Hi,大家好,我叫秋水,当前专注于 AI Agent(智能体)。
相信做过AI Agent开发的朋友都遇到过这些痛点:
-
• 为什么我的智能体在执行长任务时会突然"失忆",前面的重要信息都忘记了? -
• 为什么给智能体提供了大量工具,它反而变得更加混乱,选择错误的工具? -
• 为什么智能体的响应越来越慢,成本越来越高,但效果却在下降? -
• 为什么智能体会产生幻觉,把错误信息当作事实来使用? -
• 为什么多个智能体协作时,信息传递会出现混乱和冲突?
这些问题的根源都指向同一个核心挑战:Context Engineering(上下文工程)。
什么是Context Engineering(上下文工程)?
要理解Context Engineering,我们先来看一个很形象的比喻。
OpenAI的前研究科学家Andrej Karpathy说过:LLM(大语言模型)就像一种新的操作系统,LLM是CPU,而它的上下文窗口就是RAM。
这个比喻非常精准。我们都知道,电脑的RAM容量有限,操作系统需要管理哪些数据放在内存里,哪些数据暂时存储到硬盘。同样,LLM的上下文窗口容量也有限(即使是最新的模型也只有几百万Token(令牌)),需要管理放入什么信息。
Context Engineering(上下文工程)就是这样一门艺术和科学:在智能体执行任务的每一个步骤中,都要精确地选择合适的信息放入上下文窗口。
为什么Context Engineering(上下文工程)如此重要?
在传统的LLM应用中,我们通常只需要处理一轮对话,上下文管理相对简单。但AI Agent不同,它们需要:
-
1. 长期运行:可能需要执行几十个甚至上百个步骤 -
2. 工具调用:频繁使用各种工具,每次调用都会产生反馈信息 -
3. 状态维护:需要记住执行过程中的重要信息
这就导致了一个严重问题:上下文信息会快速积累,很快就会超出模型的处理能力。
上下文过载会带来什么问题?
LangChain的技术专家Drew Breunig总结了四种典型的上下文问题:
1. Context Poisoning(上下文污染)
当智能体产生幻觉时,这些错误信息会被保存在上下文中,影响后续的判断。就像一个人记住了错误的事实,后面的决策都会受到影响。
2. Context Distraction(上下文干扰)
当上下文信息过多时,智能体会被大量无关信息干扰,无法专注于当前任务。就像你在一个嘈杂的环境中很难集中注意力工作。
3. Context Confusion(上下文混乱)
过多的冗余信息会让智能体产生混乱,影响响应的准确性。比如同一个概念在不同地方用不同方式表达,智能体可能会理解错误。
4. Context Clash(上下文冲突)
当上下文中的不同部分包含矛盾信息时,智能体不知道该相信哪个,导致决策混乱。
Context Engineering(上下文工程)的四大核心策略
目前主流AI Agent产品和学术研究,Context Engineering主要有四大策略:Write(写入)、Select(选择)、Compress(压缩)、Isolate(隔离)。
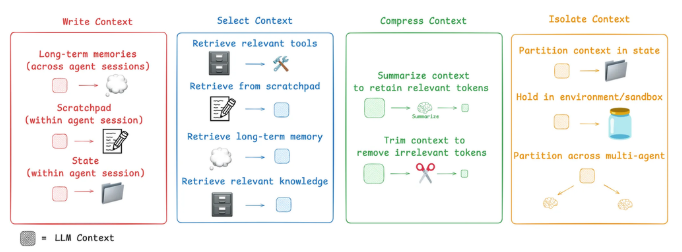
1. Write Context(写入上下文)
核心思想:把重要信息保存在上下文窗口之外,需要时再调用。
Scratchpads(暂存区)
这就像人类做复杂任务时会记笔记一样。智能体也需要一个"暂存区"来记录重要信息。
实际应用场景:
-
• 电商客服智能体在处理复杂售后问题时,需要记录客户的历史订单信息、投诉记录等 -
• 营销智能体在制定推广策略时,需要记录市场调研结果、竞品分析等
Anthropic的多智能体研究系统就是典型例子。当主研究员智能体开始工作时,它会先制定计划并保存到Memory中。因为如果上下文超过20万Token就会被截断,保存计划能确保重要信息不丢失。
Memories(记忆)
暂存区解决的是单次会话中的信息保存,但智能体还需要跨会话的长期记忆。
三种记忆类型:
-
• Procedural memories(程序记忆):记录如何执行任务的步骤和方法 -
• Episodic memories(情节记忆):记录具体的执行案例和经验 -
• Semantic memories(语义记忆):记录事实和知识
这个功能现在在ChatGPT、Cursor、Windsurf等产品中都能看到。它们会根据用户的使用习惯自动生成长期记忆。
2. Select Context(选择上下文)
核心思想:从大量可用信息中精准选择当前任务需要的信息。
这是最具挑战性的一个环节。信息选择不当会直接影响智能体的表现。
工具选择
当智能体拥有大量工具时,如何选择合适的工具是个大问题。最新研究表明,使用RAG(检索增强生成)来选择工具描述,可以将工具选择准确率提升3倍。
知识选择
代码智能体是这方面最好的例子。Windsurf的技术负责人Varun分享了他们的经验:
"代码索引不等于上下文检索...我们使用AST(抽象语法树)解析代码,按照语义边界进行分块...但随着代码库规模增长,嵌入搜索变得不可靠...我们必须结合grep/文件搜索、知识图谱检索,还有重新排序步骤。"
这说明了一个重要问题:技术选择需要根据具体场景来优化,没有万能的解决方案。
3. Compress Context(压缩上下文)
核心思想:只保留执行任务所需的最少Token数量。
Context Summarization(上下文总结)
Claude Code是这方面的典型应用。当你的对话超过95%的上下文窗口时,它会自动运行"压缩"功能,总结整个用户-智能体交互历史。
总结可以应用在多个地方:
-
• 递归或分层总结:把长对话分层总结 -
• 工具调用后处理:总结工具返回的冗长信息 -
• 智能体边界:在多个智能体交接时总结关键信息
Context Trimming(上下文修剪)
相比总结需要用LLM来提炼信息,修剪可以用更简单的规则。比如:
-
• 移除较旧的消息 -
• 过滤掉不相关的信息 -
• 使用经验规则清理冗余内容
4. Isolate Context(隔离上下文)
核心思想:将上下文分割到不同的区域来帮助智能体完成任务。
Multi-agent(多智能体架构)
OpenAI的Swarm库就是基于这个思想设计的。通过将复杂任务分解给多个专门的智能体,每个智能体都有自己的工具集、指令和上下文窗口。
Anthropic的多智能体研究系统证明了这种方法的有效性:多个具有隔离上下文的智能体表现优于单一智能体,主要因为每个子智能体的上下文窗口可以专注于更窄的子任务。
当然,多智能体也有挑战:
-
• Token使用量大(Anthropic报告称比单智能体多15倍) -
• 需要精心设计提示词来规划子智能体工作 -
• 智能体间的协调复杂
环境隔离
HuggingFace的深度研究智能体展示了另一种隔离方式。它使用CodeAgent输出代码,然后在Sandbox(沙盒环境)中运行。只有选定的上下文(如返回值)才会传回LLM。
这种方法特别适合处理高Token消耗对象,比如图像、音频等大型数据。
实际应用建议
基于以上分析,我给大家几个实际的应用建议:
1. 建立监控机制
在开始优化之前,你需要能够观察到问题。建议:
-
• 追踪Token使用情况 -
• 监控响应时间和成本 -
• 记录智能体的决策过程
2. 逐步优化
不要试图一次性解决所有问题,建议按以下优先级:
-
1. 先解决最耗费Token的部分 -
2. 然后优化关键信息的选择 -
3. 最后考虑复杂的架构调整
3. 场景化设计
不同场景需要不同策略:
-
• 客服智能体:重点关注会话历史的总结和客户信息的持久化 -
• 营销智能体:重点关注市场数据的选择和策略记忆 -
• 代码智能体:重点关注代码上下文的检索和工具选择
4. 以测试为导向的优化
每一个优化都应该通过测试来验证效果,避免过度优化。
今天的文章就到这里结束了,如果你觉得不错,随手点个赞、在看、转发三连吧。
如果想第一时间收到推送,也可以给我个星标⭐。
谢谢你看我的文章,我们,下次再见。

相关视频:
相关文章
