当前阶段决定 AI Agent 好坏的关键,除了模型本身,更需要 “上下文工程(Context Engineering)” 的设计水平。
这是 Manus 团队在踩了无数坑后得出的教训:通过精巧地设计 AI 的上下文(包括记忆、工具选择、目标管理和纠错机制),可以获得更好的产品效果。但他们分享原文的中文版本可能是从英文直译成中文的,阅读起来有些奇怪。
为了方便理解,我进行了进一步的总结和整理,以便 AI 产品团队参考。并在结尾整理了一些我个人关于 AI Agent 类产品经理在产品设计中可以参考的设计策略。
一. 核心观点
- Agent 的构建是一门实验科学:不存在一蹴而就的完美架构。最佳实践来自于不断的试错、迭代和对模型行为的经验性总结。
- Agent 的行为由上下文塑造:如何设计和管理输入给模型的上下文(Context),直接决定了智能体的效率、鲁棒性和扩展能力。上下文是塑造智能体行为的核心杠杆。
- 上下文工程优于端到端微调:在产品快速迭代和市场验证(PMF)阶段,依赖大模型的上下文学习能力进行工程设计,比耗时数周的微调(Fine-tuning)更具优势。这使得产品迭代速度更快,并且能与底层模型的发展解耦,享受技术进步的红利(水涨船高,你的产品是船,而不是固定的柱子)。
注:也就是 Manus 希望用工程和架构设计能力来不断迭代产品,来赌大模型的不断升级提升产品竞争力,而不是尝试去定制模型。
二. 实际开发 AI Agent 中遇到的典型问题和优化策略
1. 问题:高延迟与高成本
Agent 在多步任务中,上下文会滚雪球式增长,导致推理延迟高、API 调用成本巨大。
Manus 的解决思路是 围绕 KV缓存 进行设计 (Design Around the KV-Cache)。将 KV缓存命中率 作为核心优化指标。通过保持提示前缀稳定、上下文只追加不修改、确定性序列化等方式,最大化利用缓存,从而大幅降低延迟和成本。
比如,不要在系统提示开头中避免使用高频变化的动态信息(如精确到秒的时间戳)。
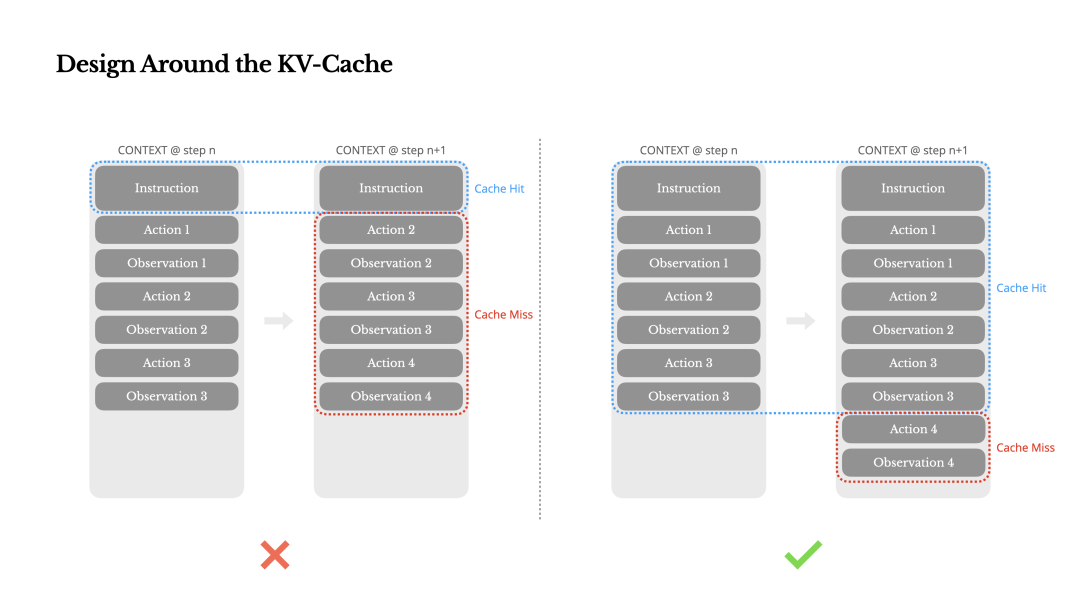
注:KV缓存 一种提升大模型生成效率的机制。
让系统把之前计算过的 Key 和 Value 存储起来。当模型生成下一个词时,它就不需要重新计算已经处理过的词的 Key 和 Value 了,直接从缓存中取出。只需要计算新生成的词的 Key 和 Value,并将其添加到缓存中。减少重复计算和提升推理速度。
2. 问题:过多可用工具导致的问题
随着 Agent 工具(可用能力)增多,模型在选择正确工具时会变得“困惑”和低效。
Manus 团队建议当需要限制智能体的可用工具时,不要从上下文中动态删除工具定义(因为这会破坏KV缓存)。而应在解码阶段通过技术手段(如 Logits Masking)通过工程设计“遮蔽”掉不可用的工具,引导模型在合法的选项内做决策。
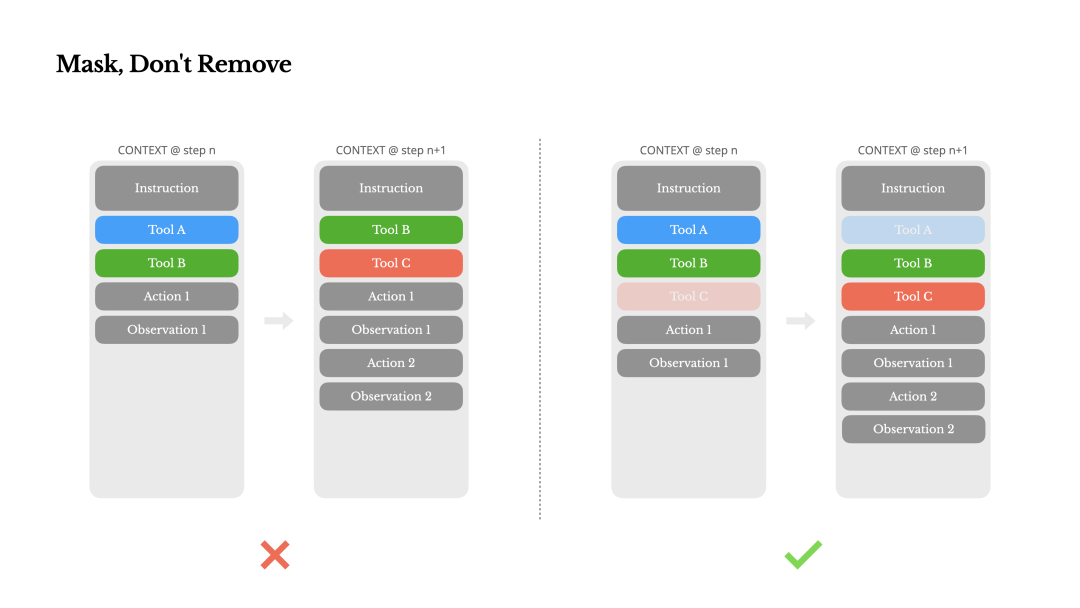
3. 问题:上下文窗口限制
即使是 128K 甚至更大的上下文窗口,在处理真实世界的复杂信息(如长文档、网页)时依然捉襟见肘,且长上下文会降低模型性能。
Manus 的思路是将 Agent 附带的文件系统视为一个无限大、可持久化的外部记忆体。
让 Agent 学会将庞大的观察结果(如网页内容)存入文件,在上下文中只保留文件路径(或者是 Url)作为“查看特定内容的指针”。
他们认为这是一种无损的、可恢复的上下文压缩策略。
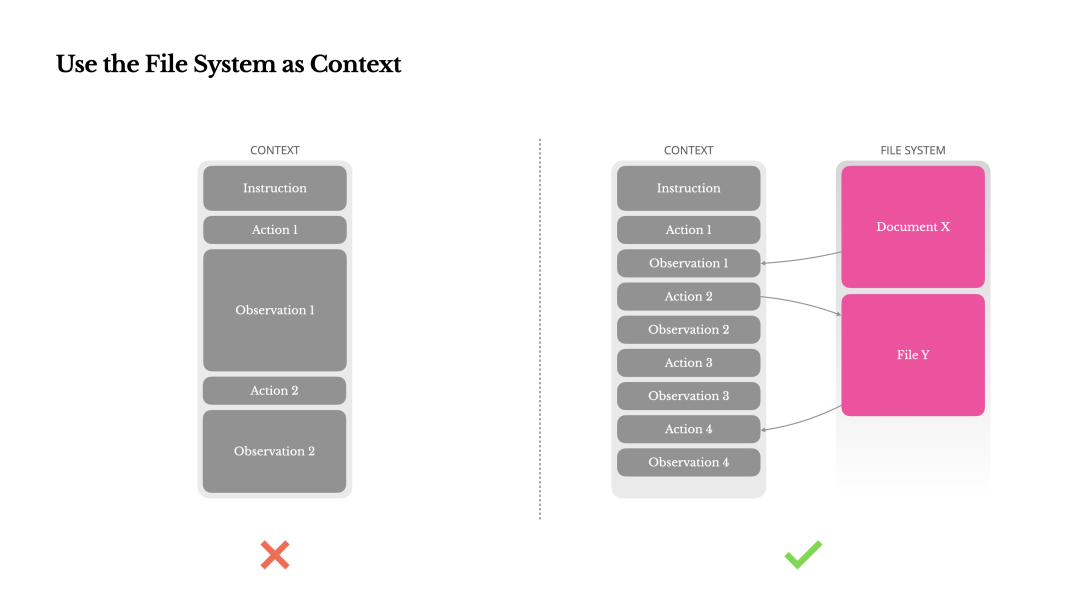
4. 问题:长期任务中忘记目标
在漫长的任务链中,Agent 容易“忘记”最初的全局目标,偏离任务主线。
Manus 的做法是让 Agent 定期地回顾和重写其核心目标或待办事项列表(比如更新一个todo.md文件)。这个动作将全局目标“复述”到上下文的末尾,利用了 LLM 注意力机制中对近期信息更敏感的特性。
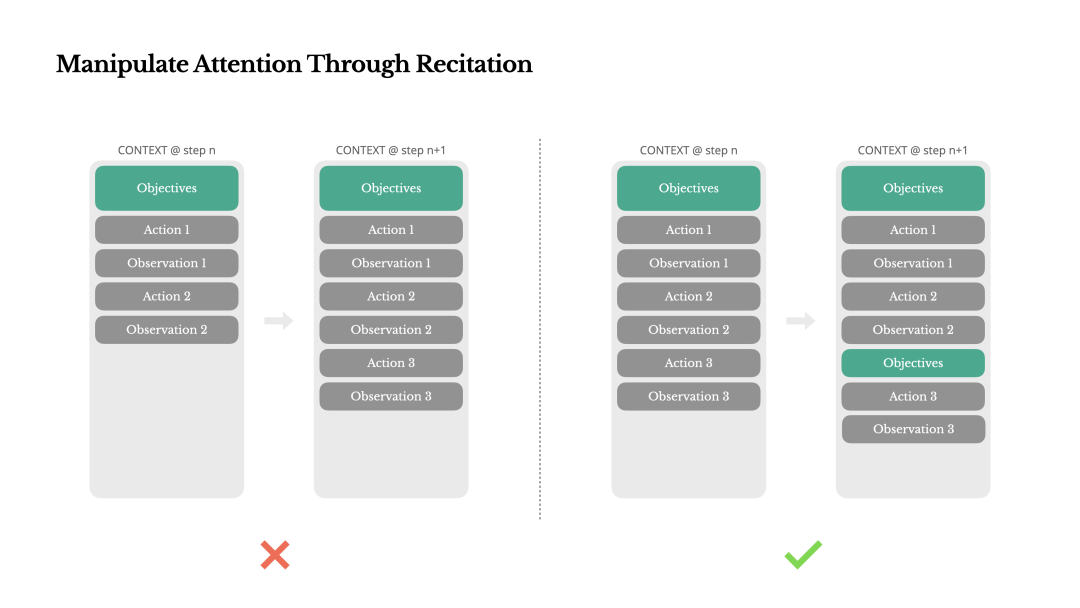
5. 问题:如何从错误中学习
Agent 在执行任务时不可避免会遇到各种错误,如何借助上下文从中“学习”而不是简单地崩溃或重试,是其是否“智能”的关键。
Manus 建议不要隐藏或删除失败的尝试(比如直接另开一个新的任务线程),而是将失败的动作和由此产生的错误观察(Error Observation)完整地保留在上下文中 —— 为模型提供负反馈的“记忆”,使其能够学习并避免重复犯错。
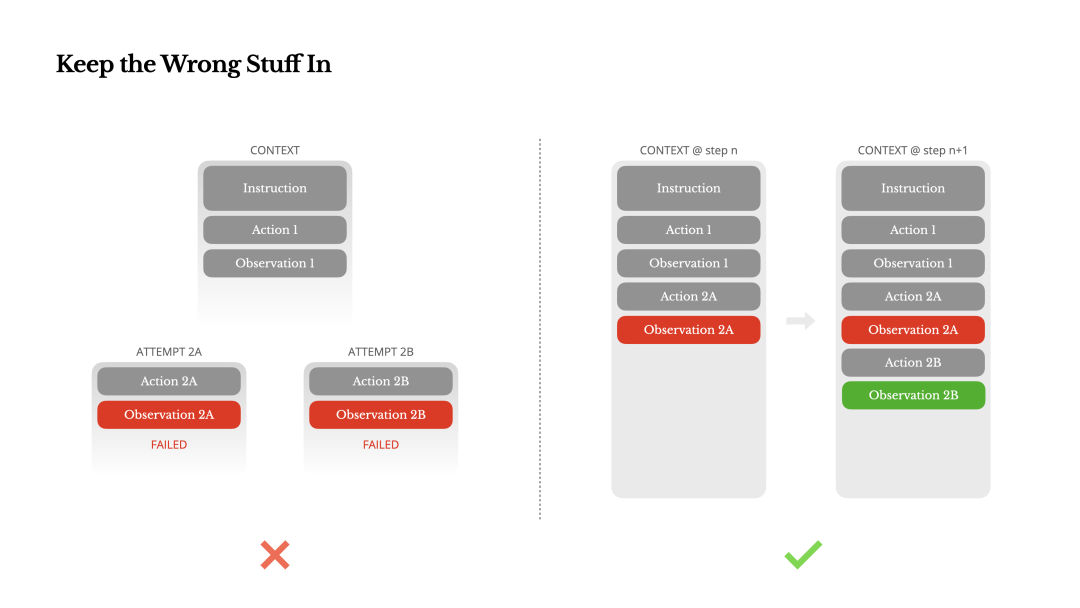
6. 问题:行为模式僵化
Agent 可能因为上下文中插入“行为-观察”这种 Few - shot 会导致出现重复模式而陷入思维定势,会机械地重复之前的行为。
所以当 Agent 执行重复性任务时,应在上下文中引入少量、可控的“噪音”或变化(如不同的措辞、格式),以打破模式,防止模型陷入机械模仿,保持其适应性。
注:这里推测应该是通过一些程序随机方式来增加微小的“噪音”。

三. 对 AI Agent 类产品经理的 Takeaway
1. 从设计功能到设计环境和信息
把 LLM 看作一个有强大潜力但需要被引导的“思考核心”,而不是一个严格按指令执行的程序流程。
将传统的工作流(Workflow)开发思维转变为更接近于“教练”或“老师”的思维模式 —— 不是追求编写精确的工作流,而是设计一个能让模型学得更好、做得更对的环境和信息流(即上下文)。并为此设计对应的功能(如文件系统,上下文策略等)
2. 从提示词技巧到上下文架构设计
大部分 AI 产品经理应该已经擅长编写提示词,了解温度和如何构建相对精确的提示词,但对于构建和设计一个需要连续执行长任务的 Agent 来说,单次交互的“提示词”远没有持续、连贯的“上下文流”设计重要。
所以不要过度追求“神级提示词技巧”,而是把思路放到构建一个上下文策略上。比如:
-
初始的 System Prompt 如何设计(给 Agent 什么样的环境)
-
任务进行中,哪些信息是“核心记忆”,需要在上下文中始终保持?
-
哪些信息是“临时笔记”,可以存到外部(如文件系统)需要时再查阅?
3. 为错误准备一些提示策略
如果你想要让通过上下文和提示策略让模型展示它的“反思”过程:“我刚才尝试了A,但失败了(因为...),现在我将尝试B”。
你需要要求要在日志和上下文管理系统完整记录失败的轨迹,并且设计对应的提示策略和输出。
4. 从功能驱动到性能成本的思考
除了关注功能(“它能做什么”),也需要关注有助于提升体验的非功能性需求(如性能、成本),并为此设计对应产品策略。
首先你需要知道 KV缓存 可以提升模型响应速度,并且显著降低成本。那么如果设计一个功能或者执行特定的任务,如果可能会频繁改变 Agent 的初始上下文,是否值得?
===
如果想和我进一步交流和讨论 AI 产品,可添加我微信:rryuliu

相关文章
