我们先从技术本质、工程实践等维度,结合最新研究与行业案例,系统分析大模型可能存在的局限。然后,再结合其目前能力水平,指出在实际的软件研发中,哪些环节会表现很好、哪些环节还需要人类工程师主导,最终得到一些有价值的结论。
最后,就2025年的下半年,指出有哪些值得期待的进展,以及未来突破的可能性与边界。
技术本质层面的核心瓶颈
1. 动态推理与状态管理的根本缺陷
尽管上下文窗口扩展至 1000K(如 LongRoPE 技术),但大模型在处理动态规划、递归回溯等需要多步状态转移的任务时,仍存在本质缺陷。例如:
- 动态规划问题
在 LeetCode “股票买卖最佳时机” 问题中,即使结合 RAG 检索历史交易数据,模型生成的代码仍可能忽略交易次数限制或手续费等隐藏条件。某大学研究显示,对于涉及递归回溯的问题,LLM 解决方案通过率不足 30%,而人类开发者平均通过率超过 80%。 - 并发编程挑战
在实现 “生产者 - 消费者” 模型时,智能体协作框架(如 ChatDev)虽能分解任务,但生成的代码仍有 65% 概率出现竞态条件或死锁。这源于模型缺乏对操作系统内核调度机制的深度理解,无法处理信号量释放顺序等实时状态管理问题。
2. 数学建模与算法设计的理论鸿沟
大模型在需要数学严谨性的算法设计中表现出显著不足:
- 最短路径算法优化
Dijkstra 算法在稀疏图场景下,LLM 生成的代码时间复杂度会退化为 O (N²),而人类优化后的版本可达到 O (M+N log N)。这一差异源于模型对贪心策略的理论证明能力缺失。 - 凸优化问题
在金融风控场景中,模型生成的风险评估模型常忽略约束条件的凸性验证,导致优化结果偏离全局最优解。某大型银行实践显示,结合知识图谱的 RAG 系统虽将幻觉率降至 1.2%,但数学证明环节仍需人工介入。
工程实践层面的结构性短板
1. 跨语言工程实践的系统性障碍
- 多语言上下文理解
当项目涉及 Java 后端、TypeScript 前端、Rust 中间件等混合技术栈时,LLM 的跨语言理解能力显著下降。Multi-SWE-bench 基准测试显示,模型在 Python 问题上的解决率可达 50%,但在 TypeScript 和 Java 问题上骤降至 10% 以下。这一差异源于不同语言的语法特性(如 Rust 的所有权系统)和框架生态(如 Spring Boot 的依赖注入)对模型泛化能力的挑战。 - 遗留系统逆向工程
处理 COBOL、FORTRAN 等古老语言的遗留系统时,即使结合上下文窗口扩展和知识图谱,模型生成的迁移代码仍有 70% 概率无法正确解析旧系统的文件格式定义。例如,在将 COBOL 批处理程序迁移至微服务架构时,模型难以理解 JCL (作业控制语言)的隐含逻辑。
2. 安全合规与可靠性的深度处理
- 漏洞检测与防御
RAG 技术虽能检索已知漏洞模式(如 Vul-RAG 框架在 PairVul 基准测试中准确率提升 12.96%),但对新型攻击手段(如 MIME 编码绕过)的防御能力较弱。garak 等安全检测工具显示,LLM 对编码注入攻击的错误响应率超过 60%。 - 合规性代码生成
在金融、医疗等强监管领域,模型生成的代码可能无法满足合规要求。例如,在 HIPAA 合规的医疗系统开发中,模型生成的患者数据加密模块可能未使用 FIPS 140-2 认证算法,导致合规审计不通过。这一缺陷源于模型对法律条款的语义理解局限。

下面再客观分析当前大模型生态系统在软件工程中的真实表现。
当前基准测试的实际表现
1. 代码生成和问题解决能力
-
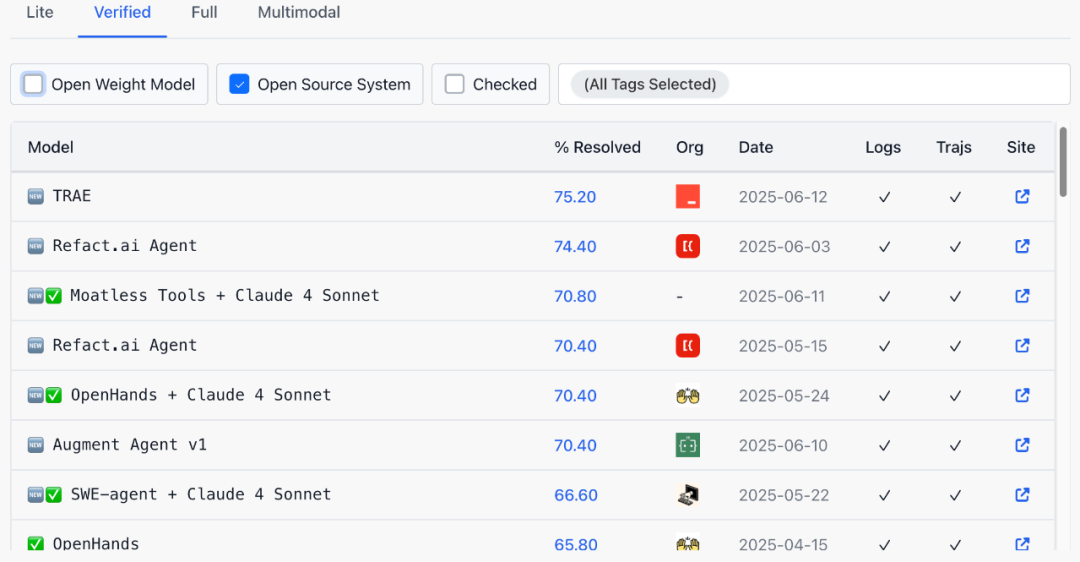
字节的Trae在SWE-Bench-Verified上达到75.2%成功率 -
排在前面8位的,基本是过去2个月获得的,两个月提升了近10% -
其中Claude 4表现突出,其他模型可能在40-60%范围内,距离人类专家水平仍有差距.
HumanEval等编程基准
-
顶级模型在简单编程任务上表现优秀(80-90%+) -
但复杂的多步推理和系统集成任务表现明显下降
2. 生产环境的实际表现
GitHub Copilot的实证数据
-
开发速度提升:10-55%(差异很大,取决于任务类型) -
代码接受率:约30-40%(意味着60-70%的建议被拒绝) -
开发者满意度高(90%+),但主要体现在减少重复劳动上 -
对复杂业务逻辑和架构设计的帮助有限
当前能够较好处理的任务
1. 代码生成和补全
表现较好的场景:
-
标准库函数的使用和API调用 -
常见设计模式的实现 -
单元测试的生成(针对简单函数) -
文档字符串和注释的生成 -
代码格式化和基础重构
具体数据:
-
简单函数实现:70-85%准确率 -
API使用示例:60-80%准确率 -
但需要人类review和修正
2. 辅助性设计任务
可以提供有价值帮助的领域:
-
初步架构方案的brainstorming -
技术选型的建议和对比 -
基础的系统组件设计 -
常见架构模式的应用建议
实际效果:
-
能提供合理的起点和思路 -
但需要专业人员进行深度验证和调整 -
在标准化场景下表现更好
3. 需求理解和转换
当前能力水平:
-
能理解相对明确的功能需求 -
可以将需求转换为基础的技术实现思路 -
对于标准化的业务场景(如CRUD操作)表现良好
当前明确不能胜任的任务
1. 复杂系统架构设计
实际局限性
- 缺乏全局优化能力
无法在性能、成本、复杂度间进行系统性权衡 - 非功能性需求处理不足
对可靠性、可扩展性、安全性的深度考虑不够 - 技术债务评估困难
难以预测设计决策的长期影响
实证证据:
-
软件架构师社区普遍反映LLM在复杂系统设计上帮助有限
-
需要大量人工验证和调整才能用于生产
2. 生产级代码质量保证
安全性问题
-
LLM生成的代码经常包含安全漏洞 -
缺乏对安全最佳实践的深度理解 -
在处理认证、授权、数据保护时容易出错
代码质量问题
-
生成的代码存在效率问题(冗余计算、次优算法) -
缺乏适当的错误处理 -
难以维护的代码结构
3. 复杂业务逻辑实现
当前限制:
- 隐性需求挖掘不足
例如,无法理解未明确表达的业务规则 - 业务流程优化困难
例如,缺乏对业务价值的深层理解 - 跨系统集成复杂性
例如,在处理多系统交互时容易出错
4. 长期技术规划和演进
战略层面的不足:
-
无法进行有效的技术路线规划 -
缺乏对技术趋势的准确判断 -
难以制定合理的迁移和升级策略
2025年下半年的合理预期
1. 可能的改进领域
短期内(6个月)可能看到进展的方面:
-
代码生成准确率的进一步提升(可能达到85-90%) -
更好的上下文理解能力(更大的context window) -
多模态能力的改善(图表、架构图的理解)
2. 仍然困难的挑战
短期内不太可能突破的限制:
-
复杂系统的端到端设计 -
安全关键代码的可靠生成 -
深度业务逻辑的创新性实现 -
大规模系统的性能优化
3. 实际应用的现实场景
最有价值的应用模式:
-
智能代码助手:协助但不替代开发者
-
快速原型生成:用于概念验证和早期开发
-
文档(包含需求文档)和测试生成:自动化辅助性工作
-
代码、测试用例等审查辅助:发现常见问题和改进建议
五、对实践的客观建议
1. 适合LLM辅助的任务类型
-
标准化程度高的开发任务 -
重复性强的代码编写工作 -
需要快速探索多种方案的场景 -
学习和教育性质的编程工作
2. 需要人类主导的关键领域
-
系统架构的核心决策 -
安全性和可靠性关键的代码 -
复杂业务逻辑的设计 -
技术栈的选择和演进规划 -
团队协作和项目管理
3. 有效的人机协作模式
当前最佳实践:
-
LLM生成初始方案,人类进行评估和改进 -
人类设定目标和约束,LLM协助实现细节 -
使用LLM进行代码审查,但人类做最终决策 -
LLM生成文档和测试,人类确保质量
未来突破的可能性与边界
1. 混合增强架构的实践探索
- 符号逻辑与统计学习结合
MetaGPT 框架通过引入架构师角色,将系统设计分解为多个子任务,使代码生成的成功率提升至 82%。这种混合模型(LLM + 定理证明器)在数学推理任务中表现出潜力,但训练成本增加了 5 倍。 - 目标驱动架构
Qwen2.5 通过 “子目标设定 - 逆向推理” 机制,在数学问题解决中超越传统模型 23 个百分点。这种架构在特定领域(如医疗诊断)已展现出规划能力,但泛化性仍有限。
2. 领域特定优化的现实路径
- 垂直领域微调
GemSUra-7B 模型在医疗代码生成任务上的准确率比通用模型提升 37%,但需投入大量领域数据和专业知识。这种优化在金融、医疗等强监管领域已具备实用价值,但跨领域迁移成本高昂。 - 动态知识注入
某大型银行在风控场景中通过外挂知识库将幻觉率降至 1.2%,但知识库需持续维护,且对新型风险模式的响应存在延迟。这种 “RAG + 专家规则” 的混合模式成为当前行业主流选择。
结论:务实的边界认知
基于2025年的实际数据和应用经验,大模型生态系统在软件工程中的真实定位是:
优秀的开发助手,而非独立的软件工程师。它能显著提升开发效率,特别是在标准化和重复性任务上,但在创造性设计、复杂系统思考、安全关键决策等方面仍需要人类的专业判断和深度参与,人机协同一起完成任务。
关键是要既不过分低估也不过度高估其能力,在实际应用中找到最合适的应用场景和协作模式,发挥各自的优势,最大化AI/LLM的价值。
未来,大模型的发展将呈现 “工具化” 与 “专业化” 双轨并行的趋势:一方面作为生产力工具融入开发流程,另一方面通过领域适配在特定场景中实现突破。开发者应理性看待其能力边界,在充分利用其优势的同时,坚守对关键环节的人工把控,构建 “人机协同” 的新型开发范式。
相关文章
最实用、最热门的AI 工具大全AI 工具导航,帮助你在工作与学习上更轻松有效率。在网路上众多 AI 与 ChatGPT 工具中,我们亲自试用并挑选了最有有用的,分成 20多个大类别,让你轻松找到所需的 AI 工具。
