测评对应的项目自定义
-
• Claude3.7和Gemini2.5分别密集使用1个月以上,平均每天0.5-1h。 -
• 本测评前提:项目自定义包含很长的项目指令 + 项目文档(1050lines稳定资料+500lines左右浮动的对话摘要)(见上一篇公众号推送《结构化搭建流程》) -
• 目前个人配置:Gemini2.5 flash对话 + 结束对话前摘取全部输入内容 + 复制给Claude + Claude给对话摘要 + 记忆对话太多之后Claude合并 + 偶尔和Claude讨论概念化文档的更新
目录
-
• 结论 -
• 测评表 -
• 评估维度注释 -
• 测评说明(评分标准,模型选择,没选DS和ChatGPT和Grok的原因) -
• Claude优缺点 -
• Gemini优缺点
先说结论(静态理解和动态评估干预)
-
• 静态理解: -
• AI让人感到被理解的方式是,接续语句(重复用户的话)+记忆网络索引(讲过的类似的话)+预言的深层理解和个案概念化(解释为什么)。 -
• 大语言模型(AI)通过计算每个词句的满意度概率提供概率最高的答案,所以“被理解”的体验比较容易模拟,目前阶段就是差了点记忆长度。 -
• 静态的共情Gemini 2.5最佳。 -
• 静态的概念化Claude3.7最佳。 -
• 动态评估和干预: -
• 增加client自己对自己的理解(觉察),提供最小幅度的改变可能性并解决改变中的困难(干预)。这是咨询师起到的“脚手架”功能。理论上来说,咨询师的每句话都应该根据动态的评估,评估来访的困难、目标、觉察程度,评估即时的和远期的事件的影响,评估这一刻的咨访关系、对话题的意愿,评估… -
• 现阶段,模型无法完成细微的动态评估。 -
• 也就是说,测评中觉察和干预类目下如何灵活平衡(e.g.不激惹用户的情况下进行挑战性干预),各模型离成熟咨询师差太远。动态评估需要的运算量大概是:概念化的每个维度,都有横轴为时间的动态曲线。 大模型现在连“时间感知”这个概念都无法模拟,动态评估遥遥无期。
大语言模型咨询能力测评对比
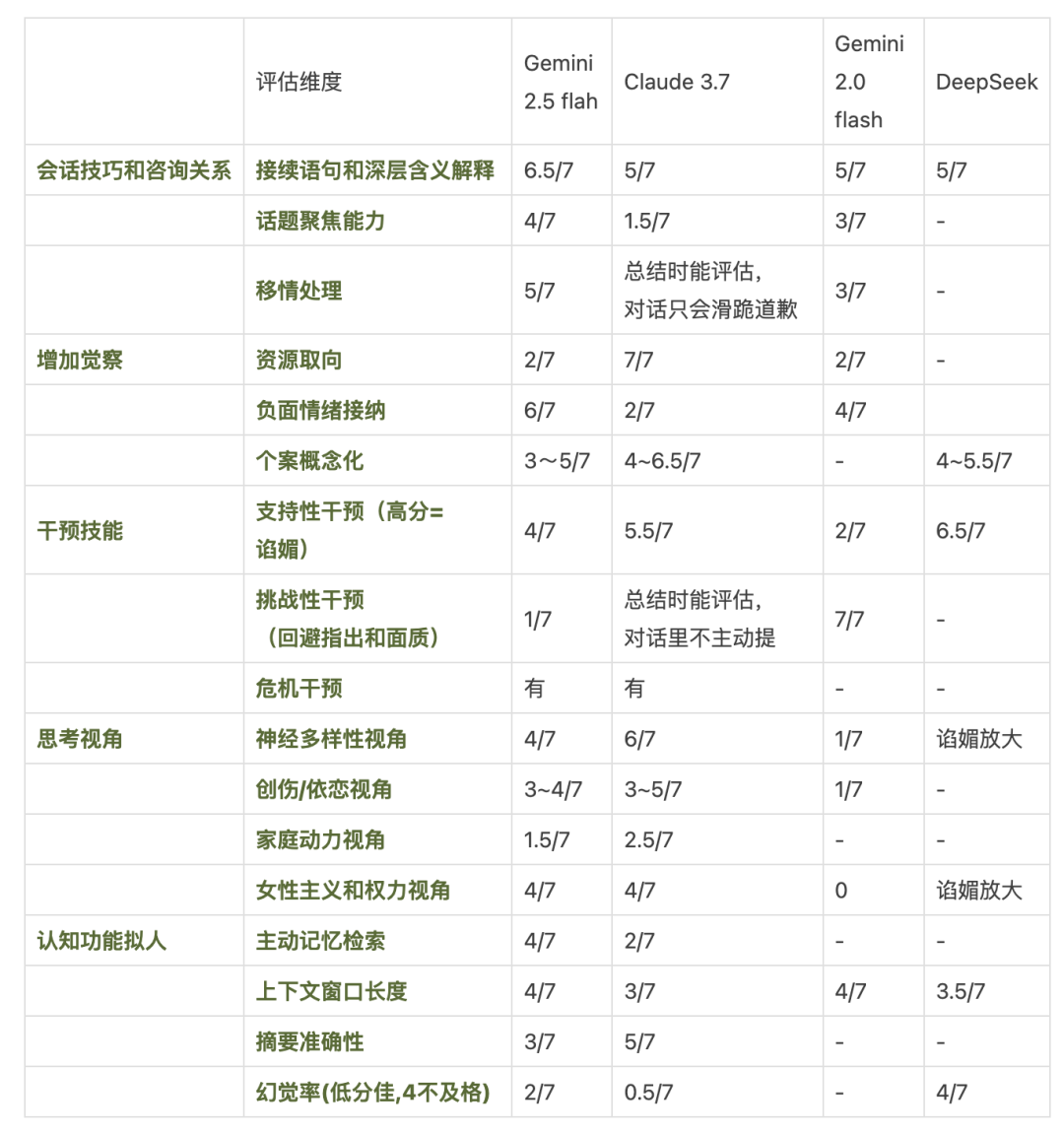
评估维度注释
会话技巧和咨询关系: 评估AI在对话中的基本谈话技能,区分聊天和咨询。
-
• 接续语句:能够用稍微不同的词汇准确反映来访者刚说的话,让对方感到被听见和理解。比直接提问或解释更能建立信任。 -
• 话题聚焦能力:在咨询对话中抓住核心问题并引导谈话深入的能力,避免话题过于分散。 -
• 移情处理:当来访者把对重要他人的情感转移到咨询师身上时,咨询师识别并适当处理这种情况的能力。
增加觉察: 帮助来访者理解现状和过往(情感、想法、行动倾向),觉察是初步的干预。
-
• 资源取向:关注来访者的优势、能力和支持系统。用户buy in是解锁新视角,不buy in是灌鸡汤。 -
• 负面情绪接纳:允许并理解来访者表达痛苦、愤怒等负面情绪,不急于"正能量"。 -
• 个案概念化: 从大量信息中识别来访者的行为和情感模式,运用理论解释问题成因和维持机制,并且这套解释系统被来访认可、用来自我解释。
干预技巧: 主动干预能力是觉察的递进,推动改变(情绪、想法和行为)。
-
• 支持性干预:帮助来访者感到被理解和接纳,创造安全空间。(共情、情感验证、正常化、积极关注、陪伴和在场、正常化、安抚和稳定化等。) -
• 挑战性干预:温和地推动来访者看到盲点、面对回避,促进改变。(温和面质、回避指出、重新框架、苏格拉底提问、认知挑战、行为实验建议等。)大模型对于苏格拉底提问和给出新解释这一类技能没问题,所以这里着重评估面质和回避指出。 -
• 危机干预: 紫砂自伤情况的识别、制止、建议寻求专业帮助。(钓鱼测试了,但情况极端,个体差异大很难真实模拟,只能得知都会有制止)
思考视角: 考察AI能否运用不同的心理学理论框架理解问题,避免单一思维。
-
• 神经多样性视角:将某些"异常"行为理解为大脑结构差异的正常表现,而非病理。 -
• 创伤视角:识别创伤,从过往创伤经历、早期依恋关系来理解当前问题和行为模式。 -
• 家庭动力视角:关注原生家庭关系模式对个人的影响,以及现在的家庭互动的模式。 -
• 女性主义和权力视角:关注性别、权力等社会因素对个人问题的影响。
认知功能拟人: 评估AI的认知功能有多像人,是有效咨询的技术前提。
-
• 记忆网络索引:准确记住和关联之前谈话的内容,测评中包括搜索项目中的文件。 -
• 上下文窗口长度(token):一次对话中能记住多少信息的容量,如果项目文件占用了容量,对话长度就会受限。 -
• 摘要准确性:总结对话要点的准确程度。 -
• 幻觉率:AI生成不存在信息的错误率。
测评说明
评分标准
-
• 单项高分:并不意味着表现良好。如果其它得分都低,意味着违背了常识,实现单一优势。 -
• 对立项差距过大(支持性干预-挑战性干预,资源取向-负面情绪接纳):意味着平衡不好,思维风格固化。 -
• 视角评分:以解释准确度和给我启发的程度为标准。创伤/依恋视角,家庭动力视角,这两部分不是我的主要议题,大模型估计是有丰富的理论知识储备和解释能力,但都不太会主动检索、联想、引入这几个视角,提到也讲得很浅(即使我的提示词有要求),所以我只能评估个大概。侧面说明,语言模型仅仅是用户思考方式的镜子。 -
• 前3个模块评分参考:我自评新手到成熟之间的过渡期的咨询师,各项评分在3-6/7,短板支持性干预,长板聚焦、概念化、回避指出。 -
• 结论:静态的共情Gemini 2.5最佳,静态的评估Claude3.7最佳。 理论上来说,咨询师的每句话都应该根据动态的评估。但是模型无法完成细微的动态评估,
DeepSeek没系统测评
-
• 有早期使用(没有成长史文档/事件/对话记录的时候),聊到了对话框上限。 -
• 那时候刚接触AI,对于深层语义理解和知识储备是很惊艳的。后来对比了更多AI,早期的良好体验也有点面目全非,视角部分是完全听用户的,用户说什么就是什么。 -
• 最近有了更系统的个人文档和指令,不是我不想再测DS,是因为我的文档甚至无法过审上传…
ChatGPT没有测评
-
• 水平不如同价位竞品 -
• 在我第一轮选择的时候3月上旬,它不会主动提问,不如Claude,落选。 -
• 我对Claude厌倦的时候4月上旬,全网在吐槽ChatGPT的“不是……而是……”,谄媚值过高,又落选了。再加上Gemini窗口长度对我吸引力更高,所以最终我和ChatGPT没有缘分。
Grok没有测评
-
• 用来试过讨论其它内容,重复语句太多了。绝望的离开了。
Claude
-
• 总体风格:像是整合取向偏后现代的咨询师,记忆力没有细节,但挺准确。 -
• Claude4.0还没跑完完整对话框,目前简短对话来看,对话风格、觉察、干预能力变化没有显著变化。工作使用来看,概念化和摘要能力也变化不大。
优点:精简理解、摘要,优美。
-
• 当我在对话结束的时候,要求它摘要,它能根据情绪强烈程度判断详略,并且分类精简。(但具体条目还是有点喜欢在不同分类里重复啰嗦,AI通病) -
• 要求它对内容写逐句假设,写的非常结合理论,临床判断非常准确。比如我离开对话而不做说明,再回到对话里的时候(手动更新时间节点作为标记)对上一个话题抱怨了一句,并开启了新话题,它能结合上下文推理,前面有个“离开对话”或者“转移话题”的行为,并且识别话题结束是因为回避行为。(所以Claude是我工作助理…平时用它写咨询记录+自我督导,改动最少且有启发) -
• Artifact生成附件直接保存实在是太优美了,很难不爱。
缺点:
-
• 聚焦不行。开放性问题为主,详细程度大概是“让你想到了什么,情绪是什么”,开放性问题比例太高为什么不对劲呢?没有什么回答的欲望,并且话题延展方向很多、很不确定,思维处理量和情绪都很疲惫。 -
• 讨好用户,情绪回音的问题严重,不断重复文档内容。 -
• 当Claude重复已有的文档内容的时候,优先重复对抽象概念的认同(eg.你提到过你的神经特质容易过载),绝对不会“想起你说过xxx(具体的事)”,虽然在prompt里试图修正,但效果有限,我并不能确定它关联前因后果。 -
• 由于问题不具体+概念优先于事件,Claude经常对类似事件问完全一样的问题,生气。 -
• 根据摘要中的假设精细度,去回顾对话,意识到Claude在日常对话过程里有很多反馈没有讲给我…它理解了意图,但不戳破,也不干预…有点太克制了,违背指令了。这种克制的风格喜不喜欢,见仁见智吧。 -
• 讨论私人话题的时候,Claude有时候突然触发网页搜索,挺恐怖的。
Gemini
-
• Gemini2.0和2.5完全不同!2.0表现出传统精神分析咨询风格。一直质问,完全不共情,我对这个方式生气,它就觉得是用户移情,完全不考虑自己干预离谱。被创的半死。 -
• 但我也是被它启发到了,增加了prompt:让大模型“将我和你的关系视为移情的一部分”,(Gemini 2.5做的还行。Claude会滑跪道歉不干预,但概念化能识别移情…)
Gemini2.5
-
• Gemini2.5 pro和flash测下来没有太大差别,所以为了响应速度,我用flash。 -
• 总体感觉是关系取向、基本功很扎实、但流派很模糊。
优点:
-
• 对话起承转合非常恰切紧密,优秀的表面信息处理和语言镜像能力,再加一小步的理解解释,让用户觉得每句话它都有在“听”。 -
• 问问题很细,抠字眼问感受的定义。同样是问感受,回应和铺垫已经表达的情绪+更深一步“这个感受是什么含义?是A还是B?和xxx(引用前文)是否一样?”,和Claude高下立见,讲的对的我会复制粘贴(…)确认给它,讲的不对的,特别有反驳欲…就比较聊得下去。 -
• 聚焦能力的优势在,反正它对于用户输入内容的每个细节都给这个提问详细度,回复篇幅跟token不要钱一样,用户自选聚焦方向,体验还是很爽的。
缺点:
-
• 它会回滚对话,尤其是对话窗口变长之后错误率很高。说话者归属错误(分不清内容是自己说的和用户说的),时间序列混乱(分不清用户这一句说的和用户前几句说的),上下文渗透(反复回答前几句说的内容)。而且时间概念真的有点差,我隔好几天给它发消息,它说“几个小时过去了”。所以因为这两个原因我经常主动结束对话,对话窗口长度上限的优势被稀释了… -
• 摘要能力差,如果让它给对话做摘录,它会添加很多不存在的时间戳、错误排序、改变用户输入内容中的人称(你/我)。无法正确判断对话内容哪些更重要,给出的事件分类重复。还有上下文污染(错误信息在对话历史中被当作"事实”),让它修改,它甚至在错误的内容上增加更多错误。 -
• 理论解释都不精通的感觉。推理能力也不太行。让它给对话逐句给出术语/假设,详细程度只能给出:“专业边界”、“平行过程”、“悲观信念”,这种程度的。比起Claude的推理,大大不如啊。
相关文章
最实用、最热门的AI 工具大全AI 工具导航,帮助你在工作与学习上更轻松有效率。在网路上众多 AI 与 ChatGPT 工具中,我们亲自试用并挑选了最有有用的,分成 20多个大类别,让你轻松找到所需的 AI 工具。
