文章背景
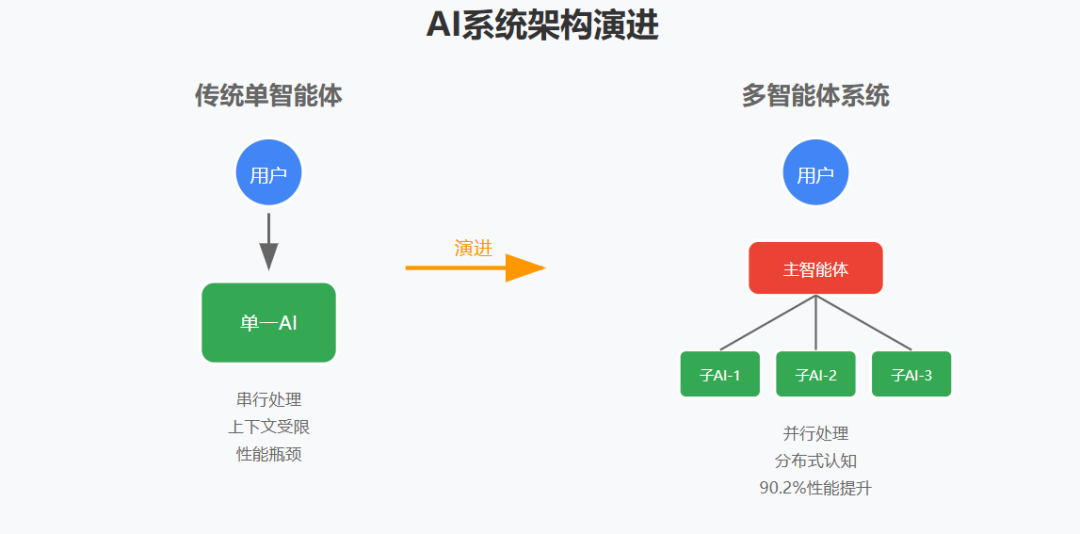
2025年6月13号,Anthropic 发布了一篇题为《How we built our multi-Agent research system》的技术博客,详细介绍了他们如何构建支撑 Claude Research 功能的多智能体系统。这篇文章之所以重要,有以下几个原因:
本文将深入解析 Anthropic 分享的核心观点,从技术和实践两个维度探讨多智能体系统的价值与挑战。
一、为什么需要多智能体系统?三个根本性突破
核心观点一:研究任务的开放性本质决定了架构选择
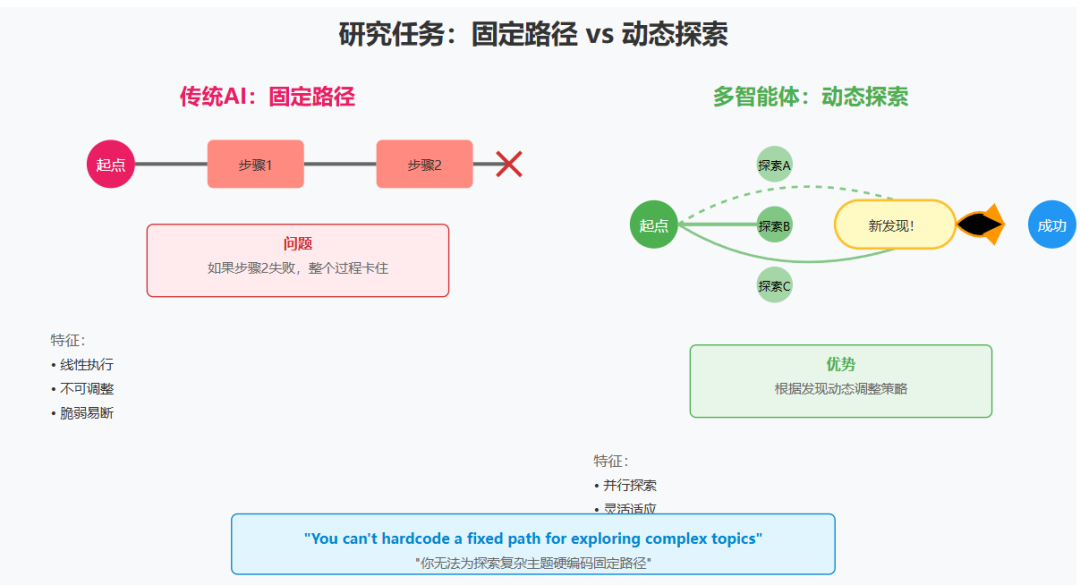
"Research work involves open-ended problems where it's very difficult to predict the required steps in advance. You can't hardcode a fixed path for exploring complex topics, as the process is inherently dynamic and path-dependent. When people conduct research, they tend to continuously update their approach based on discoveries, following leads that emerge during investigation."
"研究工作涉及开放式问题,很难提前预测所需的步骤。你无法为探索复杂主题硬编码固定路径,因为这个过程本质上是动态的且依赖路径。当人们进行研究时,他们倾向于根据发现不断更新方法,跟随调查过程中出现的线索。"
技术分析:
这段话揭示了传统 AI 系统的根本局限。当前的 LLM 主要基于"prompt-response"范式,本质上是一个确定性的函数映射。而研究任务具有以下特征:
架构影响:
传统架构:
Input → Fixed Pipeline → Output
问题:pipeline无法动态调整
多智能体架构:
Input → Dynamic Planning → Adaptive Execution → Emergent Output
↑ ↓
←── Feedback Loop ───┘
优势:可以根据发现调整策略
费曼式解读:
想象你是福尔摩斯在破案。你不可能一开始就知道所有线索在哪里。你可能先去犯罪现场,发现一个烟头,这让你想到去调查附近的烟草店,在那里你又发现了新线索...每个发现都可能改变你的调查方向。
AI 做研究也是如此——它需要能够像侦探一样,根据发现不断调整策略。
不同观点:
Anthropic 强调开放性,但我认为这里存在一个平衡问题。完全开放可能导致搜索空间爆炸,完全封闭又限制创新。理想的方案应该是"有界的开放性"——在合理的约束下保持探索的灵活性。
核心观点二:搜索的本质是多层次信息压缩
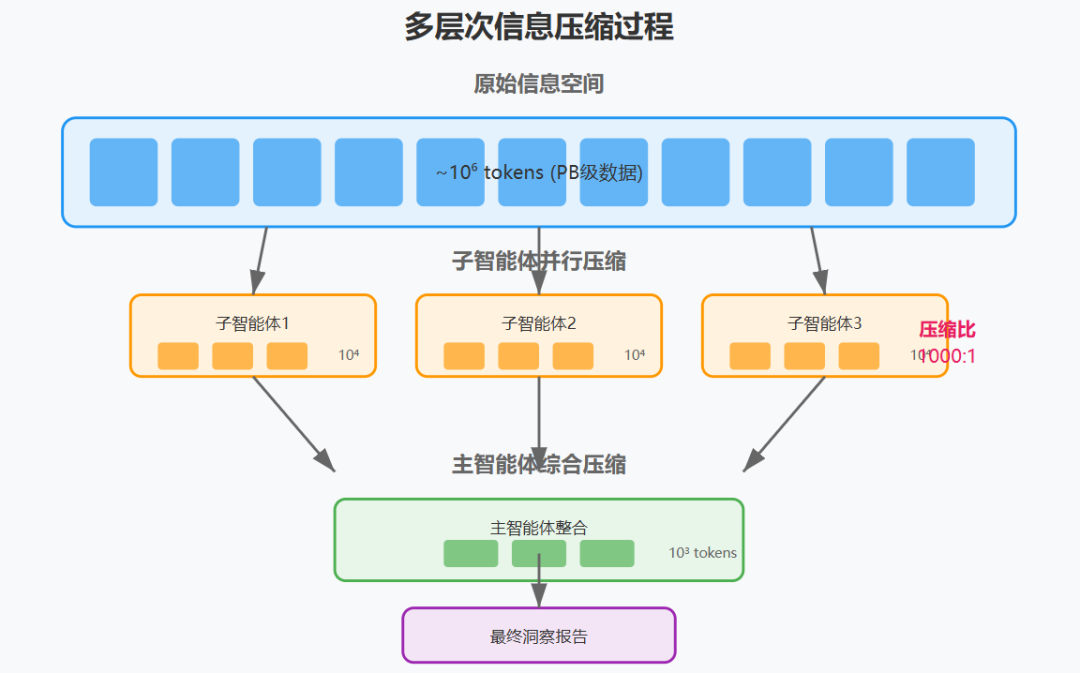
"The essence of search is compression: distilling insights from a vast corpus. Subagents facilitate compression by operating in parallel with their own context windows, exploring different aspects of the question simultaneously before condensing the most important tokens for the lead research agent. Each subagent also provides separation of concerns—distinct tools, prompts, and exploration trajectories—which reduces path dependency and enables thorough, independent investigations."
"搜索的本质是压缩:从庞大的语料库中提炼洞察。子智能体通过在各自的上下文窗口中并行操作来促进压缩,在为主研究智能体压缩最重要的标记之前,同时探索问题的不同方面。每个子智能体还提供了关注点分离——不同的工具、提示和探索轨迹——这减少了路径依赖性并实现了彻底、独立的调查。"
技术深度分析:
这是整篇文章最有洞察力的观点之一。从信息论角度看:
压缩效率计算:
原始信息空间:~10^6 tokens(网页、文档等)
子智能体压缩:~10^4 tokens(筛选后的相关信息)
主智能体整合:~10^3 tokens(最终报告)
总压缩比:1000:1
并行加速比:N(子智能体数量)
架构创新:
传统搜索架构:
Query → Search Engine → Top-K Results → LLM → Answer
问题:LLM需要处理所有信息,上下文窗口成为瓶颈
多智能体架构:
Query → Lead Agent → Plan
↓
┌────┼────┬────┐
↓ ↓ ↓ ↓
Sub1 Sub2 Sub3 SubN (并行压缩)
↓ ↓ ↓ ↓
10k 10k 10k 10k tokens
└────┼────┴────┘
↓
Lead Agent (二次压缩)
↓
Final Answer (1k tokens)
费曼式解读:
想象你要写一本关于"世界美食"的书。你不可能读遍所有烹饪书籍。更聪明的做法是:
-
找一个法国美食专家,让他总结法国菜精华 -
找一个中餐专家,总结中餐精髓 -
找一个意大利菜专家...
每个专家都是一个"压缩器",把海量信息压缩成精华。你再把这些精华整合成一本书。这就是多智能体系统的工作原理。
核心观点三:集体智能超越个体能力之和
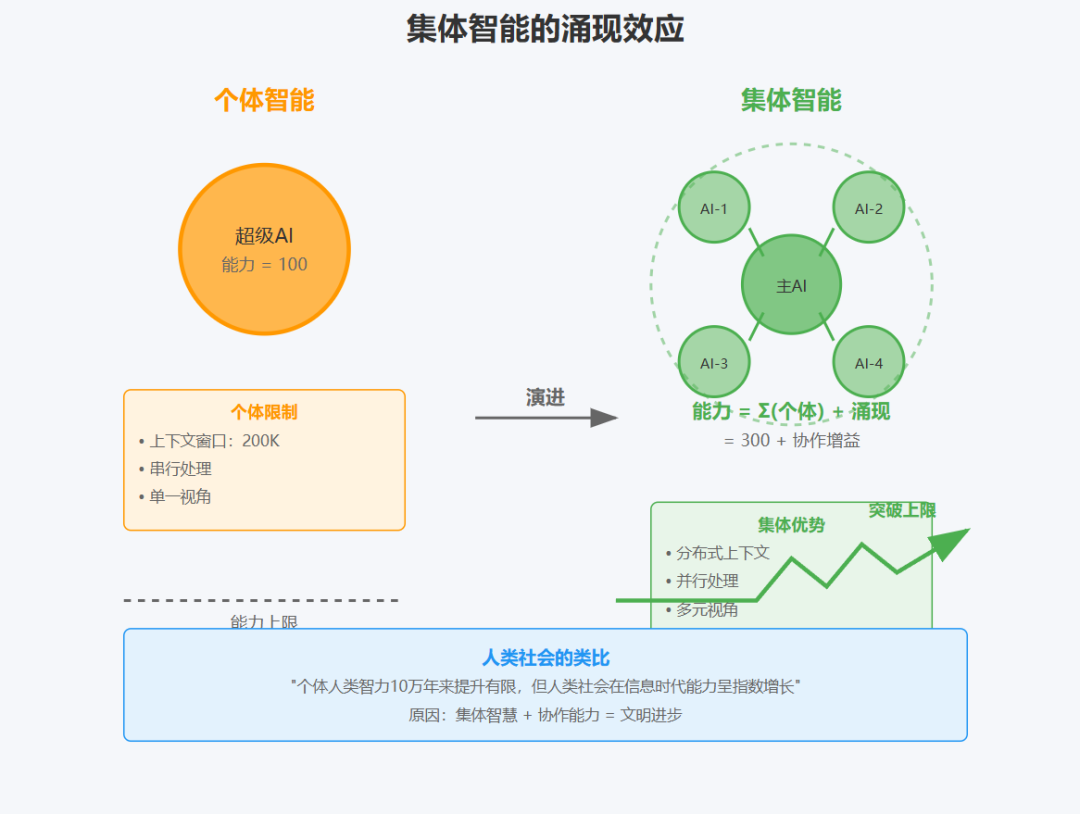
"Once intelligence reaches a threshold, multi-agent systems become a vital way to scale performance. For instance, although individual humans have become more intelligent in the last 100,000 years, human societies have become exponentially more capable in the information age because of our collective intelligence and ability to coordinate. Even generally-intelligent agents face limits when operating as individuals; groups of agents can accomplish far more."
"一旦智能达到阈值,多智能体系统就成为扩展性能的重要方式。例如,尽管个体人类在过去10万年中变得更加智能,但由于我们的集体智慧和协调能力,人类社会在信息时代变得成倍地更有能力。即使是通用智能体在作为个体运作时也面临限制;智能体群体可以完成更多任务。"
技术分析:
这个类比揭示了一个深刻的原理:智能系统的能力扩展有两条路径:
数学模型:
单智能体能力:P_single = f(model_size, training_data)
多智能体能力:P_multi = Σ(P_i) + Synergy(P_1, P_2, ..., P_n)
其中 Synergy 代表协作产生的涌现效应
关键洞察:当个体智能达到一定水平后,协作带来的提升远大于继续提升个体能力。这与人类社会的发展规律一致。
不同观点:
虽然类比很有启发性,但 AI 系统和人类社会有本质区别:
-
人类有共同的文化背景和沟通协议 -
AI 智能体之间的"理解"可能存在偏差 -
协调成本在 AI 系统中可能更高
因此,简单复制人类协作模式可能不是最优解。
核心观点四:性能提升的本质——Token 使用量是关键
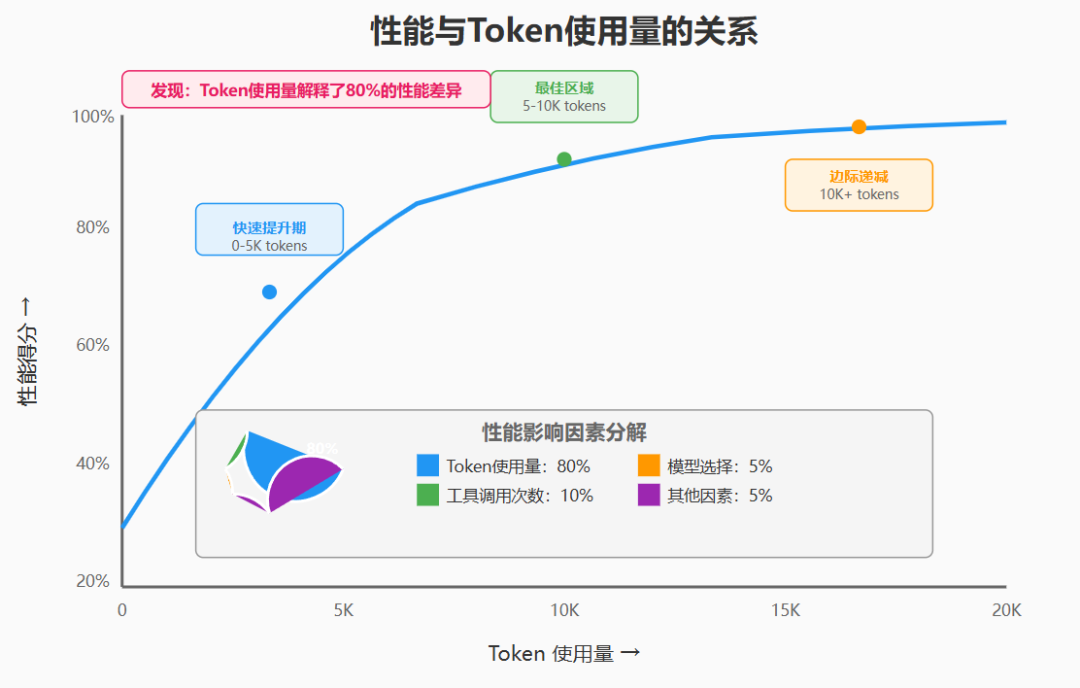
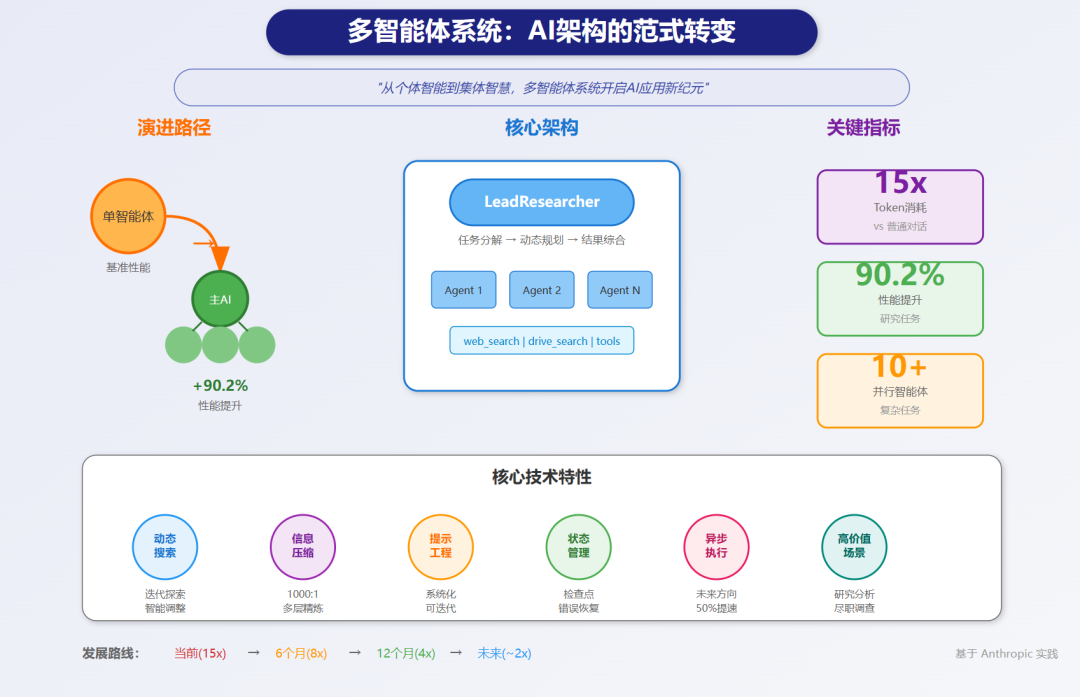
"In our analysis, three factors explained 95% of the performance variance in the BrowseComp evaluation (which tests the ability of browsing agents to locate hard-to-find information). We found that token usage by itself explains 80% of the variance, with the number of tool calls and the model choice as the two other explanatory factors."
"在我们的分析中,三个因素解释了BrowseComp评估中95%的性能差异(该评估测试浏览智能体定位难以找到的信息的能力)。我们发现标记使用本身解释了80%的差异,工具调用次数和模型选择是另外两个解释因素。"
技术深度分析:
这个发现具有重要的理论和实践意义:
-
性能主导因素:
-
Token 使用量:80% -
工具调用次数:~10% -
模型选择:~5% -
其他因素:~5%
-
理论意义:
-
计算量(token)是智能的必要条件 -
存在"思考深度"与性能的强相关性 -
简单增加模型大小不如增加计算深度 -
实践指导:
# 性能优化策略
def optimize_performance(task):
if task.complexity > threshold:
# 复杂任务:增加token预算比换模型更有效
return increase_token_budget()
else:
# 简单任务:优化prompt更重要
return optimize_prompt()
费曼式解读:
这就像做数学题。一道难题,你思考5分钟可能做不出来,思考30分钟就能找到思路。智能不仅取决于你多聪明(模型大小),更取决于你思考多深入(token使用量)。
批判性思考:
但这里有个悖论:如果性能主要取决于 token 使用量,那是否意味着我们可以通过无限增加 token 来无限提升性能?显然不是。这里一定存在边际效益递减,Anthropic 没有深入讨论这个问题。
核心观点五:架构选择——编排器模式的必然性
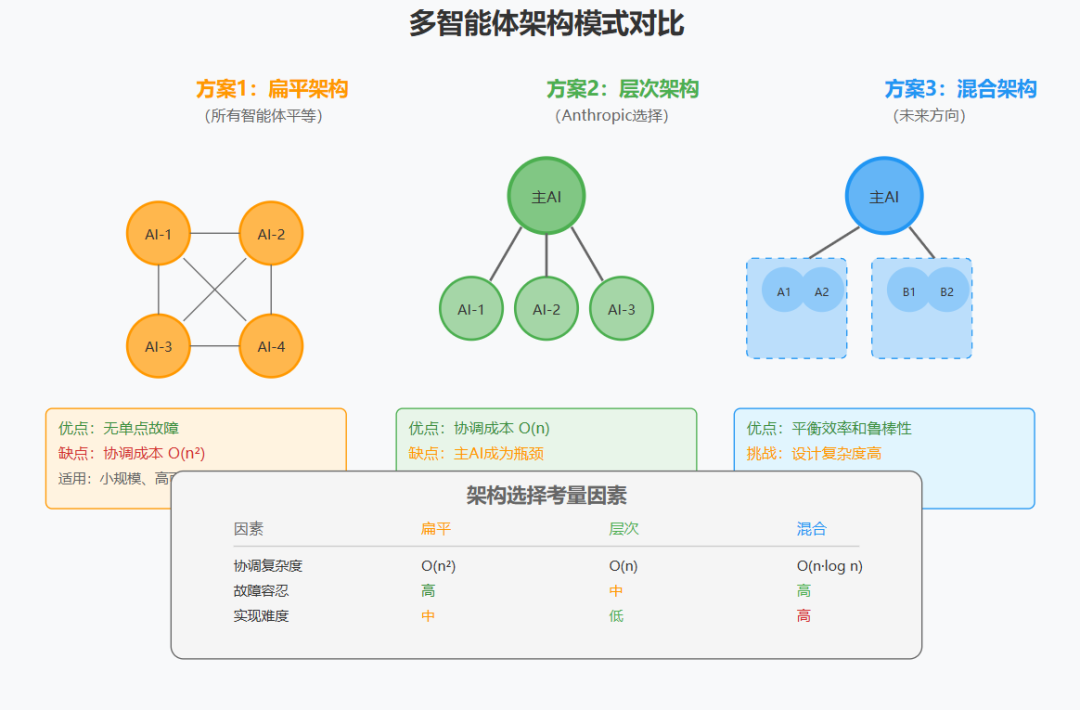
"Our Research system uses a multi-agent architecture with an orchestrator-worker pattern, where a lead agent coordinates the process while delegating to specialized subagents that operate in parallel."
"我们的研究系统使用具有编排器-工作者模式的多智能体架构,其中主智能体协调流程,同时委派给并行操作的专门子智能体。"
技术架构分析:
编排器-工作者(Orchestrator-Worker)模式不是随意选择,而是基于以下考虑:
架构对比:
方案1:扁平架构(所有智能体平等)
优点:无单点故障
缺点:协调成本指数增长 O(n²)
方案2:层次架构(Anthropic选择)
优点:协调成本线性 O(n)
缺点:主智能体成为瓶颈
方案3:混合架构(未来方向)
子团队内部扁平,团队间层次化
平衡了效率和鲁棒性
深入讨论:
Anthropic 选择层次架构是工程上的pragmatic选择,但这不一定是最终形态。随着智能体能力提升,更去中心化的架构可能会出现。
核心观点六:提示工程的系统化方法论
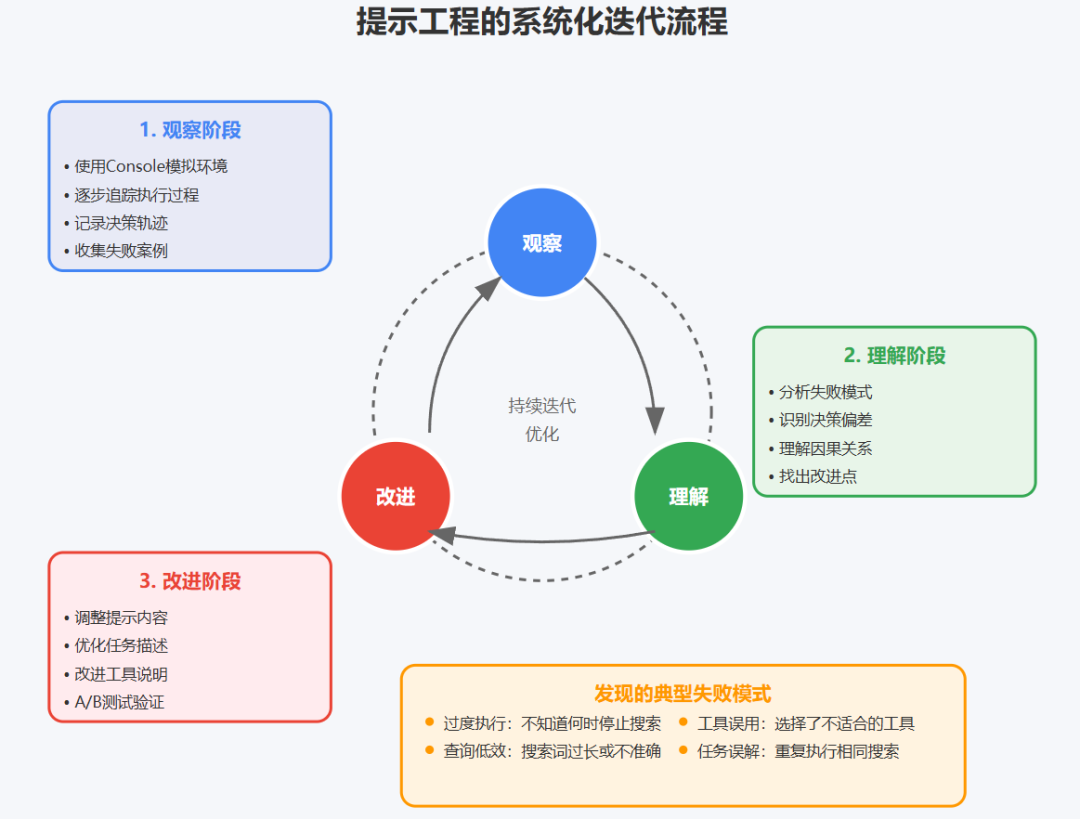
"To iterate on prompts, you must understand their effects. To help us do this, we built simulations using our Console with the exact prompts and tools from our system, then watched agents work step-by-step. This immediately revealed failure modes: agents continuing when they already had sufficient results, using overly verbose search queries, or selecting incorrect tools."
"要迭代提示,你必须理解它们的效果。为了帮助我们做到这一点,我们使用控制台构建了模拟,使用系统中的确切提示和工具,然后逐步观察智能体工作。这立即揭示了失败模式:智能体在已经有足够结果时继续工作,使用过于冗长的搜索查询,或选择不正确的工具。"
方法论提炼:
Anthropic 的提示工程方法可以总结为"观察-理解-改进"循环:
1. 建立观察系统:
观察维度:
├── 决策轨迹(智能体选择了什么)
├── 决策原因(为什么这样选择)
├── 执行效果(结果是否符合预期)
└── 失败模式(常见错误类型)
2. 失败模式分类:
-
过度执行:不知道何时停止
-
查询低效:搜索词过长或不准确
-
工具误用:选择了不适合的工具
3. 改进策略:
-
明确终止条件 -
提供查询示例 -
详细描述工具用途
费曼式解读:
这就像训练运动员。你不能只告诉他"跑快点",而要:
-
录像分析他的跑步姿势 -
找出问题(比如步幅太小) -
针对性训练改进
AI 的提示工程也是如此——需要细致的观察和针对性的优化。
核心观点七:任务委派的精确化演进
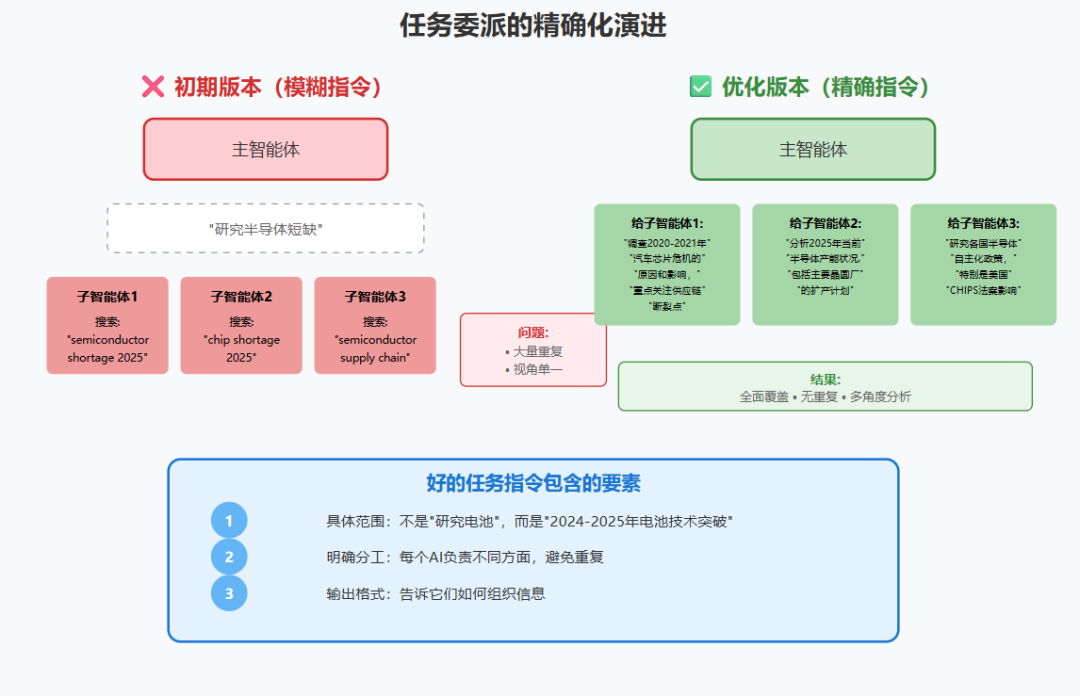
"We started by allowing the lead agent to give simple, short instructions like 'research the semiconductor shortage,' but found these instructions often were vague enough that subagents misinterpreted the task or performed the exact same searches as other agents. For instance, one subagent explored the 2021 automotive chip crisis while 2 others duplicated work investigating current 2025 supply chains."
"我们开始时允许主智能体给出简单、简短的指令,如'研究半导体短缺',但发现这些指令往往足够模糊,以至于子智能体误解任务或执行与其他智能体完全相同的搜索。例如,一个子智能体探索了2021年汽车芯片危机,而另外2个重复工作调查当前2025年的供应链。"
问题分析:
这个失败案例揭示了分布式系统的经典问题:
解决方案演进:
V1.0 - 自然语言指令(失败):
"研究半导体短缺"
问题:太模糊
V2.0 - 结构化任务(改进):
{
"任务": "半导体短缺分析",
"子任务": [
{
"agent_id": 1,
"focus": "历史分析",
"scope": "2020-2021汽车芯片危机",
"deliverable": "原因和影响总结"
},
{
"agent_id": 2,
"focus": "现状分析",
"scope": "2025年产能和供需",
"deliverable": "供应链瓶颈识别"
}
]
}
V3.0 - 动态协调(未来):
主智能体动态调整任务分配
子智能体可以相互通信避免重复
深刻教训:
在多智能体系统中,通信协议的设计和任务的清晰定义比单个智能体的能力更重要。这与分布式系统的经验一致。
核心观点八:生产环境的特殊挑战
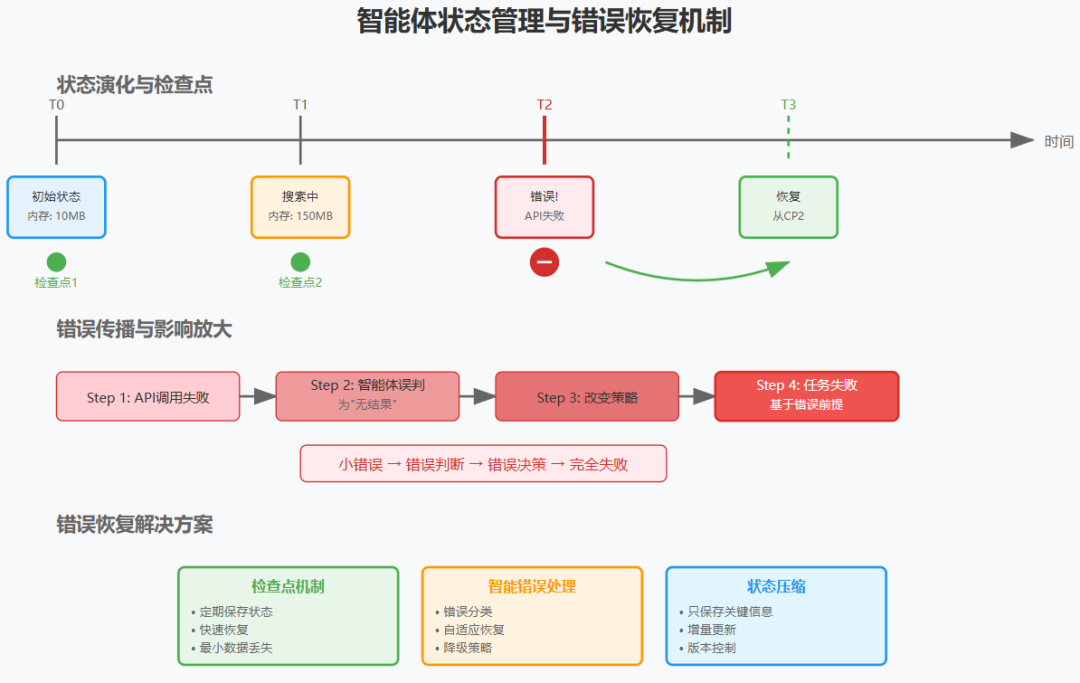
"Agents are stateful and errors compound. Agents can run for long periods of time, maintaining state across many tool calls. This means we need to durably execute code and handle errors along the way. Without effective mitigations, minor system failures can be catastrophic for agents."
"智能体是有状态的,错误会累积。智能体可以长时间运行,在多次工具调用中维护状态。这意味着我们需要持久地执行代码并在过程中处理错误。如果没有有效的缓解措施,微小的系统故障可能对智能体造成灾难性影响。"
技术挑战深度分析:
-
状态管理复杂度:
传统API:无状态,每次请求独立
智能体系统:有状态,需要维护:
├── 执行历史
├── 中间结果
├── 决策依据
└── 错误记录 -
错误放大效应:
错误传播链:
Step 1: API调用失败 →
Step 2: 智能体误判为"无结果" →
Step 3: 改变搜索策略 →
Step 4: 后续所有决策基于错误前提
结果:整个任务失败 -
解决方案架构:
class ResilientAgent:
def __init__(self):
self.checkpoints = [] # 状态快照
self.error_handler = ErrorRecovery()
def execute_with_recovery(self, task):
try:
result = self.execute(task)
self.checkpoint() # 成功则保存状态
return result
except Exception as e:
return self.error_handler.recover(
error=e,
last_checkpoint=self.checkpoints[-1]
)
费曼式解读:
想象你在玩一个复杂的角色扮演游戏,需要几个小时才能通关。如果游戏没有存档功能,一旦死亡就要从头开始,那会非常痛苦。智能体系统也是如此——需要"存档"(检查点)和"读档"(错误恢复)功能。
核心观点九:同步架构的权衡
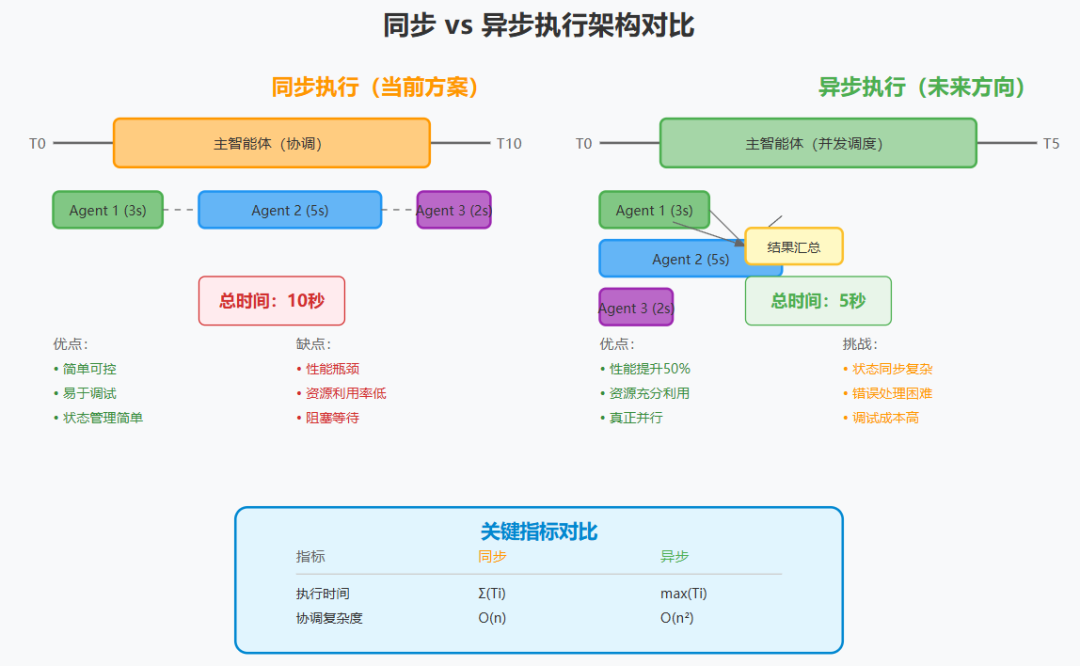
"Currently, our lead agents execute subagents synchronously, waiting for each set of subagents to complete before proceeding. This simplifies coordination, but creates bottlenecks in the information flow between agents."
"目前,我们的主智能体同步执行子智能体,等待每组子智能体完成后再继续。这简化了协调,但在智能体之间的信息流中创建了瓶颈。"
架构决策分析:
选择同步架构反映了经典的工程权衡:
同步架构:
-
优点:简单、可预测、易调试 -
缺点:性能受限、资源利用率低
异步架构:
-
优点:高性能、资源利用率高 -
缺点:复杂、难调试、一致性挑战
量化分析:
同步执行时间:T_sync = Σ(T_i)
异步执行时间:T_async = max(T_i)
加速比:S = T_sync / T_async
理论最大加速比 = N(智能体数量)
实际加速比 ≈ N / (1 + 协调开销)
批判性思考:
Anthropic 选择同步架构是明智的起点,但这显然不是终点。异步架构的挑战主要在于:
这些都是分布式系统的经典问题,已有成熟的解决方案,关键是如何适配到 AI 系统中。
核心观点十:经济性分析与 ROI 考量
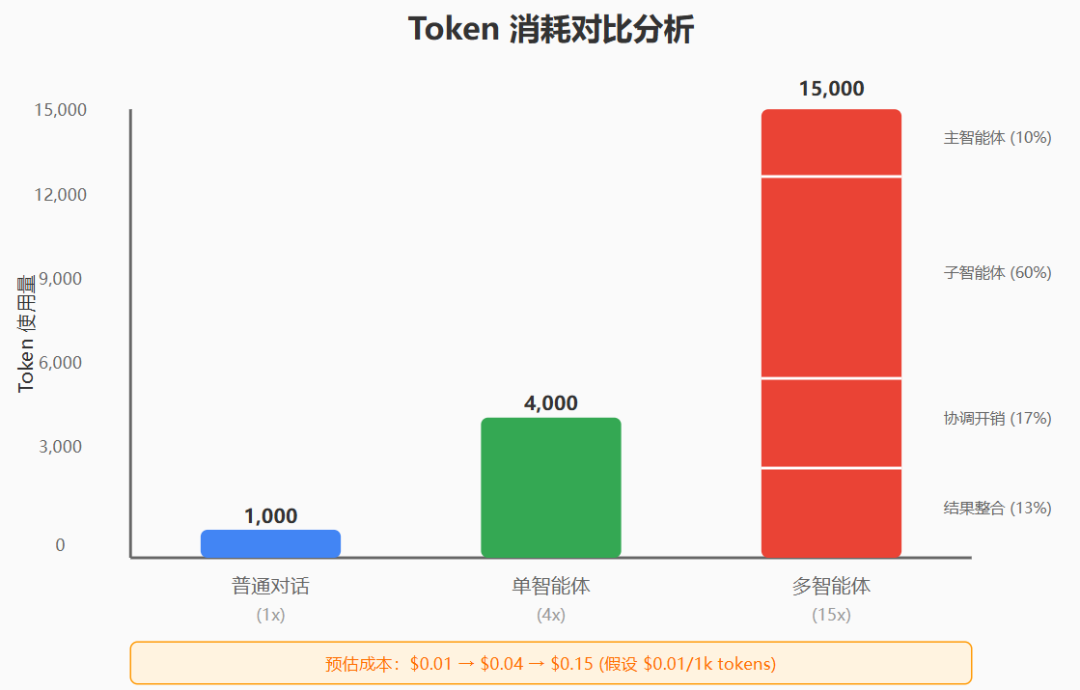
"In our data, agents typically use about 4× more tokens than chat interactions, and multi-agent systems use about 15× more tokens than chats. For economic viability, multi-agent systems require tasks where the value of the task is high enough to pay for the increased performance."
"在我们的数据中,智能体通常使用的标记是聊天交互的约4倍,多智能体系统使用的标记是聊天的约15倍。为了经济可行性,多智能体系统需要任务的价值足够高以支付增加的性能。"
成本结构深度分析:
-
成本放大系数:
基准(对话):1x
单智能体:4x
多智能体:15x
成本构成:
├── 思考过程:30%
├── 工具调用:40%
├── 协调开销:20%
└── 结果整合:10% -
ROI 计算模型:
def calculate_roi(task_value, complexity):
if complexity == "simple":
ai_cost = base_cost * 1
time_saved = 0.1 # 小时
elif complexity == "medium":
ai_cost = base_cost * 4
time_saved = 2 # 小时
else: # complex
ai_cost = base_cost * 15
time_saved = 40 # 小时
human_cost = hourly_rate * time_saved
roi = (human_cost - ai_cost) / ai_cost
return roi -
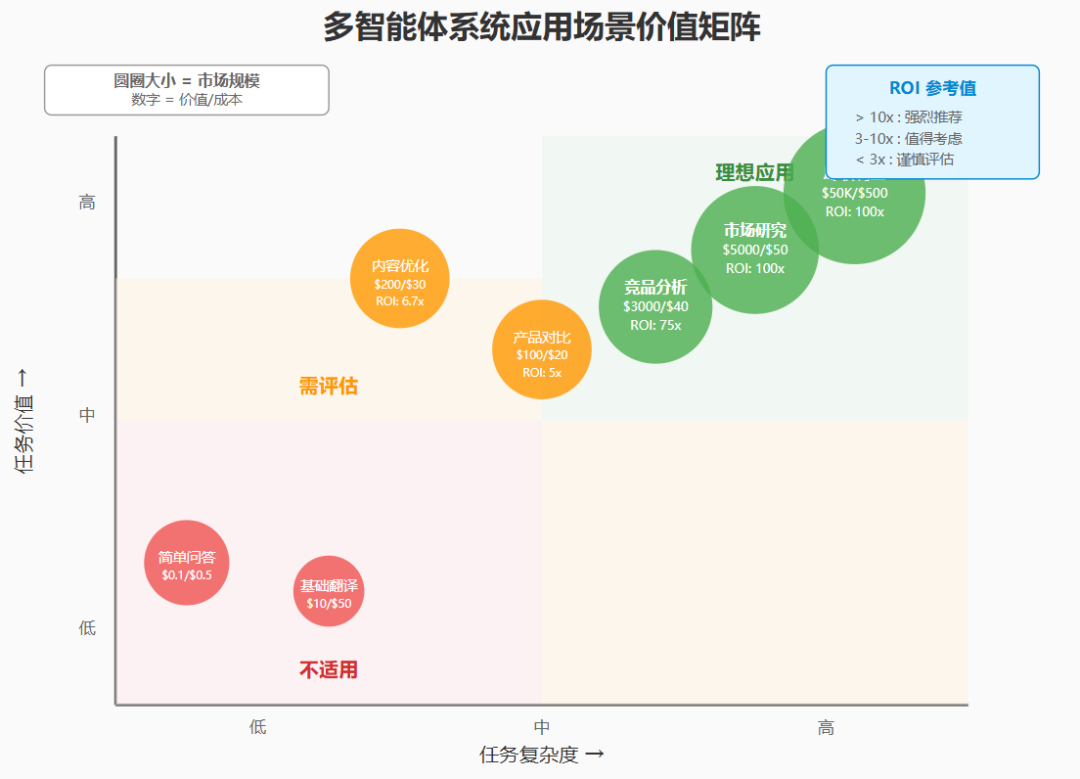
适用场景矩阵:
高价值 + 高复杂度 = 理想场景(如尽职调查)
高价值 + 低复杂度 = 过度设计
低价值 + 高复杂度 = 不经济
低价值 + 低复杂度 = 使用简单工具
优化潜力分析:
当前 15 倍的成本可能通过以下方式优化:
理论最优成本:约为当前的 40%,即 6 倍于普通对话。
二、技术架构的深度剖析
2.1 分层架构设计
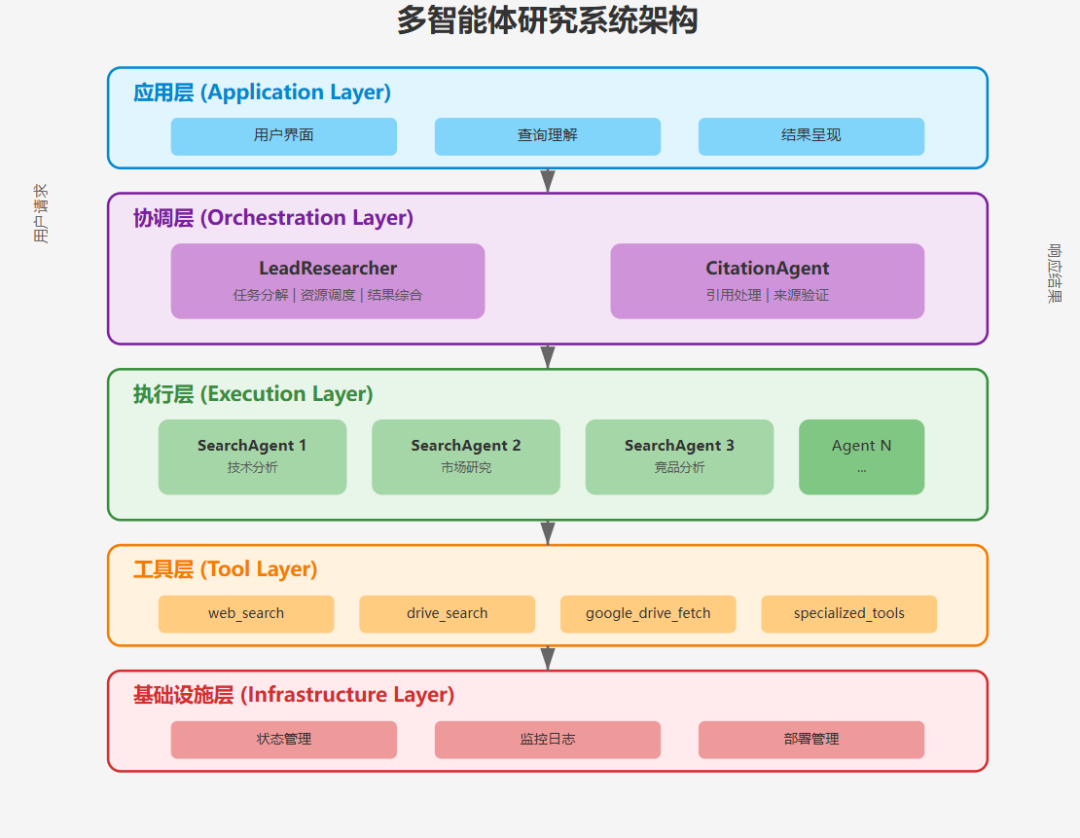
基于 Anthropic 的描述,完整的系统架构可以分解为以下层次:
┌─────────────────────────────────────┐
│ 应用层(Application) │
│ - 用户界面 │
│ - 查询理解 │
│ - 结果呈现 │
├─────────────────────────────────────┤
│ 协调层(Orchestration) │
│ - LeadResearcher(任务分解) │
│ - 资源调度 │
│ - 结果综合 │
│ - CitationAgent(引用处理) │
├─────────────────────────────────────┤
│ 执行层(Execution) │
│ - SearchAgent×N(并行搜索) │
│ - 特定领域智能体 │
│ - 错误处理机制 │
├─────────────────────────────────────┤
│ 工具层(Tools) │
│ - web_search │
│ - drive_search │
│ - 专用API接口 │
├─────────────────────────────────────┤
│ 基础设施层(Infrastructure) │
│ - 状态管理 │
│ - 监控日志 │
│ - 部署管理 │
└─────────────────────────────────────┘
关键设计决策:
-
为什么选择分层架构?
-
关注点分离,每层职责明确 -
便于测试和维护 -
支持渐进式优化
为什么主智能体不直接执行搜索?
-
避免上下文污染 -
实现真正的并行处理 -
便于任务的动态调整
2.2 信息流动机制
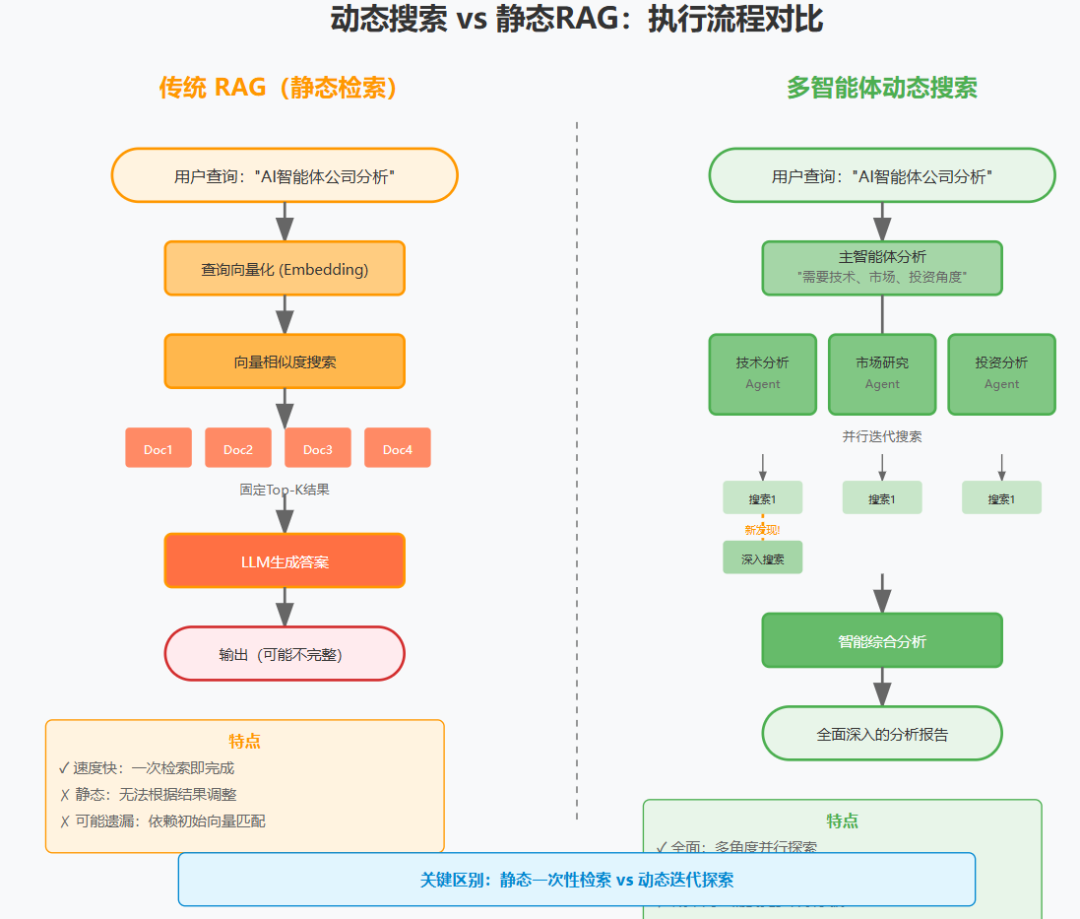
信息流动的三个阶段:
1. 扩散阶段(Divergence)
Query → LeadAgent → Multiple Subagents
特点:信息需求扩散到多个方向
2. 探索阶段(Exploration)
Subagents ←→ Tools
特点:并行探索,独立决策
3. 收敛阶段(Convergence)
Subagents → LeadAgent → Final Answer
特点:信息压缩,洞察提炼
关键创新:通过物理隔离(不同的智能体实例)实现逻辑隔离(不同的探索方向),避免了单一上下文的认知干扰。
三、提示工程的系统化实践
3.1 提示工程的三层框架
基于 Anthropic 的经验,可以构建一个三层提示优化框架:
第一层:观察与理解
# 建立系统化的观察机制
class PromptObserver:
def __init__(self):
self.decision_log = []
self.error_patterns = {}
def observe_agent(self, agent, task):
trace = agent.execute_with_trace(task)
self.analyze_decisions(trace)
self.identify_patterns(trace)
return self.generate_insights()
第二层:模式识别与分类
常见失败模式:
├── 过度执行(Over-execution)
│ └── 解决:明确终止条件
├── 低效查询(Inefficient Query)
│ └── 解决:提供查询模板
├── 工具误用(Tool Misuse)
│ └── 解决:详细工具说明
└── 任务误解(Task Misunderstanding)
└── 解决:结构化任务描述
第三层:迭代优化
优化循环:
1. 运行基准测试
2. 识别最大痛点
3. 针对性修改提示
4. A/B测试验证
5. 部署最优版本
3.2 任务委派的结构化模板
{
"task_template": {
"task_id": "unique_identifier",
"objective": "明确的目标描述",
"context": {
"background": "相关背景信息",
"constraints": "限制条件",
"priority": "优先级"
},
"specifications": {
"scope": "具体范围",
"deliverables": "预期输出",
"format": "输出格式",
"quality_criteria": "质量标准"
},
"resources": {
"tools": ["允许使用的工具"],
"time_budget": "时间预算",
"token_budget": "token预算"
},
"coordination": {
"dependencies": "依赖关系",
"communication": "通信方式"
}
}
}
这种结构化方法显著减少了任务理解的歧义。
四、性能优化与成本控制
4.1 性能优化的多维度策略
策略一:智能缓存机制
class IntelligentCache:
def __init__(self):
self.semantic_cache = {} # 语义级缓存
self.result_cache = {} # 结果级缓存
def get_or_compute(self, query, compute_fn):
# 检查语义相似的查询
similar_query = self.find_similar(query)
if similar_query:
return self.adapt_result(
self.semantic_cache[similar_query],
query
)
# 计算新结果
result = compute_fn(query)
self.semantic_cache[query] = result
return result
策略二:动态资源分配
def allocate_resources(task_complexity):
if task_complexity < 0.3:
return {"agents": 1, "tools": ["web_search"]}
elif task_complexity < 0.7:
return {"agents": 3, "tools": ["web_search", "analysis"]}
else:
return {"agents": 5+, "tools": "all"}
策略三:混合模型策略
-
路由层:小模型快速分类 -
执行层:根据任务选择适当大小的模型 -
质控层:大模型进行最终检查
4.2 成本模型与优化路径
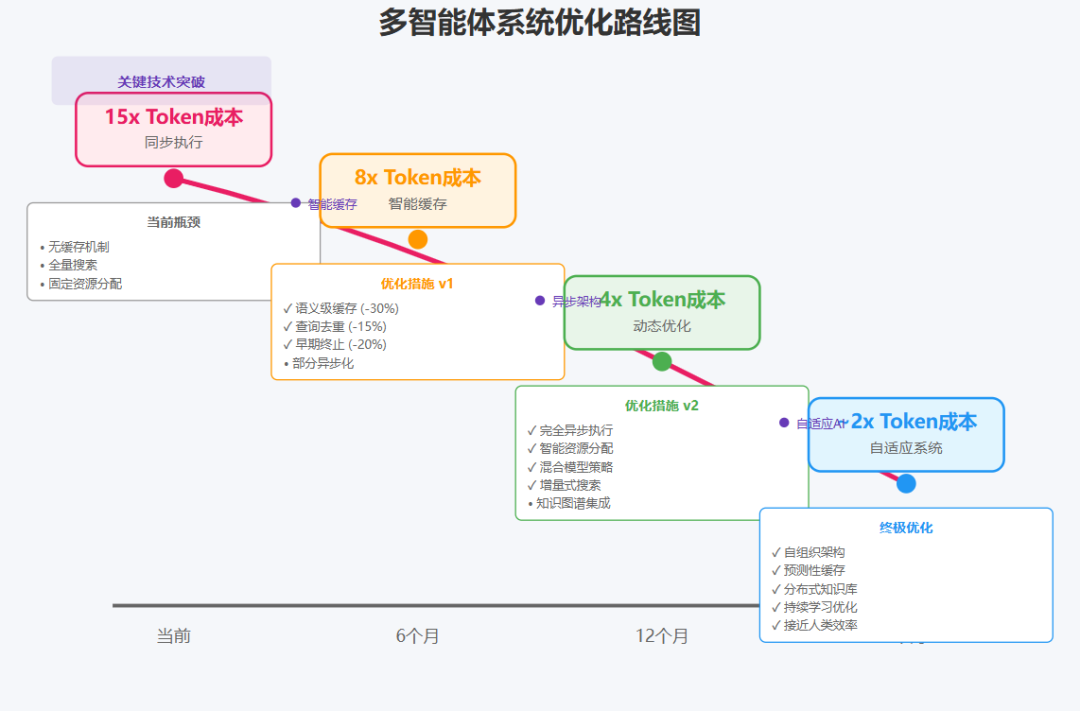
当前成本结构(15x):
├── 规划阶段:2x
├── 执行阶段:10x
├── 整合阶段:3x
优化后目标(6x):
├── 规划阶段:1x(缓存常见模式)
├── 执行阶段:4x(智能早停+缓存)
├── 整合阶段:1x(模板化输出)
关键优化技术:
1. 查询去重和合并
2. 结果增量更新
3. 智能采样而非全量搜索
4. 基于置信度的早停机制
五、未来展望与批判性思考
5.1 技术演进路线图
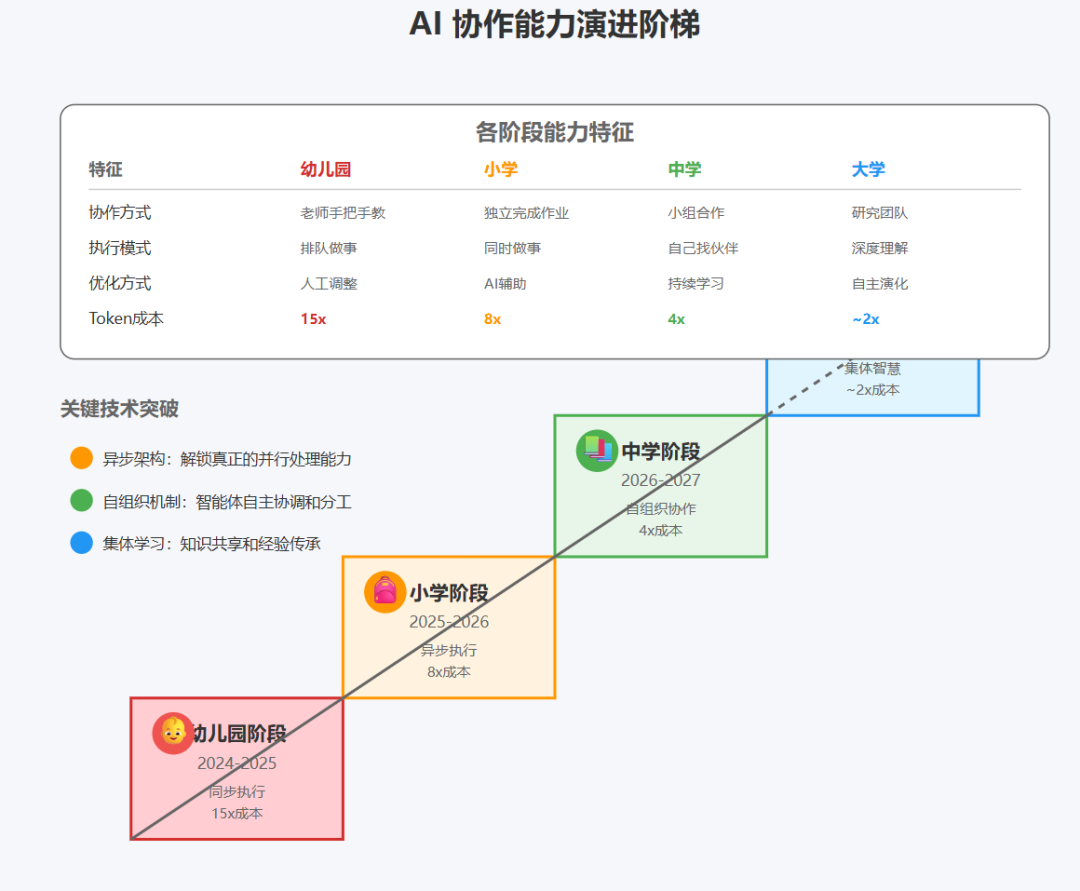
短期(6-12个月):
-
异步执行架构的实现 -
更智能的缓存机制 -
成本优化到 8x 以内
中期(1-2年):
-
智能体间的知识共享协议 -
自适应的任务分解 -
成本优化到 4x 以内
长期(2年+):
-
真正的分布式认知 -
自组织的智能体网络 -
成本接近人类水平
5.2 潜在风险与挑战
5.3 对行业的启示
六、总结与实践建议
核心结论
实践建议
对于想采用多智能体系统的团队:
对于研究者:
最后的思考
Anthropic 的实践为我们展示了一个可能的未来:AI 系统不再是孤立的模型,而是协作的智能体网络。这不仅是技术进步,更是对"智能"本质的重新理解。
正如人类文明的进步依赖于协作和知识传承,AI 的未来也必将走向协作和集体智能。Anthropic 的多智能体系统只是这个征程的开始,真正精彩的故事还在后面。
在这个快速变化的时代,保持开放的心态、批判性的思维、以及动手实践的勇气,或许是我们能从这篇文章中学到的最重要的东西。
相关文章
