前言
上一篇《AI Agent:大模型落地应用的“最后一公里”?》从理论分析角度谈了谈AI Agent在应用落地方面的可行性和前景,本篇就从技术实战角度来看看如何在生产环境构建一个AI Agent框架。
这篇文章有较大的技术难度,适合有一定工程经验的人员。
目前在AI领域,最炙手可热的程序语言当属Python,以其简洁轻量,获得了无论是在模型训练还是在跟模型交互方面的主导地位。打开各个LLM的文档,提供的官方SDK通常也都是Python或者JS,这让Java显得有点被冷落了。后面会写一篇文章讲一讲,在AI时代,曾经火热的Java框架王者Spring的一丝落寞。
但是目前在工业生产业界,Java还是当仁不让的第一语言,无论是官方文档还是网上博客,貌似都少有涉及Java的AI Agent的实现方式和原理的解析。本篇实战就准备以Java为例,讲一下如何封装一个AI Agent框架。
AI Agent的实现底层,依赖大模型的ToolsCall能力(FunctionCalling的升级),那么首先先介绍一下ToolsCall。
一、ToolsCall简介
1. 大语言模型(LLM)的能力边界
1)LLM没有真逻辑
LLM表现出来的“逻辑”是基于文本的统计概率,不是真正的逻辑,因此才会出现那个经典的错误:9.11和9.9哪个大?
2)LLM数据滞后,没有私有数据
既然是基于文本统计概率,那么LLM的能力取决于预训练的数据规模和质量。训练数据欠缺垂类的、非公开的数据,也不可能知道实时的最新信息。
3)存在幻觉,欠缺精确性
同样的输入问题,LLM的响应通常也不会保证一致,LLM的响应存在一定的随机性和错误。这极大地限制了将LLM深度嵌入集成到工程化项目和系统中。所以也导致当前我们常见的LLM based产品通常都是面向B端或者处于业务链路最下游,比如问答、生图、图片增强、语音识别、翻译等,这些应用的显著特点之一就是对于AI内容的精确性要求有较高的容忍度,需要人工进行正确性或可用性的判定。
2. 什么是Tools Call?
Tools calling的前身是Function calling,它允许用户将模型和外部工具、系统连接起来,为AI模型赋予一些模型没有的能力。
当下比较火热的agent的概念,函数调用能力也是其基石之一。针对OpenAI对于AI Agent的定义,“以大语言模型为大脑驱动的系统,具备自主理解、感知、规划、记忆和使用工具的能力,能够自动化执行完成复杂任务的系统。”
举个例子:比如用户询问大模型今天的天气如何?AI的数据预训练特性、数据滞后性导致它不可能知道“今天”是哪天,也不可能知道今天的“天气预测”从何而来。但是如果赋予AI可以调用外部接口获取天气预测信息的能力,那么AI就可以完成对用户天气预测问题的响应了。
3. 什么时候需要用?
基于上面的叙述,当我们需要利用AI处理实时的、私有垂类数据、对响应数据精确性有要求、并且希望深度集成工程化项目,即AI的响应数据需要驱动业务的下一环节时,可能就必须要使用tools calling来支持了。
让AI充当大脑,以自然语言为交互接口(NLUI),结合结构化输出和tools calling能力,确保AI响应数据符合业务下游要求的结构化定义,将AI深度集成到工程化项目中来。
二、支持ToolsCall的AI交互全生命周期
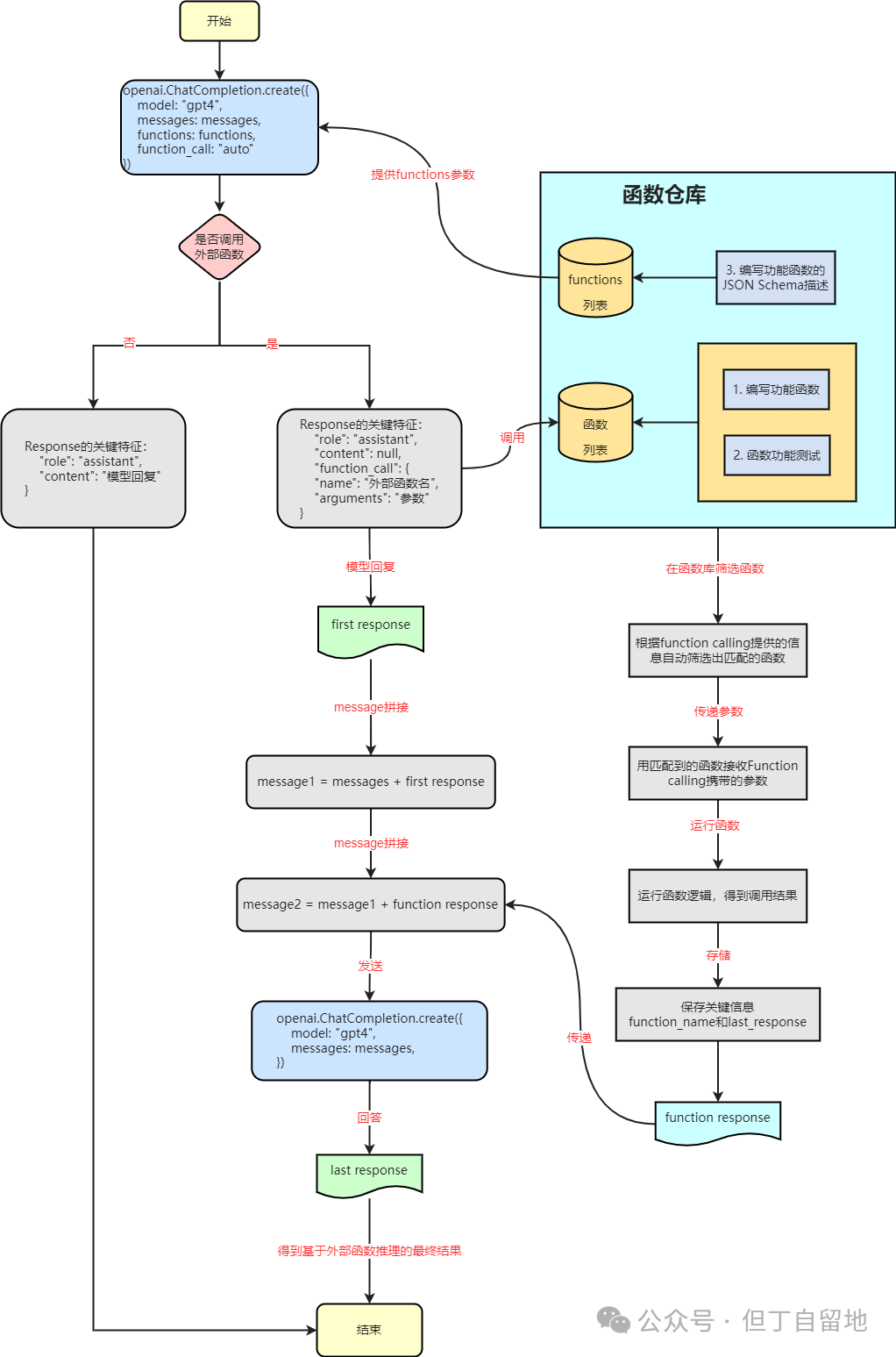
上图是一个需要使用tools calling调用时的AI交互流程示意图。
淡蓝色背景标注的函数仓库是我们需要提供给AI模型的外挂能力合集,从图中可以看到,模型实际上从不自行执行函数,模型仅负责从自然语言的交互信息中识别、抽取出需要调用的外部能力,并按照能力约定的输入参数构造出合适的入参信息传递给函数,实际的函数调用还是在工程项目的环境中(如Spring项目)执行。函数的运行生命周期始终在应用程序内。
AI在拿到能力输出的结果后,再结合NLUI输入的上下文信息给出用户问题的最终应答。AI在此链路中发挥是语义识别、自动组装参数调用外部能力、串联、聚合生成最终响应的职责。应答的有效性自然也就取决于NLUI的输入(预设prompt和提问prompt质量)、外部函数能力的赋能(函数定义的合理性以及函数定义的精确性)以及模型自身的智能(结合函数响应的聚合)。
AI模型根据任务需求和外部函数能力,自行判断出需要调用哪些函数来获取需要的输入信息,在本文里我将模型在判断出需要调用外部函数并构造了相应的调用参数的响应称为半响应,后续结合了若干次函数调用结果AI聚合后的响应称为最终响应。
三、原生的Tools Call使用方式
1. 确定需要使用的外部函数库
从当前的工程应用中,挑选出完成某一特定任务需要赋能AI模型的能力函数。后续需要适当改造这些函数,以便可以同AI模型交互。
以天气预报为例,我们需要提供一个函数,接收日期和城市名,返回对应的天气情况:(可以替换为任意实际业务中的能力)
String getWeather(String city, String date)2. 定义模型需要的函数定义声明
跟AI模型交互过程中,我们需要以模型可识别的语义告知我们的函数。针对上面的例子,我们需要使用类似下面的定义描述函数:
{"name": "getWeather","description": "该函数用来获取指定城市和日期的天气预测情况","parameters": {"type": "object","properties": {"city": {"type": "string","description": "指定的城市名"},"date": {"type": "string","description": "指定日期"}},"required": ["city","date"],"additionalProperties": false}}
这里核心是构造parameters参数,反映函数的入参结构,AI将会根据上下文输入信息从中抽取出需要的参数信息,按照该结构组装信息去调用外部函数。因此函数结构描述的正确与否将决定了AI调用外部能力的正确性。
参数类型支持string、number、boolean、array、object。
description参数也很重要,描述清晰的description是prompt的一部分,能够指导AI模型正确地判断需要能力时应该调用什么方法。
3、与AI交互时设置Tools参数
当确认需要告知AI在交互过程中心需要调用外部能力时,就需要我们将上述步骤定义好的函数定义结构作为参数传递给AI。
普通的交互我们只需要传递messages数组,此时我们需要额外传入一个tools参数,表示AI模型在过程中可能需要用到的所有外部函数的集合。
如:
tools = [{"name": "getWeather","description": "该函数用来获取指定城市和日期的天气预测情况", // description很重要,也算是prompt的一部分"parameters": { // 方法参数的描述"type": "object","properties": {"city": { // 参数名"type": "string", // 参数类型"description": "指定的城市名" // 参数描述},"date": {"type": "string","description": "指定日期"}},"required": ["city", "date"], // 必选参数,指定模型在调用时必须构造的参数"additionalProperties": false,}}]
4. 处理AI的半响应并回填prompt
虽然我们传递了外部函数给AI模型,但是AI模型会在实际的交互过程中自行判断是否需要调用。比如上述例子,我们给AI传递了天气预测的方法,但是我们在与AI互动时根本不涉及天气的话题,那么AI自然也不会去调用外部函数,此时的AI响应与正常未传递tools时一致。
当AI判断需要调用外部能力时,它的响应就与正常的响应不同。此时响应结构中,会有一个明确的标识告知用户需要调用外部函数,并且会组装好要调用的函数和对应的入参,如:
Choice(finish_reason='tool_calls',index=0,logprobs=None,message=chat.completionsMessage(content=None,role='assistant',function_call=None,tool_calls=[chat.completionsMessageToolCall(id='call_62136354',function=Function(arguments='{"city":"杭州", "date": "2024/10/01"}',name='getWeather'),type='function')]))
识别到半响应结果中需要调用函数后,系统需要使用AI构造的参数调用函数将返回结果再次返回给模型,这里比较复杂的地方在于,需要将模型返回的tool_call的id和一次调用返回的结果成对的组装好提供,同时还需要将半响应返回的tools_call信息作为assistant角色的输入。针对上述天气预测的例子,结构可能如下:
{messages: [{"role": "user", "content": "请问杭州10月1日的天气如何?"},{"role": "assistant", "content": "","toolCalls": [{"type": "function","id": "call_qP2V78iKvOA63wFGGbF3R9F8","function": {"name": "getWeathre","arguments": "{'name': '杭州', 'date': '2024/10/01'}"}}]},{"role": "tool", "tool_call_id":"call_qP2V78iKvOA63wFGGbF3R9F8","content": "10月1日杭州天气多云"}]}
5. 再次与AI交互获取最终结果
使用上述结合了函数调用结果的请求再次跟AI模型交互,AI将会结合输入prompt和函数调用结果聚合出最终的结果返回给用户。
上述例子中可能直接就可以将函数响应返回,真实的使用场景中,AI可能会从多个不同的外部能力函数获取部分数据,最终需要结合大模型的语义和推理能力生成最终的结果。这阶段prompt的写法也会对输出效果有较大的影响。
四、支持Tools Call的Java AI能力框架的封装
通过上面章节的描述可以看出,在使用AI时,直接跟外部工程能力交互还是比较复杂的,如果需要调用多个不同能力完成任务的话,还需要重复编写这些过程繁琐、逻辑复杂的代码,直接导致了使用AI Tools Call的门槛变高。最好的方式莫过于将这些编排逻辑封装成框架,业务只需要负责提供业务能力,调用AI框架提供的接口,其他复杂的逻辑交给框架即可。
那么应该如何实现该框架,将Tools Call机制与我们工程应用能力结合起来呢?我们前面提过,提供给AI Agent使用的工具实际上可以是任何可以执行的任务,这里我们封装的框架会以执行Spring Bean来举例,你可以在你的实践中进行修改。
我们可以利用Java反射机制,来直接在运行时调用工程应用能力。这种方法基本上对应用能力无侵入,适用于Java工程应用。
1. 函数定义以及Tools Schema的自动封装
首先我们看下,如何自动识别到系统需要支持AI的工程应用能力。通常我们是先有的工程应用能力,再考虑的和AI结合,这里为了尽量减少对应用系统的侵入,我使用注解的方式。
定义一个@FunDesc注解,用来描述那些辅助AI的外部能力,该注解主要用来描述外部能力,方便AI识别。
/*** 方法功能注解,必须要填,方便AI根据描述选择回调哪个函数*/publicFunDesc {String value();}
有了该注解,工程应用只需要在那些需要透给AI的方法上打上该注解即可。
同样地,方法的参数也应该要被AI能够识别,也方便框架在运行时自动识别组装成可以和AI交互的数据结构。这里我也使用注解的形式:
/*** 参数字段描述注解,方便AI解析自然语言生成对应参数*/publicFieldDesc {// 该字段的描述String value();// 该字段是否是必传参数String required() default "false";}
有了这两个注解,我们就可以在运行时通过反射来识别到工程里有哪些方法是需要提供给AI的了,也将能够自动生成跟AI交互需要的函数结构和Schema了。
2. 生成函数定义
上一章节里提到了函数定义的结构,当前通过注解和反射我们也能知道函数的具体信息了,那么剩下来的就是具体处理加工而已了。
// 当前function calling的函数只支持json string入参,可以在函数接受参数后自行转换private BinaryData getFunctionSchema(Method method) {Parameter[] parameters = method.getParameters();Map<String, Object> schema = new HashMap<>();schema.put("type", "object");Map<String, Object> parameterMap = new HashMap<>();List<String> requiredFields = new ArrayList<>();for (Parameter parameter : parameters) {// parameter是对象,反射获取该对象的字段Field[] fields = parameter.getType().getDeclaredFields();for (Field field : fields) {FieldDesc fieldDesc = AnnotationUtils.findAnnotation(field, FieldDesc.class);Assert.isTrue(fieldDesc != null, "参数类" + parameter + "未标注@FieldDesc注解");String fieldDescValue = "";if("true".equals(fieldDesc.required())) {requiredFields.add(field.getName());}fieldDescValue = fieldDesc.value();if(isEnum(field)) {Map<String, Object> map = new HashMap<>();map.put("type", "string");map.put("description", fieldDescValue);map.put("enum", Arrays.stream(field.getType().getEnumConstants()).map(Object::toString).collect(Collectors.toList()));parameterMap.put(field.getName(), map);} else if (List.class.isAssignableFrom(field.getType())|| String[].class.isAssignableFrom(field.getType())){Map<String, Object> map = new HashMap<>();map.put("type", "array");map.put("description", fieldDescValue);map.put("minItems", 1);map.put("items", new HashMap<String, Object>() {{put("type", "string");}});parameterMap.put(field.getName(), map);} else {String finalFieldDescValue = fieldDescValue;parameterMap.put(field.getName(), new HashMap<String, Object>() {{put("type", getTypeMapping(field));put("description", finalFieldDescValue);}});}}}schema.put("properties", parameterMap);schema.put("required", requiredFields);return BinaryData.fromObject(schema);}
private List<FunctionDefinition>getFunctionDefinitionList(Object callFunctionInstance,List<String> methodNames) {List<FunctionDefinition> functions = new ArrayList<>();Method[] methods = callFunctionInstance.getClass().getMethods();for (Method method : methods) {String methodName = method.getName();if(methodNames.contains(method.getName())) {FunctionDefinition definition = new FunctionDefinition(methodName);definition.setParameters(getFunctionSchema(method));FunDesc desc = AnnotationUtils.findAnnotation(method, FunDesc.class);Assert.isTrue(desc != null, "方法" + methodName + "未标注@FunDesc注解");definition.setDescription(desc.value());functions.add(definition);}}return functions;}
3. Tools call半响应的自动处理
首先需要识别AI的响应是否是半响应。可以通过解析响应结果中是否返回了Tools Call信息。
这里我以流式调用为例,流式调用时,返回的Tools Call信息也是流式返回的,无疑增加了对信息处理的复杂度。注意同一个tools call的数据会在第一次返回时返回toolCallId,后续同一个tools cal的数据该字段为空即可。
这个处理过程还需要注意的是,需要在数据处理过程中记录下来返回的tools call信息,并且添加到和AI交互的messages中。
List<ChatCompletionsToolCall> toolCalls = choices.get(0).getDelta().getToolCalls();if(CollectionUtils.isNotEmpty(toolCalls)) {needToolsCall = true;// 需要tools call,从流式响应里构造tools call参数for (ChatCompletionsToolCall toolCall : toolCalls) {FunctionCall functionCall = ((ChatCompletionsFunctionToolCall) toolCall).getFunction();String functionName = functionCall.getName();String toolCallId = toolCall.getId();String arguments = functionCall.getArguments();// 流式参数响应,toolCallId为空时表示延续上个函数的参数,不为空时表示开始一个新的回调if(StringUtils.isNotEmpty(toolCallId)) {if(StringUtils.isNotEmpty(callParam.getToolsCallId())) {functionCallParamList.add(callParam);}callParam = new FunctionCallParam();callParam.setFunctionName(functionName);callParam.setToolsCallId(toolCallId);// tools call请求需要将toolCalls信息加入messages,需要在开始时加入,后面的流式结果里没有toolCallsIdChatRequestAssistantMessage assistantMessage = new ChatRequestAssistantMessage("");assistantMessage.setToolCalls(toolCalls);callParam.setAssistantMessage(assistantMessage);}callParam.setFunctionArgumentSb(callParam.getFunctionArgumentSb().append(arguments));}}
4. 外部函数的自动调用
通过上一步的处理,半响应已经告知了我们应该调用哪个外部能力,也组装好了调用能力的参数。在这一步中,我们需要按照AI半响应的要求,调用能力得到结果后,再返回给AI二次交互。
Object instance = optionsParam.getInstance();Method[] methods = optionsParam.getMethods();List<ChatRequestMessage> messages = optionsParam.getMessages();ChatCompletionsOptions options = optionsParam.getOptions();List<ChatCompletionsToolCall> toolCalls = new ArrayList<>();List<ChatRequestToolMessage> toolMessages = new ArrayList<>();for (Method method : methods) {// 防止存在同名方法FunDesc funDesc = AnnotationUtils.findAnnotation(method, FunDesc.class);if(funDesc == null) {continue;}for (FunctionCallParam functionCallParam : functionCallParamList) {String functionName = functionCallParam.getFunctionName();StringBuilder functionArgumentSb = functionCallParam.getFunctionArgumentSb();String toolsCallId = functionCallParam.getToolsCallId();if(method.getName().equals(functionName)) {Class<?>[] parameterTypes = method.getParameterTypes();Object functionArgumentsObj = JSONObject.parseObject(functionArgumentSb.toString(), parameterTypes[0]);String result = method.invoke(instance, functionArgumentsObj).toString();Assert.isTrue(StringUtils.isNotEmpty(result), "function call failed");log.info("functionCall res: {}", result);toolCalls.addAll(functionCallParam.getAssistantMessage().getToolCalls());ChatRequestToolMessage toolMessage = new ChatRequestToolMessage(result, toolsCallId);toolMessages.add(toolMessage);}}}ChatRequestAssistantMessage assistantMessage = new ChatRequestAssistantMessage("");assistantMessage.setToolCalls(toolCalls);messages.add(assistantMessage);messages.addAll(toolMessages);// 带入函数调用结果再次调用aichatCompletionsStream = textOpenAIClient.getChatCompletionsStream(aiChatModel, options);
5. 多轮对话能力的封装
到了这里,基本上困难的部分已经没有了。多轮对话的能力,主要就是构造一个包含多角色信息的messages结构即可。
为了避免AI交互的tokens消耗过多、超过最长上下文限制,根据经验,我考虑将上下文的支持轮数定为5次。这就需要使用到一个FIFO的淘汰策略。
// 如果超过,淘汰最旧的一条,加入当前的信息if (contextMessages.size() >= 5) {contextMessages.remove(0);}for (ContextMessage contextMessage : contextMessages) {RoleEnum role = contextMessage.getRole();String content = contextMessage.getContent();if (role == RoleEnum.USER) {messages.add(new ChatRequestUserMessage(content));} else if (role == RoleEnum.ASSISTANT) {messages.add(new ChatRequestAssistantMessage(content));} else {throw new RuntimeException("错误的上下文角色");}}
6. 流式响应的封装
众所周知,与AI的交互通常是比较耗时的,一般我们都使用流式响应实现一个即时输出的效果,避免长时间等待甚至超时。
具体机制,我以使用文件流形式实现为例:
// 框架对AI流式响应的解析public void generateTextWithToolsCallStream(TextGenerateRequest request, Function<String, Object> cb) {...List<ChatChoice> choices = chatCompletions.getChoices();if(CollectionUtils.isEmpty(choices)) {continue;}// 指定了候选问题只有一个ChatChoice choice = choices.get(0);List<ChatCompletionsToolCall> toolCalls = choice.getDelta().getToolCalls();if(CollectionUtils.isEmpty(toolCalls)) {String content = choice.getDelta().getContent();if(content != null) {...// 即时返回给回调函数cb.apply(content);...}continue;}...}
// 业务接入aiGenerateService.generateTextWithToolsCallStream(request, res -> {// 这里使用文件流的方式即时输出writer.println(res);try {// 给前端时稍微sleep一会儿,否则可能会因为输出过快被浏览器认为是实时,出不来逐字输出效果Thread.sleep(65);} catch (InterruptedException ignored) {}writer.flush();answers.add(res);return null;});
还有一些细节的问题没有涉及讨论,以及一些多并发下竞态条件的处理没有考虑。可以参考我的开源项目代码做进一步细致分析,链接放在了原文链接里,可点击访问。
不知道这篇文章是否让你对Agent有了进一步的了解?大模型能使用工具,是软件工程学上的成就,而不是什么神奇魔法或者机器智能的神迹。
输出一篇六千多字的干货文章实属不易,拒绝洗稿抄袭。
欢迎留言讨论,欢迎关注点赞转发分享~~
相关文章
