Agent时代的探索
核心抉择:自研的深度 vs. 框架的速度
-
基于框架(如 LangChain, LangGraph): -
优势:开发速度快,能迅速搭建原型。社区活跃,生态丰富。 -
挑战:高度封装可能导致灵活性不足。因此,选择一个像 LangGraph 这样“魔改”空间大的框架,就显得尤其重要。 -
纯自研(如 OpenManus,或本文解析的Trae Agent): -
优势:灵活性达到极致,能够无缝集成公司内部的各种基础设施,如统一鉴权、日志系统、监控告警等。 -
挑战:开发成本高,需要团队对 Agent 架构有深刻的理解。
生产级 Agent 的一些关键挑战
-
记忆管理:如何有效管理 Agent 的短期记忆(对话上下文)与长期记忆(用户偏好、历史知识)?如何设计高效的记忆压缩算法,在避免信息丢失和控制成本之间取得平衡?开源社区也有一些实现,Mem0, MemoryOS这些 -
会话隔离与安全:如何确保多用户之间的会话严格隔离,防止数据泄露?这让人不禁回想起几年前 GitHub 因缓存问题导致用户看到他人代码库的严重事故,这在 Agent 时代是绝对不能重蹈的覆辙。 -
上下文构建:如何处理超长上下文?更重要的是,如何通过 RAG 等技术,在海量信息中精准地为 Agent 注入当前任务最需要的知识,而不是简单地堆砌文本? -
监控与可观测性:我们需要的远不止是测量首 Token 延迟或吞吐量。如何对 Agent 的决策过程进行监控?当 Agent 犯错时,我们能否快速回溯它的“思考链”或“行动轨迹”?这正是 Trae Agent 的 Trajectory Recorder 机制所要解决的核心问题,它为 Agent 的行为提供了极佳的可观测性。这也是为什么要解析这个代码库的主要原因 -
工具选择与成本控制:当 Agent 拥有数十甚至上百个工具时,它如何决策调用哪个工具?如何在保证效果的前提下,尽可能节约 Token 消耗? -
推理效率与模型调度:如何实现成本与性能的最佳平衡?这通常涉及到一套复杂的模型调度策略:根据用户请求的难度、设定的策略(Policy)或业务规则,动态地选择调用强大的闭源模型,还是经济的开源模型,或是领域专精的垂类模型。 -
多 Agent 协作:在复杂场景下,任务需要多个各司其职的 Agent 协作完成。如何设计它们之间的通信协议(A2A, Agent-to-Agent)?如何构建一个高效的调度中心来编排它们的协作流程? -
合规性与数据安全:Agent 能看什么,不能看什么?对于全球化的产品,如何满足不同地区的地缘性合规要求?如何对用户的 PII(个人可识别信息)数据进行脱敏或加密处理?
结语:保持质疑,持续求索
步入正题:Trae Agent的解析
Trae Agent 背景
带着疑问读代码
-
基于什么框架来完成的,中间的调用过程是什么样的 -
框架强调的Trajectory是什么 -
最重要的:提示词怎么写的 -
如何评估,SWE-bench是什么?效果如何? -
我们能从里面学到了什么?
细节
基于什么框架来完成的,中间的调用过程是什么样的
-
LLM 客户端 (llm_client.py, openai_client.py 等)户端 (llm_client.py, openai_client.py 等): 一个可插拔的模块,用于与各种底层的大语言模型(LLM)API(如 OpenAI, Google, Anthropic)进行通信。 -
系统提示 (agent_prompt.py): 精心设计的 Prompt,它定义了 Agent 的角色、目标、行为准则和思考流程。这是 Agent 的“大脑”和“说明书”。 -
工具集 (tools/ 目录): 一系列定义好的、供 Agent 调用的 Python 工具,例如文件编辑 (edit_tool.py)、执行终端命令 (bash_tool.py)、结构化思考 (sequential_thinking_tool.py) 等。 -
主控制循环 (Orchestration Loop): 位于 agent/trae_agent.pytration Loop): 位于 agent/trae_agent.py 中的核心逻辑,负责管理 Agent 的整个生命周期:将用户问题和系统提示发送给 LLM,解析 LLM 返回的“思考”和“工具调用”指令,执行工具,然后将结果反馈给 LLM,如此循环往复。 -
轨迹记录器 (trajectory_recorder.py): 贯穿整个过程,用于记录 Agent 的每一步思考和行动,形成可分析的“轨迹”文件。
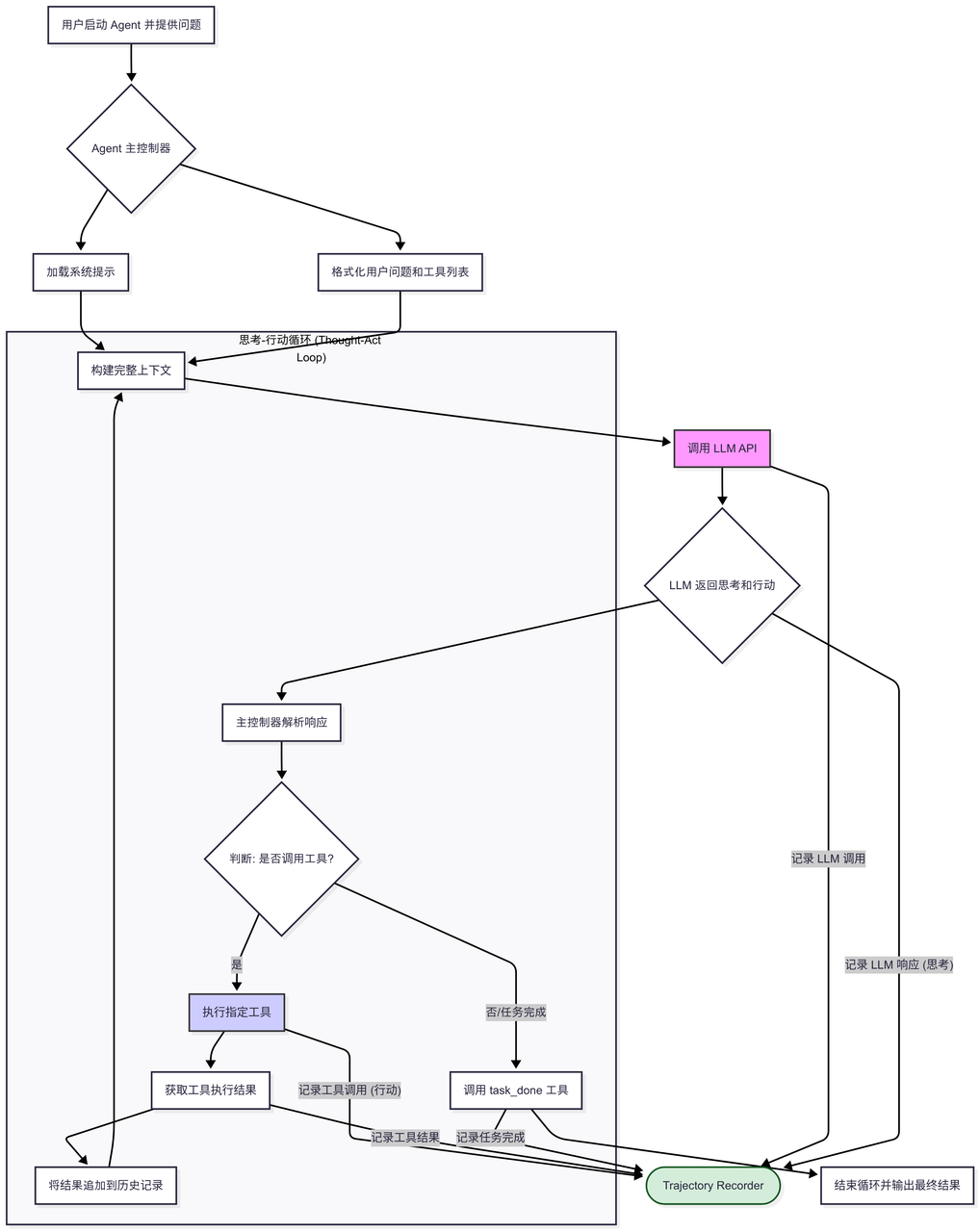
框架强调的Trajectory是什么
提示词
1. 角色与核心规则 (Role and Core Rules)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2. 主要目标与方法论 (Primary Goal and Methodology)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3. 指导原则与工具使用指南 (Guiding Principle and Tool Guides)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SWE-bench是什么?效果如何?
-
diff的文件的解决率, 要比全文的更好 -
模型更像一个偷懒的程序员,只聚焦在少量文件,不考虑复用,不考虑同类问题
学到了什么
-
Trae agent使用的swe bench的测评环境是挺巧妙的,里面涉及到docker环境的搭建,拉取git特定commit等一系列工作,并且trae agent并不是生成diff文件, 而是工具对文件进行修改, 最后生成diff文件,拿这个diff的patch去进行bench的测评,力求可以一键运行测评环境,这在生产中其实是个特别容易被忽视的地方。 -
Trajectory Recorder的实现和强制模型尽量使用sequential thinking工具的使用,虽然不太花哨,但其实也是特别重要的东西,可观测性和审计,可以去 -
SWE bench的一部分测评结果,其实实际工作中也有体感,有时cursor或者copilot生成完整代码,还不如生成一些diff的效率高,如果有时效果不好,让模型输出要更改的地方会更高效 -
读代码的时候还有个小插曲,运行不符合预期, 提交了一个简单的PR https://github.com/bytedance/trae-agent/pull/188
结尾
-
OpenAI刚刚出了一个Agent,感慨这发展快啊,也越来越朝着应用端靠拢了。Open AI在应用端也是毫无疑问的第一名 -
最近看了Open AI的一个演讲,关于如何未来如何指导软件协作的,可能未来的程序员都是确定规范,这个规范是给人看的,也是给Agent看的,Agent会确认中间的模糊地带,互相矛盾的地方,接口的定义, 这是不是一种新的swagger? -
Aws也在Agent领域卖解决方案了,感兴趣的可以去看看,都是工程上要解决的问题,国内要追上啊 -
国外的研究环境确实比国内的好一点点,在国内互联网待过的话就知道,双月okr马上就得出东西, 国外可能用户付费意愿比较强,有空间做一些探索性的产品,热钱也多,所以国外的标准多一点,框架也多,质量也高 -
实际工作中,使用大模型的体感有点像过山车,突然觉得这个东西解放了一点生产力->妄想解放更大的生产力->大模型经常生成个几百上千行,运行起来没问题,无脑apply,但是后续有些小问题,最后还得人类返工 -> 人类强监管,解放了一定的生产力,达到了平衡。 有一篇论文也讲到了:对于大型代码库来说,AI Agent反而降低了程序员20%的生产力
相关文章
最实用、最热门的AI 工具大全AI 工具导航,帮助你在工作与学习上更轻松有效率。在网路上众多 AI 与 ChatGPT 工具中,我们亲自试用并挑选了最有有用的,分成 20多个大类别,让你轻松找到所需的 AI 工具。
