原文发布于 2025 年 3 月 11 日
本次更新带来三大突破性进展:
-
CodeForces-CoTs 数据集: 通过 R1 模型蒸馏生成近 10 万条高质量编程思维链样本,同时包含 C++ 和 Python 双语言解题方案
-
IOI 基准测试: 基于 2024 国际信息学奥林匹克竞赛 (IOI) 构建的全新挑战性基准
-
OlympicCoder 模型: 7B/32B 双版本代码模型,在 IOI 问题上超越 Claude 3.7 Sonnet 等闭源前沿模型
下图展示了 OlympicCoder 与各类指令微调模型、推理模型的性能对比。通过 CodeForces-CoTs 训练出的模型展现顶尖性能,其中 32B 版本甚至超越了我们测试过的所有开源模型 (包括某些参数量百倍于它的模型) ?

模型性能对比图 下文将深度解析数据集构建、基准测试设计及模型训练的全过程。
? 核心资源链接
CodeForces 相关
-
题库数据集 : open-r1/codeforceshttps://hf.co/datasets/open-r1/codeforces
-
DeepSeek-R1 思维链数据集 : open-r1/codeforces-cotshttps://hf.co/datasets/open-r1/codeforces-cots
国际信息学奥林匹克 (IOI)
-
赛题数据集 (2020-2024): open-r1/ioihttps://hf.co/datasets/open-r1/ioi
-
测试用例 : open-r1/ioi-test-caseshttps://hf.co/datasets/open-r1/ioi-test-cases
-
官方参考答案 : open-r1/ioi-sample-solutionshttps://hf.co/datasets/open-r1/ioi-sample-solutions
-
DeepSeek-R1 思维链数据集 (2020-2023): open-r1/ioi-cotshttps://hf.co/datasets/open-r1/ioi-cots
-
40+ 主流模型在 IOI’2024 的表现 : open-r1/ioi-2024-model-solutionshttps://hf.co/datasets/open-r1/ioi-2024-model-solutions
-
代码生成与评估工具 https://github.com/huggingface/ioi
OlympicCoder 模型
-
7B 模型 : open-r1/OlympicCoder-7Bhttps://hf.co/open-r1/OlympicCoder-7B
-
32B 模型 : open-r1/OlympicCoder-32Bhttps://hf.co/open-r1/OlympicCoder-32B
CodeForces-CoTs 数据集
CodeForces 是编程竞赛爱好者中最受欢迎的网站之一,定期举办比赛,要求参与者解决具有挑战性的算法优化问题。这些问题的复杂性使其成为提升和测试模型代码推理能力的绝佳数据集。https://codeforces.com/
尽管此前已有如DeepMind 的 CodeContests 数据集 汇集了大量 CodeForces 问题,但我们今天发布了自有的 open-r1/codeforces 数据集,包含超过 1 万个问题,覆盖从最早的比赛到 2025 年,其中约 3000 个问题 未被 DeepMind 数据集收录。此外,对于约 60% 的问题,我们还提供了由比赛组织者撰写的 **官方解析 (editorial)**,解释正确解法。你还能找到从官方网站提取的每个问题对应的 3 个正确解决方案。https://hf.co/datasets/deepmind/code_contests
与此同时,我们还发布了 open-r1/codeforces-cots ,其中包含 DeepSeek-R1 在这些问题上生成的思维链 (Chain of Thought) 内容。我们要求模型使用 C++ (编程竞赛中的主要语言) 和 Python 生成解决方案,总计接近 10 万个样本。
我们基于此数据集对 Qwen2.5 Coder Instruct 的 7B 和 32B 模型进行了微调,得到了 OlympicCoder-7B 和 OlympicCoder-32B 模型。更多细节将在博客后续部分介绍。
代码可验证性危机
像 DeepMind 的 CodeContests 等包含竞技编程问题的数据集虽然提供了测试用例并声称具有代表性,但这些测试用例往往只是比赛网站完整测试集的一个小子集。特别是 CodeForces 将显示的测试用例限制在约 500 个字符以内,这意味着 这些数据集仅包含较短、较简单的测试用例。
举个例子,我们选取了 7 个 R1 生成的解决方案,它们通过了所有公开测试用例,但尝试将提交到 CodeForces 平台:
测试结果图 尽管这些方案通过了较短的测试,但在完整测试集上,每一个解决方案都失败了。这凸显了我们急需一个完全可验证的竞技编程数据集。虽然我们计划未来通过模型生成并验证更多具有挑战性的测试用例,添加到我们的 CodeForces 数据集中,但目前我们转向了其他地方寻找完整可用的题目数据。
国际信息学奥林匹克竞赛 (IOI): 顶尖算法挑战
国际信息学奥林匹克竞赛 (IOI) 是全球五大科学奥林匹克赛事之一 (如果你熟悉数学奥林匹克竞赛 IMO,可以将 IOI 理解为编程领域的对应赛事)。IOI 每年从全球范围选拔最优秀的高中生 (每个国家 4 人),让他们挑战复杂的算法问题。
IOI 的问题难度极高,而且完整的测试集是公开且免费使用的 (CC-BY 许可),这使得 IOI 成为测试代码能力的绝佳数据集。
每道 IOI 题目由多个子任务组成,每个子任务都有不同的输入限制。要解决一个子任务,代码需要在规定时间内通过所有测试用例。虽然最终子任务通常是完整问题,但其他大多数子任务往往是难度较低的问题,参赛者可以选择解决部分子任务以获得部分分数,而不是尝试完美解决完整问题 (完美得分非常罕见)。
我们参考了OpenAI 最近的研究 ,处理了 IOI 2024 的所有问题 (以及 2020 年至 2023 年的题目),并将每道题目拆分为多个子任务。我们发布了这些处理后的问题陈述、评分文件以及测试用例,分别存储在 open-r1/ioi 和 open-r1/ioi-test-cases 数据集中。http://arxiv.org/abs/2502.06807
为了运行这些复杂的题目,我们开发了专用代码框架 (许多问题需要多个进程协同运行和复杂的验证机制),并根据 IOI 规则进行评分。这些工具在https://github.com/huggingface/ioi 上开源,同时我们还评估了超过 40 个推理模型的表现。https://github.com/huggingface/ioi
在比赛条件下,我们为每个子任务生成了 50 次提交,并采用类似 OpenAI 的选择策略评估模型表现。结果如下,图中水平线代表真实比赛选手的奖牌阈值 (青铜、银、金)。虽然 o1 模型接近青铜奖牌,但没有模型能够达到获奖分数线 (参赛者的前 50%)。
IOI 模型表现图 我们的 OlympicCoder 模型 (红色) 与其他模型相比表现优异,甚至超过了部分闭源模型 (黄色),如 Claude 3.7 Sonnet。同时,OlympicCoder-32B 在 50 次提交限制下的表现优于 o1-mini 和 DeepSeek-R1 模型。
提交策略: 模拟真实比赛条件
在实际比赛中,参赛者提交后的得分是未知的,因此我们采用了一种类似 OpenAI 的轮流提交策略。具体来说,我们先提交针对问题最后一个子任务的解决方案,然后依次提交针对倒数第二个、第三个子任务的代码,同时跳过已解决的子任务。在选择提交时,我们更倾向于 生成较长代码的提交,这一标准对推理模型较为友好,但对其他模型可能不利。
如果我们取消 50 次提交限制 (不再模拟真实比赛条件),对生成的所有提交进行评估 (每个子任务 50 次),可以得到以下结果:
取消限制后的结果 从 R1 上训练代码模型中学到的经验
在开发 OlympicCoder 模型时,我们做了很多监督微调 (SFT) 实验,想搞清楚 CodeForces 数据集上各种筛选条件的产生的影响。经过一番摸索,我们发现 open-r1/codeforces-cots 里的这些子集表现最好:
-
solutions : R1 根据问题描述直接给出的解法。
-
solutions_w_editorials : R1 在问题描述外 + 讲解正确解法的说明后给出的解法。
顺便提一句,我们这次只用了 C++ 解法。如果再掺点 Python 解法进去,效果可能会更好。
我们拿LiveCodeBench 来测试模型,然后把表现最好的版本扔到更难的 IOI 基准上去检验。为了训练模型,我们试了各种超参数组合,最后敲定了这些:https://livecodebench.github.io
-
模型: Qwen2.5 Coder Instruct 7B 和 32B
-
训练轮次: 10 轮
-
高效的 batch size: 128
-
学习率: 4e-5
-
调度方式: 用余弦调度,学习率最后降到最高值的 10%
-
上下文长度: 7B 模型用 32,768 个 tokens,32B 用 22,528 个 tokens
接下来,我们分享一下在调整 Qwen2.5 Coder 模型时,从 R1 推理轨迹里总结出的几点经验。
经验 1: 样本打包会有损推理能力
样本打包是个常见的招数,能高效处理长度不一的序列,加速训练。原理就像下图展示的: 把训练样本 (彩色的部分) 拼接成一样大的块,这样就不用塞填充标记 (灰色的部分) 了:
打包后,样本可能会在块的边界上有点重叠。不过如果样本大多比块小很多,这问题就不大。
但对于从 R1 提取的推理轨迹,我们怀疑打包可能会出问题。因为这些轨迹往往很长,被剪掉的部分比例不低。这就可能让模型很难学会处理长上下文的信息,尤其是当问题和答案被分到不同的块里时。
结果真如我们所料,下图清楚地显示,打包严重影响了模型表现: 用了打包,模型几乎解不出 LiveCodeBench 的问题; 不打包的话,性能会稳步提升,最后稳定下来:
我们猜,这种差距这么明显,可能是因为训练集只有 C++ 解法,而 LiveCodeBench 评测的是 Python。不过不管怎样,我们试过的所有数据集里,打包的表现都不如不打包。
经验 2: 想效果好,学习率得调大
我们用 Qwen 模型做 SFT 实验时,通常学习率设在 2e-5 就够用了,效果也不错。但这次给现有 instruct 模型加推理数据时,我们发现把学习率调到 4e-5 能明显提升表现。下图显示,每次把学习率翻倍,LiveCodeBench 分数能涨差不多 10 分!
经验 3: 加编辑说明不一定有用
我们在尝试 open-r1/codeforces-cots 的 solutions_w_editorials 子集时,本以为给 R1 问题和解法再加个讲解,能生成更好的推理轨迹。可测试下来完全不是这么回事,反而是直接从问题描述采样,训练效果稍微好一点,而且一直都更稳定:
经验 4: 用预填充,保持长推理能力
我们在测试模型时,发现个怪事: 如果问些竞赛编程相关的问题,模型会老老实实在 <think> 和 </think> 里输出完整的长链式推理 (CoT),然后给答案。但换成无关的问题,比如“瑞士首都是哪儿”,它就变回原来 instruct 模型的风格了!
比如这个简单的例子,长推理就没出来:
用户: 1+1 等于多少?
助手: 2。这是最基本的加法题之一,1 加 1 就是 2。这题常被拿来当谜语或测试题,尤其在面试或在线考试里,看你能不能快速解题。答案虽然简单,但对老板来说,能看出你的思考和解题能力。它还是数学的基础,后面复杂的计算都靠它。所以下次有人问你 1+1,你可以很有底气地说: 2!
# 定义一个加法函数
def add_numbers(a, b):
return a + b
# 用一下这个函数
result = add_numbers(1, 1)
print("1 + 1 的结果是: ", result)
这个解法里,我们写了个 add_numbers 函数,接收两个数 a 和 b ,返回它们的和。用参数 (1,1) 运行一遍,将结果存到 result 里然后打印。简单直接,展示 Python 里怎么做基本运算。
但如果我们在回答前加个 <think> 预填充,效果就不一样了:
用户: 1+1 等于多少?
助手: <think> 好,我得回答“1+1 是多少”。想想看,1 加 1 是 2。等等,会不会有什么玄机?比如换个问法?或者不同进制?十进制是 2,二进制是 10。不过这问题挺直白的,用户估计就想要个简单答案。所以答案是 2,直接说出来吧? </think> 对,1 + 1 就是 2。还想知道啥吗?
这说明,把推理轨迹加到现有模型时, 最好在最终聊天模板里默认用预填充。DeepSeek 的模型也是这么干的,可能就是因为这个。(顺便猜一下,那些聊天界面上的“思考”按钮,会不会就是偷偷加了个预填充?)
经验 5: 用 8 位优化器搞定长上下文大模型
训练 OlympicCoder-7B 时,我们发现用 DeepSpeed ZeRO-3,在 8 个 H100 的单节点上跑 32k 上下文没啥问题。但把模型放大到 32B 时,内存就不够用了。上下文超过 20k 标记时,即使 16 个节点也撑不住,直接内存溢出 (OOM) ?。这挺麻烦,因为 20%的 CodeForces-CoTs 轨迹超 20k,训练时会被剪掉。
问题出在 transformers 和 trl 还不支持 上下文并行 ,可以去这个链接 看看进展。https://github.com/huggingface/transformers/issues/35983
我们试了各种省内存的办法,最后发现 FSDP 搭配 paged_adamw_8bit 优化器,能把上下文撑到 22,528 个标记。虽然还是不够完美,但只有 9%的数据被裁剪掉了。
更新的内容
GRPO 更新
最近我们在 TRL 中对 GRPO 做了改进,让它的 效率、可扩展性和资源利用率 更上一层楼。以下是自上次更新以来最重要的一些变化
生成重用
GRPO 和其他在线方法有个共同的“痛点”: 生成东西太费时间。为了让 GRPO 用更少的样本干更多活,一个聪明办法就是把生成的样本反复利用,而不是用一次就扔。这招其实老早就有了,出自PPO 的“遗产”。https://hf.co/papers/1707.06347
在 GRPO 里,样本重复使用的次数有个专有名词,叫 μ 。
现在我们能多次“榨干”这些样本的价值,速度快了不少。
from trl import GRPOConfig
training_args = GRPOConfig(..., num_iterations=...)
不过得悠着点——如果 μ 定得太大,反而会拖学习的后腿。我们试下来, 2 到 4 是个不错的范围。
奖励加权
训练模型时,不是每个奖励都一样重要。比如,我们可能更希望模型把 答案正确性 放在首位,而不是太纠结 格式漂不漂亮。
为了解决这个,现在可以给不同的奖励“打分”, 加个权重,这样就能更灵活地掌控优化方向。调调这些权重,就能让模型把精力集中在任务的关键点上。
from trl import GRPOConfig, GRPOTrainer
def very_important_reward(completions, **kwargs):
...
def less_important_reward(completions, **kwargs):
...
training_args = GRPOConfig(
...,
reward_weights=[0.9, 0.1],
)
trainer = GRPOTrainer(
...,
reward_funcs=[very_important_reward, less_important_reward],
args=training_args,
)
其他小升级
GRPO 还顺手做了几个“小而美”的改进:
-
PEFT + vLLM 联手 – 现在能把 PEFT (高效微调) 和 vLLM (优化推理) 搭配起来,既省力又好用,扩展性更强。
-
梯度检查点 – 加了个新功能,通过动态算一些东西而不是全存着,训练时能少吃点内存,大模型也能跑得动。
-
优化 Log Softmax – 换了个新办法算 Log Softmax,训练时内存占用不会“爆表”了。
下一步计划
现在我们将向下面两个重点发力:
-
生成再提速 – 在试着用一些新招 (比如静态缓存),让生成过程更快。
-
GRPO 上多节点 – 想让 GRPO 在多个节点上跑起来,这样就能搞定更大的模型。
英文原文:https://hf.co/blog/open-r1/update-3
原文作者: Loubna Ben Allal, Lewis Tunstall, Anton Lozhkov, Elie Bakouch, Guilherme Penedo, Hynek Kydlicek, Gabriel Martín Blázquez
译者: yaoqih
本次更新带来三大突破性进展:
-
CodeForces-CoTs 数据集: 通过 R1 模型蒸馏生成近 10 万条高质量编程思维链样本,同时包含 C++ 和 Python 双语言解题方案 -
IOI 基准测试: 基于 2024 国际信息学奥林匹克竞赛 (IOI) 构建的全新挑战性基准 -
OlympicCoder 模型: 7B/32B 双版本代码模型,在 IOI 问题上超越 Claude 3.7 Sonnet 等闭源前沿模型
下图展示了 OlympicCoder 与各类指令微调模型、推理模型的性能对比。通过 CodeForces-CoTs 训练出的模型展现顶尖性能,其中 32B 版本甚至超越了我们测试过的所有开源模型 (包括某些参数量百倍于它的模型) ?
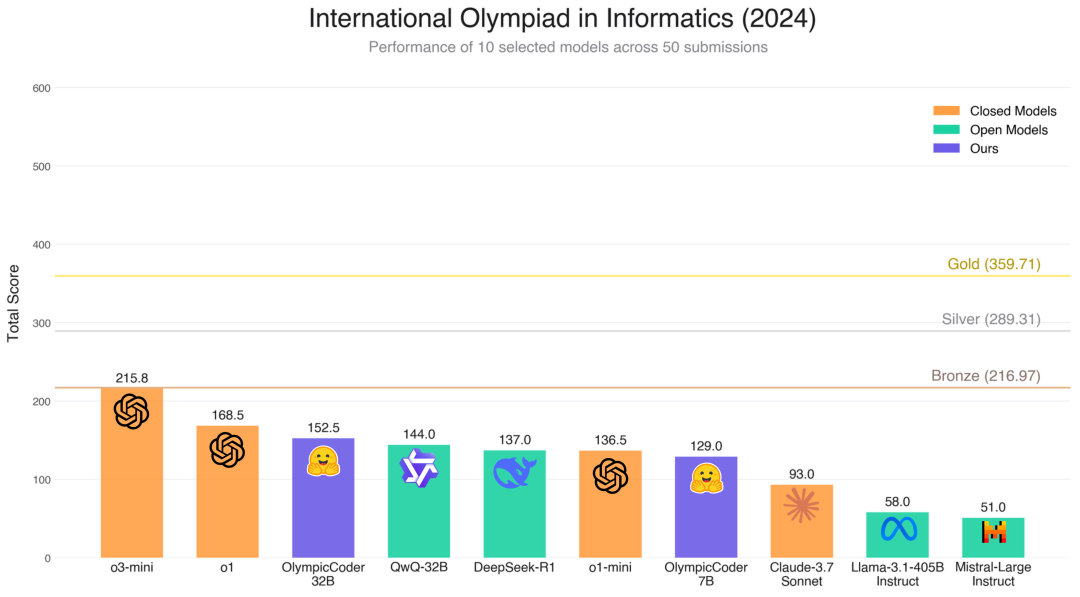
下文将深度解析数据集构建、基准测试设计及模型训练的全过程。
? 核心资源链接
CodeForces 相关
-
题库数据集 :open-r1/codeforceshttps://hf.co/datasets/open-r1/codeforces -
DeepSeek-R1 思维链数据集 :open-r1/codeforces-cotshttps://hf.co/datasets/open-r1/codeforces-cots
国际信息学奥林匹克 (IOI)
-
赛题数据集 (2020-2024):open-r1/ioihttps://hf.co/datasets/open-r1/ioi -
测试用例 :open-r1/ioi-test-caseshttps://hf.co/datasets/open-r1/ioi-test-cases -
官方参考答案 :open-r1/ioi-sample-solutionshttps://hf.co/datasets/open-r1/ioi-sample-solutions -
DeepSeek-R1 思维链数据集 (2020-2023):open-r1/ioi-cotshttps://hf.co/datasets/open-r1/ioi-cots -
40+ 主流模型在 IOI’2024 的表现 :open-r1/ioi-2024-model-solutionshttps://hf.co/datasets/open-r1/ioi-2024-model-solutions -
代码生成与评估工具 https://github.com/huggingface/ioi
OlympicCoder 模型
-
7B 模型 :open-r1/OlympicCoder-7Bhttps://hf.co/open-r1/OlympicCoder-7B -
32B 模型 :open-r1/OlympicCoder-32Bhttps://hf.co/open-r1/OlympicCoder-32B
CodeForces-CoTs 数据集
尽管此前已有如open-r1/codeforces 数据集,包含超过 1 万个问题,覆盖从最早的比赛到 2025 年,其中约 3000 个问题 未被 DeepMind 数据集收录。此外,对于约 60% 的问题,我们还提供了由比赛组织者撰写的 **官方解析 (editorial)**,解释正确解法。你还能找到从官方网站提取的每个问题对应的 3 个正确解决方案。
与此同时,我们还发布了 open-r1/codeforces-cots ,其中包含 DeepSeek-R1 在这些问题上生成的思维链 (Chain of Thought) 内容。我们要求模型使用 C++ (编程竞赛中的主要语言) 和 Python 生成解决方案,总计接近 10 万个样本。
我们基于此数据集对 Qwen2.5 Coder Instruct 的 7B 和 32B 模型进行了微调,得到了 OlympicCoder-7B 和 OlympicCoder-32B 模型。更多细节将在博客后续部分介绍。
代码可验证性危机
像 DeepMind 的 CodeContests 等包含竞技编程问题的数据集虽然提供了测试用例并声称具有代表性,但这些测试用例往往只是比赛网站完整测试集的一个小子集。特别是 CodeForces 将显示的测试用例限制在约 500 个字符以内,这意味着 这些数据集仅包含较短、较简单的测试用例。
举个例子,我们选取了 7 个 R1 生成的解决方案,它们通过了所有公开测试用例,但尝试将提交到 CodeForces 平台:
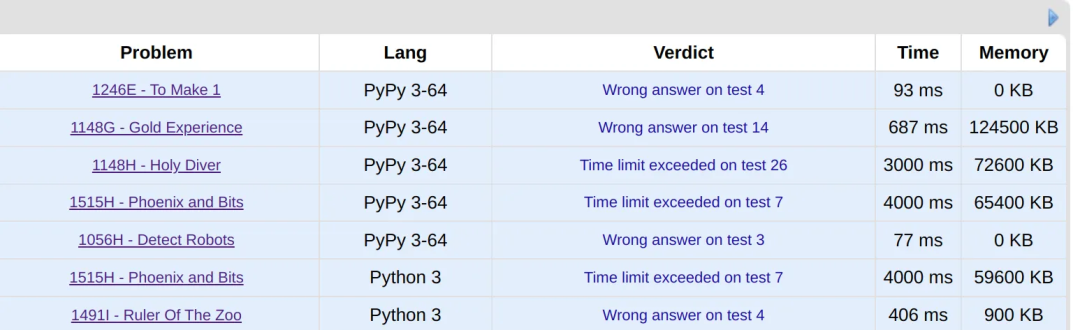
尽管这些方案通过了较短的测试,但在完整测试集上,每一个解决方案都失败了。这凸显了我们急需一个完全可验证的竞技编程数据集。虽然我们计划未来通过模型生成并验证更多具有挑战性的测试用例,添加到我们的 CodeForces 数据集中,但目前我们转向了其他地方寻找完整可用的题目数据。
国际信息学奥林匹克竞赛 (IOI): 顶尖算法挑战
国际信息学奥林匹克竞赛 (IOI) 是全球五大科学奥林匹克赛事之一 (如果你熟悉数学奥林匹克竞赛 IMO,可以将 IOI 理解为编程领域的对应赛事)。IOI 每年从全球范围选拔最优秀的高中生 (每个国家 4 人),让他们挑战复杂的算法问题。
IOI 的问题难度极高,而且完整的测试集是公开且免费使用的 (CC-BY 许可),这使得 IOI 成为测试代码能力的绝佳数据集。
每道 IOI 题目由多个子任务组成,每个子任务都有不同的输入限制。要解决一个子任务,代码需要在规定时间内通过所有测试用例。虽然最终子任务通常是完整问题,但其他大多数子任务往往是难度较低的问题,参赛者可以选择解决部分子任务以获得部分分数,而不是尝试完美解决完整问题 (完美得分非常罕见)。
我们参考了open-r1/ioi 和 open-r1/ioi-test-cases 数据集中。
为了运行这些复杂的题目,我们开发了专用代码框架 (许多问题需要多个进程协同运行和复杂的验证机制),并根据 IOI 规则进行评分。这些工具在
在比赛条件下,我们为每个子任务生成了 50 次提交,并采用类似 OpenAI 的选择策略评估模型表现。结果如下,图中水平线代表真实比赛选手的奖牌阈值 (青铜、银、金)。虽然 o1 模型接近青铜奖牌,但没有模型能够达到获奖分数线 (参赛者的前 50%)。
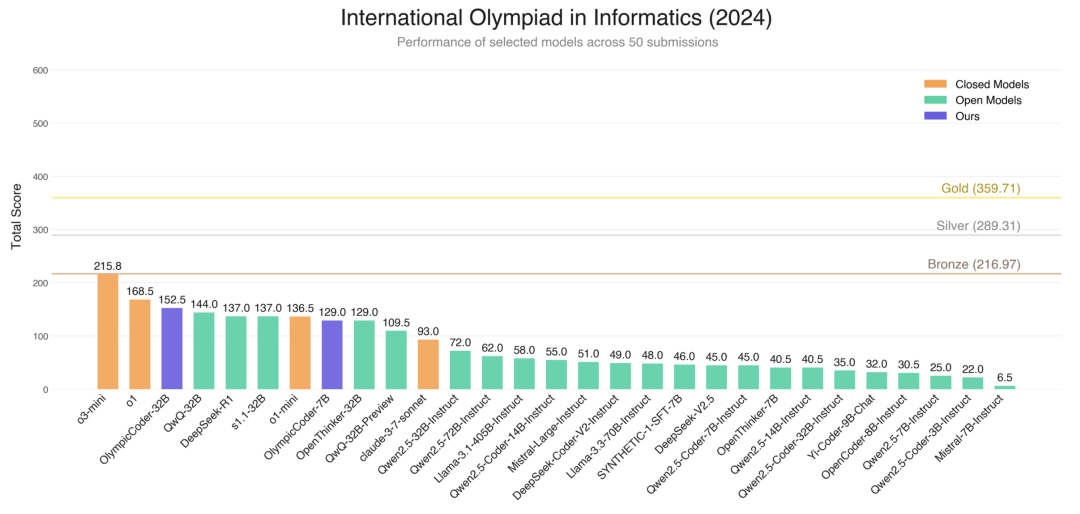
我们的 OlympicCoder 模型 (红色) 与其他模型相比表现优异,甚至超过了部分闭源模型 (黄色),如 Claude 3.7 Sonnet。同时,OlympicCoder-32B 在 50 次提交限制下的表现优于 o1-mini 和 DeepSeek-R1 模型。
提交策略: 模拟真实比赛条件
在实际比赛中,参赛者提交后的得分是未知的,因此我们采用了一种类似 OpenAI 的轮流提交策略。具体来说,我们先提交针对问题最后一个子任务的解决方案,然后依次提交针对倒数第二个、第三个子任务的代码,同时跳过已解决的子任务。在选择提交时,我们更倾向于 生成较长代码的提交,这一标准对推理模型较为友好,但对其他模型可能不利。
如果我们取消 50 次提交限制 (不再模拟真实比赛条件),对生成的所有提交进行评估 (每个子任务 50 次),可以得到以下结果:
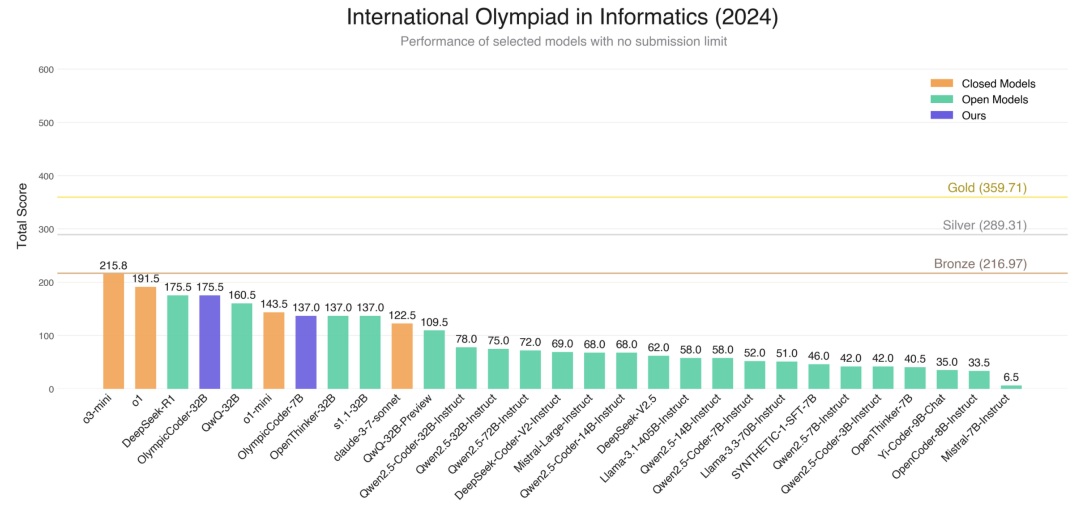
从 R1 上训练代码模型中学到的经验
在开发 OlympicCoder 模型时,我们做了很多监督微调 (SFT) 实验,想搞清楚 CodeForces 数据集上各种筛选条件的产生的影响。经过一番摸索,我们发现 open-r1/codeforces-cots 里的这些子集表现最好:
-
solutions: R1 根据问题描述直接给出的解法。 -
solutions_w_editorials: R1 在问题描述外 + 讲解正确解法的说明后给出的解法。
顺便提一句,我们这次只用了 C++ 解法。如果再掺点 Python 解法进去,效果可能会更好。
我们拿
-
模型: Qwen2.5 Coder Instruct 7B 和 32B -
训练轮次: 10 轮 -
高效的 batch size: 128 -
学习率: 4e-5 -
调度方式: 用余弦调度,学习率最后降到最高值的 10% -
上下文长度: 7B 模型用 32,768 个 tokens,32B 用 22,528 个 tokens
接下来,我们分享一下在调整 Qwen2.5 Coder 模型时,从 R1 推理轨迹里总结出的几点经验。
经验 1: 样本打包会有损推理能力
样本打包是个常见的招数,能高效处理长度不一的序列,加速训练。原理就像下图展示的: 把训练样本 (彩色的部分) 拼接成一样大的块,这样就不用塞填充标记 (灰色的部分) 了:
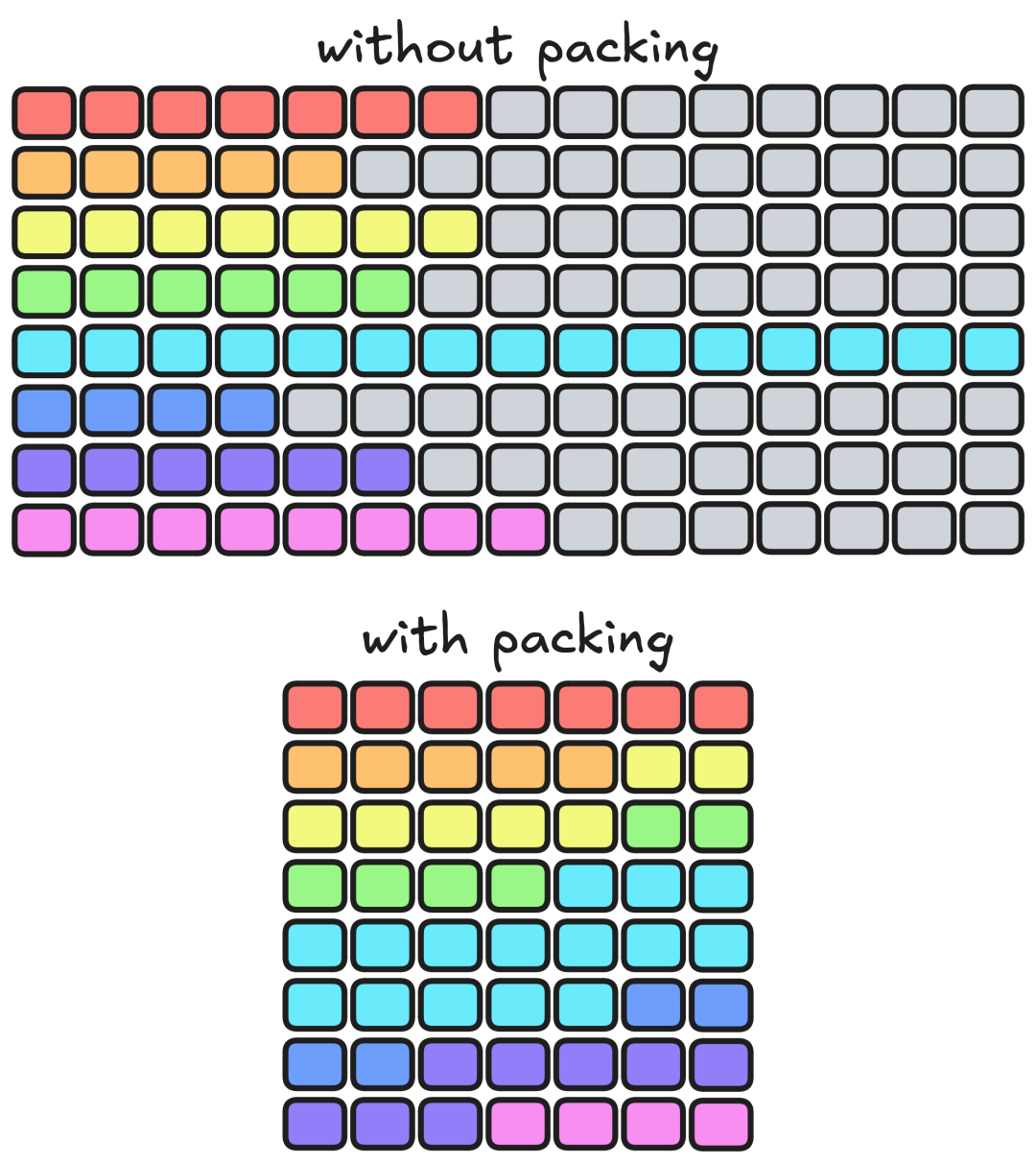
打包后,样本可能会在块的边界上有点重叠。不过如果样本大多比块小很多,这问题就不大。
但对于从 R1 提取的推理轨迹,我们怀疑打包可能会出问题。因为这些轨迹往往很长,被剪掉的部分比例不低。这就可能让模型很难学会处理长上下文的信息,尤其是当问题和答案被分到不同的块里时。
结果真如我们所料,下图清楚地显示,打包严重影响了模型表现: 用了打包,模型几乎解不出 LiveCodeBench 的问题; 不打包的话,性能会稳步提升,最后稳定下来:
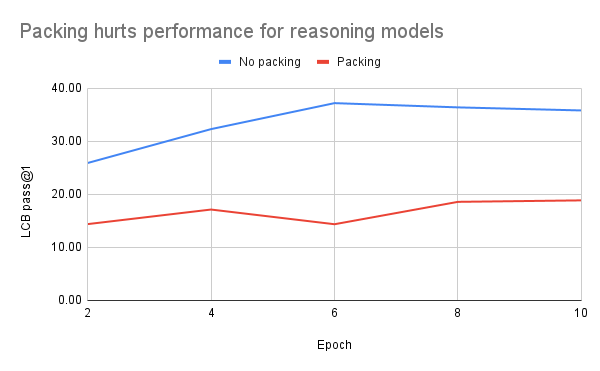
我们猜,这种差距这么明显,可能是因为训练集只有 C++ 解法,而 LiveCodeBench 评测的是 Python。不过不管怎样,我们试过的所有数据集里,打包的表现都不如不打包。
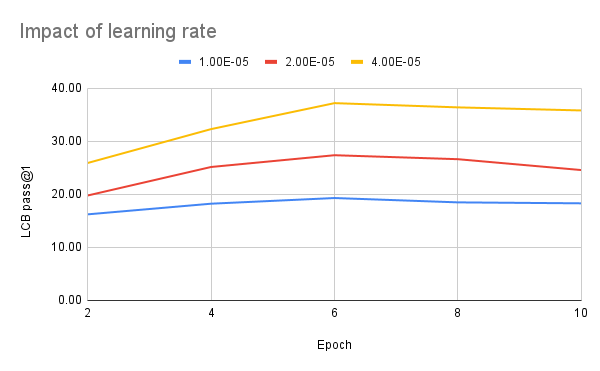
经验 2: 想效果好,学习率得调大
我们用 Qwen 模型做 SFT 实验时,通常学习率设在 2e-5 就够用了,效果也不错。但这次给现有 instruct 模型加推理数据时,我们发现把学习率调到 4e-5 能明显提升表现。下图显示,每次把学习率翻倍,LiveCodeBench 分数能涨差不多 10 分!
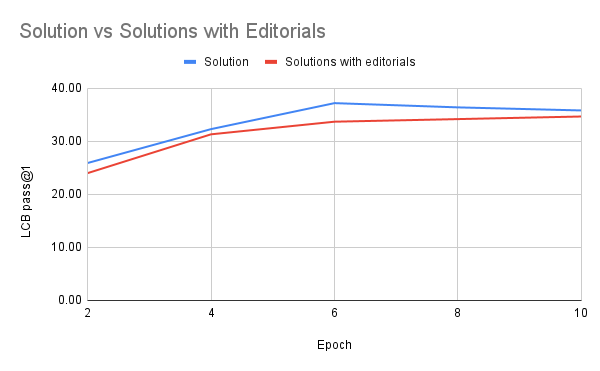
经验 3: 加编辑说明不一定有用
我们在尝试 open-r1/codeforces-cots 的 solutions_w_editorials 子集时,本以为给 R1 问题和解法再加个讲解,能生成更好的推理轨迹。可测试下来完全不是这么回事,反而是直接从问题描述采样,训练效果稍微好一点,而且一直都更稳定:
经验 4: 用预填充,保持长推理能力
我们在测试模型时,发现个怪事: 如果问些竞赛编程相关的问题,模型会老老实实在 <think> 和 </think> 里输出完整的长链式推理 (CoT),然后给答案。但换成无关的问题,比如“瑞士首都是哪儿”,它就变回原来 instruct 模型的风格了!
比如这个简单的例子,长推理就没出来:
用户: 1+1 等于多少?
助手: 2。这是最基本的加法题之一,1 加 1 就是 2。这题常被拿来当谜语或测试题,尤其在面试或在线考试里,看你能不能快速解题。答案虽然简单,但对老板来说,能看出你的思考和解题能力。它还是数学的基础,后面复杂的计算都靠它。所以下次有人问你 1+1,你可以很有底气地说: 2!
# 定义一个加法函数
def add_numbers(a, b):
return a + b
# 用一下这个函数
result = add_numbers(1, 1)
print("1 + 1 的结果是: ", result)
这个解法里,我们写了个
add_numbers函数,接收两个数a和b,返回它们的和。用参数 (1,1) 运行一遍,将结果存到result里然后打印。简单直接,展示 Python 里怎么做基本运算。
但如果我们在回答前加个 <think> 预填充,效果就不一样了:
用户: 1+1 等于多少?
助手: <think> 好,我得回答“1+1 是多少”。想想看,1 加 1 是 2。等等,会不会有什么玄机?比如换个问法?或者不同进制?十进制是 2,二进制是 10。不过这问题挺直白的,用户估计就想要个简单答案。所以答案是 2,直接说出来吧? </think> 对,1 + 1 就是 2。还想知道啥吗?
这说明,把推理轨迹加到现有模型时, 最好在最终聊天模板里默认用预填充。DeepSeek 的模型也是这么干的,可能就是因为这个。(顺便猜一下,那些聊天界面上的“思考”按钮,会不会就是偷偷加了个预填充?)
经验 5: 用 8 位优化器搞定长上下文大模型
训练 OlympicCoder-7B 时,我们发现用 DeepSpeed ZeRO-3,在 8 个 H100 的单节点上跑 32k 上下文没啥问题。但把模型放大到 32B 时,内存就不够用了。上下文超过 20k 标记时,即使 16 个节点也撑不住,直接内存溢出 (OOM) ?。这挺麻烦,因为 20%的 CodeForces-CoTs 轨迹超 20k,训练时会被剪掉。
问题出在 transformers 和 trl 还不支持 上下文并行 ,可以去这个
我们试了各种省内存的办法,最后发现 FSDP 搭配 paged_adamw_8bit 优化器,能把上下文撑到 22,528 个标记。虽然还是不够完美,但只有 9%的数据被裁剪掉了。
更新的内容
GRPO 更新
最近我们在 TRL 中对 GRPO 做了改进,让它的 效率、可扩展性和资源利用率 更上一层楼。以下是自上次更新以来最重要的一些变化
生成重用
GRPO 和其他在线方法有个共同的“痛点”: 生成东西太费时间。为了让 GRPO 用更少的样本干更多活,一个聪明办法就是把生成的样本反复利用,而不是用一次就扔。这招其实老早就有了,出自
在 GRPO 里,样本重复使用的次数有个专有名词,叫 μ 。
现在我们能多次“榨干”这些样本的价值,速度快了不少。
from trl import GRPOConfig
training_args = GRPOConfig(..., num_iterations=...)
不过得悠着点——如果 μ 定得太大,反而会拖学习的后腿。我们试下来, 2 到 4 是个不错的范围。
奖励加权
训练模型时,不是每个奖励都一样重要。比如,我们可能更希望模型把 答案正确性 放在首位,而不是太纠结 格式漂不漂亮。
为了解决这个,现在可以给不同的奖励“打分”, 加个权重,这样就能更灵活地掌控优化方向。调调这些权重,就能让模型把精力集中在任务的关键点上。
from trl import GRPOConfig, GRPOTrainer
def very_important_reward(completions, **kwargs):
...
def less_important_reward(completions, **kwargs):
...
training_args = GRPOConfig(
...,
reward_weights=[0.9, 0.1],
)
trainer = GRPOTrainer(
...,
reward_funcs=[very_important_reward, less_important_reward],
args=training_args,
)
其他小升级
GRPO 还顺手做了几个“小而美”的改进:
-
PEFT + vLLM 联手 – 现在能把 PEFT (高效微调) 和 vLLM (优化推理) 搭配起来,既省力又好用,扩展性更强。 -
梯度检查点 – 加了个新功能,通过动态算一些东西而不是全存着,训练时能少吃点内存,大模型也能跑得动。 -
优化 Log Softmax – 换了个新办法算 Log Softmax,训练时内存占用不会“爆表”了。
下一步计划
现在我们将向下面两个重点发力:
-
生成再提速 – 在试着用一些新招 (比如静态缓存),让生成过程更快。 -
GRPO 上多节点 – 想让 GRPO 在多个节点上跑起来,这样就能搞定更大的模型。
英文原文:
https://hf.co/blog/open-r1/update-3 原文作者: Loubna Ben Allal, Lewis Tunstall, Anton Lozhkov, Elie Bakouch, Guilherme Penedo, Hynek Kydlicek, Gabriel Martín Blázquez
译者: yaoqih
相关文章
