本公众号主要关注NLP、CV、LLM、RAG、Agent等AI前沿技术,免费分享业界实战案例与课程,助力您全面拥抱AIGC。
-
SmolDocling基于 Hugging Face 的 SmolVLM-256M 构建,该模型在参数数量上比同类文档理解任务调整的视觉-语言模型小 5 到 10 倍。 -
视觉骨干采用 SigLIP base patch-16/512(93M)其训练数据经过重新平衡,以强调文档理解(41%)和图像描述(14%)。 -
通过增加像素到标记的比率至每标记 4096 像素,并引入子图像分隔符的特殊标记,提高了标记化效率。 -
语言骨干采用轻量级的 SmolLM-2 家族(135M),并采用激进的像素洗牌方法,将每个 512×512 的图像块压缩为 64 个视觉标记。 -
该模型通过生成一种名为 DocTags 的新通用标记格式,全面处理整页文档,捕捉页面元素的全部上下文及其位置信息。 -
SmolDocling 在多种文档类型(包括商业文件、学术论文、技术报告、专利和表单等)中表现出色,能够正确复现代码列表、表格、公式、图表、列表等元素。 -
针对图表、表格、公式和代码识别的新型公开数据集。
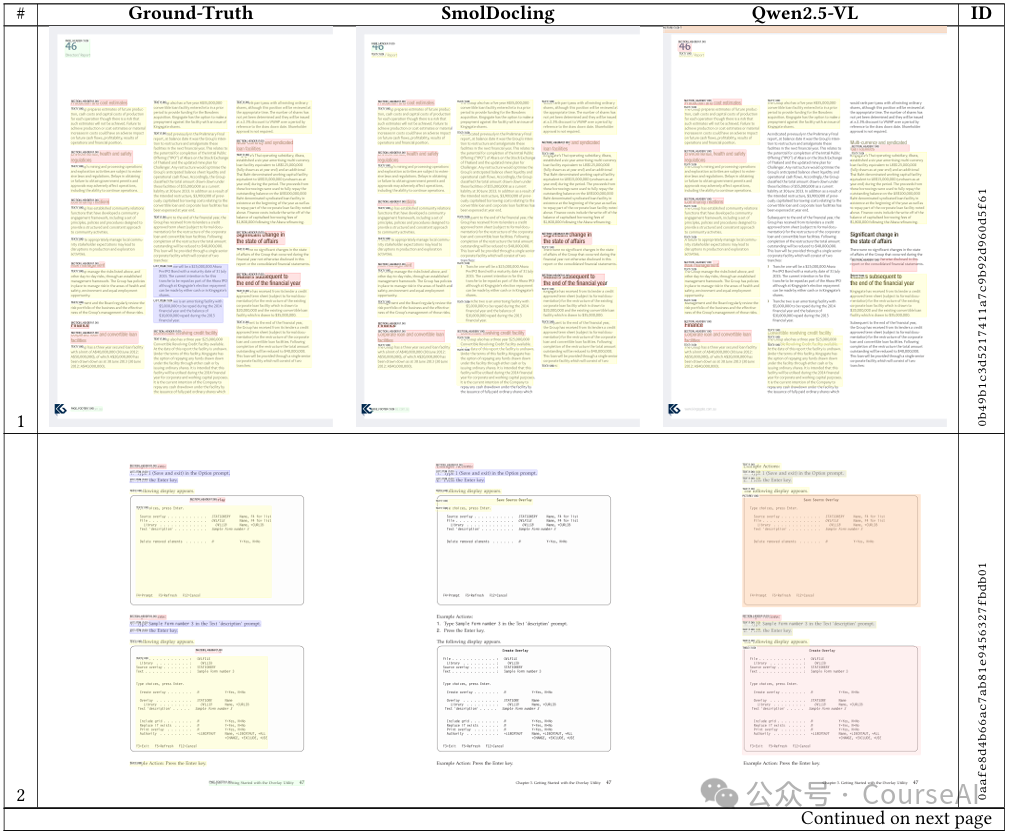
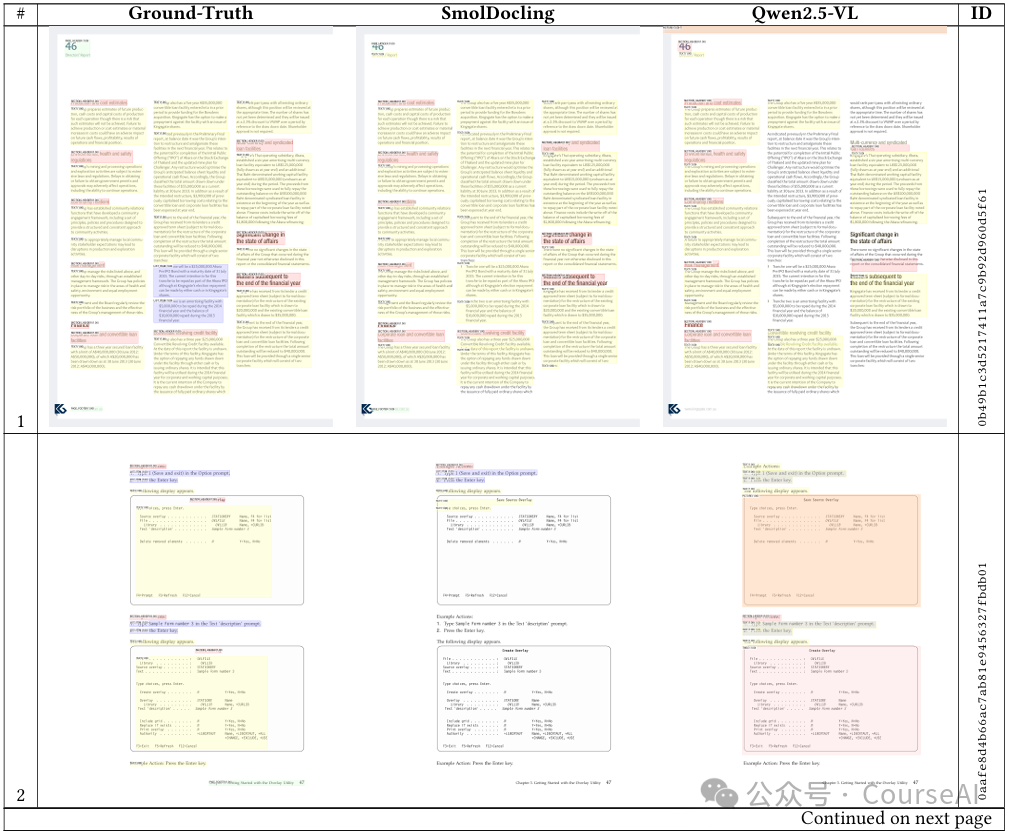
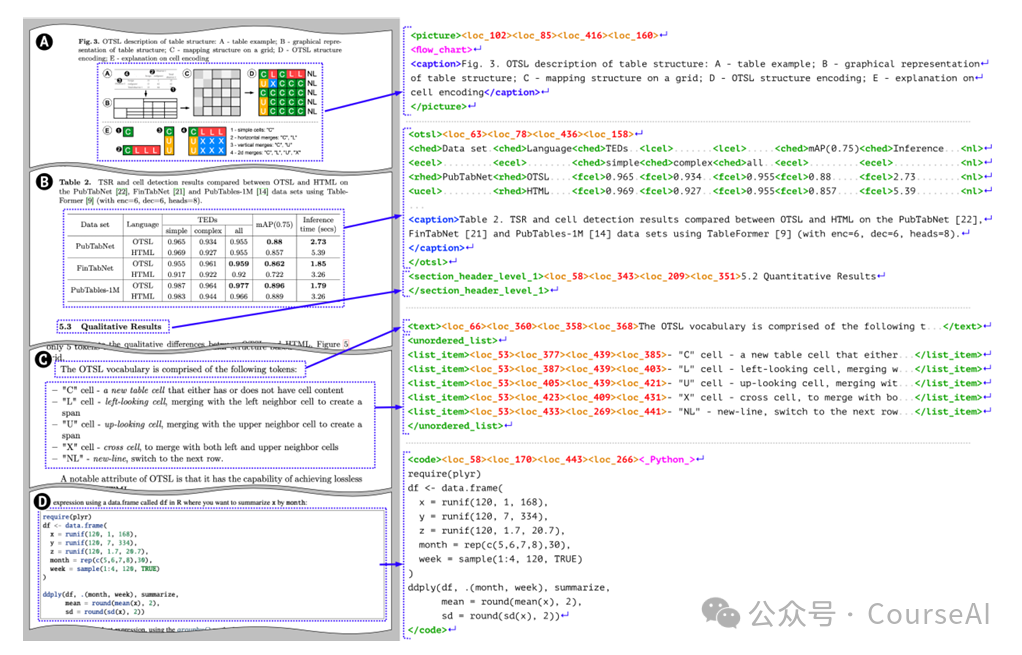
SmolDocling架构
-
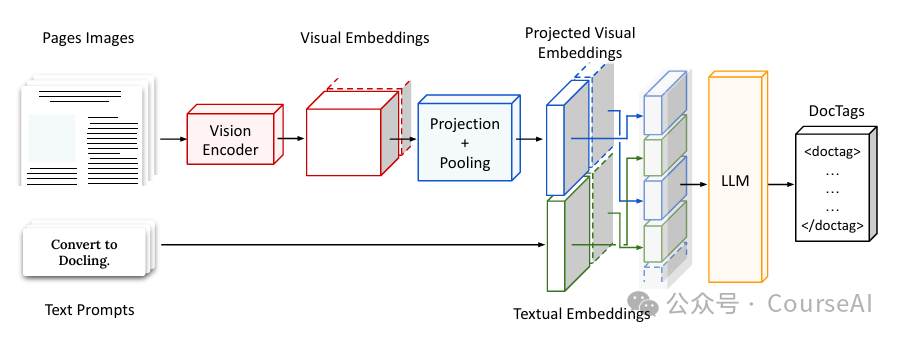
输入图像编码:输入的文档页面图像首先通过视觉编码器进行编码,然后通过投影和池化进行重塑。 -
标记化和嵌入:将投影后的嵌入与用户提示的文本嵌入进行拼接,可能还会进行交错处理。 -
自回归预测:将拼接后的序列输入到语言模型中,自回归地预测 DocTags 序列。
假设有一个包含文本、表格和图表的文档页面图像,SmolDocling 将该图像转换为 DocTags 序列。
例如,文本内容将被封装在 <text> 标记中,表格结构将使用 OTSL 标记(如 <fcel>、<ecel> 等)表示,图表将被封装在 <picture> 标记中,并可能包含 <caption> 标记以表示图表标题。
DocTags 格式
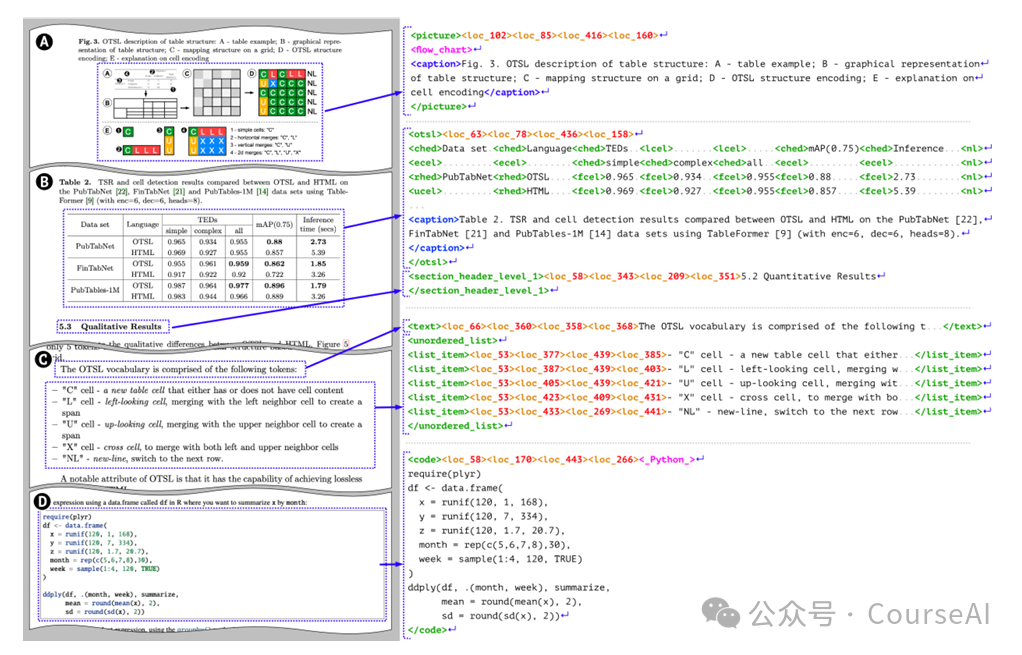
DocTags 受 OTSL 启发,定义了一个结构化的词汇表和规则,明确区分文本内容和文档结构,减少了图像到序列模型的混淆。
-
DocTags 使用 XML 风格的标记来封装基本元素的文本内容,并定义了如文本、标题、脚注、公式、列表项等文档块类型。 -
每个元素都可以嵌套额外的位置标记,以编码其在页面上的位置,形式为 <loc_x1><loc_y1><loc_x2><loc_y2>。 -
对于特殊块(如表格和图像),DocTags 还嵌套了额外的描述符,用于标题、表格结构或图像类别。 -
为了促进文档理解流程中稳健的视觉-语义对齐,保持了裁剪页面元素(如表格、代码、公式)的统一 DocTags 表示,使其与完整页面对应物相同
训练流程
-
首先,将 DocTags 作为标记纳入分词器,并冻结视觉编码器,仅训练剩余网络以适应新的输出格式。 -
为了确保涵盖所有 DocTags,训练过程中保持了任务和数据类型的平衡混合。 -
接下来,解冻视觉编码器,并在预训练数据集以及所有特定任务的转换数据集(包括表格、代码、公式和图表)上训练模型。 -
最后,使用所有可用数据集进行微调。
预训练数据集
-
DocLayNet-PT -
包含 140 万页的数据集 -
从 DocFM 数据集中提取,涵盖了来自 CommonCrawl、维基百科和商业相关文档的独特 PDF 文档。 -
该数据集通过一系列处理步骤进行了弱标注,包括布局元素、表格结构、语言、主题和图像分类的标注。 -
Docmatix -
为了保留 SmolVLM 的原始 DocVQA 能力,对 Docmatix 数据集中的 130 万文档应用了与 DocLayNet-PT 相同的弱标注策略,并引入了将多页文档转换为 DocTags 的指令。
特定任务的数据集
-
布局: -
为了优化文档布局和表格结构的预测质量,从 DocLayNet-PT 中抽取了 76K 页进行人工标注和严格的质量审查,形成了 DocLayNet v2 数据集。 -
从 WordScape 中提取了 63K 页,并合成生成了 250K 页的 SynthDocNet 数据集,以增强模型对不同布局、颜色和字体的适应能力。 -
表格: -
在 PubTables-1M、FinTabNet、WikiTableSet 和从 WordScape 文档中提取的表格信息上训练模型,并将表格结构信息转换为 OTSL 格式。 -
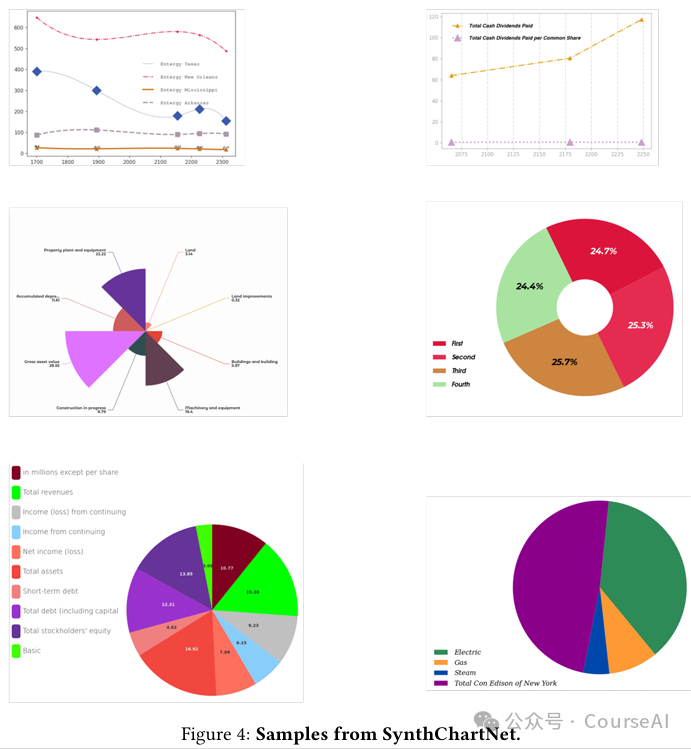
图表: -
为了填补现有图表数据集在数量和视觉多样性方面的不足 -
使用来自 FinTabNet 数据集的 90,000 个表格数据生成了包含 250 万张视觉多样图表的 SynthChartNet 数据集。
-
代码: -
为了满足技术书籍和科学文档中代码片段处理的需求 -
使用 LaTeX 和 Pygments 生成了包含 56 种编程语言的 930 万段视觉多样代码的 SynthCodeNet 数据集。

-
公式: -
结合公开数据集和从 arXiv 提取的公式,创建了一个包含 550 万独特公式的 SynthFormulaNet 数据集。

https://huggingface.co/ds4sd/SmolDocling-256M-preview
https://github.com/AIAnytime/SmolDocling-OCR-App
https://arxiv.org/pdf/2503.11576
推荐阅读
-
19.2KStar 超级Agent,超LangGraph5000倍的
-
GraphRAG性能拉胯,DeepSearcher开箱即用
-
3.7K Star!GraphRAG不香了~
-
修复低质扫描件PDF:不怕页面扭曲、字体模糊
-
HuggingFace出品:极简且强大的Agent
-
Alibaba出品:OmniParser通用文档复杂场景下OCR抽取
-
清华、面壁智能发布:主动式Agent 2.0
-
Alibaba发布:可编辑CoT,超越ReAct20%
-
微软发布:工业级Agent落地方案RDAgent
-
Alibaba开源UReader:通用免OCR文档理解
-
PDF转中文,版式还原、文字、公式识别、英译中全都要
-
文档OCR版式识别,兼顾速度与精度,YOLO当首选
相关文章
