
阿里妹导读
推理性能的提升涉及底层硬件、模型层,以及其他各个软件中间件层的相互协同,因此了解大模型技术架构的全局视角,有助于我们对推理性能的优化方案进行评估和选型。
随着 DeepSeek R1 和 Qwen2.5-Max 的发布,国内大模型推理需求激增,性能提升的主战场将从训练转移到推理。
-
计算资源成本的下降,更便宜 -
客户端体验的提升,内容生成更快

一、芯片层
二、面向芯片的编程语言和芯片开发包层
三、通用深度学习框架层
提供一系列基础工具和功能,简化了大模型的开发、训练和部署流程。教练水平决定训练效果,PyTorch 和 TensorFlow 是两大“顶流私教”,主流框架包括:
-
PyTorch:由 Facebook AI Research 开发并维护。采用动态计算图技术,在执行过程中能动态调整计算流程,与 Python 深度集成,提供直观的 API 接口和灵活的编程体验。适用于快速原型开发、研究和实验,尤其是需频繁修改和迭代模型的场景。
-
TensorFlow:由谷歌基于 DistBelief 研发的第二代人工智能学习系统,可用于 Python、JavaScript、C++ 和 Java 等多种编程语言,广泛应用于语音识别、图像识别等机器学习和深度学习领域,支持 CNN、RNN 和 LSTM 等算法。
-
JAX:由谷歌开发,旨在为科研人员提供一个既能够方便进行算法实验,又能充分利用硬件资源加速计算的工具,尤其在需要进行自动求导和并行计算的场景中表现出色。
-
MindSpore:有华为开源,是一种适用于端边云场景的新型开源深度学习训练/推理框架,为Ascend AI 处理器提供原生支持,以及软硬件协同优化。
-
PaddlePaddle:由百度开源,支持多种深度学习模型的高效训练,能在多 GPU 和多节点环境下分布式训练,优化计算资源使用效率。
-
MXNet:由 Carlos Guestrin 在华盛顿大学共同开发,是亚马逊云计算服务的首选深度学习框架,支持 C++、Python、Java、Julia、MATLAB、JavaScript、Go、R、Scala 等多种编程语言。
-
Caffe:由伯克利人工智能研究小组和伯克利视觉和学习中心开发,内核用 C++ 编写,有 Python 和 Matlab 相关接口。以模块化原则设计,实现了对新的数据格式、网络层和损失函数的轻松扩展。
四、大模型推理加速层
针对推理阶段优化计算效率与资源利用率,通过编译、量化、批处理等技术降低延迟与成本。这一层参与的行业玩家众多,有芯片制造商、云厂商、软件企业、模型社区、科研机构,提供包括开源方案和商业服务,后端接入大模型,提供 API 调用服务。
-
vLLM:由 UC Berkeley 研究团队开源的大语言模型推理和服务框架,采用 PagedAttention 技术,有效减少内存碎片,提升内存利用率,支持多种大语言模型,如通义、LLaMA 等,与 Hugging Face 生态集成良好,可直接加载 HF 上的模型权重。
-
TensorRT-LLM:是 NVIDIA 基于 TensorRT 优化的 LLM 开源推理库,深度集成 NVIDIA GPU 硬件特性,如 Tensor Core,可与 NVIDIA 其他工具和库(如 CUDA、cuBLAS 等)无缝配合,还可以与 Triton 框架结合,以提升服务在 NVIDIA GPU 上的推理效率。
-
ONNX Runtime:轻量级、跨平台的高性能推理引擎,由微软开发并维护,旨在打破不同深度学习框架之间的壁垒,使得模型可以在多种环境中高效运行,提高模型的可移植性和部署效率。
-
TGI:由Hugging Face 团队开发,紧密集成 Hugging Face 的 Transformer 库,可轻松加载和使用 Hugging Face 上的众多模型;支持分布式推理,可在多 GPU 环境下扩展服务能力。
-
Deepytorch Inference:阿里云 GPU 云服务器自研的AI推理加速器,专注于为Torch模型提供高性能的推理加速。通过对模型的计算图进行切割、执行层融合以及高性能OP的实现,大幅度提升PyTorch的推理性能。
-
BladeLLM:阿里云人工智能平台 PAI 自研的为大语言模型优化的推理引擎,在模型计算、生成引擎、服务框架、应用场景层均作了提升,性能优于主流开源框架。
-
SiliconLLM:硅基流动科技推出的专注于大模型推理加速的框架,自主研发了高效的算子和调度策略,支持多种硬件平台,可与多种深度学习框架协同工作。
五、大模型层
-
国外主流方案:OpenAI 的 GPT、Google 的 Gemini、Meta 的 LLaMA、Anthropic 的 Claude、Mistral AI、X 的 Grok,其中,Meta 的 LLaMA 和 Mistral AI 对模型核心能力进行了开源,其他大模型也有通过技术报告分享,或者部分能力开源的方式反馈社区。
-
国内主流方案:阿里云 Qwen、DeepSeek、百度文心一言、字节豆包、腾讯云混元、讯飞星火、kimi 等六小龙...其中,Qwen、DeepSeek 对模型核心能力进行了开源,其他大模型也有通过技术报告分享,或者部分能力开源的方式反馈社区。
六、计算平台层
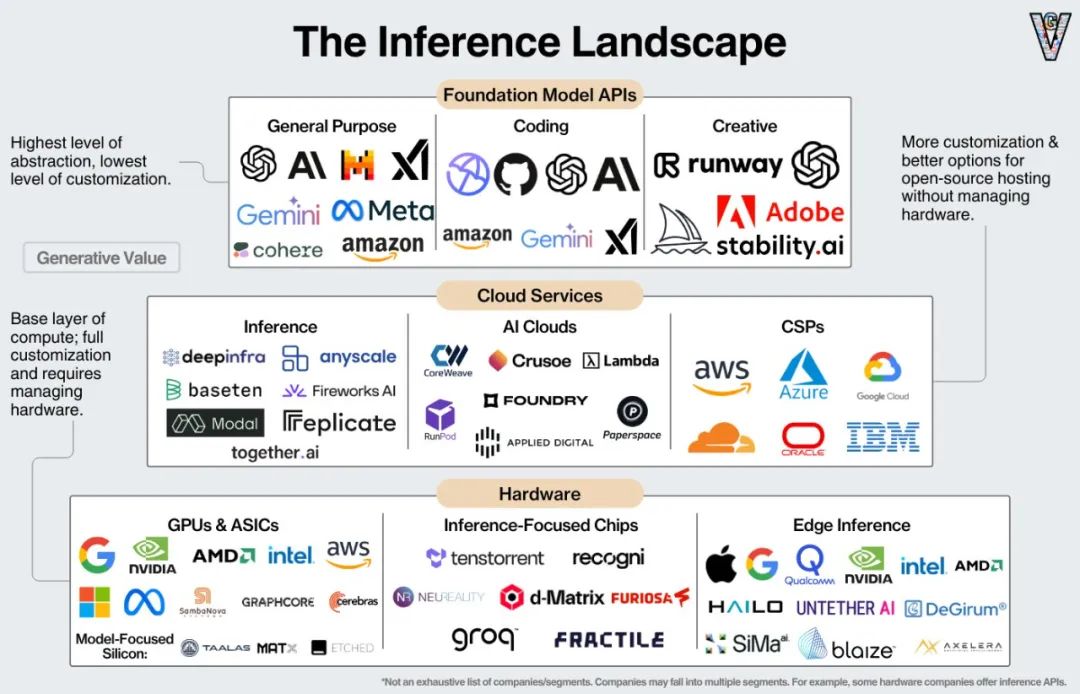
七、应用编排层
-
Langchain:由 Harrison Chase 于2022年创建的开源项目,通过 Chain、Agent、Memory 三大组件,像搭乐高一样组合工具链,支持 OpenAI 等30+模型 API,集成 Wikipedia、Wolfram Alpha 等200+外部服务,内置Chroma/Pinecone 等向量数据库接口,实现知识库实时检索增强。
-
LlamaIndex:聚焦于数据处理和索引构建,适用于需要对大量数据进行有效管理和利用的场景,特别是当你希望 LLM 能够基于特定领域的知识进行回答。
-
Spring AI Alibaba:专为 Spring 和 Java 开发者设计的智能体开发框架,对 AI 智能体应用的通用开发范式做了很好的抽象,从原子能力层次如对话模型接入、提示词模板到函数调用,再到高层次抽象如智能体编排、对话记忆,和国内大模型做了深度适配,还提供了应用从部署到运维的最佳实践,包括网关、配置管理、部署、可观测等。
-
Dify:是一个开源的 LLM 应用开发平台,提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等能力,轻松构建和运营生成式 AI 原生应用。
-
阿里云百炼:是一站式的大模型开发及应用构建平台。不论是开发者还是业务人员,都能深入参与大模型应用的设计和构建。无须代码,通过简单的界面操作,就可以开发 AI 应用。
此外,也可以使用云原生应用开发平台 CAP+函数计算 FC,以 Serverless 的范式,调用算力资源和编排 AI 应用。
八、流量管理层
-
长连接。由 AI 场景常见的 Websocket 和 SSE 协议决定,长连接的比例很高,要求网关更新配置操作对长连接无影响,不影响业务。
-
高延时。LLM 推理的响应延时比普通应用要高出很多,使得 AI 应用面向恶意攻击很脆弱,容易被构造慢请求进行异步并发攻击,攻击者的成本低,但服务端的开销很高。
-
大带宽。结合 LLM 上下文来回传输,以及高延时的特性,AI 场景对带宽的消耗远超普通应用,网关如果没有实现较好的流式处理能力和内存回收机制,容易导致内存快速上涨。
-
相比传统 Web 应用,大模型应用的内容生成时间更长,对话连续性对用户体验至关重要,如何避免后端插件更新导致的服务中断?
-
相比传统 Web 应用,大模型应用在服务端处理单个请求的资源消耗会大幅超过客户端,来自客户端的攻击成本更低,后端的资源开销更大,如何加固后端架构稳定性?
-
很多 AI 应用都会通过免费调用策略吸引用户,如何防止黑灰产爬取免费调用量封装成收费 API 所造成的资损?
-
不同于传统 Web 应用基于信息的匹配关系,大模型应用生成的内容则是基于人工智能推理,如果保障生产内容的合规和安全?
-
当接入多个大模型 API 时,如何屏蔽不同模型厂商 API 的调用差异,降低适配成本?
-
Higress:内核基于 Istio 和 Envoy,并基于生产业务需求做了增强,可用于部署 Web 类应用和大模型应用,在 AI 领域,已经支撑了通义千问 APP、百炼大模型 API、机器学习 PAI 平台、FastGPT、中华财险等 AI 业务。
-
Kong AI Gateway:基于 Kong 的插件架构,Kong AI Gateway 具有很强的可扩展性。开发者可以根据自己的需求开发自定义插件,以实现特定的功能,如自定义的流量控制策略、数据转换、模型框架的调度等。
-
阿里云云原生 API 网关:提供大模型相关的 API 的全生命周期管理,和阿里云其他云产品集成体验好,例如 PAI、函数计算等,同时基于 Higress 提供了诸多开源增强能力。
相关文章
