最近 DeepSeek-R1 非常热门,我们知道在 o1-Like 模型出现之前,传统的大模型的多语言能力已经十分出色。
那么相较于传统大模型,DeepSeek-R1 这类的 o1-Like 大模型的多语言能力又如何呢?在我们实际应用的时候,选择哪一个模型进行多语言任务(比如翻译/国外客服等)是一个值得探索的问题。
哈尔滨工业大学近期的一项研究发现,在多个多语言翻译任务中 o1-Like 大模型性能超过了传统的大模型,但与此同时也暴露了新的挑战。首先,o1-Like大模型的推理成本显著增加,并且在一些复杂的多语言任务中,其性能表现出现大幅下降。更为严重的是,o1-Like模型在翻译等任务中由于需要先进行“思考”再输出,导致了“漫谈”(Rambling)现象的产生。
这一发现为大模型领域的研究者提供了新的探索方向和思路,揭示了更深层次的优化潜力和应用挑战。

-
论文标题:Evaluating o1-Like LLMs: Unlocking Reasoning for Translation through Comprehensive Analysis
-
论文链接:https://arxiv.org/abs/2502.11544
-
论文作者:Andong Chen (陈安东), Yuchen Song (宋宇宸), Wenxin Zhu (祝文鑫), Kehai Chen (陈科海), Muyun Yang (杨沐昀), Tiejun Zhao (赵铁军), Min zhang (张民)
-
1.背景介绍
类 o1 模型(o1-Like LLMs,包括 OpenAI o1 模型及阿里巴巴团队的 QwQ 、微信团队的 Marco-o1 和近期火爆的 DeepSeek-R1 等模型)以其强大的推理能力而闻名,在扩展测试中表现出类似人类的深度思考,能够探索多种推理策略,并通过决策反思和迭代改进来完善答案。这使它们能够模拟人类解决问题的认知过程。
而多语言机器翻译(MMT)作为一项极具挑战性的任务,要求模型不仅要实现跨语言的语义一致性,还要确保在常识推理、历史和文化背景以及专用术语等方面的翻译准确性。此前大语言模型在机器翻译领域已经显示出巨大的潜力,而类o1模型在多语言机器翻译中的能力目前还没有得到系统的研究。
本研究重点关注类o1模型在多语言机器翻译任务中的表现,解决两个关键研究问题:
1)在不同的 MMT 任务中,类o1 模型的翻译性能与其他 LLM 相比如何?
2)哪些因素可能影响类o1 模型的翻译质量?
为研究类 o1 模型在不同多语言机器翻译任务中的表现,我们选择了多个类o1模型(包括闭源模型和开源模型),并将它们与 ChatGPT 和 GPT-4o 等传统 LLM 进行比较。
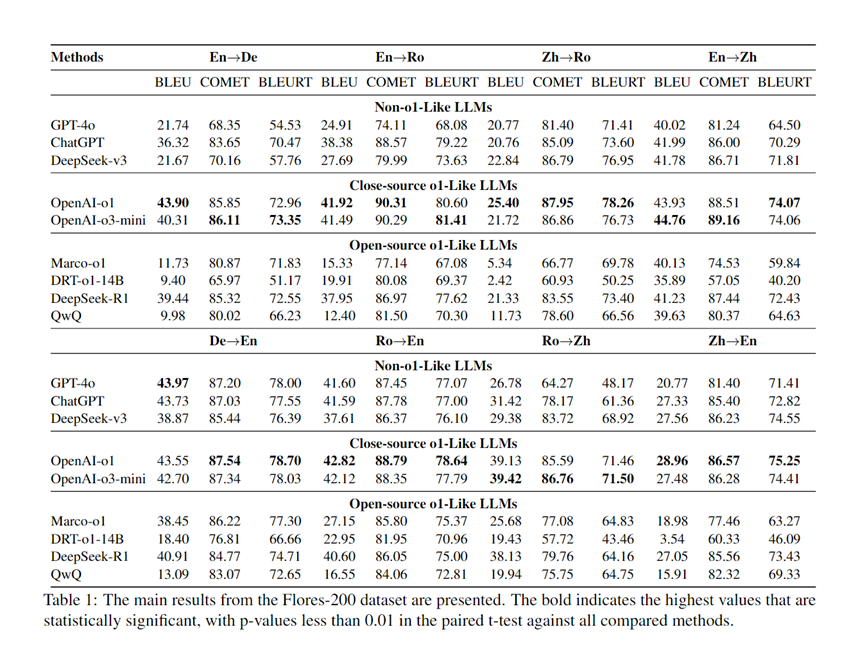
为评估类 o1 模型的多语言翻译能力,我们在 Flores-200 数据集上进行了测试。测试结果见表 1 。在多语言翻译任务中,闭源类o1模型表现最佳,尤其是 OpenAI o1,其BLEU得分最高提升了34.5。平均而言,类o1模型的BLEU分数比其他类型的模型高出11.14分。在开源模型中,DeepSeek-R1的表现最好,与其他开源LLM相比,平均BLEU得分提升约16.92。对于参数规模相对较小的开源类o1模型,例如参数分别为7B和14B的Marco-o1和DRT-o1,它们在多个翻译方向上的COMET和BLEURT指标表现接近闭源模型。未来,利用小参数的开源类o1模型进行多语言翻译是一个很有前景的研究方向。
此外,在实验过程中,我们发现 类o1模型在 COMET 和 BLEURT 分数上的提高比在 BLEU 分数上的提高要明显得多。在某些数据集中,类o1模型的 COMET 和 BLEURT 分数与 LLM 分数相当,甚至超过了 LLM 分数,而其 BLEU 分数却明显低于 LLM 分数。这种现象在 QwQ 中尤为明显。对于类 o1 模型来说,由于能够进行深度思考,因此表达方式会更加多样化,甚至会使用与参考译文不同的词汇或句子结构,但仍能保留译文的意思。COMET 和 BLEURT 并不受这种多样性的影响,而是能提供更客观的评价,因此相较于 BLEU ,它们更适合于评价类 o1 模型的翻译能力。
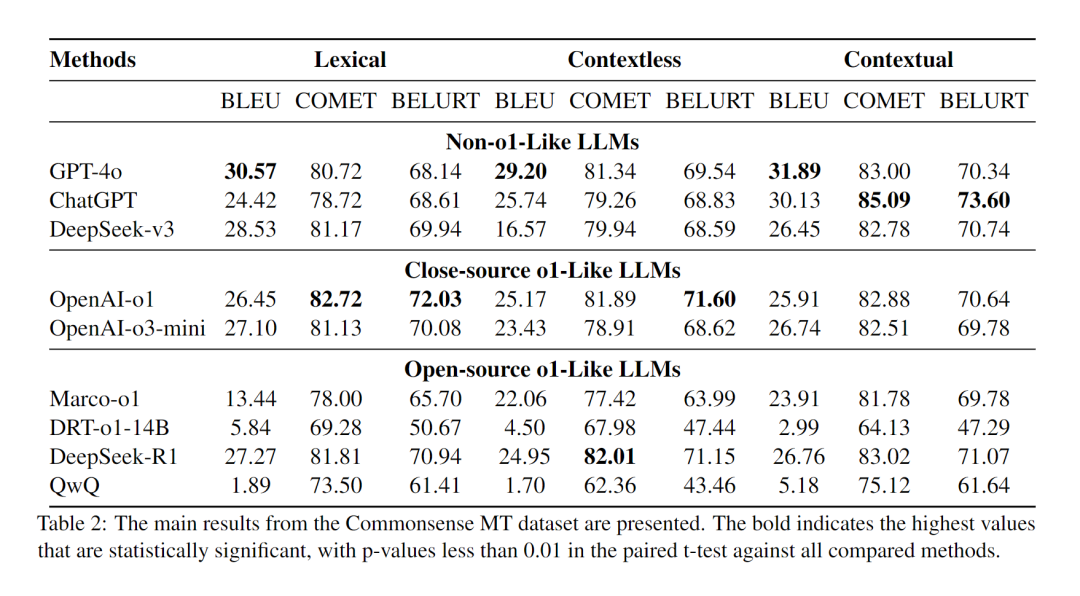
为评估类 o1 模型在常识推理翻译任务中的表现,我们使用 CommonsenseMT 数据集进行测试。测试结果见表 2 。在 Lexical 任务中,OpenAI-o1 继续表现出卓越的性能,在 COMET 和 BLEURT 指标上均优于 GPT-4o,其中 COMET 指标提高了 2.00,BLEURT 指标提高了 3.89。然而,在 Contextless 和 Contextual 任务中,传统 LLM 的表现优于类 o1 模型。通过案例分析,我们发现源文本中上下文信息的缺乏导致类 o1 模型在思考过程中产生了带有明显幻觉的译文,而传统 LLM 则不受这种内部推理的影响,其能产生更可靠的结果。对于常识推理翻译任务而言,设计有效的外部模块以减少模型推理过程中产生的幻觉至关重要。
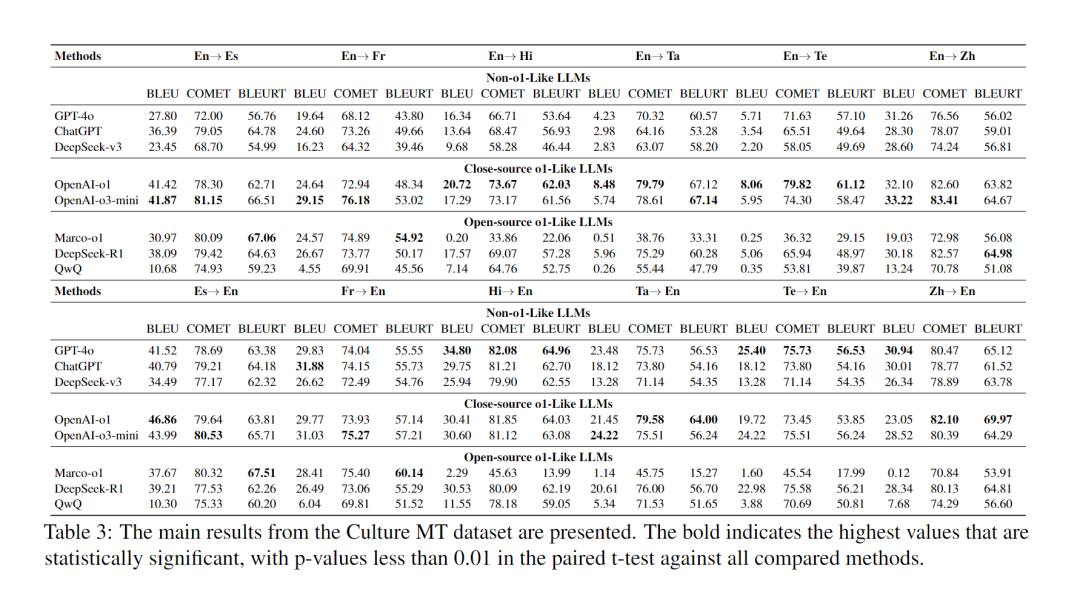
为评估类 o1 模型在翻译特定文化内容时的性能,我们使用 Culture MT 数据集进行测试。测试结果如表 3 所示。结果显示,在以英语为源语言的翻译任务中,与 GPT-4o 相比,类 o1 模型在 BLEU、COMET 和 BLEURT 方面的平均最大提升分别为 4.71、6.88 和 7.23。在以英语为目标语言的任务中,三种类型模型的表现各不相同。开源模型 Marco-o1 虽然只有 7B 参数,但在 BLEURT 指标上表现优异,与 OpenAI-o1 相比最大提高了 1.80。通过案例分析,我们观察到类 o1 模型在思考过程中自然而然地融入了对特定术语的恰当的本地化理解,从而实现了对特定术语更准确的翻译和对文化的地道表达。
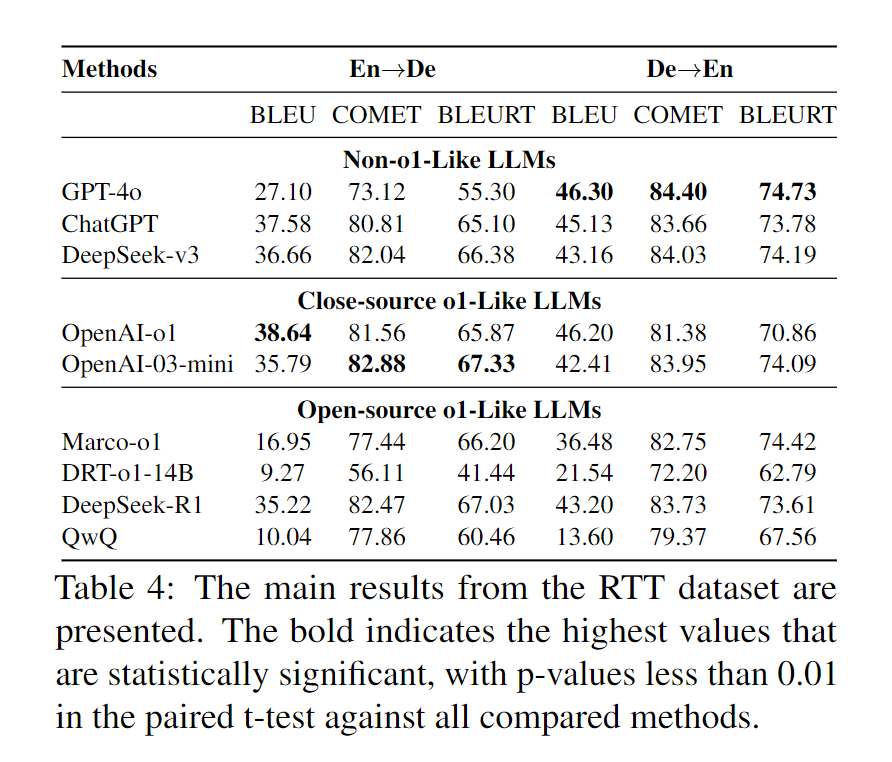
为评估类 o1 模型翻译专有术语的能力,我们使用 RTT 数据集进行了实验。实验结果见表 4 。在该数据集上,传统 LLM 表现强劲,其中 ChatGPT 在两项任务中的 COMET 和 BLEURT 上分别比类 o1 模型高约 7.67 和 8.49。我们观察到,类 o1 模型在推理过程中经常产生错误信息,这对最终的翻译结果产生了不利影响。设计外部知识结构以提高类 o1 模型的专有名词翻译性能是一个很有前景的研究方向。
3.影响类 o1 模型翻译性能的因素探究
为探究影响类 o1 模型翻译性能的可能因素,我们设计了多个分析性试验。
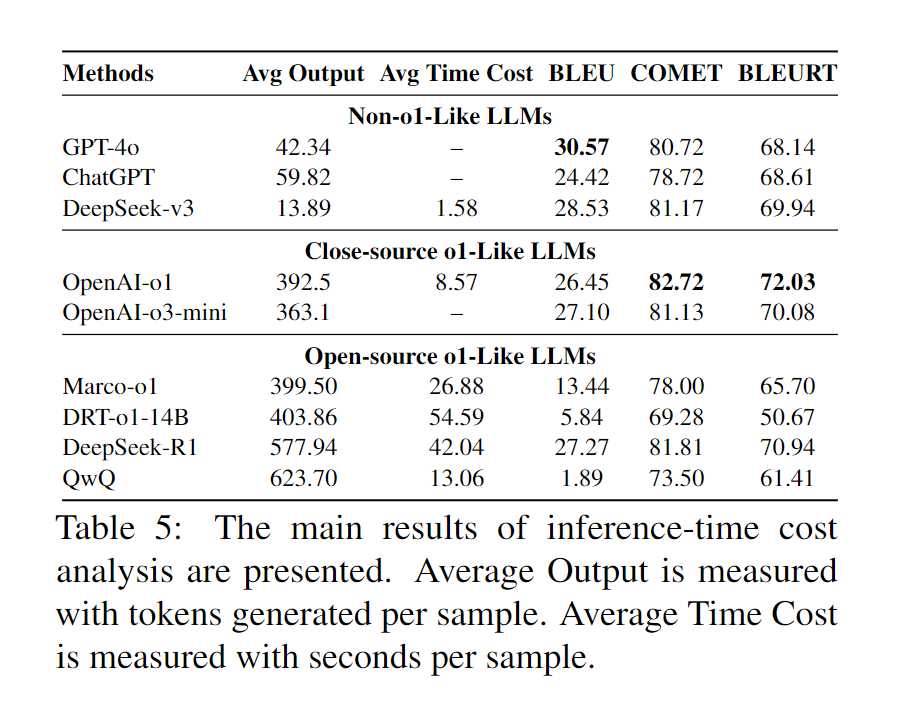
相较于传统 LLM ,类 o1 模型的推理过程明显延长,这不可避免地影响了模型的推理效率。为进一步评估类 o1 模型的翻译效率,我们对类 o1 模型和传统 LLM 的推理成本进行了比较分析。实验采用 CommonsenseMT 数据集中的 Lexical 任务。我们测量了每个模型生成的平均 token 数及其各自的生成速度,以表示每个模型的推理成本。详细结果见表 5 。
我们观察到,虽然类 o1 模型在常见推理任务中表现出卓越的性能,但它们的推理成本却高得多。与传统 LLM 相比,类 o1 模型需要的输出 token 多大约 10 倍,时间成本多 8 到 40 倍,这意味着翻译成本大幅增加。此外,思考过程需要生成更多的输出,这大大降低了推理速度。因此,这种权衡使得在翻译质量和实时性能之间实现最佳平衡变得十分困难。
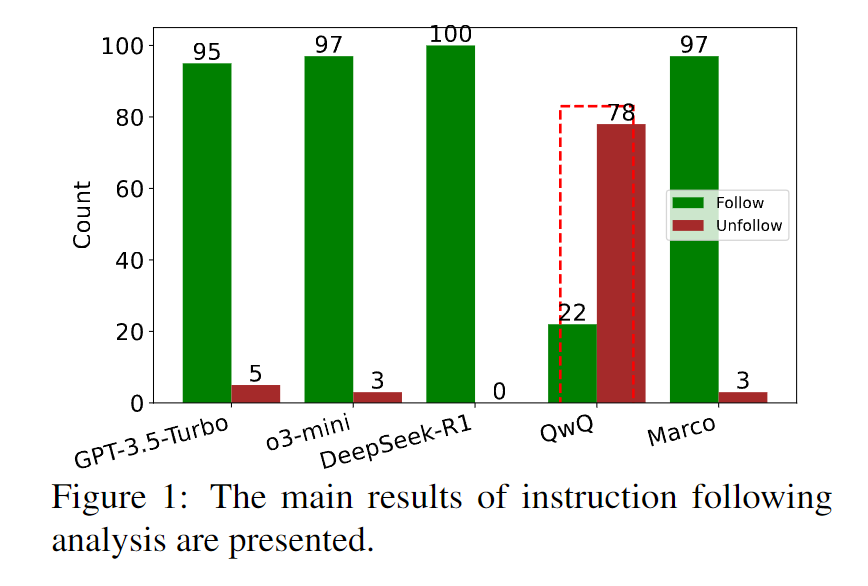
类 o1 模型的一个显著特点是其推理过程的延长。然而,如果模型不能有效地遵循指令,推理过程就会变得毫无意义。为评估每个模型的指令遵循能力,我们使用 CommonsenseMT 数据集中的 Contextless 任务进行实验,评估结果如图 1 所示。
我们观察到,尽管类 o1 模型使用了复杂的思维链示例进行训练,其仍然在有效地遵循指令方面遇到了挑战。出现指令不遵循的概率大约在 3% 到 10% 之间。 这意味着那些旨在保持 LLM 指令遵循能力的模块仍然至关重要。这些模块可用于进一步提高类 o1 模型的指令遵循能力,是未来提高类 o1 模型性能的一个重要研究方向。
此外, QwQ 模型表现出了较差的指令遵循能力,它经常会生成与源句子相关的一组句子并对其进行翻译,而不是直接翻译源句子。我们将这种现象称为 "rambling issues"(漫谈),它不仅会增加计算开销,还会降低翻译质量。图 2 中展示了一个漫谈样例,在文末的图 5 中提供了一个完整的例子。在某种程度上,如何在推理速度和翻译准确性之间取得平衡可能是未来研究的一个关键重点。
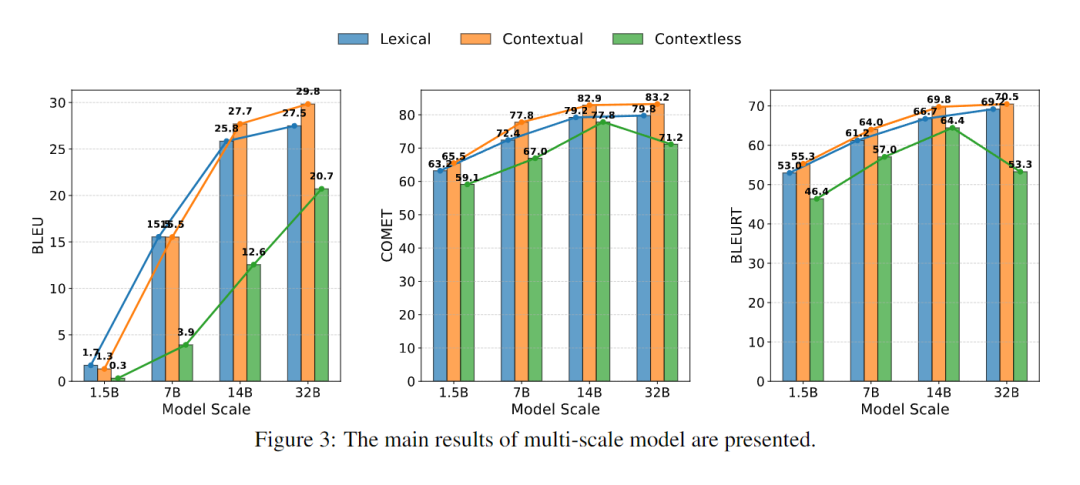
在传统 LLM 中,一般来说更大的的模型规模能提高模型相关性能。为研究类 o1 模型参数量与翻译性能之间的关系,我们使用 CommonsenseMT 数据集的 En?De/Zh/Ro 任务进行了实验,结果如图 3 所示。
我们发现参数量越大的模型往往性能越好。然而,当模型的参数数达到 10B 到20B 的范围时,进一步增加参数数只能获得边际性能提升。此外,我们还发现,在某些情况下,增加参数量会导致翻译性能的下降。
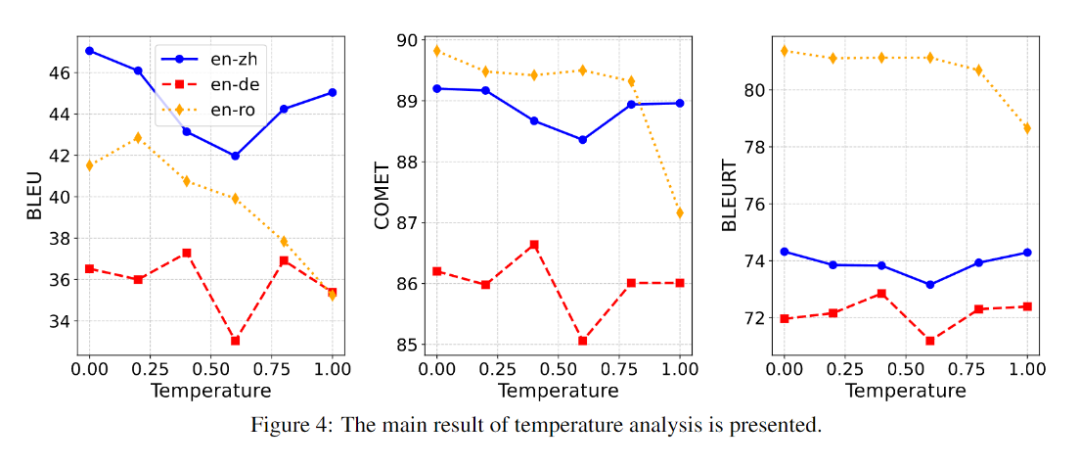
为研究温度参数对类 o1 模型翻译性能的影响,我们使用 DeepSeek-R1-671B 模型和 Flores-200 数据集进行了实验,温度设置分别为 0.0、0.2、0.4、0.6、0.8 和 1.0。结果如图 4 所示。
从结果来看,较低的温度设置有助于模型产生更稳定、更准确的翻译。此外,在不同的任务中,获得最佳性能的最佳温度也各不相同。在考虑评价指标时,BLEU、COMET 和 BLEURT 在温度变化时都表现出相似的趋势,这表明这些指标都能有效地反映模型的翻译性能。不过,它们对温度变化的敏感度有所不同。BLEU 和 COMET 的分数波动更明显,而 BLEURT 受影响较小。这种差异源于每个指标的独特性,其中 BLEURT 更适合多样化和创造性的翻译。
附:一个完整的模型漫谈(Rambling)问题的例子
一起“点赞”三连↓



 一起“点赞”三连↓
一起“点赞”三连↓