随着AI智能体技术的快速发展,如何高效构建和管理多Agent系统成为开发者关注的焦点。本文将深入解析8种当前最受欢迎的LLM Agents开发框架,并详细演示如何为每种框架集成MCP Server,让你的智能体拥有强大的外部工具调用能力,本文上一篇文章的实操篇企业新基建:MCP + LLM + Agent架构,将打通AI Agent的“神经中枢”。
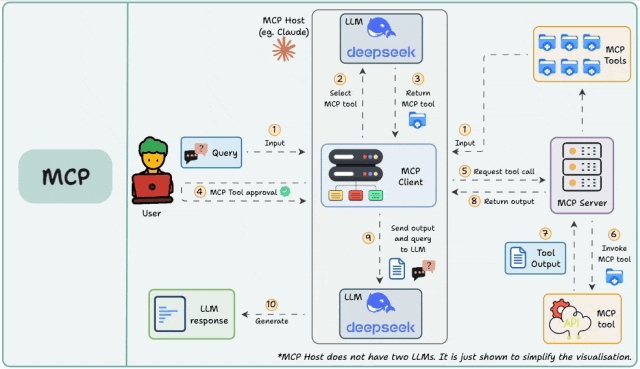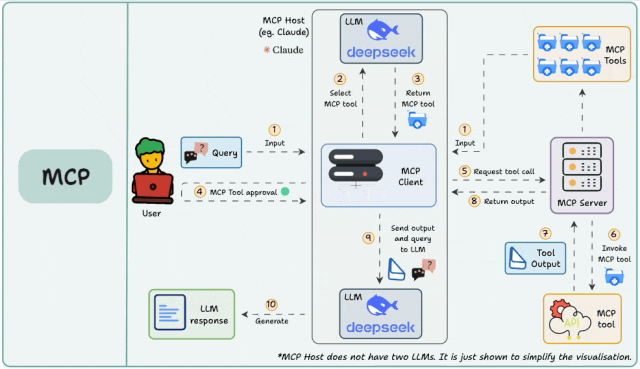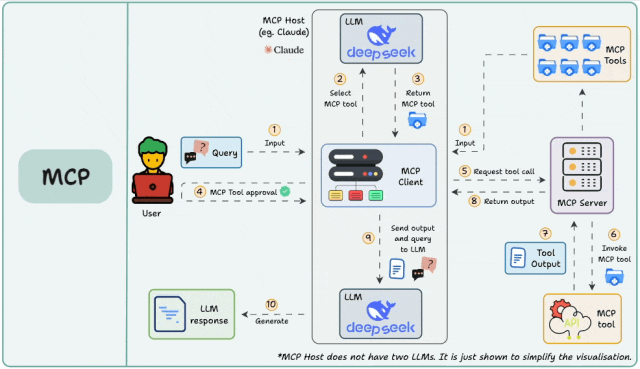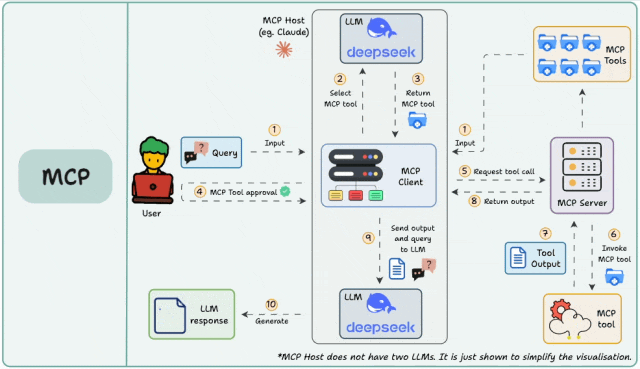
一、什么是MCP Server?
MCP(Model Context Protocol)Server是一个标准化的工具接口协议,它允许AI Agent通过统一的方式调用各种外部工具和服务。无论是搜索引擎、数据库查询,还是API调用,MCP Server都能提供标准化的接入方式。
MCP Server支持两种主要连接模式:
-
Stdio模式:通过命令行进程通信,适合本地开发
-
SSE模式:通过HTTP连接,适合生产环境部署
二、OpenAI Agents SDK - 轻量级多Agent协作
OpenAI Agents SDK是官方推出的轻量级框架,特别适合构建多Agent协作系统。
快速开始
# 安装依赖pip install openai-agents-sdk mcp-client-python# 基础Agent设置from openai_agents import Agent, create_agentfrom mcp_client import MCPClientimport asyncioasync def setup_openai_agent_with_mcp():# 创建MCP客户端mcp_client = MCPClient()# 连接Tavily搜索工具await mcp_client.connect_stdio(command="npx",args=["@tavily/mcp-server"])# 获取工具列表tools = await mcp_client.get_tools()# 创建Agentagent = create_agent(name="搜索助手",instructions="你是一个专业的搜索助手,能够帮助用户获取最新信息",tools=tools,model="gpt-4")return agent, mcp_client# 运行Agentasync def main():agent, mcp_client = await setup_openai_agent_with_mcp()# 与Agent对话response = await agent.run("帮我搜索一下2025年AI领域的重要进展")print(response.content)# 清理连接await mcp_client.disconnect()# 执行if __name__ == "__main__":asyncio.run(main())
多Agent协作示例
async def create_agent_team():# 创建MCP客户端mcp_client = MCPClient()await mcp_client.connect_stdio(command="npx",args=["@tavily/mcp-server"])tools = await mcp_client.get_tools()# 创建研究员Agentresearcher = create_agent(name="研究员",instructions="负责信息搜集和分析",tools=tools,model="gpt-4")# 创建写手Agentwriter = create_agent(name="写手",instructions="负责将研究结果整理成文章",model="gpt-4")# 创建协作工作流from openai_agents import Handoffs# 配置Agent间的任务转交handoffs = Handoffs()handoffs.add_handoff(from_agent=researcher,to_agent=writer,condition="完成信息收集后转交给写手")return researcher, writer, handoffs# 运行协作任务async def run_team_task():researcher, writer, handoffs = await create_agent_team()# 启动协作任务result = await researcher.run("研究量子计算的最新突破,并整理成一篇科普文章",handoffs=handoffs)print(result.content)
三、LangGraph - 有状态图工作流
LangGraph是基于图结构的工作流框架,特别适合复杂的多步骤任务。
安装和基础设置
pip install langgraph langchain-openai mcp-client-pythonfrom langgraph.prebuilt import create_react_agentfrom langchain_openai import ChatOpenAIfrom mcp_client import MCPClient, load_mcp_toolsimport asyncioasync def create_langgraph_agent():# 方法1:使用load_mcp_toolstools = await load_mcp_tools(server_config={"command": "npx","args": ["@tavily/mcp-server"]})# 初始化LLMllm = ChatOpenAI(model="gpt-4")# 创建ReactAgentagent = create_react_agent(llm=llm,tools=tools,state_modifier="你是一个专业的AI助手,能够使用各种工具帮助用户解决问题")return agent# 运行Agentasync def run_langgraph_agent():agent = await create_langgraph_agent()# 执行任务config = {"configurable": {"thread_id": "1"}}result = await agent.ainvoke({"messages": [("user", "帮我搜索并总结Python 3.12的新特性")]},config=config)print(result["messages"][-1].content)# 多Server集成示例async def create_multi_server_agent():from langgraph.mcp import MultiServerMCPClient# 创建多Server客户端mcp_client = MultiServerMCPClient()# 添加搜索工具await mcp_client.add_server("search",command="npx",args=["@tavily/mcp-server"])# 添加数据库工具(示例)await mcp_client.add_server("database",command="npx",args=["@example/database-mcp-server"])# 获取所有工具all_tools = await mcp_client.get_all_tools()llm = ChatOpenAI(model="gpt-4")agent = create_react_agent(llm=llm, tools=all_tools)return agent, mcp_clientif __name__ == "__main__":asyncio.run(run_langgraph_agent())
复杂工作流示例
from langgraph.graph import StateGraph, START, ENDfrom typing import TypedDictimport jsonclass AgentState(TypedDict):messages: listresearch_data: dictfinal_report: strasync def create_research_workflow():# 创建MCP工具tools = await load_mcp_tools(server_config={"command": "npx","args": ["@tavily/mcp-server"]})llm = ChatOpenAI(model="gpt-4")# 定义工作流节点async def research_node(state: AgentState):"""研究节点"""messages = state["messages"]last_message = messages[-1]research_agent = create_react_agent(llm=llm,tools=tools,state_modifier="你是一个专业的研究员,负责收集和分析信息")result = await research_agent.ainvoke({"messages": [("user", f"深入研究:{last_message}")]},config={"configurable": {"thread_id": "research"}})return {"messages": messages + [result["messages"][-1]],"research_data": {"raw_data": result["messages"][-1].content}}async def analysis_node(state: AgentState):"""分析节点"""research_data = state["research_data"]analysis_prompt = f"""基于以下研究数据,进行深入分析:{research_data['raw_data']}请提供:1. 关键发现2. 趋势分析3. 潜在影响"""analysis_agent = create_react_agent(llm=llm,tools=[], # 分析阶段不需要外部工具state_modifier="你是一个专业的数据分析师")result = await analysis_agent.ainvoke({"messages": [("user", analysis_prompt)]},config={"configurable": {"thread_id": "analysis"}})return {"messages": state["messages"] + [result["messages"][-1]],"research_data": {**research_data,"analysis": result["messages"][-1].content}}async def report_node(state: AgentState):"""报告生成节点"""research_data = state["research_data"]report_prompt = f"""基于研究和分析结果,生成最终报告:原始研究:{research_data['raw_data']}分析结果:{research_data['analysis']}请生成一份结构化的专业报告。"""report_agent = create_react_agent(llm=llm,tools=[],state_modifier="你是一个专业的报告撰写专家")result = await report_agent.ainvoke({"messages": [("user", report_prompt)]},config={"configurable": {"thread_id": "report"}})return {"messages": state["messages"] + [result["messages"][-1]],"research_data": research_data,"final_report": result["messages"][-1].content}# 构建工作流图workflow = StateGraph(AgentState)# 添加节点workflow.add_node("research", research_node)workflow.add_node("analysis", analysis_node)workflow.add_node("report", report_node)# 定义边workflow.add_edge(START, "research")workflow.add_edge("research", "analysis")workflow.add_edge("analysis", "report")workflow.add_edge("report", END)# 编译工作流app = workflow.compile()return app# 运行复杂工作流async def run_research_workflow():app = await create_research_workflow()result = await app.ainvoke({"messages": [("user", "人工智能在医疗领域的应用前景")],"research_data": {},"final_report": ""})print("最终报告:")print(result["final_report"])
四、LlamaIndex - 企业级RAG+Agent
LlamaIndex专注于企业级RAG和Agent系统,特别适合需要处理大量文档和知识库的场景。
安装和基础设置
pip install llama-index llama-index-agent-openai mcp-client-pythonfrom llama_index.core import Settingsfrom llama_index.llms.openai import OpenAIfrom llama_index.agent.openai import OpenAIAgentfrom llama_index.tools.mcp import McpToolSpecfrom mcp_client import BasicMCPClientimport asyncioasync def create_llamaindex_agent():# 配置全局设置Settings.llm = OpenAI(model="gpt-4")# 创建MCP客户端mcp_client = BasicMCPClient()await mcp_client.connect_stdio(command="npx",args=["@tavily/mcp-server"])# 使用McpToolSpec包装MCP工具mcp_tool_spec = McpToolSpec(mcp_client)tools = mcp_tool_spec.to_tool_list()# 创建Agentagent = OpenAIAgent.from_tools(tools=tools,system_prompt="""你是一个专业的AI助手,具备以下能力:1. 使用搜索工具获取最新信息2. 分析和整理信息3. 提供专业建议请始终基于可靠的信息源进行回答。""",verbose=True)return agent, mcp_client# 运行Agentasync def run_llamaindex_agent():agent, mcp_client = await create_llamaindex_agent()try:# 执行查询response = await agent.achat("帮我搜索并分析2024年大语言模型的发展趋势")print("Agent回复:")print(response.response)# 查看工具调用历史print("n工具调用历史:")for i, source in enumerate(response.source_nodes):print(f"调用 {i+1}: {source.node.text[:100]}...")finally:await mcp_client.disconnect()# RAG + Agent 集成示例async def create_rag_agent():from llama_index.core import VectorStoreIndex, Documentfrom llama_index.embeddings.openai import OpenAIEmbedding# 设置嵌入模型Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-large")# 创建文档(示例)documents = [Document(text="人工智能是计算机科学的一个分支,致力于创建能够执行通常需要人类智能的任务的系统。"),Document(text="机器学习是人工智能的一个子领域,专注于开发能够从数据中学习的算法。"),Document(text="深度学习是机器学习的一个分支,使用多层神经网络来模拟人脑的工作方式。")]# 创建向量索引index = VectorStoreIndex.from_documents(documents)# 创建查询引擎作为工具query_engine = index.as_query_engine()# 创建MCP工具mcp_client = BasicMCPClient()await mcp_client.connect_stdio(command="npx",args=["@tavily/mcp-server"])mcp_tool_spec = McpToolSpec(mcp_client)mcp_tools = mcp_tool_spec.to_tool_list()# 创建RAG工具from llama_index.core.tools import QueryEngineToolrag_tool = QueryEngineTool.from_defaults(query_engine=query_engine,name="knowledge_base",description="查询内部知识库,获取AI相关的基础信息")# 组合所有工具all_tools = [rag_tool] + mcp_tools# 创建Agentagent = OpenAIAgent.from_tools(tools=all_tools,system_prompt="""你是一个专业的AI知识助手,具备以下能力:1. 使用内部知识库查询基础概念2. 使用搜索工具获取最新信息3. 结合两者提供全面的回答请优先使用内部知识库,必要时使用搜索工具获取最新信息。""",verbose=True)return agent, mcp_client# 运行RAG Agentasync def run_rag_agent():agent, mcp_client = await create_rag_agent()try:response = await agent.achat("什么是深度学习?它在2025年有哪些最新进展?")print("RAG Agent回复:")print(response.response)finally:await mcp_client.disconnect()if __name__ == "__main__":# 运行基础Agentasyncio.run(run_llamaindex_agent())# 运行RAG Agentprint("n" + "="*50 + "n")asyncio.run(run_rag_agent())
五、AutoGen 0.4+ - 分布式多Agent系统
AutoGen是微软开发的多Agent协作框架,0.4版本开始引入了更强大的分布式能力。
安装和基础设置
pip install autogen-agentchat mcp-client-pythonimport asynciofrom autogen_agentchat.agents import AssistantAgentfrom autogen_agentchat.teams import RoundRobinGroupChatfrom autogen_agentchat.ui import Consolefrom mcp_client import StdioServerParams, SseServerParamsfrom mcp_client.integrations.autogen import AutoGenMCPClientasync def create_autogen_agents():# 创建MCP客户端mcp_client = AutoGenMCPClient()# 配置Stdio Serverstdio_params = StdioServerParams(command="npx",args=["@tavily/mcp-server"])# 连接MCP Serverawait mcp_client.connect_server("search_tools", stdio_params)# 获取工具列表tools = await mcp_client.get_tools("search_tools")# 创建研究员Agentresearcher = AssistantAgent(name="研究员",model_client=OpenAI(model="gpt-4"),tools=tools,system_message="""你是一个专业的研究员,负责:1. 收集和分析信息2. 使用搜索工具获取最新数据3. 提供准确的研究结果""")# 创建分析师Agentanalyst = AssistantAgent(name="分析师",model_client=OpenAI(model="gpt-4"),system_message="""你是一个专业的数据分析师,负责:1. 分析研究员提供的数据2. 识别趋势和模式3. 提供深入见解""")# 创建报告员Agentreporter = AssistantAgent(name="报告员",model_client=OpenAI(model="gpt-4"),system_message="""你是一个专业的报告撰写专家,负责:1. 整理研究和分析结果2. 生成结构化报告3. 确保内容准确易懂""")return researcher, analyst, reporter, mcp_clientasync def run_autogen_team():researcher, analyst, reporter, mcp_client = await create_autogen_agents()try:# 创建团队team = RoundRobinGroupChat([researcher, analyst, reporter])# 执行任务result = await Console(team.run_stream(task="请研究、分析并报告区块链技术在2024年的最新发展趋势"))print("团队协作结果:")print(result.messages[-1].content)finally:await mcp_client.disconnect_all()# 分布式Agent示例async def create_distributed_system():from autogen_agentchat.base import TaskResultfrom autogen_agentchat.messages import ChatMessage# 创建多个MCP客户端(模拟分布式环境)search_client = AutoGenMCPClient()# 使用SSE连接远程MCP Serversse_params = SseServerParams(url="http://localhost:8000/mcp",headers={"Authorization": "Bearer your-token"})await search_client.connect_server("remote_search", sse_params)# 创建专门的搜索Agentsearch_agent = AssistantAgent(name="搜索专家",model_client=OpenAI(model="gpt-4"),tools=await search_client.get_tools("remote_search"),system_message="你专门负责信息搜索和数据收集")# 创建本地分析Agentlocal_analyst = AssistantAgent(name="本地分析师",model_client=OpenAI(model="gpt-4"),system_message="你负责分析从搜索Agent获得的数据")# 创建分布式团队distributed_team = RoundRobinGroupChat([search_agent, local_analyst])return distributed_team, search_clientif __name__ == "__main__":asyncio.run(run_autogen_team())
自定义MCP工具集成
from autogen_agentchat.base import Toolfrom typing import Any, Dictimport jsonclass CustomMCPTool(Tool):"""自定义MCP工具包装器"""def __init__(self, mcp_client, tool_name: str):self.mcp_client = mcp_clientself.tool_name = tool_nameasync def run(self, **kwargs) -> Any:"""执行MCP工具"""try:result = await self.mcp_client.call_tool(self.tool_name,kwargs)return resultexcept Exception as e:return f"工具调用失败: {str(e)}"@propertydef schema(self) -> Dict[str, Any]:"""工具schema"""return {"type": "function","function": {"name": self.tool_name,"description": f"调用{self.tool_name}工具","parameters": {"type": "object","properties": {"query": {"type": "string","description": "查询参数"}},"required": ["query"]}}}async def create_custom_tools_agent():# 创建MCP客户端mcp_client = AutoGenMCPClient()# 连接多个MCP服务await mcp_client.connect_server("search",StdioServerParams(command="npx", args=["@tavily/mcp-server"]))# 创建自定义工具search_tool = CustomMCPTool(mcp_client, "tavily_search")# 创建Agentagent = AssistantAgent(name="多工具专家",model_client=OpenAI(model="gpt-4"),tools=[search_tool],system_message="你是一个能够使用多种工具的专家")return agent, mcp_client# 运行自定义工具Agentasync def run_custom_tools():agent, mcp_client = await create_custom_tools_agent()try:# 创建单Agent对话from autogen_agentchat.teams import Swarmteam = Swarm([agent])result = await team.run("使用搜索工具查找Python asyncio的最佳实践")print("自定义工具结果:")print(result.messages[-1].content)finally:await mcp_client.disconnect_all()
六、Pydantic AI - 结构化输出框架
Pydantic AI结合了Pydantic的类型验证能力,特别适合需要结构化输出的场景。
安装和基础设置
pip install pydantic-ai mcp-client-pythonfrom pydantic_ai import Agent, ModelRetryfrom pydantic import BaseModel, Fieldfrom mcp_client import MCPServerStdio, MCPServerHTTPfrom typing import List, Optionalimport asyncio# 定义结构化输出模型class SearchResult(BaseModel):title: str = Field(description="搜索结果标题")content: str = Field(description="搜索结果内容")url: str = Field(description="搜索结果链接")relevance_score: float = Field(description="相关度评分", ge=0.0, le=1.0)class ResearchReport(BaseModel):topic: str = Field(description="研究主题")executive_summary: str = Field(description="执行摘要")key_findings: List[str] = Field(description="关键发现")search_results: List[SearchResult] = Field(description="搜索结果")conclusion: str = Field(description="结论")confidence_level: float = Field(description="置信度", ge=0.0, le=1.0)async def create_pydantic_agent():# 创建MCP Server连接mcp_server = MCPServerStdio(command="npx",args=["@tavily/mcp-server"])# 获取工具tools = await mcp_server.get_tools()# 创建Agentagent = Agent(model="openai:gpt-4",tools=tools,system_prompt="""你是一个专业的研究助手,能够:1. 使用搜索工具获取信息2. 分析和整理搜索结果3. 生成结构化的研究报告请确保输出符合指定的数据结构。""",result_type=ResearchReport)return agent, mcp_serverasync def run_pydantic_agent():agent, mcp_server = await create_pydantic_agent()try:# 执行结构化查询result = await agent.run("研究人工智能在教育领域的应用现状,生成详细的研究报告")print("结构化研究报告:")print(f"研究主题: {result.data.topic}")print(f"执行摘要: {result.data.executive_summary}")print(f"置信度: {result.data.confidence_level}")print("n关键发现:")for i, finding in enumerate(result.data.key_findings, 1):print(f"{i}. {finding}")print("n搜索结果:")for i, search_result in enumerate(result.data.search_results, 1):print(f"{i}. {search_result.title} (相关度: {search_result.relevance_score})")print(f" 链接: {search_result.url}")print(f" 摘要: {search_result.content[:100]}...")print(f"n结论: {result.data.conclusion}")finally:await mcp_server.disconnect()# 高级结构化Agent示例class AnalysisStep(BaseModel):step_name: str = Field(description="分析步骤名称")description: str = Field(description="步骤描述")tools_used: List[str] = Field(description="使用的工具")findings: str = Field(description="发现内容")confidence: float = Field(description="步骤置信度", ge=0.0, le=1.0)class MultiStepAnalysis(BaseModel):query: str = Field(description="原始查询")analysis_steps: List[AnalysisStep] = Field(description="分析步骤")final_answer: str = Field(description="最终答案")overall_confidence: float = Field(description="整体置信度", ge=0.0, le=1.0)sources_cited: int = Field(description="引用源数量")async def create_advanced_pydantic_agent():# 创建HTTP MCP Server连接mcp_server = MCPServerHTTP(base_url="http://localhost:8000/mcp",headers={"Authorization": "Bearer your-token"})tools = await mcp_server.get_tools()# 创建多步骤分析Agentagent = Agent(model="openai:gpt-4",tools=tools,system_prompt="""你是一个专业的分析师,能够进行多步骤深度分析。分析流程:1. 信息收集 - 使用搜索工具收集相关信息2. 数据验证 - 验证信息的准确性3. 深度分析 - 分析数据的含义和影响4. 结论综合 - 整合所有发现得出结论每个步骤都要记录使用的工具、发现的内容和置信度。""",result_type=MultiStepAnalysis)return agent, mcp_serverasync def run_advanced_analysis():agent, mcp_server = await create_advanced_pydantic_agent()try:result = await agent.run("分析区块链技术在供应链管理中的应用前景和挑战")print("多步骤分析结果:")print(f"查询: {result.data.query}")print(f"整体置信度: {result.data.overall_confidence}")print(f"引用源数量: {result.data.sources_cited}")print("n分析步骤:")for i, step in enumerate(result.data.analysis_steps, 1):print(f"步骤 {i}: {step.step_name}")print(f" 描述: {step.description}")print(f" 使用工具: {', '.join(step.tools_used)}")print(f" 发现: {step.findings}")print(f" 置信度: {step.confidence}")print()print(f"最终答案: {result.data.final_answer}")finally:await mcp_server.disconnect()if __name__ == "__main__":# 运行基础结构化Agentasyncio.run(run_pydantic_agent())# 运行高级分析Agentprint("n" + "="*50 + "n")asyncio.run(run_advanced_analysis())
七、SmolAgents - 轻量级代码生成
SmolAgents是Hugging Face开发的轻量级框架,基于代码生成进行工具调用。
安装和基础设置
pip install smolagents mcp-client-pythonfrom smolagents import CodeAgent, ToolCollectionfrom mcp_client import MCPClientimport asyncioasync def create_smol_agent():# 创建MCP客户端mcp_client = MCPClient()await mcp_client.connect_stdio(command="npx",args=["@tavily/mcp-server"])# 使用ToolCollection导入MCP工具tools = ToolCollection.from_mcp(mcp_client)# 创建CodeAgentagent = CodeAgent(tools=tools,model="gpt-4",system_prompt="""你是一个专业的代码生成助手,能够:1. 理解用户需求2. 生成Python代码调用工具3. 执行代码并返回结果请总是生成清晰、可执行的代码。""")return agent, mcp_clientasync def run_smol_agent():agent, mcp_client = await create_smol_agent()try:# 执行代码生成任务result = await agent.run("""请帮我搜索"Python异步编程最佳实践",然后分析搜索结果,提取关键要点。""")print("SmolAgent生成的代码:")print(result.code)print("n执行结果:")print(result.output)finally:await mcp_client.disconnect()# 自定义工具集成示例async def create_custom_smol_tools():from smolagents import Tool# 创建自定义工具class CustomSearchTool(Tool):name = "custom_search"description = "自定义搜索工具,支持高级搜索选项"def __init__(self, mcp_client):self.mcp_client = mcp_clientsuper().__init__()async def forward(self, query: str, max_results: int = 5) -> str:"""执行自定义搜索"""try:# 调用MCP工具result = await self.mcp_client.call_tool("tavily_search",{"query": query,"max_results": max_results})return resultexcept Exception as e:return f"搜索失败: {str(e)}"@propertydef inputs(self):return {"query": {"type": "string", "description": "搜索查询"},"max_results": {"type": "integer", "description": "最大结果数", "default": 5}}@propertydef output_type(self):return "string"# 创建MCP客户端mcp_client = MCPClient()await mcp_client.connect_stdio(command="npx",args=["@tavily/mcp-server"])# 创建自定义工具custom_tool = CustomSearchTool(mcp_client)# 创建工具集合tools = ToolCollection([custom_tool])# 创建Agentagent = CodeAgent(tools=tools,model="gpt-4",system_prompt="""你是一个专业的搜索分析师,能够:1. 使用自定义搜索工具2. 分析搜索结果3. 生成洞察报告""")return agent, mcp_clientasync def run_custom_smol_agent():agent, mcp_client = await create_custom_smol_tools()try:result = await agent.run("""使用自定义搜索工具搜索"机器学习模型部署"相关内容,限制结果数量为3个,然后分析这些结果的共同点。""")print("自定义SmolAgent结果:")print(result.code)print("n输出:")print(result.output)finally:await mcp_client.disconnect()# 批量任务处理示例async def create_batch_processing_agent():# 创建MCP客户端mcp_client = MCPClient()await mcp_client.connect_stdio(command="npx",args=["@tavily/mcp-server"])tools = ToolCollection.from_mcp(mcp_client)# 创建批量处理Agentagent = CodeAgent(tools=tools,model="gpt-4",system_prompt="""你是一个批量任务处理专家,能够:1. 处理多个搜索任务2. 并行执行工具调用3. 汇总和分析结果请使用Python的asyncio来实现并行处理。""")return agent, mcp_clientasync def run_batch_processing():agent, mcp_client = await create_batch_processing_agent()try:# 批量搜索任务queries = ["人工智能在金融领域的应用","区块链技术发展趋势","云计算市场分析","物联网安全挑战"]result = await agent.run(f"""对以下查询进行批量搜索和分析:{queries}请:1. 并行执行所有搜索2. 分析每个查询的结果3. 生成综合报告""")print("批量处理结果:")print(result.code)print("n综合报告:")print(result.output)finally:await mcp_client.disconnect()if __name__ == "__main__":# 运行基础SmolAgentasyncio.run(run_smol_agent())# 运行自定义工具Agentprint("n" + "="*50 + "n")asyncio.run(run_custom_smol_agent())# 运行批量处理Agentprint("n" + "="*50 + "n")asyncio.run(run_batch_processing())
八、Camel - 多Agent角色扮演
Camel专为多Agent角色扮演和协作任务设计,特别适合需要不同专业角色协作的场景。
安装和基础设置
pip install camel-ai mcp-client-pythonfrom camel.agents import ChatAgentfrom camel.messages import BaseMessagefrom camel.types import RoleType, ModelTypefrom camel.toolkits import MCPToolkitfrom mcp_client import MCPClientimport asyncioasync def create_camel_agents():# 创建MCP客户端mcp_client = MCPClient()await mcp_client.connect_stdio(command="npx",args=["@tavily/mcp-server"])# 创建MCP工具包mcp_toolkit = MCPToolkit(mcp_client)tools = mcp_toolkit.get_tools()# 创建研究员Agentresearcher = ChatAgent(system_message=BaseMessage.make_assistant_message(role_name="研究员",content="""你是一个专业的研究员,具备以下特点:1. 善于信息收集和分析2. 能够使用各种搜索工具3. 注重数据的准确性和可靠性4. 擅长发现趋势和模式你的任务是为团队提供准确、全面的研究数据。"""),model_type=ModelType.GPT_4,tools=tools)# 创建策略师Agentstrategist = ChatAgent(system_message=BaseMessage.make_assistant_message(role_name="策略师",content="""你是一个资深的策略师,具备以下能力:1. 基于研究数据制定策略2. 分析市场趋势和机会3. 识别风险和挑战4. 提供可行的行动建议你的任务是将研究结果转化为实际的策略建议。"""),model_type=ModelType.GPT_4)# 创建执行官Agentexecutor = ChatAgent(system_message=BaseMessage.make_assistant_message(role_name="执行官",content="""你是一个经验丰富的执行官,专长包括:1. 将策略转化为具体行动计划2. 评估资源需求和时间安排3. 识别执行风险和解决方案4. 制定关键指标和里程碑你的任务是确保策略能够有效执行。"""),model_type=ModelType.GPT_4)return researcher, strategist, executor, mcp_clientasync def run_camel_collaboration():researcher, strategist, executor, mcp_client = await create_camel_agents()try:# 定义协作任务task = "制定一个关于人工智能在零售业应用的完整商业策略"# 第一阶段:研究员收集信息research_prompt = BaseMessage.make_user_message(role_name="项目经理",content=f"""请对以下主题进行全面研究:{task}需要重点关注:1. 当前市场状况2. 技术发展趋势3. 成功案例分析4. 潜在挑战和机遇""")research_result = await researcher.step(research_prompt)print("研究员报告:")print(research_result.msg.content)print("n" + "="*50 + "n")# 第二阶段:策略师制定策略strategy_prompt = BaseMessage.make_user_message(role_name="项目经理",content=f"""基于研究员的报告,请制定详细的商业策略:研究报告:{research_result.msg.content}请提供:1. 市场定位策略2. 技术实施方案3. 竞争优势分析4. 风险评估和应对""")strategy_result = await strategist.step(strategy_prompt)print("策略师方案:")print(strategy_result.msg.content)print("n" + "="*50 + "n")# 第三阶段:执行官制定执行计划execution_prompt = BaseMessage.make_user_message(role_name="项目经理",content=f"""基于策略师的方案,请制定详细的执行计划:策略方案:{strategy_result.msg.content}请提供:1. 具体行动步骤2. 资源需求和预算3. 时间表和里程碑4. 关键指标和评估方法""")execution_result = await executor.step(execution_prompt)print("执行官计划:")print(execution_result.msg.content)finally:await mcp_client.disconnect()# 动态角色分配示例async def create_dynamic_role_system():from camel.societies import RolePlaying# 创建MCP客户端mcp_client = MCPClient()await mcp_client.connect_stdio(command="npx",args=["@tavily/mcp-server"])mcp_toolkit = MCPToolkit(mcp_client)tools = mcp_toolkit.get_tools()# 创建角色扮演系统role_play = RolePlaying(assistant_role_name="AI专家",user_role_name="企业顾问",assistant_agent_kwargs={"model_type": ModelType.GPT_4,"tools": tools},user_agent_kwargs={"model_type": ModelType.GPT_4})return role_play, mcp_clientasync def run_dynamic_roles():role_play, mcp_client = await create_dynamic_role_system()try:# 初始化对话task_prompt = """我需要为我的制造业公司制定一个AI转型战略。请AI专家研究当前的AI技术趋势,企业顾问则基于实际业务需求提供建议。让我们开始这个协作过程。"""# 运行角色扮演对话input_msg = BaseMessage.make_user_message(role_name="项目发起人",content=task_prompt)print("开始角色扮演协作:")print(f"任务: {task_prompt}")print("n" + "="*50 + "n")# 运行多轮对话for i in range(3): # 进行3轮对话assistant_msg, user_msg = await role_play.step(input_msg)print(f"第{i+1}轮对话:")print(f"AI专家: {assistant_msg.content}")print(f"企业顾问: {user_msg.content}")print("n" + "-"*30 + "n")# 准备下一轮输入input_msg = user_msgfinally:await mcp_client.disconnect()# 专业团队协作示例async def create_professional_team():# 创建MCP客户端mcp_client = MCPClient()await mcp_client.connect_stdio(command="npx",args=["@tavily/mcp-server"])mcp_toolkit = MCPToolkit(mcp_client)tools = mcp_toolkit.get_tools()# 定义专业角色roles = {"数据科学家": {"description": "专注于数据分析、机器学习模型开发和数据洞察","tools": tools},"产品经理": {"description": "负责产品规划、用户需求分析和市场策略","tools": tools},"技术架构师": {"description": "设计系统架构、技术选型和实施方案","tools": []},"业务分析师": {"description": "分析业务流程、需求分析和效益评估","tools": []}}# 创建Agent团队team = {}for role_name, role_config in roles.items():team[role_name] = ChatAgent(system_message=BaseMessage.make_assistant_message(role_name=role_name,content=f"""你是一个专业的{role_name},职责是:{role_config['description']}请以专业的角度参与团队协作,提供你领域内的专业建议和见解。"""),model_type=ModelType.GPT_4,tools=role_config.get('tools', []))return team, mcp_clientasync def run_professional_team():team, mcp_client = await create_professional_team()try:# 团队协作任务project_brief = """项目:开发一个基于AI的客户服务聊天机器人需求:1. 能够理解客户问题并提供准确回答2. 支持多语言交互3. 具备学习和优化能力4. 集成现有客服系统请各位专家从自己的角度提供专业建议。"""print("专业团队协作开始:")print(f"项目简介: {project_brief}")print("n" + "="*50 + "n")# 让每个角色分别提供建议for role_name, agent in team.items():prompt = BaseMessage.make_user_message(role_name="项目经理",content=f"""项目简介:{project_brief}请从{role_name}的角度,提供专业的建议和方案。""")result = await agent.step(prompt)print(f"{role_name}的建议:")print(result.msg.content)print("n" + "-"*30 + "n")# 生成综合方案print("团队协作完成,各专家已提供专业建议。")finally:await mcp_client.disconnect()if __name__ == "__main__":# 运行基础协作asyncio.run(run_camel_collaboration())# 运行动态角色系统print("n" + "="*70 + "n")asyncio.run(run_dynamic_roles())# 运行专业团队print("n" + "="*70 + "n")asyncio.run(run_professional_team())
九、CrewAI - 结构化Agent团队
CrewAI专注于构建结构化的Agent团队(Crew),强调明确的角色分工和任务流程。
安装和基础设置
pip install crewai mcp-client-python# 安装第三方MCP适配器pip install crewai-mcp-adapterfrom crewai import Agent, Task, Crew, Processfrom crewai.tools import BaseToolimport asyncioimport jsonimport subprocessimport sysfrom typing import Dict, Any, Optionalimport os# 简化的MCP客户端实现class MCPClient:def __init__(self):self.process = Noneself.connected = Falseasync def connect_stdio(self, command: str, args: list, env: Optional[Dict[str, str]] = None):"""连接到MCP服务器"""try:# 设置环境变量full_env = os.environ.copy()if env:full_env.update(env)# 启动MCP服务器进程self.process = await asyncio.create_subprocess_exec(command, *args,stdin=asyncio.subprocess.PIPE,stdout=asyncio.subprocess.PIPE,stderr=asyncio.subprocess.PIPE,env=full_env)# 发送初始化请求init_request = {"jsonrpc": "2.0","id": 1,"method": "initialize","params": {"protocolVersion": "2024-11-05","capabilities": {"tools": {}},"clientInfo": {"name": "CrewAI-MCP-Client","version": "1.0.0"}}}await self._send_request(init_request)response = await self._receive_response()if response.get("result"):self.connected = Trueprint("MCP客户端连接成功")return Trueelse:print(f"MCP连接失败: {response}")return Falseexcept Exception as e:print(f"MCP连接错误: {e}")return Falseasync def _send_request(self, request: Dict[str, Any]):"""发送请求到MCP服务器"""if not self.process:raise Exception("MCP客户端未连接")request_str = json.dumps(request) + "n"self.process.stdin.write(request_str.encode())await self.process.stdin.drain()async def _receive_response(self) -> Dict[str, Any]:"""接收来自MCP服务器的响应"""if not self.process:raise Exception("MCP客户端未连接")line = await self.process.stdout.readline()if line:try:return json.loads(line.decode().strip())except json.JSONDecodeError as e:print(f"JSON解析错误: {e}")return {"error": "JSON解析失败"}return {"error": "无响应"}async def call_tool(self, tool_name: str, params: Dict[str, Any]) -> str:"""调用MCP工具"""if not self.connected:return "MCP客户端未连接"try:# 发送工具调用请求request = {"jsonrpc": "2.0","id": 2,"method": "tools/call","params": {"name": tool_name,"arguments": params}}await self._send_request(request)response = await self._receive_response()if "result" in response:content = response["result"].get("content", [])if content:return content[0].get("text", "无内容")return "工具调用成功但无返回内容"else:return f"工具调用失败: {response.get('error', '未知错误')}"except Exception as e:return f"工具调用异常: {str(e)}"async def disconnect(self):"""断开MCP连接"""if self.process:self.process.terminate()await self.process.wait()self.connected = Falseprint("MCP客户端已断开连接")# 创建MCP工具适配器class MCPSearchTool(BaseTool):name: str = "MCP搜索工具"description: str = "使用MCP协议进行网络搜索,获取最新信息"def __init__(self, mcp_client):super().__init__()self.mcp_client = mcp_clientdef _run(self, query: str) -> str:"""执行搜索"""try:# 在新的事件循环中运行异步代码import asynciotry:loop = asyncio.get_event_loop()if loop.is_running():# 如果事件循环正在运行,创建一个新的事件循环import threadingresult = [None]exception = [None]def run_in_thread():new_loop = asyncio.new_event_loop()asyncio.set_event_loop(new_loop)try:result[0] = new_loop.run_until_complete(self.mcp_client.call_tool("tavily_search", {"query": query}))except Exception as e:exception[0] = efinally:new_loop.close()thread = threading.Thread(target=run_in_thread)thread.start()thread.join()if exception[0]:raise exception[0]return result[0]else:result = loop.run_until_complete(self.mcp_client.call_tool("tavily_search", {"query": query}))return resultexcept RuntimeError:# 如果没有事件循环,创建一个新的result = asyncio.run(self.mcp_client.call_tool("tavily_search", {"query": query}))return resultexcept Exception as e:return f"搜索失败: {str(e)}"async def create_crew_with_mcp():"""创建带有MCP工具的Crew"""# 创建MCP客户端mcp_client = MCPClient()# 连接到Tavily搜索服务# 注意:需要设置TAVILY_API_KEY环境变量success = await mcp_client.connect_stdio(command="npx",args=["-y", "@tavily/mcp-server"],env={"TAVILY_API_KEY": os.getenv("TAVILY_API_KEY", "your_api_key_here")})if not success:print("警告:MCP连接失败,将使用模拟数据")# 创建模拟工具class MockSearchTool(BaseTool):name: str = "模拟搜索工具"description: str = "模拟搜索工具,用于演示"def _run(self, query: str) -> str:return f"模拟搜索结果:关于'{query}'的信息 - 这是一个模拟搜索结果,包含了相关的基础信息。"search_tool = MockSearchTool()else:# 创建MCP搜索工具search_tool = MCPSearchTool(mcp_client)# 创建研究员Agentresearcher = Agent(role='资深研究员',goal='收集和分析相关信息,提供准确的研究报告',backstory="""你是一个经验丰富的研究员,擅长从各种来源收集信息,进行深入分析,并提供有价值的洞察。你总是确保信息的准确性和相关性。""",tools=[search_tool],verbose=True,allow_delegation=False)# 创建分析师Agentanalyst = Agent(role='数据分析师',goal='分析研究数据,识别趋势和模式,提供专业见解',backstory="""你是一个专业的数据分析师,善于从复杂的数据中提取有意义的信息,识别趋势和模式,并提供基于数据的专业建议。""",verbose=True,allow_delegation=False)# 创建内容创作者Agentcontent_creator = Agent(role='内容创作专家',goal='将分析结果转化为易于理解的内容',backstory="""你是一个专业的内容创作专家,擅长将复杂的分析结果转化为清晰、有吸引力的内容,确保读者能够轻松理解。""",verbose=True,allow_delegation=False)return researcher, analyst, content_creator, mcp_clientasync def create_crew_tasks(researcher, analyst, content_creator):"""创建任务"""# 定义研究任务research_task = Task(description="""对"人工智能在医疗保健中的应用"进行全面研究。需要研究的方面:1. 当前应用现状2. 主要技术和解决方案3. 成功案例和失败教训4. 未来发展趋势5. 面临的挑战和机遇请提供详细的研究报告。""",expected_output="一份包含当前状况、技术方案、案例分析和趋势预测的详细研究报告",agent=researcher)# 定义分析任务analysis_task = Task(description="""基于研究报告,进行深入的数据分析。分析要点:1. 市场规模和增长趋势2. 技术成熟度分析3. 竞争格局评估4. 投资机会识别5. 风险因素评估请提供专业的分析报告。""",expected_output="一份包含市场分析、技术评估、竞争分析和投资建议的专业分析报告",agent=analyst)# 定义内容创作任务content_task = Task(description="""基于研究和分析报告,创作一篇高质量的科普文章。内容要求:1. 通俗易懂,适合普通读者2. 结构清晰,逻辑性强3. 包含实际案例和数据4. 提供实用的建议5. 字数控制在1500-2000字请创作一篇引人入胜的科普文章。""",expected_output="一篇1500-2000字的高质量科普文章,内容准确、易懂、有趣",agent=content_creator)return research_task, analysis_task, content_taskasync def create_advanced_crew():"""创建高级Crew配置"""# 创建MCP客户端mcp_client = MCPClient()success = await mcp_client.connect_stdio(command="npx",args=["-y", "@tavily/mcp-server"],env={"TAVILY_API_KEY": os.getenv("TAVILY_API_KEY", "your_api_key_here")})if success:search_tool = MCPSearchTool(mcp_client)else:# 使用模拟工具class MockSearchTool(BaseTool):name: str = "模拟搜索工具"description: str = "模拟搜索工具,用于演示"def _run(self, query: str) -> str:return f"模拟搜索结果:关于'{query}'的专业信息和最新数据。"search_tool = MockSearchTool()# 创建专业化的Agent团队market_researcher = Agent(role='市场研究专家',goal='专注于市场趋势和竞争分析',backstory='你是一个资深的市场研究专家,对各行业的市场动态有深入了解。',tools=[search_tool],verbose=True,max_iter=3, # 最大迭代次数memory=True # 启用记忆功能)tech_analyst = Agent(role='技术分析师',goal='专注于技术发展和创新分析',backstory='你是一个技术分析专家,对新兴技术和创新趋势有敏锐的洞察力。',tools=[search_tool],verbose=True,max_iter=3,memory=True)strategy_consultant = Agent(role='战略咨询师',goal='提供战略建议和实施方案',backstory='你是一个经验丰富的战略咨询师,擅长将研究和分析转化为可执行的战略方案。',verbose=True,max_iter=3,memory=True)return market_researcher, tech_analyst, strategy_consultant, mcp_clientasync def run_crew_ai():"""运行CrewAI任务"""try:print("开始创建CrewAI团队...")# 创建Agentsresearcher, analyst, content_creator, mcp_client = await create_crew_with_mcp()# 创建任务research_task, analysis_task, content_task = await create_crew_tasks(researcher, analyst, content_creator)# 创建Crewcrew = Crew(agents=[researcher, analyst, content_creator],tasks=[research_task, analysis_task, content_task],process=Process.sequential, # 顺序执行verbose=2)print("📋 开始执行CrewAI任务...")# 执行任务result = crew.kickoff()print("nCrewAI任务完成!")print("n最终结果:")print("="*50)print(result)print("="*50)return resultexcept Exception as e:print(f"执行过程中出现错误: {str(e)}")return Nonefinally:# 清理资源if 'mcp_client' in locals():await mcp_client.disconnect()async def run_advanced_crew():"""运行高级Crew配置"""try:print("开始创建高级CrewAI团队...")# 创建高级Agentsmarket_researcher, tech_analyst, strategy_consultant, mcp_client = await create_advanced_crew()# 创建高级任务market_task = Task(description="""对人工智能医疗保健市场进行深入的市场研究。重点关注:1. 全球市场规模和增长预测2. 主要参与者和竞争格局3. 区域市场差异4. 监管环境影响""",expected_output="详细的市场研究报告,包含数据分析和竞争格局",agent=market_researcher)tech_task = Task(description="""分析人工智能在医疗保健中的技术发展趋势。重点关注:1. 关键技术栈和解决方案2. 技术成熟度评估3. 创新突破点4. 技术实施挑战""",expected_output="技术分析报告,包含技术路线图和实施建议",agent=tech_analyst)strategy_task = Task(description="""基于市场研究和技术分析,制定战略建议。重点关注:1. 投资机会识别2. 风险评估和缓解3. 实施路径规划4. 成功因素分析""",expected_output="战略建议报告,包含可执行的行动方案",agent=strategy_consultant)# 创建高级Crewadvanced_crew = Crew(agents=[market_researcher, tech_analyst, strategy_consultant],tasks=[market_task, tech_task, strategy_task],process=Process.sequential,verbose=2)print("📋 开始执行高级CrewAI任务...")# 执行任务result = advanced_crew.kickoff()print("n高级CrewAI任务完成!")print("n最终结果:")print("="*50)print(result)print("="*50)return resultexcept Exception as e:print(f"❌ 执行过程中出现错误: {str(e)}")return Nonefinally:# 清理资源if 'mcp_client' in locals():await mcp_client.disconnect()def main():"""主函数"""print("CrewAI + MCP 集成演示")print("="*50)# 检查环境变量if not os.getenv("TAVILY_API_KEY"):print(" 警告:未设置TAVILY_API_KEY环境变量")print(" 将使用模拟数据进行演示")print(" 要获取真实搜索结果,请设置环境变量:")print(" export TAVILY_API_KEY=your_api_key_here")print()print("请选择运行模式:")print("1. 基础CrewAI演示")print("2. 高级CrewAI演示")choice = input("请输入选择 (1 或 2): ").strip()if choice == "1":asyncio.run(run_crew_ai())elif choice == "2":asyncio.run(run_advanced_crew())else:print("无效选择,运行基础演示...")asyncio.run(run_crew_ai())if __name__ == "__main__":main()
十、总结与最佳实践
通过以上8种框架的深入解析,我们可以看到每种框架都有其独特的优势和适用场景:
1、框架选择建议
-
快速原型开发:选择 OpenAI Agents SDK 或 SmolAgents
-
复杂工作流:选择 LangGraph 或 CrewAI
-
企业级RAG应用:选择 LlamaIndex
-
多Agent协作:选择 AutoGen 或 Camel
-
类型安全要求:选择 Pydantic AI
-
团队协作管理:选择 CrewAI
2、MCP集成最佳实践
-
统一工具管理:使用MCP Server统一管理所有外部工具
-
错误处理:始终包含完整的错误处理机制
-
异步操作:优先使用异步操作提高性能
-
资源管理:及时关闭MCP连接避免资源泄漏
-
环境变量:使用环境变量管理API密钥等敏感信息
3、技术发展趋势
-
标准化:MCP协议将成为Agent工具集成的标准
-
多模态:框架将支持更多模态的输入输出
-
分布式:Agent系统将更加分布式和可扩展
-
企业级:更多企业级特性如权限管理、审计日志等
随着AI技术的不断发展,这些框架也在快速演进。建议开发者根据具体需求选择合适的框架,并关注其发展动态。通过合理使用MCP Server,你的Agent系统将具备更强大的外部工具调用能力,为用户提供更丰富的功能体验。
转载请注明:企业新基建:MCP + LLM + Agent 8大架构,将打通AI Agent的“神经中枢”落地实操! | AI工具大全&导航
相关文章
