在大模型技术蓬勃发展的当下,训练数据集质量、模型结构优化、推理能力增强成为决定模型性能的核心问题。
昨天写了一篇关于NSA(Native Sparse Attention,原生稀疏注意力)的文章,今天谈一个更大的话题。而NSA和MoE(Mixture-of-Experts,混合专家系统,明天有专文来讨论)的出现,为解决大模型发展的核心问题提供了独特的思考方向与创新思路。深入探究它们在架构和算法层面的价值,对推动大模型技术进步意义重大。
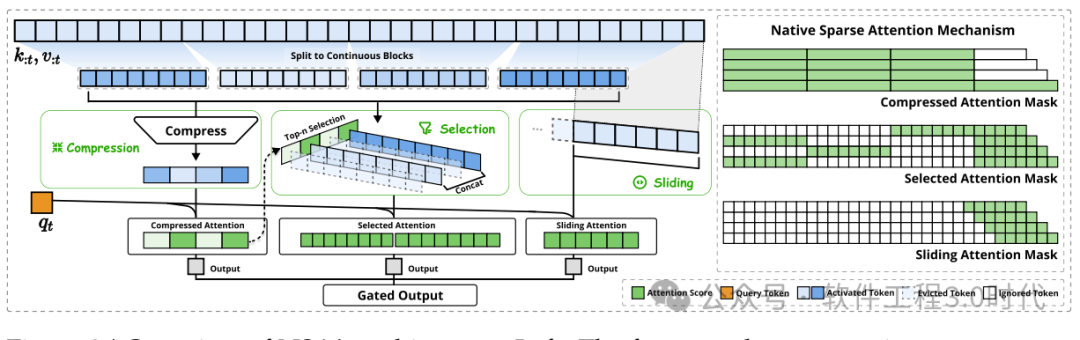
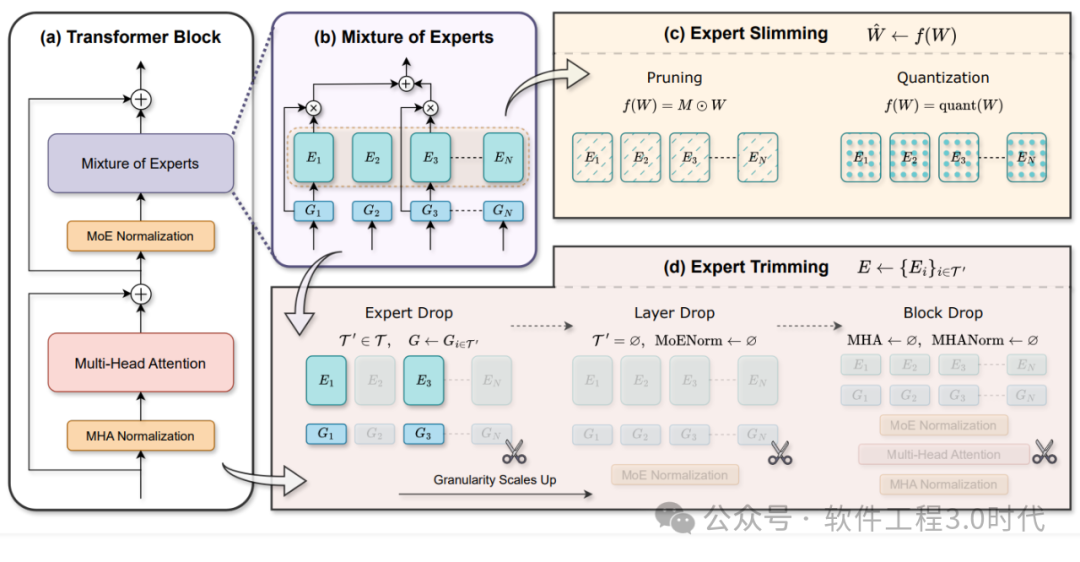
NSA作为一种改进版的注意力机制,致力于解决传统注意力机制计算复杂度随序列长度呈O(n²)增长的难题。传统注意力机制在处理长序列时,计算开销巨大,严重限制了模型对长文本的处理能力。NSA通过引入创新的计算方式,打破了这一困境。它基于对注意力分数固有稀疏性的利用,不再对所有位置进行同等关注,而是有选择性地聚焦关键部分,大大降低了计算成本。在实际应用中,比如在处理长文档时,NSA能智能地筛选出与当前任务最相关的信息片段进行重点分析,避免了对无关信息的过度计算,从而在保证模型性能的前提下,显著提升了处理效率。这种机制的创新为模型在处理长序列任务时提供了更高效的解决方案,使得模型能够在资源有限的情况下,更好地应对复杂的文本处理需求。

(NSA架构,参考论文:https://arxiv.org/pdf/2502.11089)
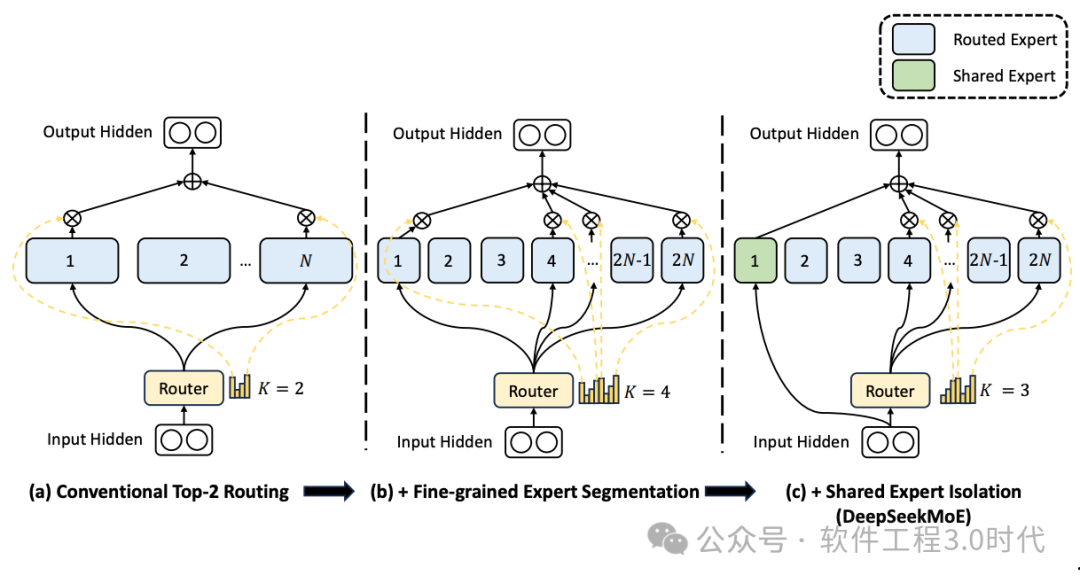
MoE(混合专家系统)打破了传统单一模型的局限,通过将多个不同的“专家”模型组合在一起,每个专家负责处理不同类型或不同部分的任务,然后根据输入数据的特点动态分配任务给最合适的专家进行处理,最后综合各个专家的输出得到最终结果。在图像识别领域,面对不同场景、不同拍摄条件下的图像,MoE中的不同专家可以分别擅长处理人物识别、场景分类等任务。当输入一张包含人物和风景的图片时,MoE能迅速判断并将人物识别任务分配给擅长此领域的专家,将场景分类任务分配给相应专家,通过协同合作,提升整体的识别准确率和效率。在大语言模型中,MoE可以针对不同的语言任务,如文本生成、语义理解等,让擅长特定任务的专家模型发挥专长,从而提高模型在复杂语言处理任务上的表现。
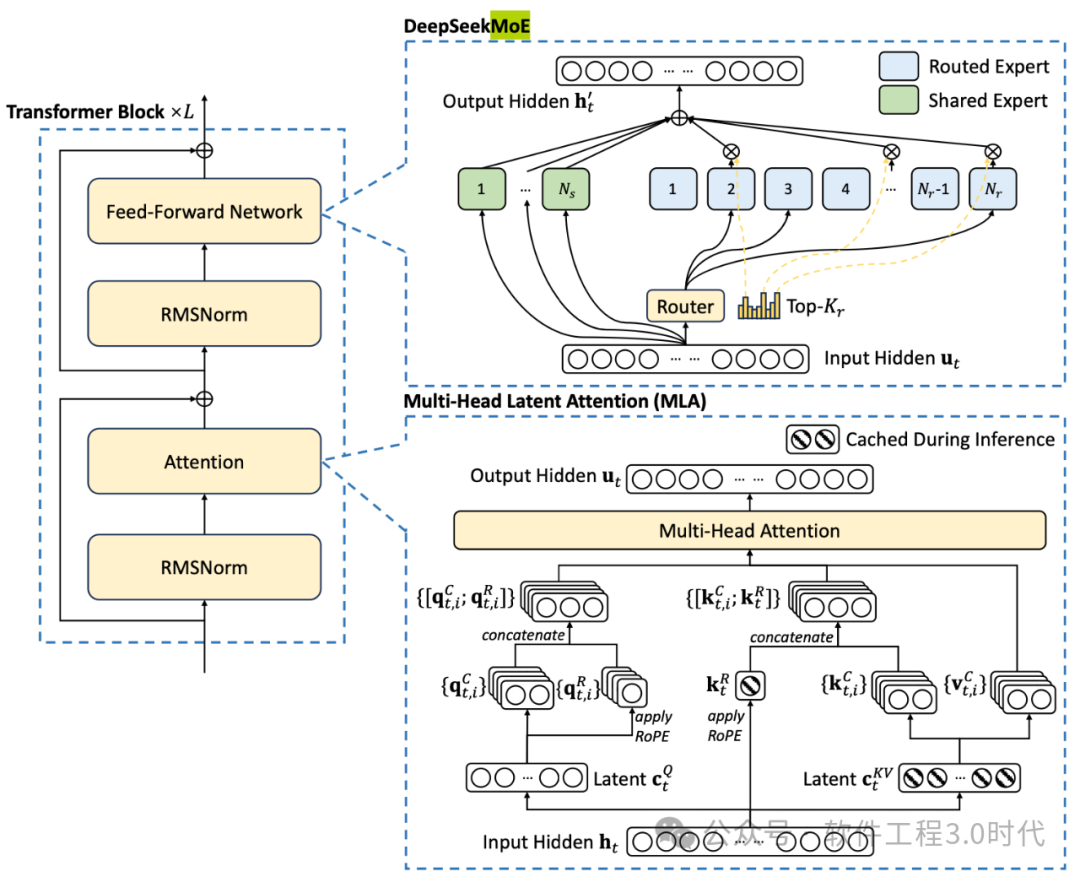
(DeepSeek MoE架构:https://github.com/deepseek-ai/DeepSeek-MoE)
(MoE架构,参考论文:https://arxiv.org/pdf/2412.19437)
NSA和MoE在训练数据集质量提升方面有着独特的作用。NSA通过优化注意力机制,能够更精准地从数据集中提取关键信息,减少噪声数据的干扰。在处理大规模文本数据训练时,NSA能帮助模型聚焦于有价值的语义内容,避免被一些无关紧要的词汇或语句误导,从而提高训练数据的有效利用率。MoE则通过多专家协同的方式,对数据进行多角度处理。不同的专家模型可以从不同的特征和模式出发,对数据进行更全面的学习和分析。这有助于发现数据中隐藏的关系和规律,从而提高数据的质量。在训练过程中,MoE可以让不同专家分别关注数据的语法、语义、语境等方面,综合这些专家的学习结果,能够更全面地理解数据,进而提高训练数据集的质量,为模型提供更优质的学习素材。
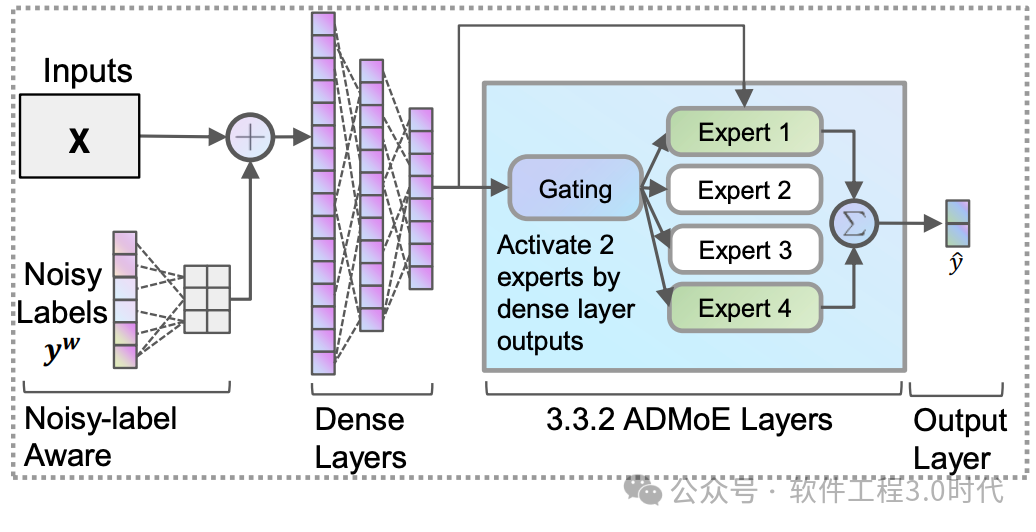
(参考:https://arxiv.org/pdf/2208.11290)
从模型结构优化角度看,NSA和MoE都为模型架构带来了创新性变革。NSA改进了传统注意力机制在长序列处理上的性能,使得模型结构在处理长文本时更加高效。它的出现促使模型架构在设计时更加注重对长序列信息的处理能力,推动了模型架构向更适应复杂任务的方向发展。例如,在Transformer架构中引入NSA机制,可以增强模型对长文本的理解和处理能力,优化整体架构性能。MoE的多专家结构则为模型带来了更高的灵活性和可扩展性。它打破了传统单一模型的固定结构,使得模型可以根据任务需求动态调整内部结构。这种灵活性不仅可以提高模型在不同任务上的适应性,还能通过增加或替换专家模型的方式,方便地对模型进行扩展和优化。可以根据具体任务需求,动态调整专家模型的数量和类型,以达到最佳的模型性能。
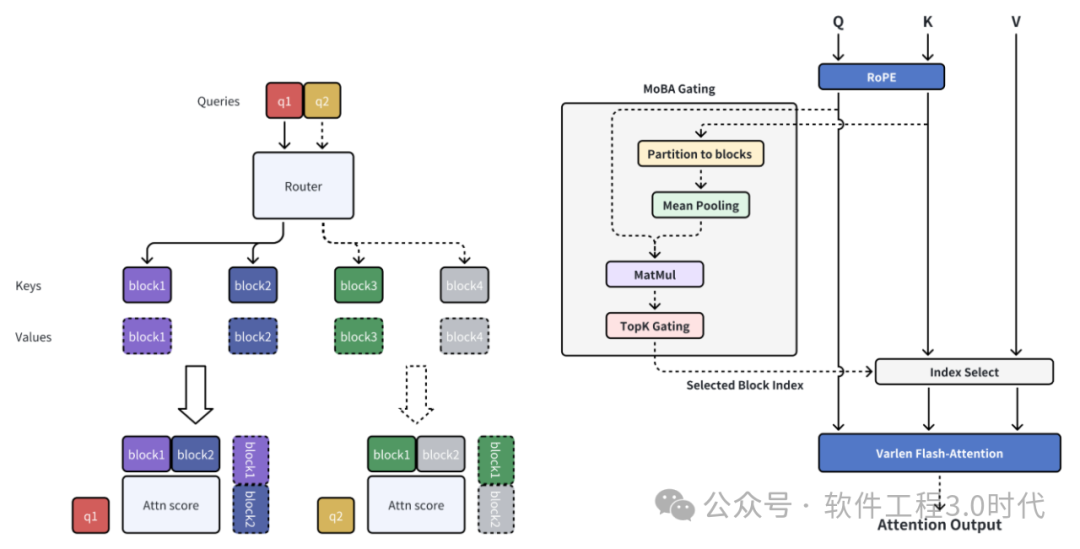
(Kimi的最新论文中MoBA的描述)
NSA和MoE在增强模型推理能力方面也发挥着重要作用。NSA的选择性关注机制使得模型在推理过程中能够更准确地把握关键信息,提高推理的准确性。在阅读理解任务中,NSA可以帮助模型快速定位与问题相关的文本内容,从而更准确地推断出答案。MoE的多专家协同机制为推理提供了更丰富的知识和思路。不同专家模型基于各自的学习经验和知识储备,对推理任务提供不同的见解和解决方案。这些不同的观点相互补充和验证,能够提高推理的可靠性和全面性。在复杂的逻辑推理任务中,不同专家可以从不同的逻辑角度进行分析,综合这些分析结果,模型能够得出更准确、更全面的推理结论。
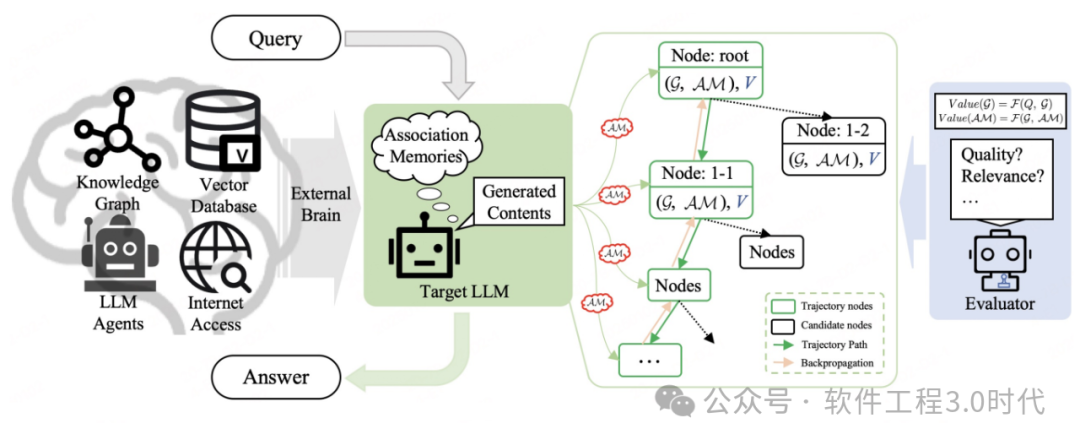
(CoAT架构:https://arxiv.org/pdf/2502.02390)
NSA和MoE在为大模型发展带来新机遇的同时,也面临着一些挑战。NSA的稀疏注意力模式虽然提高了计算效率,但可能会丢失一些重要信息,影响模型对全局信息的把握。在某些需要综合考虑全局信息的任务中,这种信息丢失可能会导致模型性能下降。MoE在实际应用中,多专家模型的协同管理和调度是一个难题。如何准确地将任务分配给最合适的专家,以及如何有效地融合各个专家的输出结果,都需要进一步优化算法和策略。而且,MoE的计算复杂度在一定程度上仍然较高,对硬件资源的要求也比较苛刻,这在一定程度上限制了其大规模应用。NSA和MoE为解决“训练数据集质量、模型结构优化、推理能力增强”等大模型关键问题提供了极具价值的思路和方法。尽管它们面临着一些挑战,但随着技术的不断发展和研究的深入,相信这些问题将逐步得到解决。未来,它们有望在大模型领域发挥更大的作用,推动大模型技术朝着更加智能、高效的方向迈进。
针对NSA可能丢失信息的问题,研究人员可以探索更为精细的信息筛选与保留机制。
-
通过引入更先进的注意力权重分配算法,使NSA在减少计算量的同时,最大程度地保留关键信息。
-
结合强化学习的方法,让模型在训练过程中自主学习如何在稀疏注意力模式下更好地平衡信息筛选与保留,提高对全局信息的理解和利用能力。
对于MoE的任务分配和结果融合难题,优化调度算法是关键。
-
可以利用深度学习技术,构建专门的任务分配模型,通过对输入数据特征的深度分析,更精准地将任务分配给最合适的专家模型。
-
在结果融合方面,开发更智能的融合策略,如基于置信度的加权融合方法,根据每个专家模型输出结果的可信度进行加权计算,提高融合结果的准确性。
为降低MoE的计算复杂度,硬件与软件协同优化是重要方向。
-
在硬件层面,研发针对MoE架构的专用芯片,优化芯片的计算架构和存储结构,提高对多专家模型并行计算的支持能力。
-
在软件层面,采用更高效的模型压缩技术和计算资源管理算法,合理分配计算资源,减少不必要的计算开销,提升MoE在不同硬件环境下的运行效率。
展望未来,NSA和MoE有望实现更紧密的协同创新。将NSA的高效注意力机制与MoE的多专家协同优势相结合,可以构建更为强大的大模型架构。在这种架构中,NSA负责对输入数据进行高效的特征提取和筛选,将处理后的关键信息传递给MoE的各个专家模型。MoE则利用多个专家的专业能力,对这些关键信息进行深入分析和处理,再通过优化的融合策略得到最终结果。这种协同创新不仅能够进一步提升模型的训练效率和性能,还能增强模型在复杂任务上的处理能力。在多模态数据处理领域,NSA可以先对图像、文本、音频等不同模态的数据进行高效的特征提取,然后将这些特征分配给MoE中擅长处理相应模态的专家模型。通过这种方式,模型可以更全面、更深入地理解多模态数据,实现更精准的分析和决策。NSA和MoE代表了大模型架构和算法创新的重要方向。它们在解决大模型关键问题上展现出的潜力,为未来人工智能的发展提供了广阔的想象空间。