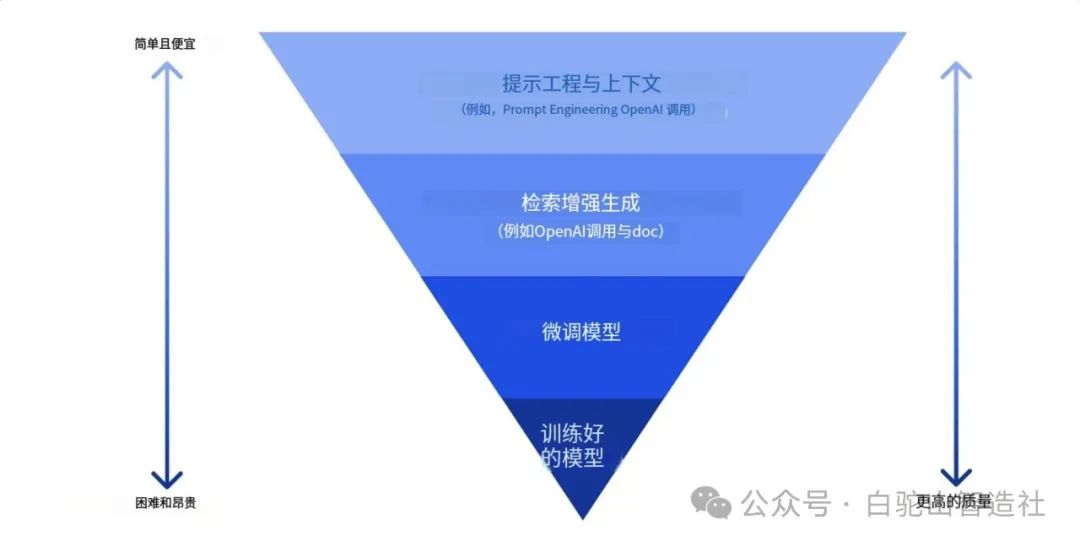
企业可以使用多种方法来从 LLM 获得所需的结果。在生产中部署 LLM 时,您可以选择不同类型的模型,这些模型具有不同的训练程度,复杂度、成本和质量水平也各不相同。以下是一些不同的方法:
提示工程并附加上下文。这样做的目的是在提示时提供足够的上下文,以确保您获得所需的响应。
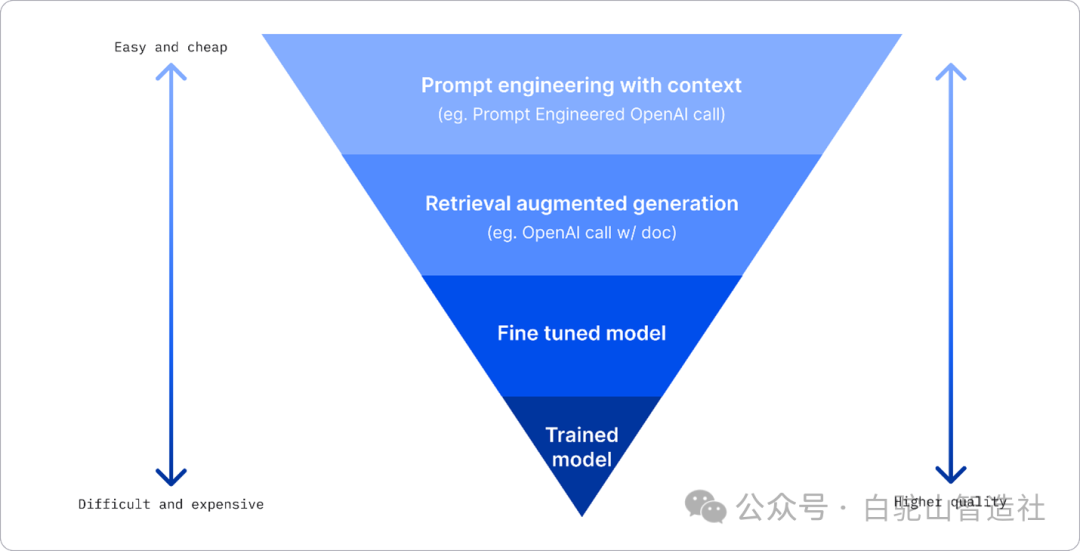
检索增强生成 (RAG)。例如,您的数据可能存在于数据库或 Web 端点中,为了确保在提示时包含此数据或其子集,您可以获取相关数据并将其作为用户提示的一部分。
微调模型。在这里,您可以根据自己的数据进一步训练模型,从而使模型更加精确,更能满足您的需求,但成本可能较高。
利用上下文提示工程
预先训练过的 LLM 在通用自然语言任务上表现非常出色,甚至可以通过一个简短的提示来调用它们,比如要完成的句子或问题——即所谓的“零样本”学习。但是,用户越能用详细的请求和示例(即上下文)来组织他们的查询,答案就越准确,也越接近用户的期望。在这种情况下,如果提示仅包含一个示例,我们称之为“一次性”学习,如果包含多个示例,我们称之为“少量学习”。使用上下文进行提示工程是最具成本效益的启动方法。
检索增强生成 (RAG)
LLM 的局限性在于,它们只能使用在训练期间使用过的数据来生成答案。这意味着它们对训练过程后发生的事实一无所知,也无法访问非公开信息(如公司数据)。这可以通过 RAG 来克服,这是一种在考虑提示长度限制的情况下,使用文档块形式的外部数据增强提示的技术。矢量数据库工具(如Azure 矢量搜索)支持此功能,这些工具从各种预定义数据源中检索有用的块并将其添加到提示上下文中。
当企业没有足够的数据、足够的时间或资源来微调 LLM,但仍希望提高特定工作负载的性能并降低捏造风险(即神秘化现实或有害内容)时,此技术非常有用。

微调模型
微调是一种利用迁移学习使模型“适应”下游任务或解决特定问题的过程。与少样本学习和 RAG 不同,微调会生成一个新模型,并更新权重和偏差。它需要一组由单个输入(提示)及其相关输出(完成)组成的训练示例。如果符合以下条件,则这种方法是首选方法:
使用微调模型。企业希望使用经过微调、功能较差的模型(如嵌入模型),而不是高性能模型,从而获得更具成本效益和更快速的解决方案。
考虑延迟。延迟对于特定用例很重要,因此不可能使用很长的提示,或者应从模型中学习的示例数量不符合提示长度限制。
保持最新状态。企业拥有大量高质量数据和基本事实标签,以及维持这些数据随时间保持最新状态所需的资源。

训练大模型
从头开始学习训练大模型无疑是最困难、最复杂的方法,需要大量数据、熟练的资源和适当的计算能力。只有在企业拥有特定领域的用例和大量以领域为中心的数据的情况下,才应考虑此选项。
相关文章
