Tl;DR
在学习Manus的经验教训" data-itemshowtype="0" linktype="text" data-linktype="2">AI代理的上下文工程:构建Manus的经验教训一文时,对于前两点做了一些深入的研究,发现原来在与LLM通过API交互时,有2个忽略的基础知识,如果不理清就很难理解该文中描述的具体操作。
这几天一直在整理与Multi Agent以及Context Engineering的文章,逐步理解了这两者的含义和关系,结合最近遇到的一些落地案例,特别想强调一下,在做Agent相关开发时,一定在充分分析业务的基础上,从尽可能简单的架构出发,千万不能为了用Context Engineering而去用。
补充一点:昨天Context Engineering:不要构建多代理这篇文章被转发阅读了很多次(对于我来讲已经算是爆发了),我觉得主要还是"不要构建多代理"这个标题很吸引人,在B站上关于Multi Agent视频比比皆是,都在讲怎么快速、怎么简单,但是真正做过或在做的人,一定知道其中的艰险。
什么是上下文(Context)?
“上下文窗口(Context Window)”指的是语言模型在生成新文本时可以回顾和参考的文本总量,加上它生成的新文本。这与语言模型训练所用的大型语料库不同,而是代表了模型的”工作记忆”。较大的上下文窗口允许模型理解并回应更复杂和更长的提示,而较小的上下文窗口可能会限制模型处理更长提示或在延长对话中保持连贯性的能力。
在通过API调用大模型时,上下文的内容是由调用端提供的,调用端需要在每次调用API时,将上下文的内容作为参数传入。如下图:

所有大模型在发布时,都会标明模型的上下文窗口大小,如上图所示,当上下文窗口超过模型的限制时,模型一般会截取或限制服务。
以下是一些主流LLM模型的上下文窗口大小,一般在官网都可以查询到:
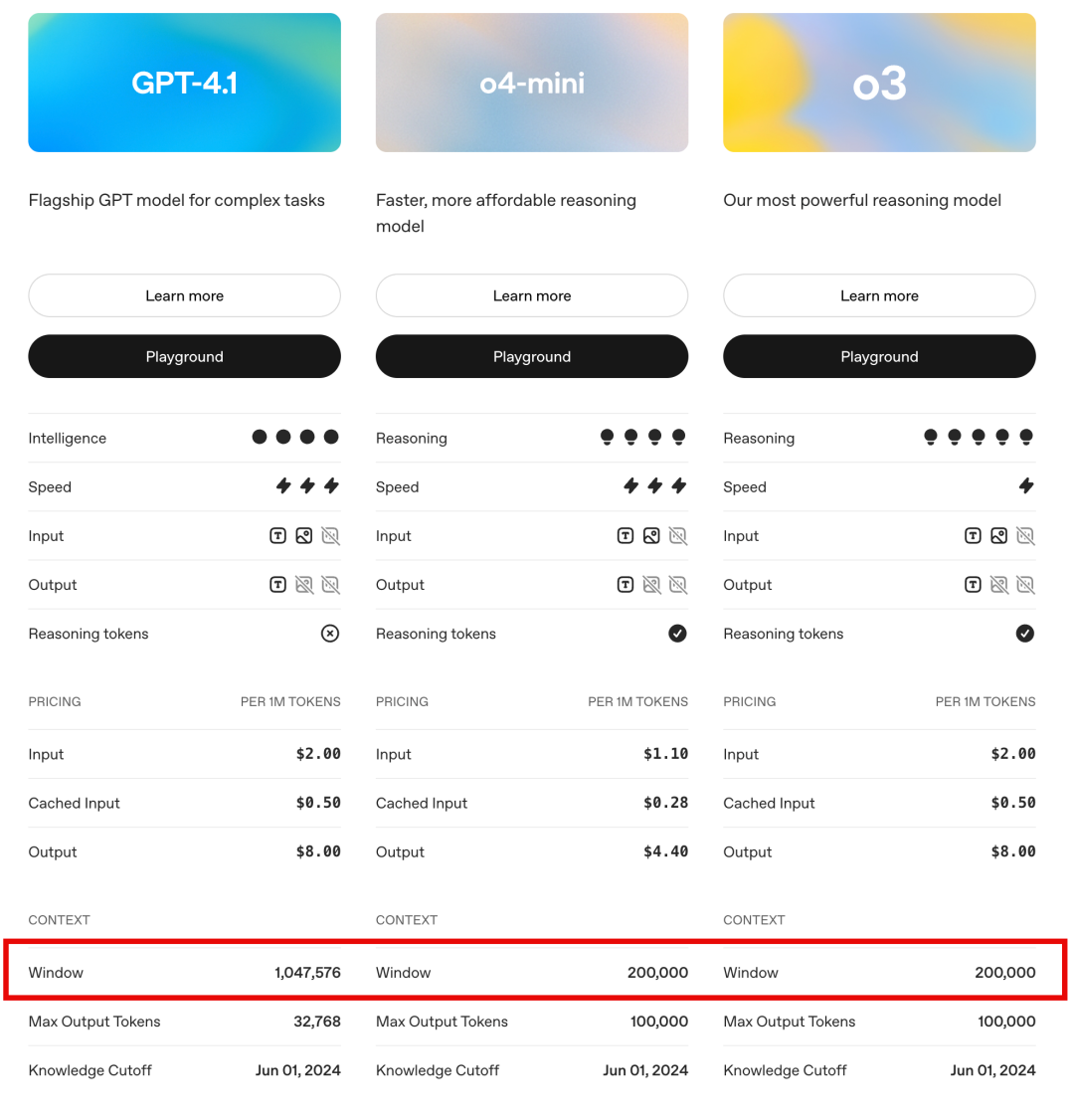
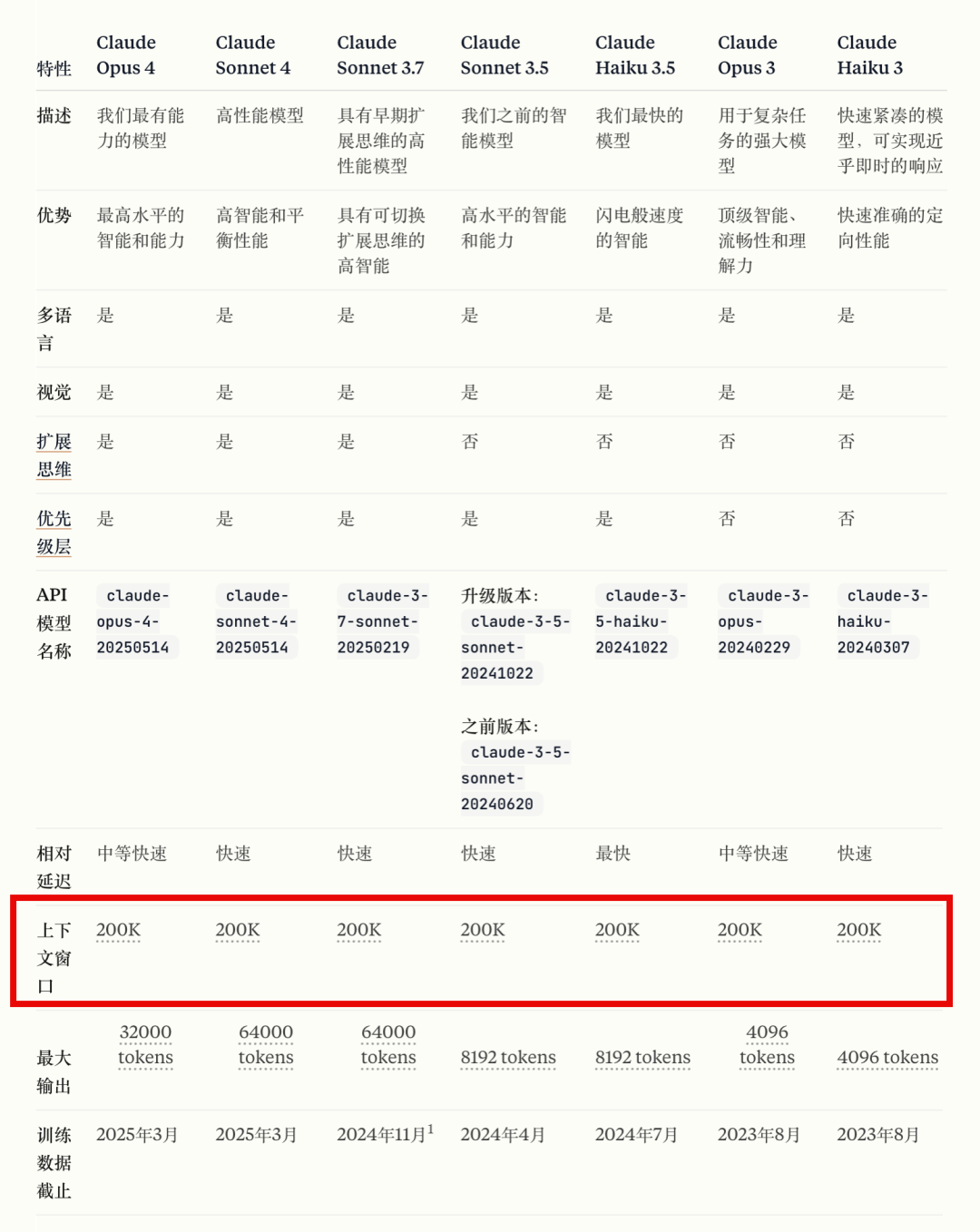
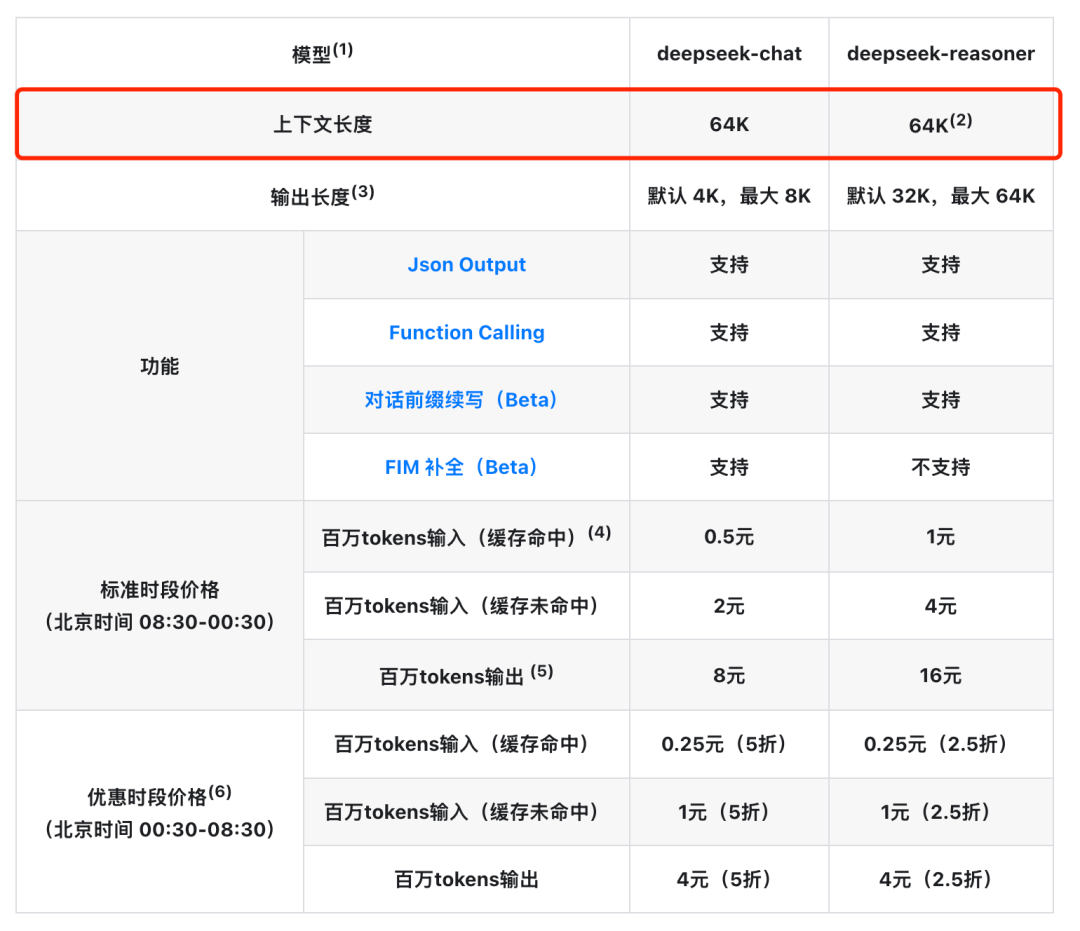
什么是KV缓存(KV-Cache)?
这个问题我问了一下Gemini,它的回答是:
从模型的内部视角(Model's Internal Perspective),LLM 的核心是 Transformer 架构,其关键是自注意力(Self-Attention)机制。为了计算下一个 token,模型需要“回顾”之前所有的 token。
-
• 没有缓存: 每生成一个新 token,都要重新计算所有前面 token 的注意力关系。这是一个非常耗时的操作。 -
• 有 KV 缓存: 模型在处理完一个 token 后,会将其关键的计算结果(Key 和 Value 矩阵,简称 KV)存储起来。在生成下一个 token 时,它只需要计算新 token 与所有“已缓存”旧 token 的关系,而无需重新计算那些旧 token 彼此之间的关系。
结论: KV 缓存是一个性能优化工具,它极大地加快了模型的推理速度(即响应速度),尤其是长文本的生成。
但是,为什么文章中,作者一直在强调:
幸运的是,具有相同前缀的上下文可以利用KV缓存[7],这大大减少了首个token的生成时间(TTFT)和推理成本——无论你是使用自托管模型还是调用推理API。我们说的不是小幅度的节省:例如使用Claude Sonnet时,缓存的输入token成本为0.30美元/百万token,而未缓存的成本为3美元/百万token——相差10倍。
这其中的推理成本可能对现在的使用场景更加关键,像最近Cursor、Claude Code等出现的订阅收费的问题,更加说明了在Agent快速发展的时候,推理成本的问题会变得更加突出。好像现在市面上,原来号称可以无限"续杯"的会员服务都在调整策略,其中最大的原因就是Agent数量庞大的Tokens消耗(在Anthropic: 如何构建多智能体研究系统文章中,Claude的工程师就提出Multi Agent系统的Token耗用量大概是普通聊天的15倍左右,这是一个非常惊人的数字)
现在主流的LLM基本都已经支持"Prompting Cache"这样的技术,在查阅Deepseek官网时,看到它对整个缓存的动作机制有清晰的描述。
下面摘取一段Deepseek官网的说明,它是以API接口中消息的顺序进行讲解的,与AI代理的上下文工程:构建Manus的经验教训一文中的缓存表述非常吻合,可以作为参考。
例一:长文本问答
第一次请求
messages: [
{"role": "system", "content": "你是一位资深的财报分析师..."}
{"role": "user", "content": "<财报内容>nn请总结一下这份财报的关键信息。"}
]第二次请求
messages: [
{"role": "system", "content": "你是一位资深的财报分析师..."}
{"role": "user", "content": "<财报内容>nn请分析一下这份财报的盈利情况。"}
]在上例中,两次请求都有相同的前缀,即 system 消息 + user 消息中的 <财报内容>。在第二次请求时,这部分前缀会计入“缓存命中”。
例二:多轮对话
第一次请求
messages: [
{"role": "system", "content": "你是一位乐于助人的助手"},
{"role": "user", "content": "中国的首都是哪里?"}
]第二次请求
messages: [
{"role": "system", "content": "你是一位乐于助人的助手"},
{"role": "user", "content": "中国的首都是哪里?"},
{"role": "assistant", "content": "中国的首都是北京。"},
{"role": "user", "content": "美国的首都是哪里?"}
]在上例中,第二次请求可以复用第一次请求开头的 system 消息和 user 消息,这部分会计入“缓存命中”。
例三:使用 Few-shot 学习
在实际应用中,用户可以通过 Few-shot 学习的方式,来提升模型的输出效果。所谓 Few-shot 学习,是指在请求中提供一些示例,让模型学习到特定的模式。由于 Few-shot 一般提供相同的上下文前缀,在硬盘缓存的加持下,Few-shot 的费用显著降低。
第一次请求
messages: [
{"role": "system", "content": "你是一位历史学专家,用户将提供一系列问题,你的回答应当简明扼要,并以`Answer:`开头"},
{"role": "user", "content": "请问秦始皇统一六国是在哪一年?"},
{"role": "assistant", "content": "Answer:公元前221年"},
{"role": "user", "content": "请问汉朝的建立者是谁?"},
{"role": "assistant", "content": "Answer:刘邦"},
{"role": "user", "content": "请问唐朝最后一任皇帝是谁"},
{"role": "assistant", "content": "Answer:李柷"},
{"role": "user", "content": "请问明朝的开国皇帝是谁?"},
{"role": "assistant", "content": "Answer:朱元璋"},
{"role": "user", "content": "请问清朝的开国皇帝是谁?"}
]第二次请求
messages: [
{"role": "system", "content": "你是一位历史学专家,用户将提供一系列问题,你的回答应当简明扼要,并以`Answer:`开头"},
{"role": "user", "content": "请问秦始皇统一六国是在哪一年?"},
{"role": "assistant", "content": "Answer:公元前221年"},
{"role": "user", "content": "请问汉朝的建立者是谁?"},
{"role": "assistant", "content": "Answer:刘邦"},
{"role": "user", "content": "请问唐朝最后一任皇帝是谁"},
{"role": "assistant", "content": "Answer:李柷"},
{"role": "user", "content": "请问明朝的开国皇帝是谁?"},
{"role": "assistant", "content": "Answer:朱元璋"},
{"role": "user", "content": "请问商朝是什么时候灭亡的"},
]在上例中,使用了 4-shots。两次请求只有最后一个问题不一样,第二次请求可以复用第一次请求中前 4 轮对话的内容,这部分会计入“缓存命中”。
综上所述,无论是处理长文档、进行多轮对话,还是利用 Few-shot 提升效果,其背后都遵循着同一个核心原则:通过保持 Prompt 前缀的稳定性来最大化缓存命中率。理解并善用 Prompt Caching 机制,已经不再是一个锦上添花的技术选项,而是未来在开发高效率、低成本 AI 应用,尤其是在构建复杂 Agent 系统时,每一位开发者都必须掌握的关键技能。
如何遮蔽(Mask)?
在Manus的论文中,第二点提到:"遮蔽,而非移除(Mask, Don't Remove)",那什么是遮蔽(Mask)呢?
“遮蔽 (Masking)” 的核心思想是:在任何时候,都将所有可能的工具定义完整地保留在模型的上下文(Context)中,但通过技术手段在模型生成(解码)的瞬间,动态地限制模型只能选择当前可用的工具。
在文章有如下的描述:
函数调用通常有三种模式(Hermes):
• 自动(Auto)–模型可以选择调用或不调用函数。通过预填充回复前缀实现:<|im_start|>assistant • 必需(Required)–模型必须调用函数,但选择不受约束。通过预填充到工具调用令牌实现:<|im_start|>assistant<tool_call> • 指定(Specified)–模型必须从特定子集中调用函数。通过预填充到函数名称的开头实现: <|im_start|>assistant<tool_call>{"name": "browser_ 通过这种方式,我们通过直接掩码token的logits来约束动作选择。 Jack,公众号:LiveThinkingAI代理的上下文工程:构建Manus的经验教训
而如果使用API调用模型时,已经有对遮蔽(Mask) 进行支持,以OpenAI的API为例:
当我们调用 chat.completions.create 接口时,可以传递一个 tool_choice 参数来精确控制模型的行为。
tool_choice 参数的作用就是告诉模型:“在这次生成中,你关于工具使用的选择空间被我‘遮蔽’了,你必须遵循以下规则”。
它有几种模式:
-
1. 遮蔽“不使用工具”的选项(强制调用工具)
这对应文章中的“必需 (Must)”模式。response = client.chat.completions.create(
model="gpt-4-turbo",
messages=my_messages,
tools=my_tools,
tool_choice="required" # 强制模型必须选择一个工具调用
) -
2. 遮蔽“所有工具”的选项(禁止调用工具)
如果你想让模型进行纯文本对话,而忽略它可能看到的工具时,可以使用这个。response = client.chat.completions.create(
model="gpt-4-turbo",
messages=my_messages,
tools=my_tools,
tool_choice="none" # 强制模型不能调用任何工具,只能生成文本
) -
3. 遮蔽“除某个特定工具外”的所有选项(强制调用特定工具)
这对应文章中的“指定 (Specific)”模式,是最强大的“遮蔽”形式。response = client.chat.completions.create(
model="gpt-4-turbo",
messages=my_messages,
tools=my_tools,
# 强制模型必须调用名为 "get_current_weather" 的函数
tool_choice={"type": "function", "function": {"name": "get_current_weather"}}
)


总结:可以看出几乎所有主流的模型都支持动态选择,tool_choice 参数(或其它命名方式,视模型而定)是 API 层面对“遮蔽”原则的直接实现。它稳定、可靠,是与 OpenAI、Claude、Gemini 或任何兼容 OpenAI API 的模型交互时的首选方法。
总结
最近的几篇文章:
-
1. Anthropic: 如何构建多智能体研究系统 -
2. Context Engineering:不要构建多代理 -
3. Context Engineering: 来自LangChain的剖析 -
4. AI代理的上下文工程:构建Manus的经验教训
都是围绕在 Multi-Agent 实施过程中,如何通过 Context Engineering 从理论走向实操的探讨。在深入这些技术细节之后,我希望分享我最核心的一点体会:警惕复杂性。
在实际的落地过程中,我深刻体会到管理和控制 Multi-Agent 系统的复杂度是项目成功的关键。这与行业顶尖公司的理念不谋而合。正如 Anthropic 在其工程建议(Anthopic:构建有效的Agent)中明确指出的:
(何时(以及何时不)使用智能体)
在构建LLM应用时,我们建议寻找最简单的解决方案,并仅在必要时增加复杂性。这可能意味着根本不需要构建智能体系统。智能体系统通常以牺牲延迟和成本为代价,换取更好的任务性能,因此您应该考虑这种权衡何时是合理的。当需要更多复杂性时,工作流为明确定义的任务提供了可预测性和一致性,而智能体则在需要灵活性和模型驱动的决策时是更好的选择。然而,对于许多应用来说,通常通过检索和上下文示例优化单次LLM调用就已足够。
这段话清晰地告诉我们一个朴素的真理:技术是工具,而非目标。智能体(Agent)只是我们工具箱中的一个强大选项,但它有明确的适用场景和需要付出的代价——延迟、成本,以及不可预测性。
因此,在面对眼花缭乱的新技术时,请务必保持清醒与克制。千万不要为了技术而技术。 回归工程的本源,让真实的业务价值,成为驱动你技术选型的唯一核心。
相关文章
