:
更清晰的解释: 在建表时,我们现在清晰地解释了 Partition key 和 Partition 的区别,引导用户根据实际场景选择合适的租户粒度和 Partition key 字段。
独立的分区管理页面: 新增了一个独立页面,支持创建、预览 Partition,并能将数据直接导入到指定 Partition。
此外,当使用 Parition Key 时,Parition 由系统自动创建,界面会禁用Parition 创建入口,避免用户误操作。

Mmap (内存映射)是一项强大的技术,能有效减少内存占用,让每个 CU 处理更多数据,尤其适用于处理大数据量或不常访问的字段。以前,Mmap 只能在建表时开启,后期修改只能通过 SDK 操作,SDK 也没提示需要先 Release 后才生效。更棘手的是用户很难区分集群级别、表级别、列级别、原始数据和索引数据 Mmap 设置的差别。基本靠猜测,一旦出错会影响业务性能。本次优化,我们提供了:
-
更细粒度的控制: 明确定义了 字段、集合、集群 级别的 Mmap 作用优先级
-
灵活的配置: 用户现在可以在表级别和列级别轻松开关 Mmap,并能分别针对原始数据和索引数据分别配置
-
实时预览与便捷修改: 可以在 Schema 页面预览 Mmap 状态。如果需要修改,只需 release collection 即可在页面中完成
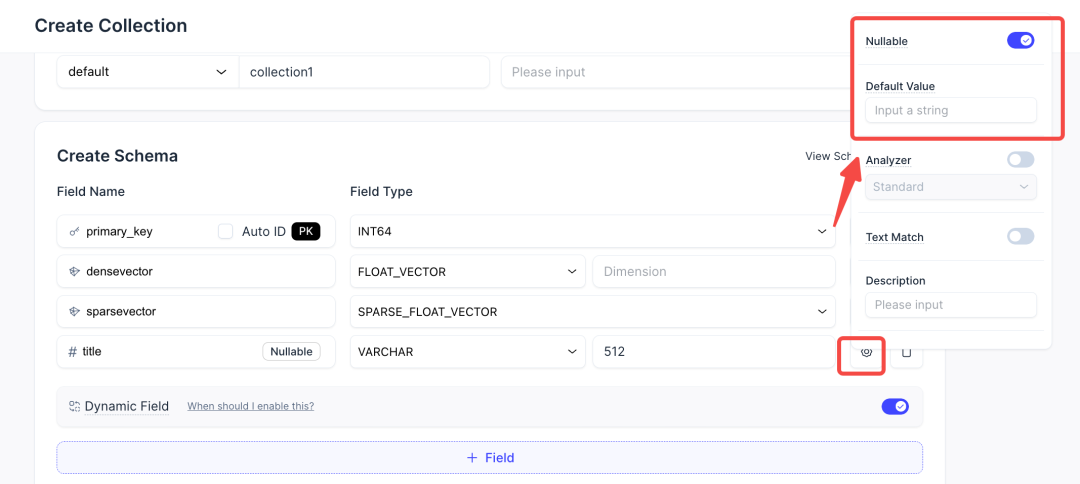
支持Nullable和default value设置,提升容错,界面更简洁
设置字段的 Nullable 属性和 Default Value 对于提高数据写入的容错性,以及处理不完整或动态结构的数据至关重要。过去,它们占据了建表界面的显眼位置,但大多数字段并不需要设置,反而干扰了高频操作。本次优化我们将这些设置收起,既满足了功能需求,又确保了高频操作的易用性,使主要的建表流程更加简洁。
完整索引生命周期管理,新增标量索引
索引是提升向量检索性能的核心组件。 过去,Zilliz Cloud 建表流程仅支持创建向量索引,而标量索引需通过 SDK 配置,使用体验不统一。同时,界面默认仅创建向量索引,缺乏对标量索引作用的说明,导致许多用户在高频使用标量字段进行筛选时未配置索引,进而严重影响查询性能。本次改版,提供了:
-
全面的索引模块: 新建表流程中包含了完整的索引模块,解释了创建索引的必要性,并引导用户按需创建
-
独立的索引管理页面: 新增了一个独立页面,支持新建、删除和预览所有索引,实现了完整的生命周期管理
-
支持 JSON Path 索引: 支持最新的 JSON Path 索引,显著提升了 JSON 和动态字段的查询速度
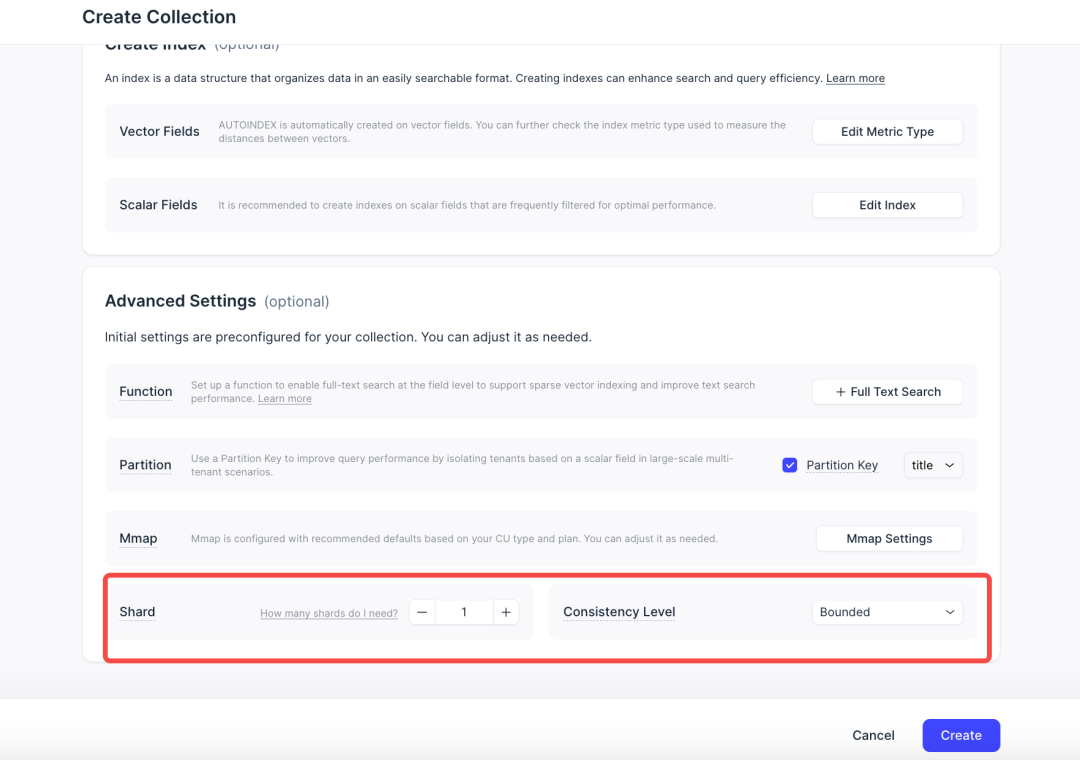
Shard与Consistency Level配置,掌控数据分布与可见性
Shard 和 Consistency level 是 Collection 两个重要能力,Shard 是Collection 的水平分区,提供独立的写入通道,能显著提升写入吞吐量。一致性级别决定了在搜索和查询操作中跨副本最新数据的可见性,默认 Bounded 级别平衡了数据新鲜度与性能。过去,这俩个选项在建表界面中是隐藏的,用户很难了解默认设置是否满足需求,一旦不符就可能面临高昂的重新建表成本。现在,我们直接在界面中展示这些默认配置,并支持您根据实际需求进行修改,同时还提供了不同配置的作用及最佳实践,帮助用户轻松做出最适合的选择。
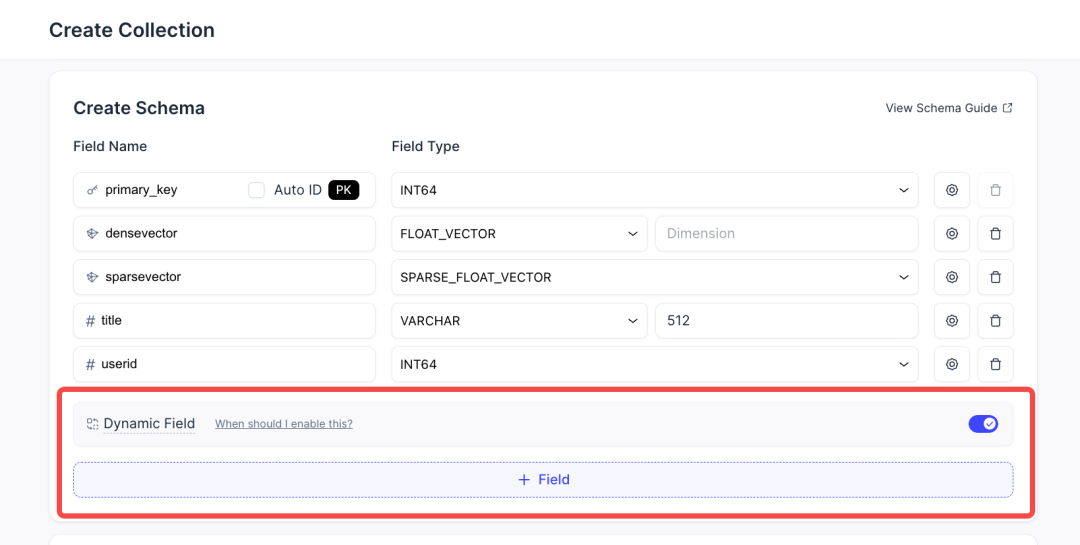
Dynamic field 展示优化,理解更直观
Dynamic filed 对于数据结构不固定、需要频繁新增列的场景非常有用,插入数据时可直接添加新字段而无需更新 Schema。过去界面仅将其视为一个开关,用户不易理解其与其他向量/标量列的关系。本次调整,在 Schema 设计中将其与标量列、向量列并列展示,并辅以描述和使用场景说明,帮助用户理解这也是一种特殊的列类型,并了解其能力差异。
除了以上各项功能升级,我们还把 Data Import 页面融合进了 Data Preview,进一步精简了产品界面。
我们深知,准确构建数据 Schema 是一项挑战,而后期任何调整都可能带来不小的成本。正因如此,我们努力通过这次更新,提供更直观的界面和更清晰的功能说明,让用户能一次性创建出最理想的数据模型,有效减少重复工作。帮助用户把重心从数据准备转移到核心的向量检索任务上,精力聚焦于应用端的创新上~
立即登录 Zilliz Cloud,亲自感受这些优化带来的便利。我们非常期待了解一线的使用反馈,并据此持续迭代产品!
作者介绍
Zilliz 高级产品经理 汤雪

相关文章
