?工具 是 Agent 与外部世界交互的媒介/手段,工具包含:
-
函数:仅返回各种调用参数,调用 api 的工作由用户侧而非 Agent 实现
-
扩展:供 Agent 直接调用的各种应用服务接口,如 Google Flights API
-
数据存储
-
插件
尽管语言模型擅长处理信息,但它们缺乏直接感知和影响现实世界的能力。这限制了它们在与外部系统或数据交互的情况下发挥作用。这意味着,从某种意义上说,一个语言模型的表现仅取决于它从训练数据中学到的东西。但无论我们向模型输入多少数据,它们仍然缺乏与外界交互的基本能力。那么,我们如何赋予模型与外部系统进行实时、上下文感知的交互能力呢?
函数(Functions)、扩展(Extensions)、数据存储(Data Stores)和插件(Plugins)都是为模型提供这种关键能力的方式。
尽管这些工具有许多名称,但它们才是将我们的基础模型与外部世界连接起来的纽带。这种与外部系统及数据的连接,使得我们的代理能够执行更多种类的任务,并且执行得更加准确和可靠。例如,工具可以让代理调整智能家居设置、更新日历、从数据库中获取用户信息,或根据一组特定指令发送电子邮件。
截至本文发布日期,Google 模型能够交互的三种主要工具类型是扩展、函数和数据存储。通过为 Agent 配备工具,我们解锁了它们巨大的潜力,不仅让它们能够理解世界,还能对其采取行动,打开了通往无数新应用和可能性的大门。
2.1 扩展 Extensions
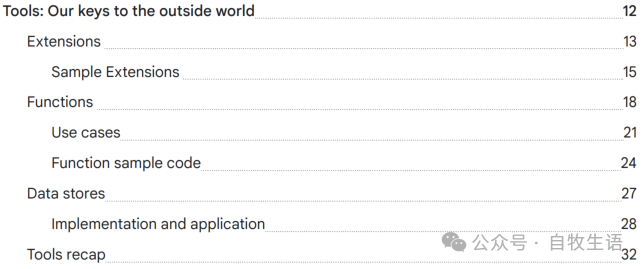
理解 Extensions 最简单的方式就是把它们看作是在 API 和 Agent 之间架起一座标准化的桥梁,使得 Agent 能够无缝执行 API,而不受其底层实现的影响。
假设你构建了一个帮助用户预订航班的 Agent 。你知道你想使用 Google Flights API 来获取航班信息,但你还不确定如何让你的 Agent 调用这个 API 端点。

图3. Agent如何与外部API交互?
一种方法可能是实现自定义代码,该代码会接收用户的查询,解析查询中的相关信息,然后进行 API 调用。例如,在航班预订的使用场景中,用户可能会说:“我想从奥斯汀飞往苏黎世预订航班。”
在这种情况下,我们的自定义代码解决方案需要在尝试进行 API 调用之前,从用户查询中提取“奥斯汀”和“苏黎世”作为相关实体。
但如果用户说:“ 我想预订飞往苏黎世的航班 ”,但没有提供出发城市,会发生什么?
API 调用会因为没有所需数据而失败,并且需要实现更多代码来捕捉此类边缘和极端情况。这种方法不具备扩展性,并且在任何超出已实现自定义代码的场景中很容易出现问题。一种更具弹性的方法是使用扩展。扩展通过以下方式弥合 Agent 与 API 之间的差距:
-
通过示例教导 Agent 如何使用 API 端点。
-
教导 Agent 成功调用 API 端点所需的参数或参数。
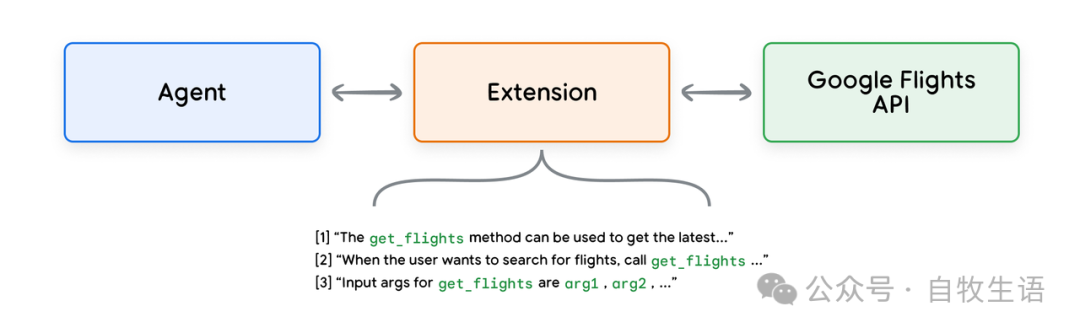
图4. 扩展将代理连接到外部API
扩展可以独立于 Agent 进行设计,但应作为 Agent 配置的一部分提供。 Agent 在运行时使用模型和示例来决定解决用户查询时最合适的扩展(如果有)。
这突显了扩展的一个关键优势:其内置的示例类型,使得 Agent 能够动态选择最适合任务的扩展。

图5. Agent、Extension和API之间的一对多关系
设想软件开发者解决用户问题的情形,他们决定使用哪些 API 端点。若用户想订机票,开发者或会调用 Google Flights API。若用户想知与其位置最近的咖啡馆,开发者或会用 Google Maps API。
同理, Agent / 模型栈利用一套已知的扩展来决定哪个最适合用户查询。如欲见扩展功能实操,可于 Gemini 应用中进入设置>扩展,启用欲试的扩展。譬如,启用 Google Flights 扩展后,可询问 Gemini:“显示从奥斯汀到苏黎世下周五起飞的航班。”
2.1.1 扩展示例 Sample Extensions
为简化扩展的使用,Google 提供了一些开箱即用的扩展,可以快速导入到项目中,并使用最少的配置。例如,代码片段 1 中的代码解释器扩展允许你从自然语言描述生成并运行 Python 代码。
Pythonimport vertexaiimport pprintPROJECT_ID = "YOUR_PROJECT_ID"REGION = "us-central1"vertexai.init(project=PROJECT_ID, location=REGION)from vertexai.preview.extensions import Extensionextension_code_interpreter = Extension.from_hub("code_interpreter")CODE_QUERY = """Write a python method to invert a binary tree in O(n) time."""response = extension_code_interpreter.execute(operation_id = "generate_and_execute",operation_params = {"query": CODE_QUERY})print("Generated Code:")pprint.pprint({response['generated_code']})# The above snippet will generate the following code.```Generated Code:class TreeNode:def __init__(self, val=0, left=None, right=None):self.val = valself.left = leftself.right = rightdef invert_binary_tree(root):"""Inverts a binary tree.Args:root: The root of the binary tree.Returns:The root of the inverted binary tree."""if not root:return None# Swap the left and right children recursivelyroot.left, root.right =invert_binary_tree(root.right), invert_binary_tree(root.left)return root# Example usage:# Construct a sample binary treeroot = TreeNode(4)root.left = TreeNode(2)root.right = TreeNode(7)root.left.left = TreeNode(1)root.left.right = TreeNode(3)root.right.left = TreeNode(6)root.right.right = TreeNode(9)# Invert the binary treeinverted_root = invert_binary_tree(root)```
片段 1。 代码解释器扩展可以生成和运行 Python 代码
2.2 函数 Functions
在软件工程领域,函数被定义为自包含的代码模块,用于完成特定任务并可根据需要重复使用。当软件开发人员编写程序时,他们通常会创建许多函数来执行各种任务。他们还会定义何时调用 function_a 而不是 function_b 的逻辑,以及预期的输入和输出。
在 Agent 领域,函数的工作方式非常相似,但我们可用模型替代软件开发人员。模型可以根据一组已知函数,决定何时使用每个函数以及根据其规范所需的参数。函数与扩展有几个不同之处,最显著的是:
-
1. 模型输出函数及其参数,但不进行实时的 API 调用。
-
2. 函数在客户端执行,而扩展在代理端执行。
再次以我们的 Google 航班示例为例,函数的一个简单设置可能看起来如图 7 所示。
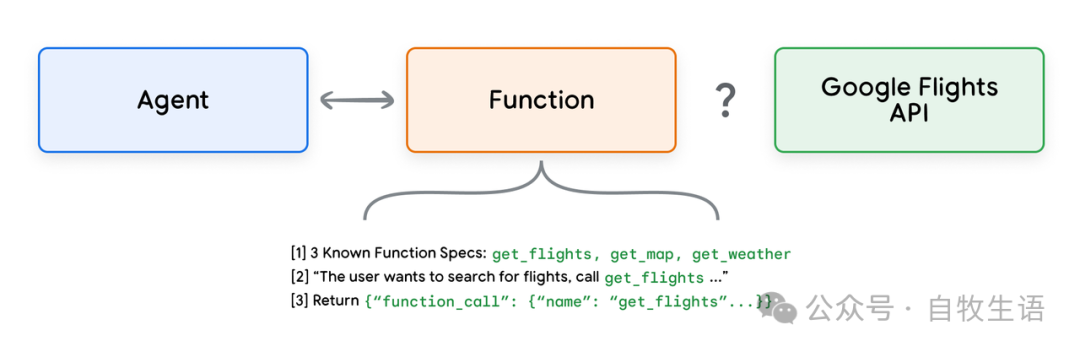
图7. 函数如何与外部API交互?
需要注意的是,这里的主要区别在于,函数和 Agent 都未直接与 Google Flights API 进行交互。那么,API 调用究竟是如何发生的呢?
通过函数,调用实际 API 端点的逻辑和执行过程从 Agent 转移到了客户端应用程序,如图 8 和图 9 所示。这为开发者提供了对应用程序数据流动的更精细控制。开发者选择使用函数而非扩展的原因有很多,但一些常见用例如下:
-
API 调用需要在应用程序堆栈的另一层进行,而非直接在 Agent 架构流程中(例如中间件系统、前端框架等)。
-
由于安全或认证限制, Agent 无法直接调用 API(例如 API 未暴露于互联网,或 Agent 基础设施无法访问)。
-
由于时序或操作顺序的限制, Agent 无法实时进行 API 调用(例如批处理操作、人机协作审查等)。
-
API 响应需要应用额外的数据转换逻辑,这些逻辑是 Agent 无法执行的。例如,考虑一个 API 端点,它不提供用于限制返回结果数量的过滤机制。在客户端使用函数为开发者提供了更多的机会来进行这些转换。
-
开发者希望在不影响 API 端点部署的情况下迭代 Agent 开发(即函数调用可以像 API 的“存根 stubbing ”一样发挥作用)
尽管从图 8 中可以看出,这两种方法在内部架构上的差异很细微,但函数调用提供的额外控制以及对外部基础设施的解耦依赖使得它成为开发者的一个有吸引力的选择。
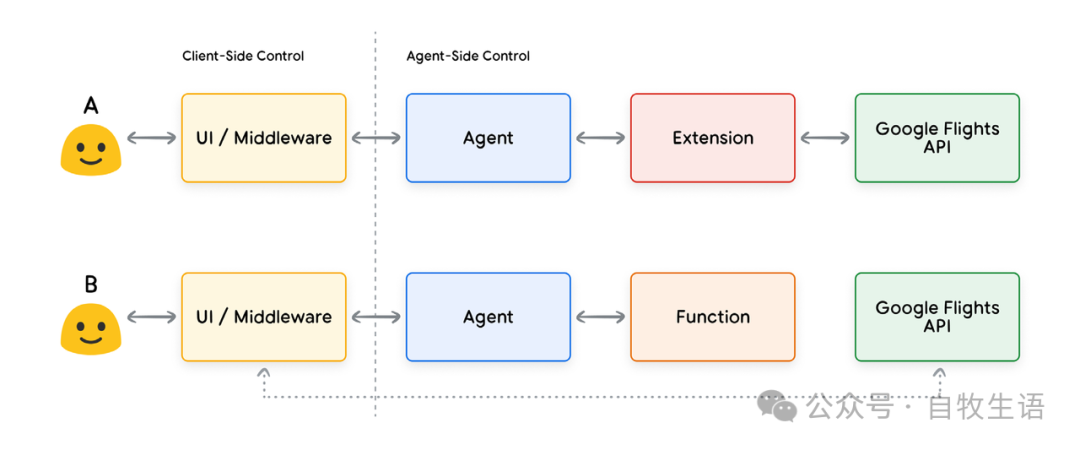
图8. 区分扩展和函数调用的客户端与代理端控制
2.2.1 使用案例
一个模型可以用来调用函数,以便处理终端用户在客户端执行的复杂流程,其中开发者可能不希望语言模型来管理 API 执行(如扩展的情况)。
让我们考虑以下示例,其中 Agent 正在被训练为旅行礼宾员,以与希望预订度假旅行的用户进行互动。目标是让 Agent 生成一个城市列表,我们可以在中间件应用程序中使用这些城市来为用户下载旅行计划所需的图像、数据等。用户可能会说:
我想和家人一起去滑雪旅行,但不确定去哪里。
在典型的模型提示中,输出可能如下所示:
当然,这里有一系列适合家庭滑雪旅行的城市供您考虑:
-
克雷斯特德比特,科罗拉多州,美国
-
惠斯勒,不列颠哥伦比亚省,加拿大
-
采尔马特,瑞士
虽然上述输出包含了我们需要的数据(城市名称),但格式并不理想,难以解析。通过函数调用,我们可以教导模型以结构化的风格(如 JSON)格式化输出,这样更便于另一个系统解析。给定用户相同的输入提示,函数可能输出的示例 JSON 如下所示。
function_call {name: "display_cities"args: {"cities": ["Crested Butte", "Whistler", "Zermatt"],"preferences": "skiing"}}
代码片段 5。显示城市列表和用户偏好的示例函数调用载荷
这个 JSON 载荷是由模型生成的,然后发送到我们的客户端服务器,以完成我们希望对其执行的任何操作。
在本例中,我们将调用 Google Places API,利用模型提供的城市信息查找相关图片,然后将它们作为格式化的富内容返回给用户。图 9 中的序列图展示了上述交互的详细步骤。
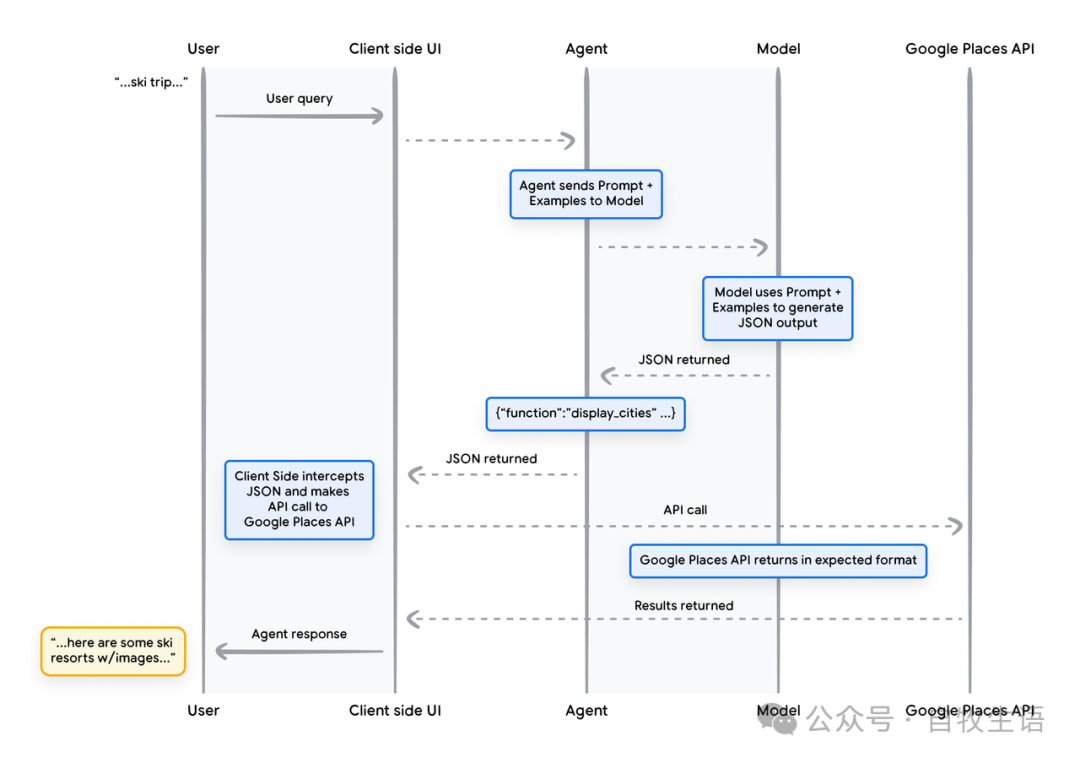
图9. 序列图展示了一个函数调用的生命周期
图 9 中示例的结果是,模型被用来“填补空白”,即提供客户端 UI 调用 Google Places API 所需的参数。客户端 UI 使用模型在返回的函数中提供的参数来管理实际的 API 调用。这只是函数调用的一个用例,但还有许多其他场景需要考虑,例如:
-
你希望语言模型建议一个可以在代码中使用的函数,但你不想在代码中包含凭据。因为函数调用不会运行该函数,所以你不需要在代码中包含凭据和函数信息。
-
您正在运行可能需要数秒以上的异步操作。由于函数调用是一种异步操作,这些场景非常适合使用函数调用。
-
您希望在一个不同于生成函数调用及其参数的系统上运行这些函数。
关于函数的一个重要概念是,它们旨在为开发者提供更多控制权,不仅针对 API 调用的执行,还包括整个应用程序中数据的流转。
在图 9 的示例中,开发者选择不将 API 信息返回给 Agent,因为该信息与 Agent 可能采取的未来行动无关。然而,根据应用程序的架构,返回外部 API 调用数据给 Agent 可能是有意义的,以便影响未来的推理、逻辑和行动选择。最终,选择适合特定应用的方案由应用程序开发者决定。
2.2.2 函数示例代码
要实现上述滑雪假期场景的输出,我们来构建每个组件,使其与我们的 gemini-1.5-flash-001 模型协同工作。首先,我们将定义 display_cities 函数作为一个简单的 Python 方法。
def display_cities(cities: list[str], preferences: Optional[str] = None):"""Provides a list of cities based on the user's search query and preferences.Args:preferences (str): The user's preferences for the search, like skiing,beach, restaurants, bbq, etc.cities (list[str]): The list of cities being recommended to the user.Returns:list[str]: The list of cities being recommended to the user."""return cities
代码片段 6:显示城市列表的 python 方法示例
接下来,我们将实例化模型,构建工具,然后将用户的查询和工具传递给模型。执行下面的代码将产生代码片段底部所示的输出结果。
from vertexai.generative_models import GenerativeModel, Tool, FunctionDeclarationmodel = GenerativeModel("gemini-1.5-flash-001")display_cities_function = FunctionDeclaration.from_func(display_cities)tool = Tool(function_declarations=[display_cities_function])message = "I’d like to take a ski trip with my family but I’m not sure whereto go."res = model.generate_content(message, tools=[tool])print(f"Function Name: {res.candidates[0].content.parts[0].function_call.name}")print(f"Function Args: {res.candidates[0].content.parts[0].function_call.args}")> Function Name: display_cities> Function Args: {'preferences': 'skiing', 'cities': ['Aspen', 'Vail','Park City']}
代码片段 7 构建工具,将用户查询发送到模型并允许函数调用执行
总结来说,函数提供了一个简明的框架,使应用程序开发者能够对数据流动和系统执行进行细粒度的控制,同时有效利用 Agent/模型生成关键输入。
开发者可以根据具体的应用架构需求,选择是通过返回外部数据将 Agent“纳入流程”,还是将其排除在外。
2.3 数据存储 Data stores
想象一下,将语言模型比作一个庞大的图书库,它包含了其训练数据。但不同于一个不断购入新书的图书馆,这个图书库是静态的,仅保存了最初训练时的知识。这带来了挑战,因为现实世界的知识在不断演变。
数据存储通过提供更多动态且最新的信息来解决这一局限性,确保模型的回答基于事实并保持相关性。
设想一个常见场景,开发者可能需要向模型提供少量额外数据,可能是以电子表格或 PDF 的形式。
图10. Agent如何与结构化和非结构化数据交互?
数据存储允许开发者以原始格式向 Agent 提供额外的数据,从而无需进行耗时的数据转换、模型重新训练或微调。
数据存储将传入的文档转换为一组向量数据库嵌入,Agent 可以使用这些嵌入来提取所需信息,以补充其下一个动作或对用户的响应。
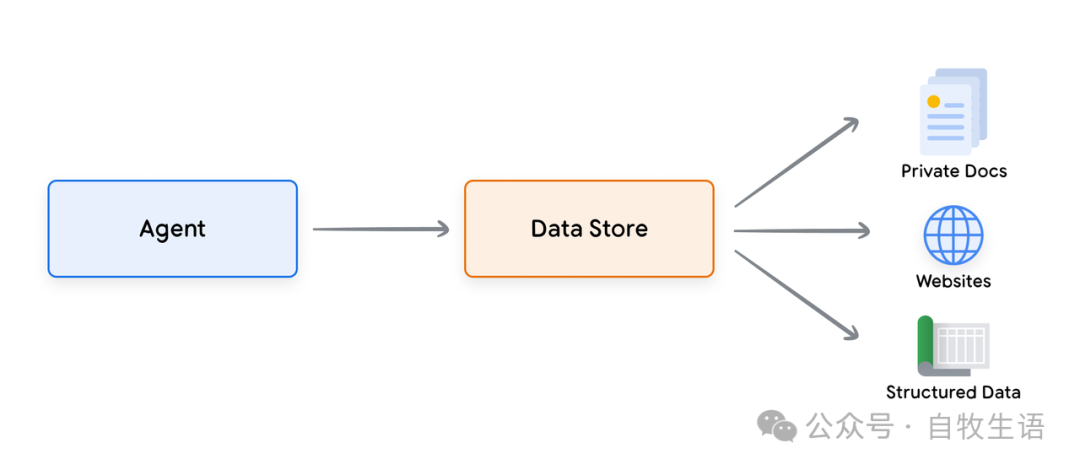
图11. 数据存储连接代理至各类新实时数据源。
2.3.1 实施与应用
在生成式 AI Agent 的背景下,数据存储通常被实现为一个矢量数据库,开发者希望 Agent 在运行时能够访问该数据库。
虽然我们不会在这里深入探讨矢量数据库,但关键点在于它们以矢量嵌入的形式存储数据,这是一种高维矢量或数据的数学表示。
近期与语言模型相关的数据存储最丰富的应用实例之一是基于检索增强生成(RAG)的应用程序的实现。这些应用程序旨在通过赋予模型访问各种格式数据的能力,来扩展模型的知识广度和深度,超越其基础训练数据,这些数据格式包括:
-
网页内容
-
结构化数据,如 PDF、Word 文档、CSV、电子表格等
-
非结构化数据,如 HTML、PDF、TXT 等
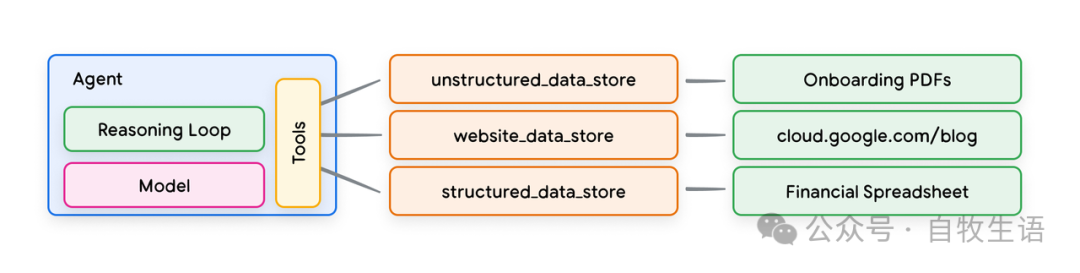
图12. 代理与数据存储之间的一对多关系,可以表示各种类型的预索引数据
每个用户请求与代理应答循环的基本流程一般如图 13 所示。
-
用户查询被发送到嵌入模型生成查询嵌入
-
查询嵌入通过类似 SCaNN 的匹配算法与向量数据库内容匹配
-
匹配的文本内容从向量数据库中以文本格式检索并返回代理
-
代理收到用户查询及检索内容,制定相应回应或行动
-
向用户发送最终响应
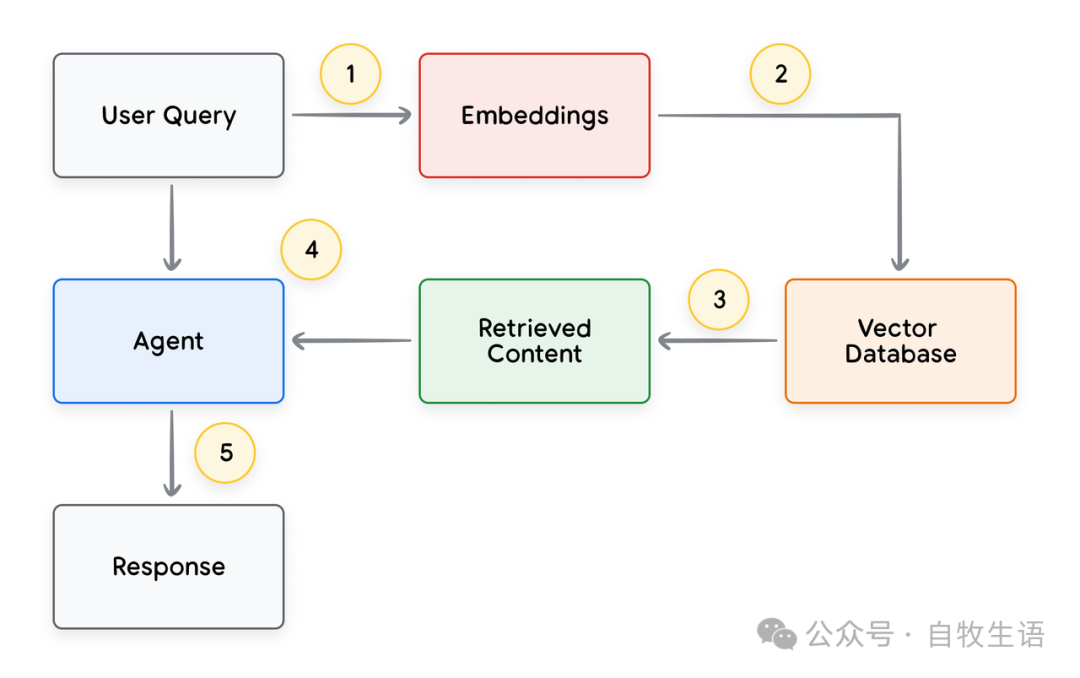
图13. RAG 应用中用户请求及代理响应的生命周期
最终结果是一个应用程序,允许 Agent 通过向量搜索将用户查询匹配到已知数据存储,检索原始内容,并将其提供给编排层和模型以进行进一步处理。
下一步可能是向用户提供最终答案,或执行额外的向量搜索以进一步细化结果。图 14 展示了一个实现 RAG 与 ReAct 推理/规划的 Agent 的示例交互。
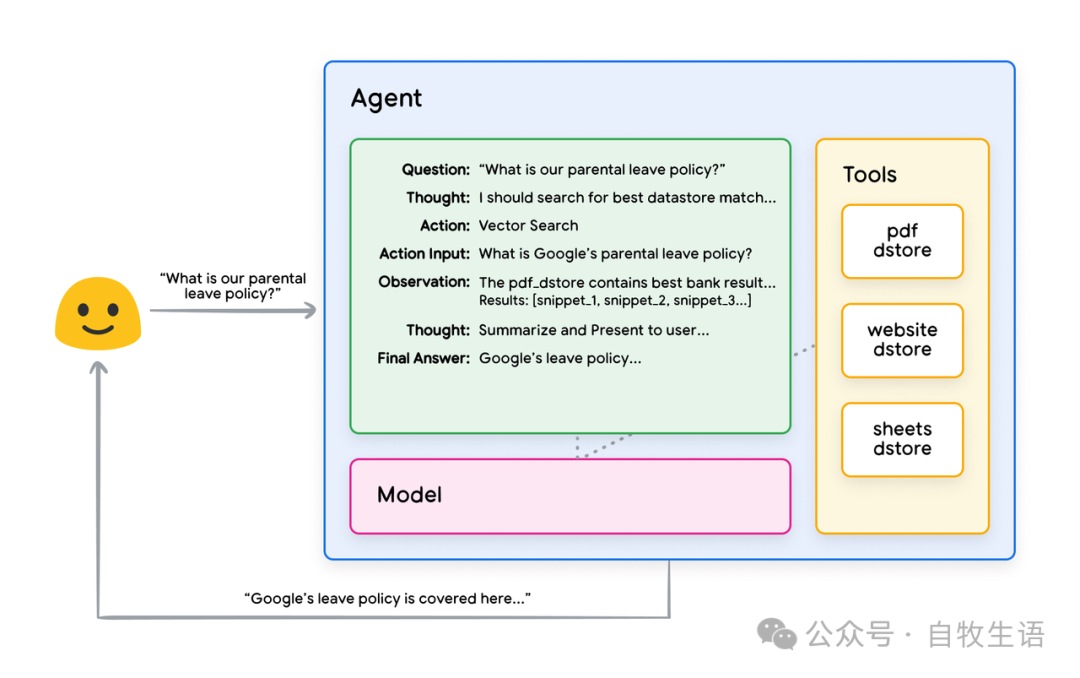
图14. 基于RAG的ReAct推理/规划示例应用
2.4 工具回顾
总结来说,插件、函数和数据存储构成了可供智能体在运行时使用的几种不同工具类型。每种工具都有其各自的用途,且可由智能体开发者灵活选择单独使用或组合使用。

相关文章
