“如果你问我这两年中国AI最迷的是什么,我一定会毫不犹豫地回答:大家都在卷通用大模型,但没人真正想清楚要卷出什么差异化。今天聊聊为什么中国需要有一个像Claude这样的专业化选手,以及谁可能成为那个人。”
2023年3月,百度文心一言正式向公众开放,拉开了中国大模型百模大战的序幕。
在随后的两年中,国内大模型数量激增至200余个,资本投入超过300亿元。各大科技巨头纷纷入局,通义千问、星火认知、豆包大模型等产品相继推出,一时间"大模型"成为科技界最热门的赛道。

然而,在这场声势浩大的竞赛背后,中国大模型产业正面临着严峻的同质化困境。
绝大多数模型在功能与能力上高度相似,都在追求参数规模扩大和通用能力提升,却很少有模型形成真正的差异化优势。
根据艾瑞咨询的数据,截至2025年第一季度,中国头部大模型在技术指标上的差异已经微乎其微,"你能做到的,我也能做到"成为行业常态。
更为严峻的是商业变现困境。
尽管投入巨大,但大模型的商业回报却十分有限。以百度为例,2023年Q4智能云营收84亿元,而大模型仅贡献6.6亿元增量,占比不足8%。阿里云、科大讯飞等公司的大模型业务收入占比同样偏低。一位不愿具名的行业内专家表示:"投入一百亿,可能只有不到十亿的回报,这样的商业模式显然是不可持续的。"
在评测标准上,各家模型厂商热衷于在MMLU、CMMLU、Chatbot Arena等评测基准上刷分,试图证明自己的技术实力。Qwen2.5-Max在Chatbot Arena全球排名第七,文心一言在沙利文报告中的语言理解能力被评为国内第一,星火V4.0则宣称在8项国际测试集超越GPT-4 Turbo。
然而,这种评测刷分与实际应用价值之间存在显著断层。
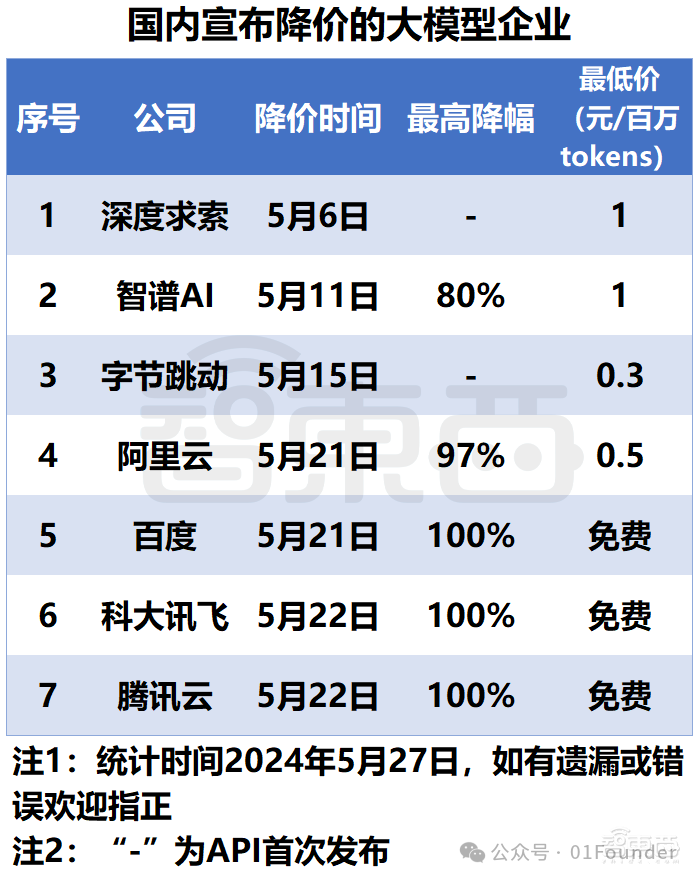
企业用户的反馈更加直观。根据一项覆盖500家企业的调查,超过60%的企业认为"不同大模型之间没有本质区别",50%的企业表示"模型能力与实际业务需求存在明显差距"。由于难以形成差异化优势,价格战成为模型厂商的主要竞争手段。
从最初的每月数百元订阅费,到如今多家厂商宣布API免费或大幅降价,价格战不仅无法提升产品差异化,还进一步加剧了盈利难题。
资本市场也已经对大模型热情消退。
特别是在25年春季DeepSeek爆火后,多家大模型创业公司已经无法继续融资,甚至有头部厂商已连续多个季度进行人员优化。资本寒冬下,缺乏清晰商业模式的大模型公司面临严峻挑战。
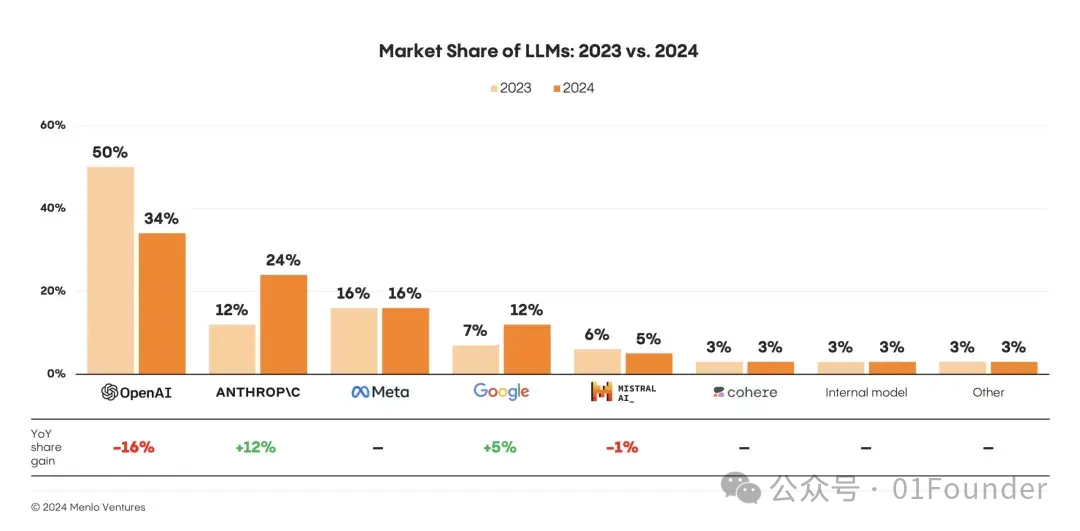
与中国大模型的同质化竞争形成鲜明对比,美国Anthropic公司的Claude选择了一条截然不同的发展路径。
相较于OpenAI主要致力于通用推理与全模态融合的AGI之路,Claude专注于代码生成、指令遵循和长文本处理等特定能力,尤其在代码生成领域建立了显著优势。
这种专注策略背后是深思熟虑的技术壁垒构建。
行业观察者发现一个有趣现象:OpenAI的o1推理模型在发布几个月后就被国内外多家公司基本复制,而Claude在代码生成和SVG能力方面的优势已持续近一年,至今仍难以被完全复制。
这一差异背后的原因值得深思。推理模型主要是使用强化学习来进行后训练,相对容易通过数据蒸馏和架构调整来复制。而代码能力则需要更深层次的数据质量与训练方法,不仅是模式的学习,因此形成了更强的技术壁垒。
Claude的数据策略也独具特色。
与大多数模型依赖Stack Overflow和Reddit等常见公开来源不同,Claude注重数据的多样性和全面覆盖。这种广泛的数据覆盖使模型能够更全面地理解世界,从而在复杂任务上表现更好。Claude的模型训练团队特别注重数据质量和多样性,这也是其在特定领域能够建立持续优势的关键因素之一。
除了技术壁垒,Claude还通过生态系统构建了第二道护城河。
2024年11月,Claude推出了MCP(Model Context Protocol)协议,这一协议迅速成为AI模型与外部工具、数据源连接的标准化接口。MCP的核心理念是"一次开发,多平台通用",类似于硬件领域的USB-C接口标准。截至目前,已有GitHub、Slack、Figma、Replit、Cursor IDE等众多合作伙伴加入MCP生态。
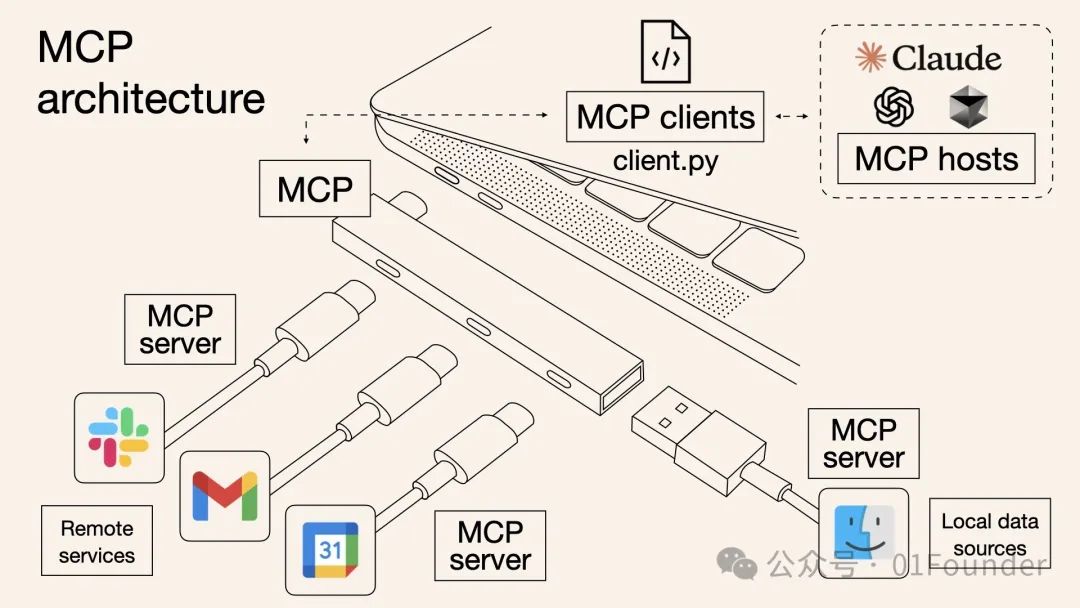
MCP与Claude的专业化战略高度协同。以代码领域为例,Cursor IDE通过MCP将Claude与GitHub、文件系统无缝连接,实现代码生成、调试到提交的全流程闭环,使Claude的coding优势得到最大化发挥。
数据显示,基于MCP的代码调试效率提升10倍,PR自动生成准确率达92%,大大强化了Claude在开发者生态中的竞争力。
Claude的这一策略已经产生了显著的行业影响力。OpenAI已宣布支持MCP协议,Gemini的CEO也公开询问用户对MCP的需求。这表明Claude的差异化路径正在获得市场认可,并可能成为行业标准。
值得注意的是,Claude的3.5和3.7被认为使用了同一套预训练模型,但通过不同方向的微调实现了差异化能力。这表明在相同基础上,可以通过专注不同方向的微调实现差异化竞争,而不必每次都重新进行成本高昂的预训练。
结合MCP生态,Claude正在构建一个技术能力与生态系统互相强化的良性循环。
面对同质化竞争的困境,中国各大模型厂商已经从单纯追求通用能力的百模大战,逐步转向差异化战略探索。2025年的行业动态显示,这种专业化趋势正在加速形成。
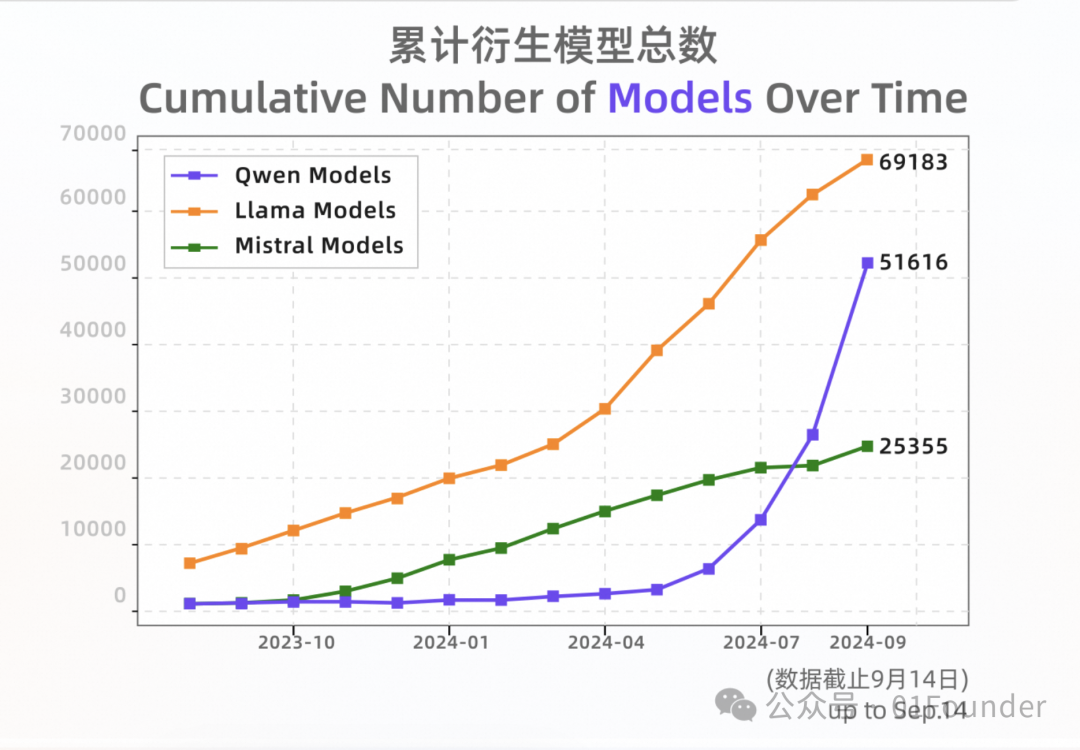
通义千问在开源策略上持续发力,不仅24年Qwen系列模型下载量突破4000万,衍生模型超过5万,在全球开源生态中位居第二,更在2025年推出QwQ-32B开源模型,其性能已经媲美DeepSeek-R1。
同时发布了超大规模MoE模型Qwen2.5-Max,强化多模态推理能力,并计划推出全新的预训练模型Qwen3。
这一策略有效扩大了开发者社区影响力,但也面临着如何将开源生态转化为商业价值的挑战。
百度文心一言则在"大模型+产业"的落地路线上持续探索。2024年百度千帆平台已服务8.5万企业,AI原生应用超19万。2025年,百度采取了更为激进的策略——文心一言全部免费开放,并发布了新的X1模型和文心4.5,特别提升了数学推理和代码生成能力,用户渗透率显著提升。
百度还加速了生态整合,依托搜索场景优化多模态交互。然而,企业级应用的高度定制需求与通用大模型能力之间仍存在适配鸿沟。

字节跳动旗下的豆包在C端市场取得了显著进展,接入多地政务系统,用户达到2.4亿,并保持全系产品(即梦、豆包、海绵)免费策略。
值得注意的是,字节还引入了Google Fellow 吴永辉博士,发布了Top Seed计划,押注长期AGI发展。

在马化腾的重视下,腾讯在2025年全面加速AI应用开发,其元宝App接入Deepseek后开始投放,用户量猛增。同时,腾讯还发布了混元T1推理模型,成为第一个应用创新架构Mamba的大厂,性能已经追上了DeepSeek-R1。

更值得关注的是AI六小龙在2025年的战略转向:
百川智能发布了Baichuan-M1全场景推理模型,并深耕医疗领域,开发行业定制化解决方案。同时,百川也开始探索轻量化部署,降低企业端应用成本。值得注意的是,百川智能已经出现两位高管离职创业,并传出收缩预训练投入的消息,表明专业化和应用层成为新焦点。
月之暗面的Kimi大模型推出K1.5多模态版本,强化了长文本处理能力(类似Claude的优势方向之一)。虽然用户增长放缓,面临字节"豆包"的竞争压力,但月之暗面在代码能力上的专注已见成效。其K1.6版本虽未正式发布,但已经在Livecodebench代码测评中取得第一名的成绩,表明其在代码领域的专业化方向已初具规模。
零一万物则采取了更为彻底的转向,宣布放弃超大模型预训练,转向应用层开发,尝试与大厂合作"大厂+小虎"模式。这一决策反映了市场对专业化分工的认可——不是每家公司都需要从预训练开始构建完整技术栈。
智谱AI推出了通用Agent AutoGLM沉思,新增深度思考功能,支持生成思维链拆解任务,并通过代码机制提升推理能力。此外,智谱AI发布了GLM-Z1-Rumination模型,强化长程推理和工具调用能力。这种对特定能力的聚焦与Claude的专业化路径有相似之处。
在各家大模型的差异化尝试中,最接近Claude专业化路径的是Deepseek。
作为一家成立于2021年的AI创业公司,Deepseek在Deepseek在代码生成领域的探索尤为值得关注。从早期的DeepSeek-Coder模型到其近期推出的DeepSeek-V3-0324版本,专注提升了代码和工具调用能力,显示出对标Claude专业化道路的潜力。

更引人注目的是,Deepseek于2025年发布的DeepSeek-R1开源模型引发了行业震动。
该模型在推理能力上实现了重大突破,将推理成本降至行业1/7,并且能够很好地适配国产芯片供应链。
DeepSeek-R1开源后快速覆盖政务、开发者和企业场景,被业界类比为"AI安卓系统"。
然而,相比Claude的全方位布局,Deepseek在生态构建方面仍有差距。
尽管技术上已经开始向代码领域倾斜,但如何构建像Claude这样的开放但有控制的生态系统,如何与开发工具链实现无缝集成,仍是Deepseek面临的重要挑战。如果Deepseek能够进一步构建类似Claude的MCP生态,实现代码生成能力与开发工具链的深度融合,将有望成为中国真正的Claude式选手。
面对中国大模型的同质化困境,Claude的成功路径提供了一个重要的参考方向。中国市场迫切需要自己的Claude式选手——一个专注于代码领域并能构建生态护城河的大模型厂商。这种需求既有商业逻辑,也有技术发展和产业安全的考量。
从商业价值看,代码领域具有显著优势。
根据IDC的数据,2024年全球开发者工具市场规模达到1400亿美元,年增长率超过15%。
与通用AI服务相比,开发者工具具有更高的付费意愿和用户粘性。GitHub Copilot的月活用户已超过200万,付费转化率高达12%,远超通用AI产品的平均水平。
通过专注代码领域,大模型厂商可以避开通用赛道的价格战,获得更稳定的商业回报。
从技术壁垒角度看,代码生成能力比通用对话能力更难被复制。
代码生成不仅需要理解编程语言的语法规则,还需要把握软件架构设计、算法选择、性能优化等多层次知识,这种复杂性使得专业化模型能够建立更深的技术护城河。
生态系统构建也是关键因素。
代码领域的大模型需要与IDE、版本控制系统、代码库等开发工具紧密集成,这种集成一旦形成,将产生强大的用户粘性。
Claude的MCP协议已经证明,通过标准化接口可以构建开放但有控制的生态系统,既推动了行业创新,又保持了核心竞争力。中国市场同样需要这样的生态协议,连接本土的开发工具和开发者社区。
更重要的是,代码大模型实际上是构建中国AI产业的关键基础设施。
软件开发效率的提升将直接影响各行业的数字化转型和智能化升级。一位业内专家指出:"代码大模型就像智能时代的'编译器',它不仅是一个工具,而是整个产业创新的倍增器。中国不能在这一关键领域完全依赖国外技术。"
值得注意的是,中国开发者生态具有独特性,这为本土代码大模型提供了差异化空间。
中国开发者在使用场景、技术栈选择和工作流程上都有区别于海外的特点。例如,更多使用微信小程序、Flutter等跨平台技术,更关注移动应用和电商系统的开发。针对这些特点定制的代码大模型将更能满足本土需求。
要构建中国的Claude式选手,需要从技术路线、生态建设和商业模式三个维度实现系统性转型。
在技术路线上,中国大模型厂商需要从追求通用能力转向特定领域深耕。这种转变不仅是研发资源的重新分配,更是思维方式的转变:不再追求"样样通,样样松",而是在特定领域做到"一项精,一项强"。具体到代码生成领域,需要建立更专业的评测标准,关注代码质量、易维护性、安全性等多维度指标,而不仅仅是能否通过简单Benchmark测试。
在训练数据上,需要构建更丰富、更多样化的代码语料库。
这包括高质量开源项目代码、企业内部代码库(在隐私保护前提下)、编程教程和文档等。重要的是,这些数据不仅要包含代码本身,还要包含代码的上下文、注释、提交历史等元信息,帮助模型理解代码的演化和设计意图。
在生态建设方面,中国模型厂商可以借鉴Claude的MCP模式,构建开放但有控制的开发者生态。
一个适合中国市场的生态连接协议应当兼顾开放性和安全性,支持本地化部署,并与中国主流开发工具实现无缝集成。与现有开发工具的协同至关重要。
模型厂商应当与IDE提供商、代码托管平台、云服务提供商建立深度战略合作,共同构建开发者生态。
这种合作可以采取产品捆绑、联合研发、API互通等多种形式,目标是为开发者提供从代码生成、调试到部署的全流程智能支持。
在商业模式方面,中国模型厂商需要探索差异化的盈利模式,避开通用大模型的价格战。
特别值得关注的是,可以借鉴Claude的多层次产品策略,以不同的模型版本满足不同市场需求。
例如,基础版面向个人开发者,具备核心代码生成功能;专业版面向中小团队,增加团队协作功能;企业版面向大型组织,提供私有部署和定制化服务。
最后,中国模型厂商需要重视社区建设,培养忠实的开发者群体。可以通过举办黑客马拉松、开发者大会、优质案例展示等活动,吸引开发者使用和推广产品。开发者社区不仅是用户来源,更是产品改进的重要反馈通道和创新灵感的来源。
经过两年的百模大战,中国大模型行业正在从同质化竞争走向专业化分工。在这一转型过程中,代码领域的专业化模型具有特殊战略价值,不仅能够实现商业上的可持续发展,也将成为中国AI产业的关键基础设施。
放眼全球,专业化趋势已经成为大模型发展的主流方向。
OpenAI借助GPT-4o实现全模态融合,主导通用智能领域;Claude专注代码生成和长文本处理,打造开发者生态;Gemini专攻搜索与多模态理解,与Google生态深度结合。每家公司都在寻找并强化自己的差异化优势,形成各自的护城河。
中国大模型也需要走向专业化分工。
从现状来看,通义千问在开源生态、文心一言在行业应用、星火在语音教育、豆包在C端体验等方面已经形成各自特色。而Deepseek在代码生成领域的探索则显示出成为中国"Claude式选手"的潜力。
未来数年,我们预计中国大模型市场将经历四个关键变化:
首先,专业化分工将进一步深化。通用大模型将主要由大厂主导,而创业公司将更加聚焦垂直能力,在细分市场形成差异化竞争优势。
其次,生态系统将成为竞争的核心。单纯的API服务难以建立持久优势,而深度融入开发者工作流的生态系统才能形成真正的护城河。我们预计会出现类似MCP的中国本土生态连接协议,推动模型与工具的无缝集成。
第三,商业模式将趋于多元化。从单一的API调用收费,向生态分润、解决方案定制、分层订阅等多元模式转变,提高商业可持续性。
最后,技术迭代方式将更加注重效率。大模型厂商将减少全量预训练的频率,转向更高效的增量训练和定向微调,降低技术迭代成本,提高创新效率。
对于政策制定者而言,支持大模型的专业化发展具有重要意义。
可以考虑设立专项资金支持垂直领域的模型研发,鼓励产业链上下游合作,建立行业标准和评测体系,为大模型的专业化分工提供政策引导和资源支持。
对于投资者而言,专业化大模型将成为新的投资热点。与通用大模型相比,专业化模型具有更清晰的商业路径和更高的技术壁垒,有望获得更好的投资回报。
对于开发者而言,专业化大模型将带来工作方式的革命性变化。更先进的代码生成工具将大幅提高开发效率,降低编程门槛,同时也对开发者提出了新的要求——如何有效地与AI协作开发,将成为未来开发者的核心技能。
总之,中国大模型行业正迎来专业化分工的转折点。在这一新阶段,我们期待看到中国的Claude式选手崛起,引领大模型从同质化竞争走向健康多元的产业生态。
也为下游苦苦挣扎的AI应用们解一解燃眉之急。
相关文章
