
点击蓝字 关注我们
AI Agent系统中的记忆系统如何开发?一文搞懂大模型的上下文机制
最近主导了一款ai agent系统的开发,在定架构的时候选择了MCP协议,在期间遇到不少坑点,记录顺分享一下相关内容。此篇是系列的第五篇:介绍AI agent系统中的记忆系统。
大模型的记忆能力从何而来?大模型本身是不具备记忆能力的,在跟大模型聊天的过程中,它能记住你之前说过的一些话,是因为对话中携带了上下文信息。在一个系统应用中,除了上下文是不够的,需要一个完善的记忆系统。
记忆系统是什么?
记忆系统是指通过特定机制存储、管理和检索信息,以增强模型在长期交互或复杂任务中的上下文连贯性、个性化响应及知识持久化的技术框架。其核心目标是解决大模型因固定上下文窗口限制导致的“失忆”问题,并模拟人类记忆的分层与动态更新特性。
记忆的分层架构
记忆系统通常借鉴人类记忆的三层结构,分为短期、中期和长期记忆:
-
• 短期记忆(STM):存储当前对话或任务的即时信息,受限于模型的上下文窗口长度(如GPT-4的2048 tokens)。实现技术:将对话历史直接嵌入提示词中,但容量有限。 -
• 中期记忆(MTM):整合短期记忆中的主题信息,通过分段分页策略组织(如MemoryOS将同一主题的对话归并为“段”),并基于热度算法(访问频率、时间衰减等)动态更新。 -
• 长期记忆(LPM):持久化存储用户偏好、角色特征等个性化数据。例如,MemoryOS的LPM模块包含用户画像和智能体特征,通过向量数据库或知识图谱实现长期存储,然后通过RAG手段来进行提取。
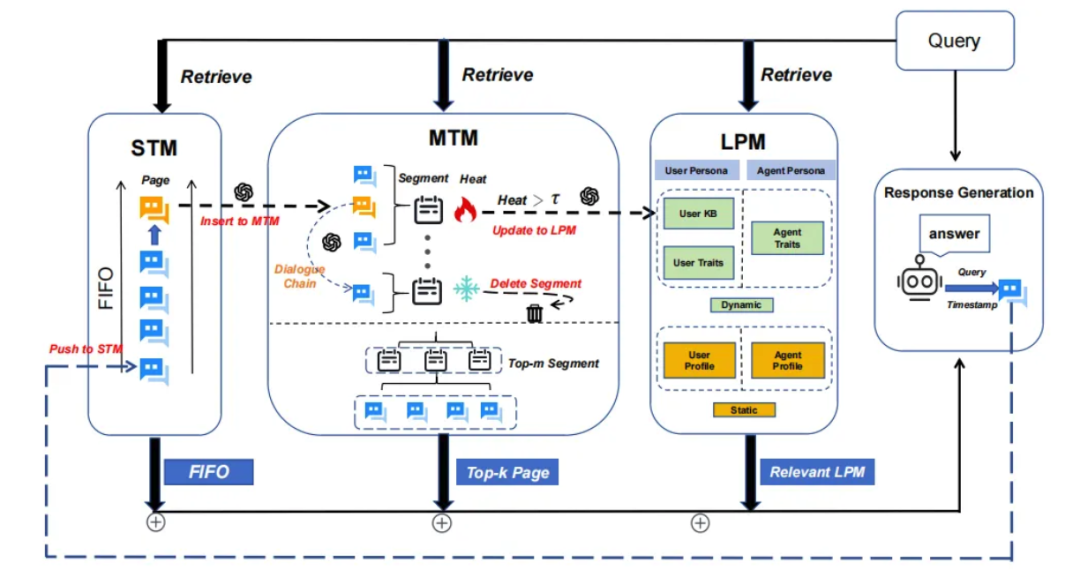
为什么需要记忆系统?
-
• 大模型本身不存在记忆能力——如果开发agent应用,需要外挂记忆系统进行信息的记忆 -
• 大模型本身的上下文阈值是有限的,没有办法直接给它所有的对话或者文本内容,超出后早期对话内容会被丢弃,导致多轮对话中出现“断片”或重复提问。记忆系统通过分层存储(短期/长期记忆)和动态检索(如向量数据库),将历史信息压缩后注入当前上下文,确保对话连贯性。
开发agent系统中,上下文内容该怎么做管理?
我们可以以一个最简对话系统为例,结合短期、中期、长期记忆进行分层处理:
-
• 短期记忆:聚焦当前对话的最近信息,直接将最新消息体输入模型。这类似大脑对当下信息的清晰即时记录,确保模型能响应最新对话内容。 -
• 中期记忆:由于模型存在阈值容量限制,需对当前对话中的关键信息进行摘要处理。这如同大脑在记忆容量有限时,自动将知识压缩为核心要点(非逐字记忆,而是保留关键内容),让模型抓住对话的核心逻辑。 -
• 长期记忆:通过RAG(检索增强生成)等技术,在用户提问时调用外部知识库,提取已沉淀的长期记忆内容。这一机制类比大脑调用过往经验与知识储备,为对话提供更丰富的背景信息支撑。
实际开发中可能遇到的问题
1)messages消息体如何组织?
message数组样例如下,具体role有 system、user、tool、assistant。
-
• system:对话的全局导演,设定模型的行为框架和初始规则。交互框架的 “设计者” 与 “规则制定者”。 -
• user:交互的 “需求发起者” 与 “信息输入方”。 -
• tool:交互中的 “功能执行者” 与 “数据提供者”。 -
• assistant:交互的 “问题解决者” 与 “内容整合者”。
messages = [
{
"role": "system",
"content": """你是一个很有帮助的助手。如果用户提问关于天气的问题,请调用 ‘get_current_weather’ 函数;
如果用户提问关于时间的问题,请调用‘get_current_time’函数。
请以友好的语气回答问题。""",
},
{
"role": "user",
"content": "深圳天气"
}
]
print("messages 数组创建完成n")2)上述messages超过模型阈值了怎么办?
由于大模型的阈值始终有限,上述的消息体在一定的对话回复轮次之后会超出大模型的上下文窗口限制。最简单的做法直接如基于时间衰减(近期对话优先保留)或重要性排序(关键信息优先),避免记忆冗余。
| 方法名称 | 核心思路 | 实现步骤 | 优点 | 缺点 |
| 简单截断法 |
|
|
|
|
| 优先级保留法 |
|
|
|
|
| 摘要压缩法 |
|
|
|
|
| 滑动窗口法 |
|
|
|
|
| 动态分段法 |
|
|
|
|
| 混合策略法 |
|
|
|
|
3)可能需要调度历史的其他对话消息或者其他信息怎么办?
可以将这些可能需要的信息汇总成一个知识库,然后在实际用户提问的时候,通过RAG的技术来做检索内容→增强内容→生成最后的答案。
— 分享完 —

世界很大,吾来看看。努力活出自己的姿态~
相关文章
最实用、最热门的AI 工具大全AI 工具导航,帮助你在工作与学习上更轻松有效率。在网路上众多 AI 与 ChatGPT 工具中,我们亲自试用并挑选了最有有用的,分成 20多个大类别,让你轻松找到所需的 AI 工具。
