
 ,人家输入是声音,因为它是ASR
,人家输入是声音,因为它是ASR传统自回归文本模型(如GPT/Llama)
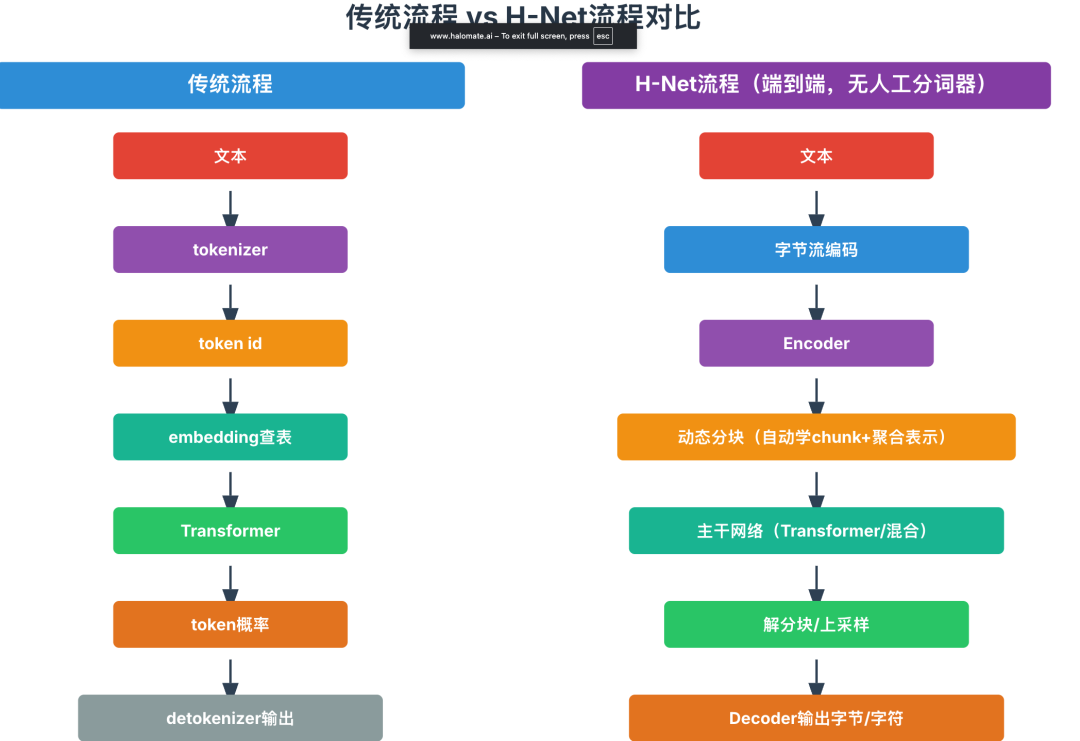
原始文本 → tokenizer切分 → token id序列 → embedding → Transformer → 输出概率/预测下一个token
文本 → tokenizer → token id → embedding → 模型生成token id → detokenizer(还原文本)
1. 词表构建机制决定的“偏见”和局限
-
大部分主流tokenizer(BPE、WordPiece等)是基于英文语料统计频率自动生成“片段” (tokens/subwords),词表中每个条目是按常见性排序和合并出来的。 -
这会导致词表里绝大多数都是英语常用词、前缀、后缀,以及特殊分隔符,对别的语言(中文、阿拉伯文、俄语)、编程代码、emoji、数学符号等覆盖不全,兼容性低。
2. 非英文/多语言适应困难
- 词表是静态的且容量有限,比如GPT-2的vocab仅5万-6万个而已
。英文组成大都在其中,其他语种即便包含,也非常零散或拆分得特别碎。 -
比如中文,往往被拆成单字(明/天/去/看/书),或者出现大量 UNK(未登录词)或‘##’前缀的生僻合成,而不是自然分词和表达。 -
罕见符号/扩展字符/emoji/古文字等,因为词表没收录,只能用char级别或fallback(拆为u8字节)编码成很多token,表达效率极低。
3. 新词/热词/代码/专业类token的弱势
-
领域专有名词(如新科技名词、代码单词、化学式等)未进入初始词表时,只能被拆为很多“字符”或“常出现的前缀/后缀”碎片,模型难以捕捉其整体语义; -
代码文本常见变量、内置语法结构、斜杠点等符号,传统tokenizer未专门优化,往往拆的四分五裂,远不如直接字符/字节级处理。
4. 多语言词表扩展的工程复杂性
-
为了多语言LLM,多数方案要显式加大词表,或多人手动挑选token,但词表容量越大,embedding参数爆炸,推理速度也会下降,说到扩词表,比如4o当时上市的时候都干到15万左右了,大家还觉得它整挺好,它其实非常无奈,完了为了维护多模态,又得压缩,导致一个长词对应一个token id,才有了那时候的一些小bug,感兴趣的各位自己去找当年的新闻。 -
有些词永远用不上,冗余空间浪费;而新加入的热词又需要重新训练embedding才能学出属性。
-
特点是词表极小(只需覆盖所有常见字符或字节),无须分词器,OOV问题天然不存在,对语种/符号极友好,即使所有中文字、标点都可编码进固定的小字表(7000常用汉字以内都能轻松搞定) -
旧的LSTM/char-RNN/ByT5等都是纯char-level(或byte-level)。

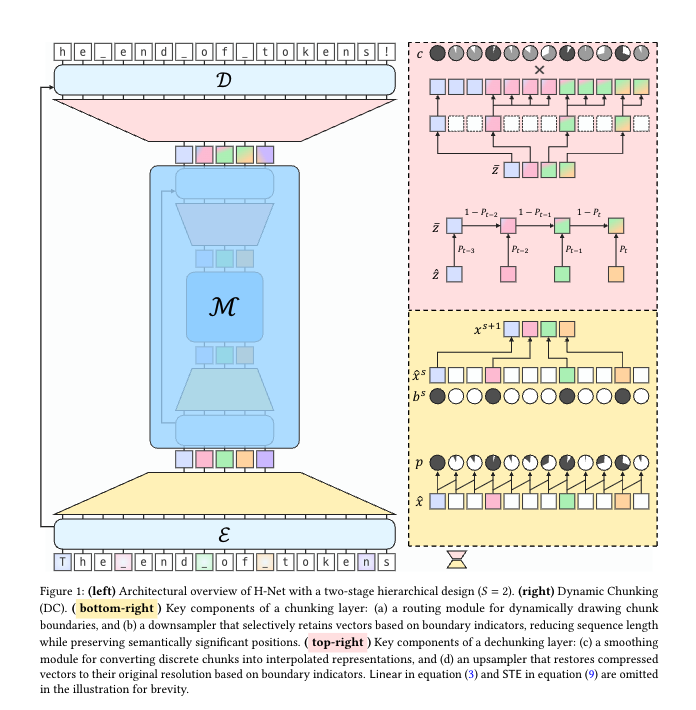
H-Net总体架构
核心思想:创造支持“动态分块机制”(Dynamic Chunking, DC)的层次化神经网络(H-Net),让模型自己端到端学会:哪里是有意义的边界,该怎么自动分段、压缩和聚合输入序列。
1. 架构图如上面的图
-
原始字节输入 (从下面网上面看)→ 编码器(Encoder)做初步字节级embedding(这也可以用Mamba SSM层,线性注意力,当然也可以transformer); - 动态分块模块(DC)
模型自适应“切片”输入序列,按上下文/内容决定block(被分词的)位置。 -
主干网络(Main Network):主要参数集中于此,对已被压缩的chunk序列做深度建模(高语义、长距离依赖捕获)。 -
解分块(Dechunking):用上采样/smoothing等方法,将高层chunk输出重新映射回细粒度token,供解码器(Decoder)输出。
2. “分块”与常规分词对比:
我们用一个具体例子来说明H-Net的动态分块(Dynamic Chunking,DC)机制是怎么“自动检测上下文变化”并形成chunk的。
示例文本
假设输入文本为:"The end of tokens."
1. 传统tokenizer分割
例如使用BPE等,会直接把它分为
["The", "end", "of", "tokens", "."]
2. H-Net动态分块的流程与输出
第一步:编码各字节/字符
输入会转成:["T", "h", "e", " ", "e", "n", "d", " ", "o", "f", " ", "t", "o", "k", "e", "n", "s", "."]
每个字符/空格/符号作为一个输入位置,初步embedding。
第二步:模型自动“判别”边界概率
H-Net的routing module会对每两个相邻embedding进行相似度测量(比如用余弦相似度),如果发现:
["d", " "](即“单词结束后是空格”)、["s", "."](单词结束遇到句号)等位置,embedding变化大(语法/语义上有明显切换),相似度低,边界概率高!["e", "n"]、“["o", "f"]”等(单词内部连续字母),相似度高,边界概率低。这样,模型经过训练后,会在如下位置分块边界概率最高(比如):
T h e _ e n d _ o f _ t o k e n s .
↑ ↑ ↑ ↑ ↑ ↑
0 0 1 0 0 1
下划线和句号后的边界概率更高
第三步:根据概率做动态分块
H-Net的downsampler会筛选出边界概率超过一定阈值的位置,比如:
-
“The end”作为一个chunk -
“of”作为一个chunk -
“tokens.”作为一个chunk
最终分块方式可能是:
["The end", "of", "tokens."]
或者更细粒度:
["The", "end", "of", "tokens", "."](这么分和BPE就一样了)
chunk的大小、边界完全由数据和上下文(而不是手工规则)自动学到,且不同上下文还能灵活变化。
第四步:聚合chunk embedding并继续建模
被判定为一个chunk的所有原始字节embedding会聚合(池化/加权等方法),形成一个chunk级higher-level embedding,进入主干网络进行高抽象推理,这快就不用讲了,因为已经进transformer了
打个比方:
- 像是在读句子的时候,你发现“这里信息切换了,和下文关联对有区分了”就自动切一刀,把前面的归为一个高抽象信息块。如果连续的内容没变化(比如单词内),就不分块。
-
你给模型的任何输入,不论语言、结构、符号,只要数据里有“信息变化点”,就可能自动形成chunk。
再举极端对照例子
-
"I love applepie"
普通tokenizer:["I", "love", "apple", "pie"],这就分错了呗,分成了 apple and pie H-Net:可能["I", "love", "applepie"] 或 ["I love", "applepie"](因为"applepie"常一起出现),这两个分都没毛病 -
代码场景:"def run_fast(x):"
普通tokenizer:["def", "run", "_", "fast", "(", "x", ")", ":"],这么分也比较扯了(当然你们大多数看不见这么差的,是因为代码量大,special token和辅助字符机制让你们不止于碰到这么离谱的,我就是举个例子) H-Net:可能["def", "run_fast", "(", "x", "):"],甚至整个函数名+参数合成chunk
所以,动态分块DC让模型“自动发现结构”,而不是简单、固定地分词或分字,大大增强了理解、压缩和表达的能力。
我们最后再做一下流程对比
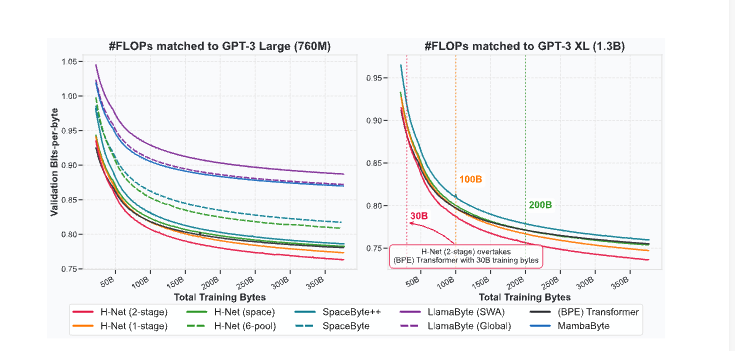
A. 语言建模主任务(英文+多语言)
1. 验证困惑度/压缩效率(BPB)
-
H-Net (1-stage): BPB ≈ BPE Transformer -
H-Net (2-stage): BPB 显著低于同算力BPE Transformer -
训练曲线显示,H-Net随数据量增加,性能提升更快,最终收敛值更低(见下图)。 
2. 多语言与代码/DNA建模
-
H-Net对中文、代码、DNA等特殊输入类型展现强大优势,尤其是没有自然token边界的文本数据。 -
中文建模时,BPB显著优于Llama3/Transformer等多语支持模型。 -
代码建模同理,chunk压缩率更高,表现优于词表法。 -
DNA建模 性能提升极大,数据效率比等参数Transformer高3.6倍(可用更少数据达到同样困惑度)。
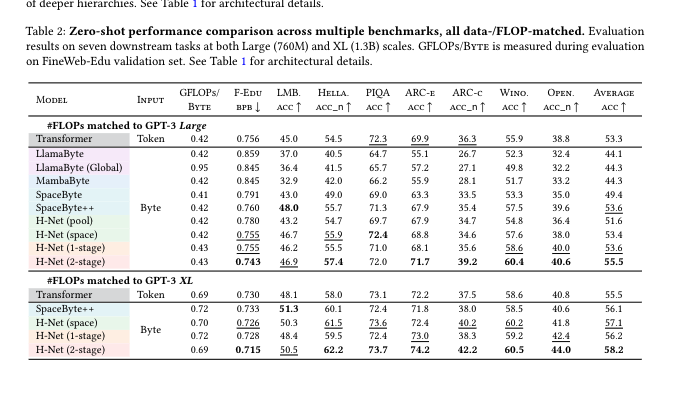
B. 下游通用任务表现
大规模zero-shot评测在LAMBADA、HellaSwag、PIQA、ARC-e、ARC-c、Winograd、OpenBook等七大benchmark任务上,H-Net(2-stage)平均分比传统BPE Transformer高2%~3%
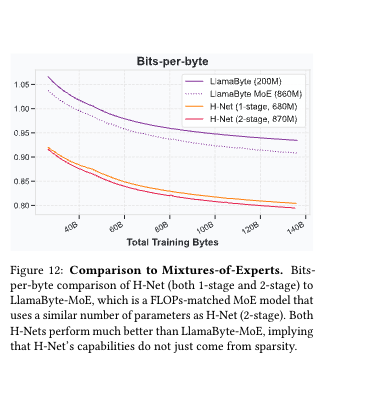
对比Mix-of-Experts(MoE) 、SpaceByte、LlamaByte等各种优化方法,H-Net也依然表现胜出,这里吐槽作者为什么方MOE,不过页能理解,虽然不是一个层面的,但是,也都是优化手段,姑且理解为主干(FFN)稀疏vs压缩冗余吧, 反正它敢比,我就敢把这个也粘过来了

C. 鲁棒性和泛化能力
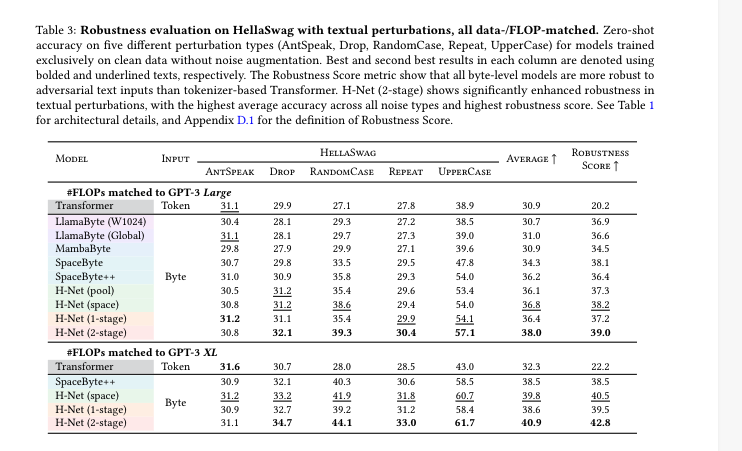
D. 数据/计算效率
相关文章
