
本文来自Sebastian Raschka,介绍了building reasoning models的四种主要方法,或者如何运用reasoning capabilities来增强LLMs。
-
https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
2024年,LLM领域最显著的变化即“specialization”(专业化)的提高。我们预测这一趋势会在2025年继续加速。
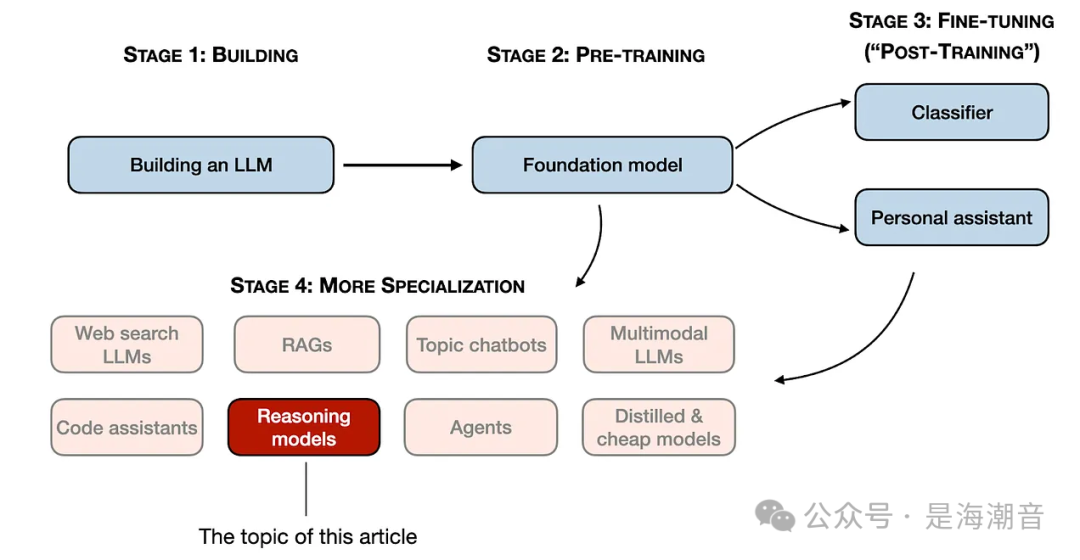
注:reasoning models后续均指 推理模型;
推理模型帮我们改进LLM,使其更加擅长通过中间步骤解决复杂问题,比如解谜,高等数学,编程挑战等。
1. How to define "reasoning model"?
“reasoning”可以看作回答问题的过程,这些问题需要复杂的、多步骤的生成和中间步骤。
例如,像“法国的首都是哪里?”这样的事实性问题回答不涉及推理。但是,像“如果火车以每小时60英里的速度行驶,行驶3个小时,它能走多远?”这样的问题需要一些简单的推理,比如在得出答案之前,需要先理解距离、速度和时间之间的关系。

现在大部分LLM都可以进行基本的推理,因此现在提到的推理模型是指擅长更复杂的推理任务的 LLM,例如解决谜题和数学证明。
同时现在大多数LLM的响应过程都包含 "thought" or "thinking" process
2. When should use reasoning models?
推理模型被设计为擅长复杂的任务,如解决谜题、高级数学问题和具有挑战性的编码任务。然而,对于更简单的任务,如摘要、翻译或KBQA,则并不需要推理模型。
而且,对所有问题都使用推理模型可能导致效率低下且成本高昂。因为推理模型通常使用更昂贵,响应时间更长,有时更容易因 overthinking 而出错。

3. A brief of DeepSeek training pipeline
-
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning:https://arxiv.org/abs/2501.12948
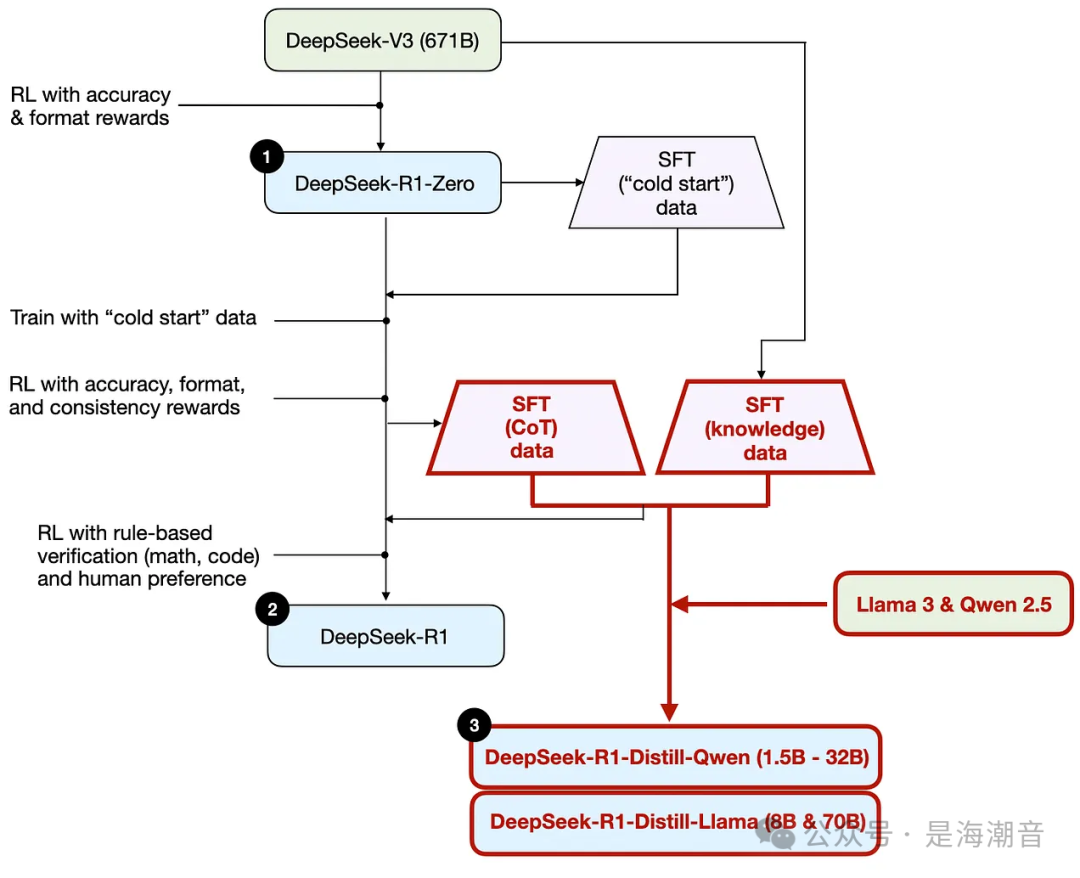
DeepSeek没有发布单个R1推理模型,而是引入了三个不同的变体:DeepSeek-R1-Zero、DeepSeek-R1和DeepSeek-R1-Distil。
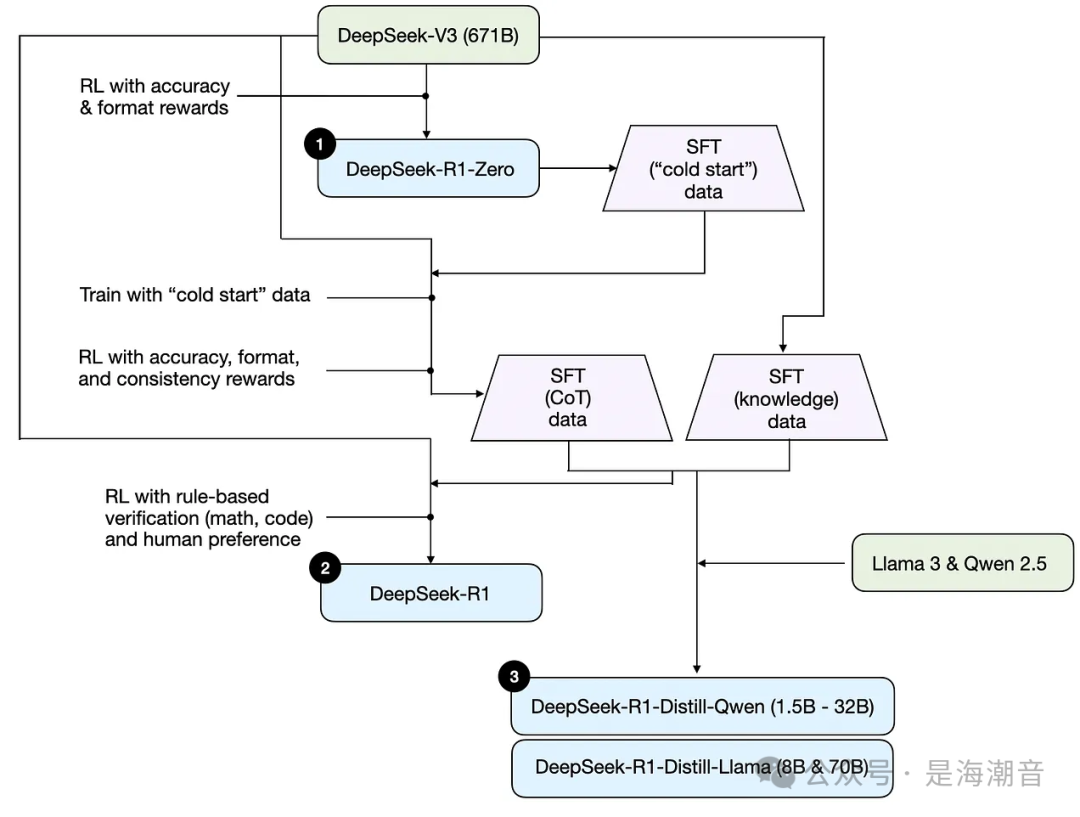
1. DeepSeek-R1-Zero
该模型基于2024年12月发布的671B pre-trained DeepSeek-V3 base model。
研究团队使用two types of rewards 的 RL 对其进行了训练。这种方法被称为“cold start”训练,因为它不包括 SFT 步骤,这通常是人类反馈强化学习(RLHF)的一部分。
2. DeepSeek-R1
这是DeepSeek的旗舰推理模型,建立在DeepSeek-R1-Zero之上。
研究团队通过额外的SFT阶段和进一步的RL训练进一步完善了它,改进了“冷启动”的R1-Zero模型。
3. DeepSeek-R1-Distill*
利用前面步骤中生成的SFT数据,DeepSeek团队对Qwen和Llama模型进行了微调,以增强它们的推理能力。
虽然不是传统意义上的蒸馏,但这一过程涉及在更大的DeepSeek-R1 671B 模型的输出上训练较小的模型(Llama8B和70B,以及Qwen1.5B-30B)。
4. The 4 main ways to build and improve reasoning models
本节主要概述目前用于增强LLM推理能力和构建专门推理模型的关键技术
1. Inference-time scaling
提高 LLM 的推理能力(或任何一般能力)的一种方法是Inference-time scaling,在这里,Inference-time scaling指在推理过程中增加计算资源以提高输出质量。
比如当有更多时间思考复杂问题时,人类往往会产生更好的反应。因此,我们可以用一些技术,鼓励 LLM 在生成答案时更多地 “think”。
-
一种直接的方法比如通过prompt engineering,比如经典的CoT prompting:"think step by step"。将鼓励模型生成中间推理步骤,而不是直接跳到最终答案,这通常会在更复杂的问题上产生更准确的结果,但非一直有效。
-
另一种方法是使用 voting and search strategies(投票和搜索策略)。一个简单的例子是多数投票,我们让 LLM 生成多个答案,我们通过多数票选择正确答案。同样,我们可以使用beam search和其他搜索算法来生成更好的响应。
推荐 Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters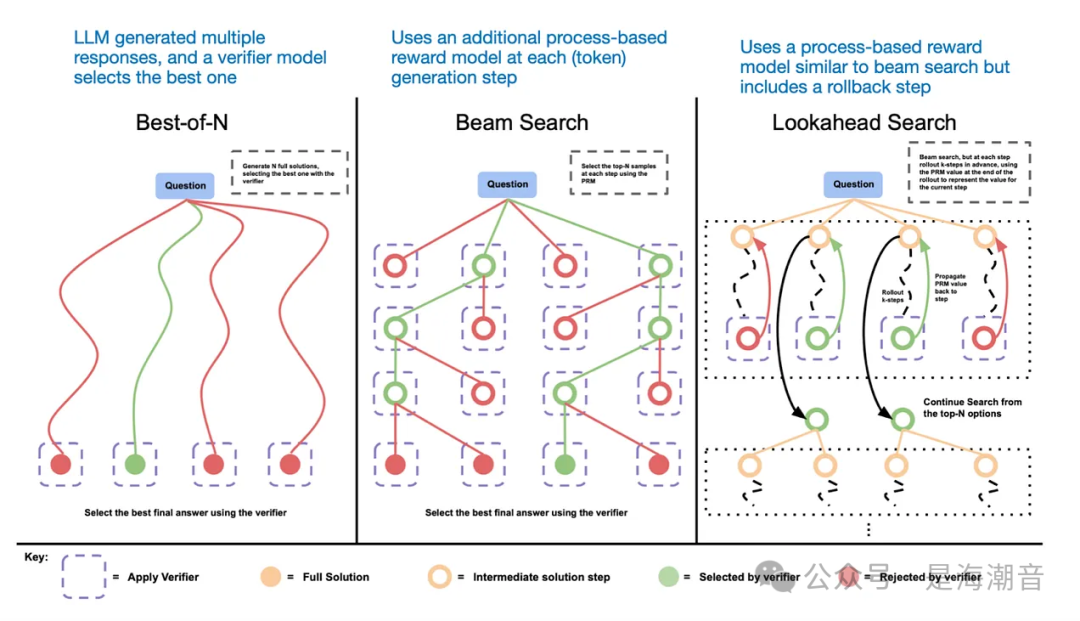
DeepSeek R1技术报告指出,其模型不使用Inference-time scaling。然而,这种技术通常在LLM之上的应用层实现,因此DeepSeek有可能在应用程序中应用。
但是OpenAI的o1,o3可能使用了Inference-time scaling,这可以解释相比较GPT-4o其模型更贵。
2. Pure reinforcement learning
与典型的 RL pipeline 不同,在 RL 之前应用 SFT,而 DeepSeek-R1-Zero 完全使用强化学习进行训练,没有初始 SFT 阶段
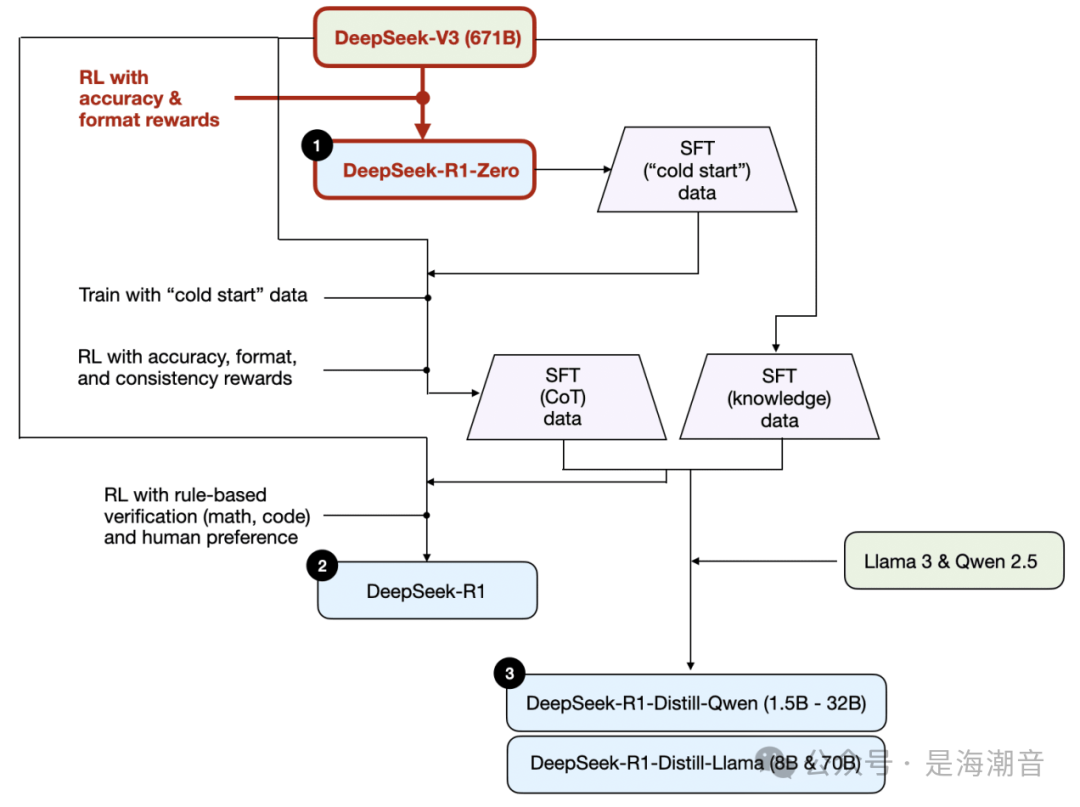
对于奖励,他们没有使用根据人类偏好训练的奖励模型,而是采用了两种类型的奖励:准确性奖励和格式奖励。
-
准确性奖励使用 LeetCode 编译器来验证编码答案,并使用确定性系统来评估数学响应。 -
格式奖励依赖于 LLM 裁判来确保回答遵循预期的格式,例如在< think>标签内放置推理步骤
这种方法足以让 LLM 培养基本的推理技能。研究人员观察到一个“Aha”moment,尽管没有经过明确的训练,但模型开始生成推理轨迹作为其响应的一部分

虽然 R1-Zero 不是一个性能最好的推理模型,但它确实通过生成中间的 “思考” 步骤来展示推理能力,如上图所示。这证实了使用纯 RL 开发推理模型是可能的。
3. Supervised finetuning and reinforcement learning (SFT + RL)
DeepSeek-R1 的开发过程,它是构建推理模型的蓝图。该模型在 DeepSeek-R1-Zero 的基础上进行了改进,加入了额外的监督微调 (SFT) 和强化学习 (RL) 来提高其推理性能。
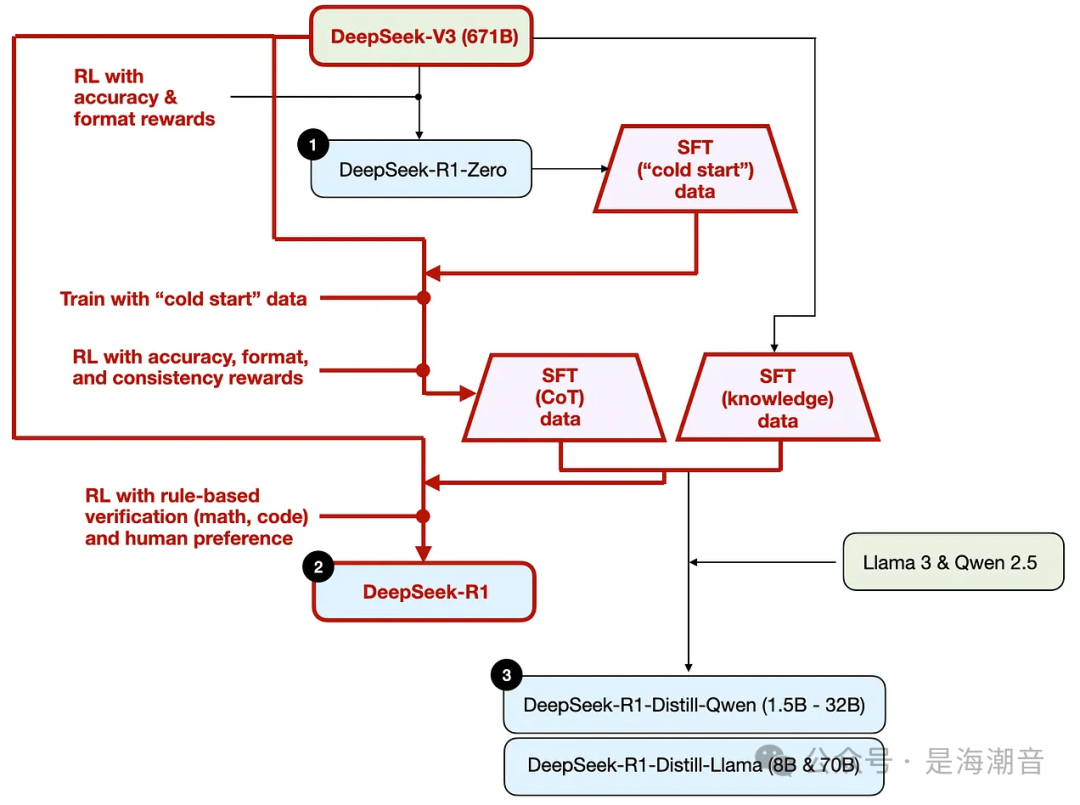
DeepSeek 团队使用 DeepSeek-R1-Zero 生成了他们所谓的“冷启动”SFT 数据。“冷启动”是指这些数据是由 DeepSeek-R1-Zero 生成的,而 DeepSeek-R1-Zero 本身没有接受过任何 SFT 数据的训练。
然后,DeepSeek 使用这些冷启动 SFT 数据,通过指令微调来训练模型,然后是另一个 RL 阶段。这个 RL 阶段保留了 DeepSeek-R1-Zero 的 RL 流程中使用的相同准确性和格式奖励。但是,他们添加了一致性奖励以防止语言混合,当模型在响应中的多种语言之间切换时,就会发生这种情况。
RL 阶段之后是另一轮 SFT 数据收集。在此阶段,使用最新的模型检查点生成 600K 思维链 (CoT) SFT 示例,同时使用 DeepSeek-V3 基本模型创建另外 200K 基于知识的 SFT 示例。
然后,这些 600K + 200K SFT 样本用于指令微调 DeepSeek-V3 base,然后进行最后一轮 RL。在这个阶段,他们再次使用基于规则的方法对数学和编码问题进行准确性奖励,而人类偏好标签则用于其他问题类型。总而言之,这与常规 RLHF 非常相似,只是 SFT 数据包含(更多)CoT 示例。除了基于人类偏好的奖励外,RL 还具有可验证的奖励。
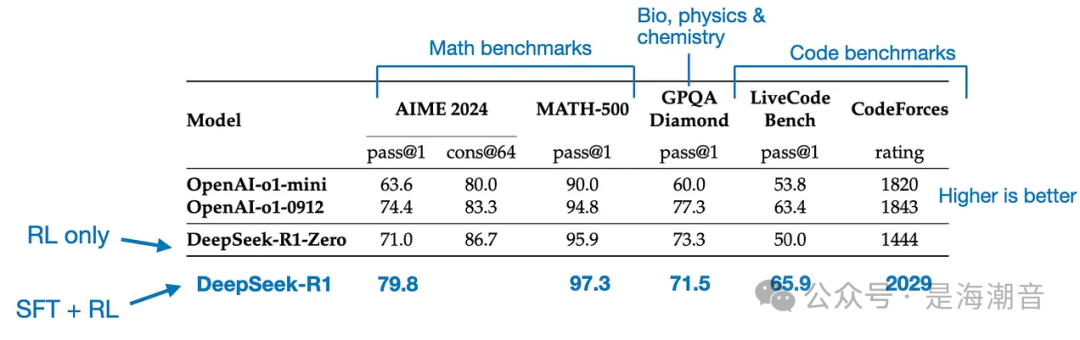
最终模型 DeepSeek-R1 的性能明显优于 DeepSeek-R1-Zero,这要归功于额外的 SFT 和 RL 阶段,如下表所示。
4. Pure supervised finetuning (SFT) and distillation
在 LLM 中,蒸馏不一定遵循深度学习中使用的经典知识蒸馏方法。传统上,在知识蒸馏中,较小的学生模型在较大的教师模型的 logits 和arget dataset上进行训练。
但是,LLM 的蒸馏是指在由较大的 LLM 生成的 SFT 数据集上对较小的 LLM 进行指令微调,例如 Llama 8B 和 70B 以及 Qwen 2.5 模型(0.5B 到 32B)。
具体来说,这些较大的 LLM 是 DeepSeek-V3 和 DeepSeek-R1 的中间checpoint。事实上,用于此蒸馏过程的 SFT 数据与用于训练 DeepSeek-R1 的数据集相同。
蒸馏这些模型的原因在于:
-
模型越小,效率越高。这意味着它们的运行成本更低,且可以在低端硬件上运行。 -
纯 SFT 的案例研究。这些蒸馏的模型是一个有趣的基准,展示了纯监督微调 (SFT) 可以在没有强化学习的情况下使模型走多远。
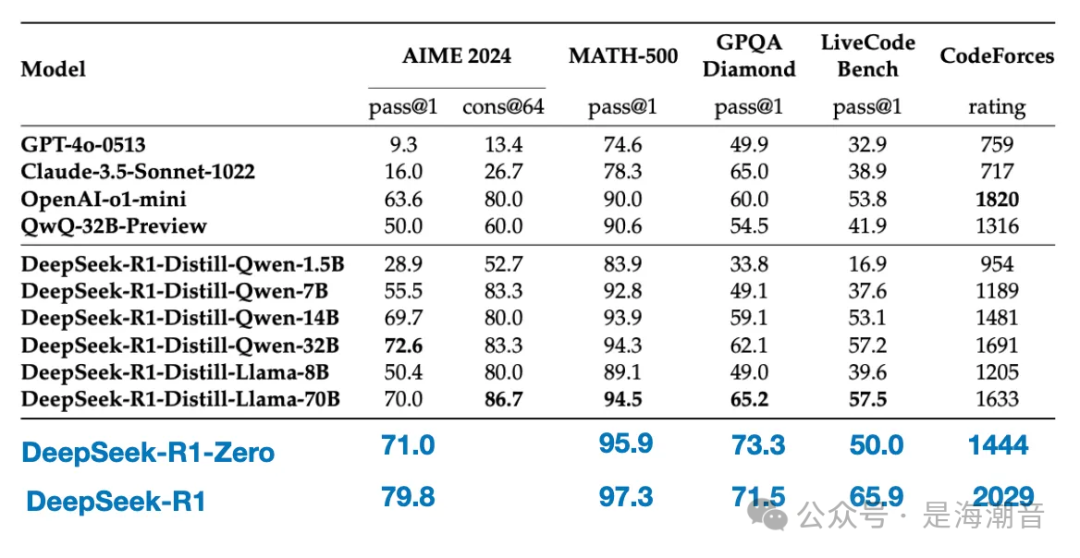
蒸馏模型明显弱于 DeepSeek-R1,但相对于 DeepSeek-R1-Zero 来说,它们却出奇地强,尽管它们小了几个数量级。
最后,DeepSeek 团队测试了 DeepSeek-R1-Zero 中看到的紧急推理行为是否也可以出现在较小的模型中。为了研究这个问题,他们将 DeepSeek-R1-Zero 的相同纯 RL 方法直接应用于 Qwen-32B。
实验的结果表明,对于较小的模型,蒸馏比纯 RL 有效得多。
Conclusion
-
推理时扩展不需要额外的训练,但会增加推理成本,随着用户数量或查询量的增长,大规模部署的成本会更高。 -
纯 RL 对于研究目的很有趣,因为它提供了将推理作为一种emergent行为的见解。然而,在实际模型开发中,RL + SFT 是首选方法,因为它会产生更强大的推理模型。 -
如上所述,RL + SFT 是构建高性能推理模型的关键方法。 -
蒸馏是一种有吸引力的方法,尤其是对于创建更小、更高效的模型。然而,其限制在于蒸馏不会推动创新或产生下一代推理模型。蒸馏始终依赖于现有的、更强大的模型来生成监督微调 (SFT) 数据。
5. Developing reasoning models on a limited budget
The good news: Distillation can go a long way
模型蒸馏提供了一种更具成本效益的替代方案。DeepSeek 团队用他们的 R1 蒸馏模型证明了这一点,尽管比 DeepSeek-R1 小得多,但该模型实现了令人惊讶的强大推理性能。然而,即使是这种方法也并非完全便宜。他们的蒸馏过程使用了 800K SFT sample,这需要大量的计算。
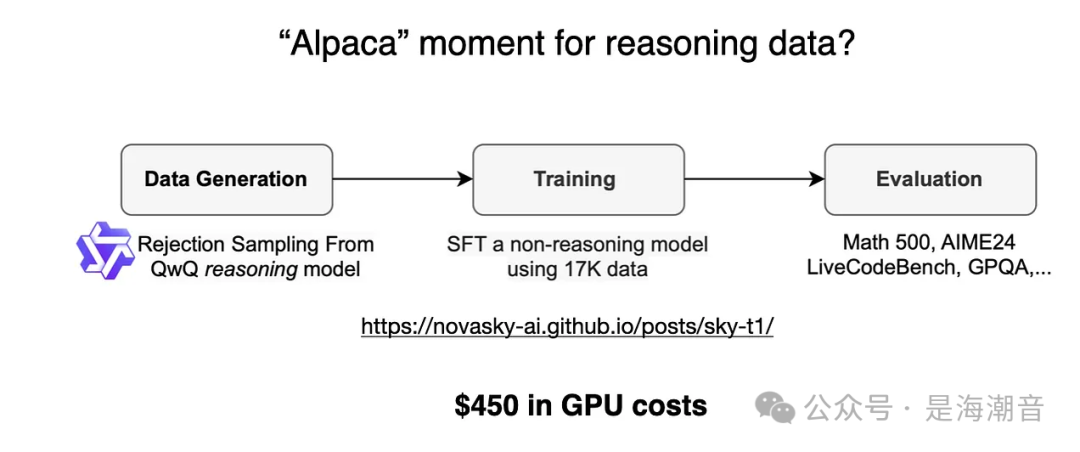 仅使用 17K SFT 样本训练了一个开源的 32B 模型。总成本只需 450 美元
仅使用 17K SFT 样本训练了一个开源的 32B 模型。总成本只需 450 美元
Pure RL on a budget: TinyZero
TinyZero,是一个复制 DeepSeek-R1-Zero 方法的 3B 参数模型(训练成本不到 30 美元)
即使只有 3B 参数,TinyZero 也表现出一些紧急自我验证能力,这支持了推理可以通过纯 RL 出现的观点,即使在小模型中也是如此。
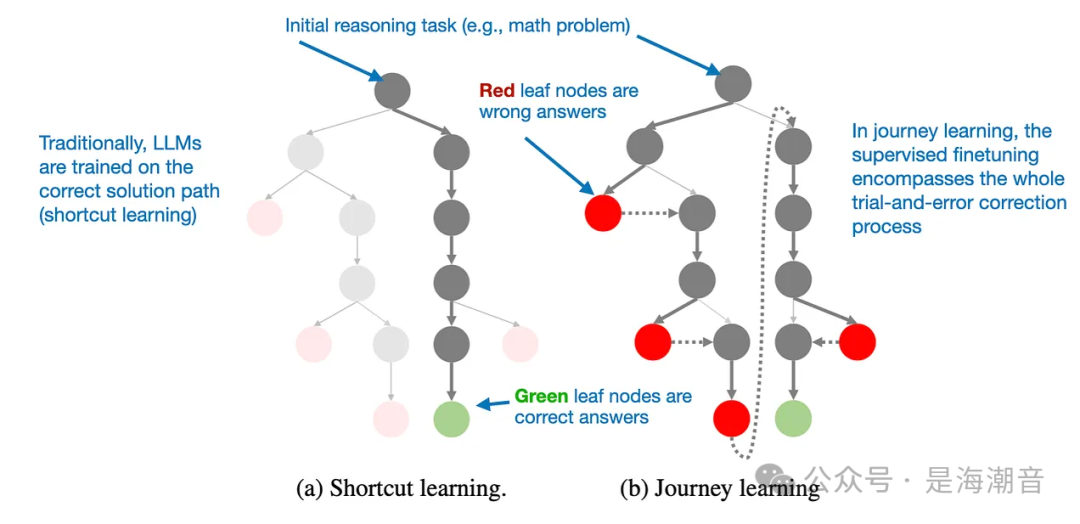
Beyond Traditional SFT: Journey Learning
这种方法与 TinyZero 的纯 RL 训练中观察到的自我验证能力有点相关,但它的重点是完全通过 SFT 来改进模型。通过使模型暴露于不正确的推理路径及其更正,旅程学习还可以增强自我纠正能力,从而可能使推理模型更加可靠。
相关文章
