导读 本文将分享蚂蚁最新的基于 Ray 的分布式 Agent 框架,Ragent。
主要内容包括以下几个部分:

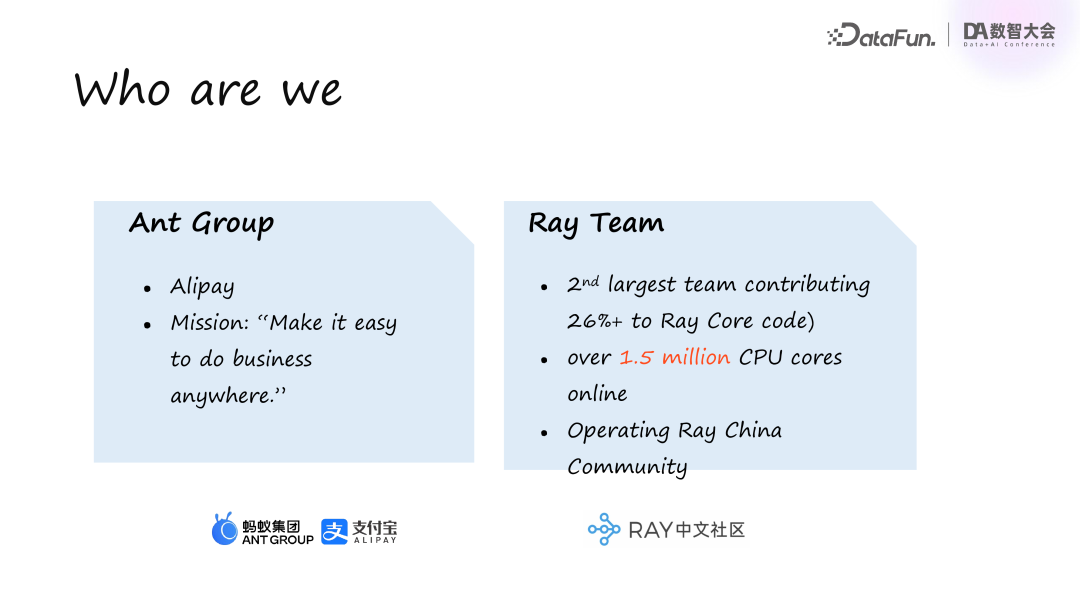
相信很多人都了解 Ray,它是 OpenAI 用于大模型训练的底层分布式框架。蚂蚁集团早在很久之前就加入了 Ray,且今年 Ray 的 CEO 在夏季发布会上也提到,蚂蚁是第一个正式使用并协作开发 Ray 的团队。我们贡献了超过 26% 的 Ray 核心代码,是全球第二大贡献团队。目前,蚂蚁集团在线上运营着超过 150 万 CPU 核心,规模已相当庞大,同时我们也在运营 Ray 在中国的社区。
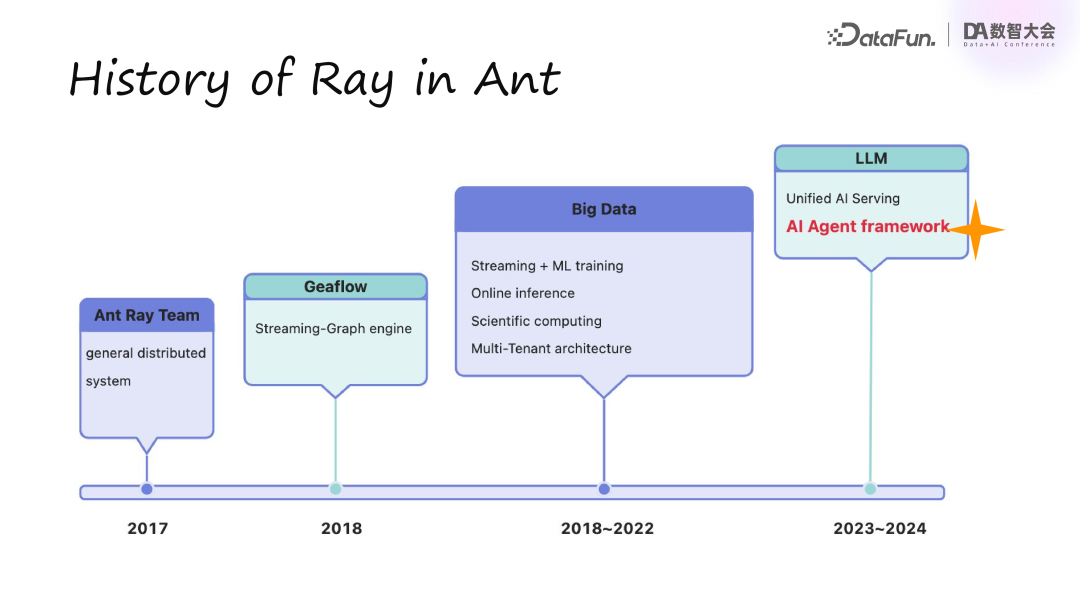
简单介绍一下 Ray 在蚂蚁内部的发展情况。我们在 2017 年成立了 Ray 团队,并于 2018 年推出了首个业务场景流图计算引擎 Geaflow。在 2018 年至 2022 年间的大数据时代,我们基于 Ray 开发了多个计算引擎,如用于流计算和机器学习训练的 Realtime、Mobius 开源引擎,以及在线推理和科学计算引擎 Mars。同时,我们也贡献了 Multi-Tenant 架构,Ray 社区今年才开始考虑这种架构,而蚂蚁因线上集群规模庞大,早已开始考虑多租户。
在 2023 到 2024 年大模型时代,我们在美国完成了一项工作 Unified AI Serving,将离线、在线与 AI 推理、AI 部署整合为一个框架,这是我们 150 万内核业务的核心场景之一。接下来将介绍我们的最新工作,基于 Ray 构建的 AI Agent 框架,主要分为三个部分:背景、动因,以及设计与实现。
Background
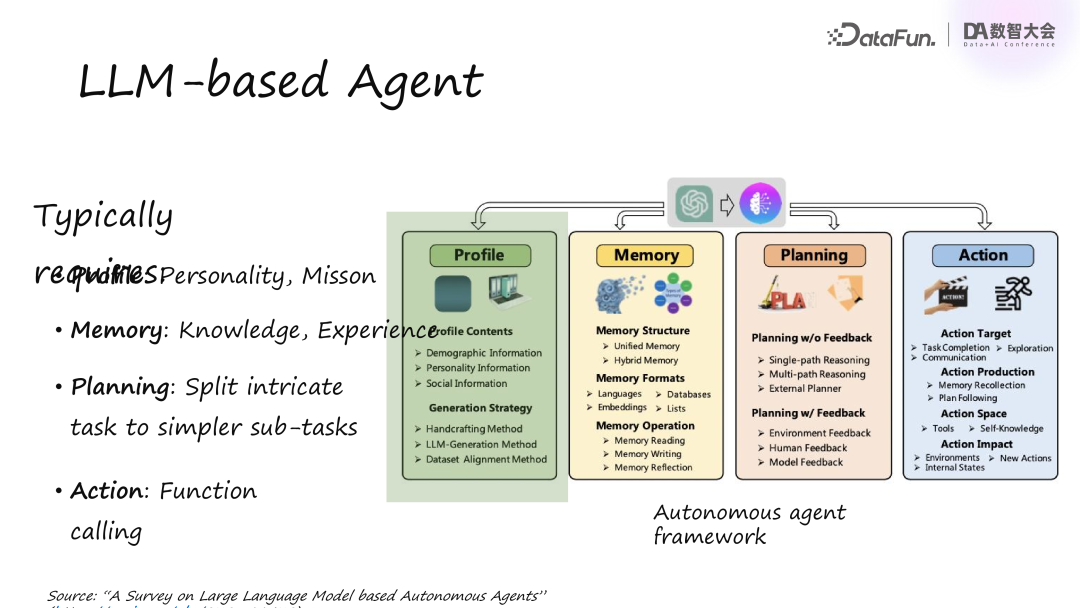
首先来看一下基于大语言模型的 Agent(LLM-based Agent)通常需要哪些模块。
-
第一个是 Profile 模块,它定义了 Agent 的个性,即扮演怎样的角色,比如它可以是一个温和的旅游助手,执行旅游管理、数据分析等任务。
-
第二个是 Memory 模块,包括两部分:一是 Knowledge,包含行业知识和先验知识;二是 Experience,记录 Agent 过去的对话、用户问题、思考过程及行动结果,这些经验将帮助 Agent 改进后续的行为,避免重复错误。
-
第三个是 Planning 模块,用于将复杂任务拆解成更容易执行的子任务。通过这种方式,Agent 可以在文本交互的基础上完成更广泛的任务。Planning 常见的算法有 Chain of Thought和Tree of Thought,这些就像程序设计中的流程图,用来拆解复杂问题。
-
第四个是 Action 模块,根据经验和规划执行实际任务。与大模型不同,Agent 不仅仅是文本或图像输入输出,而是能对现实世界产生实际影响。Action 模块的一个关键功能是 Function Calling,让模型调用外部功能,甚至在某些场景中与机械臂等物理设备交互。
这四个模块是我们认为一个基于大语言模型的 Agent 所需的核心组件。
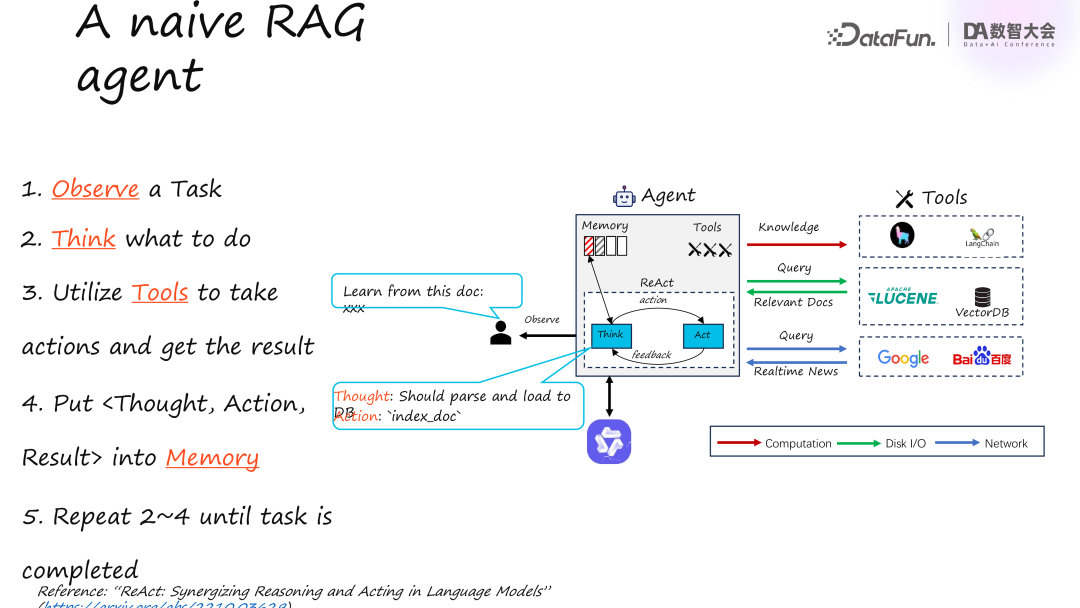
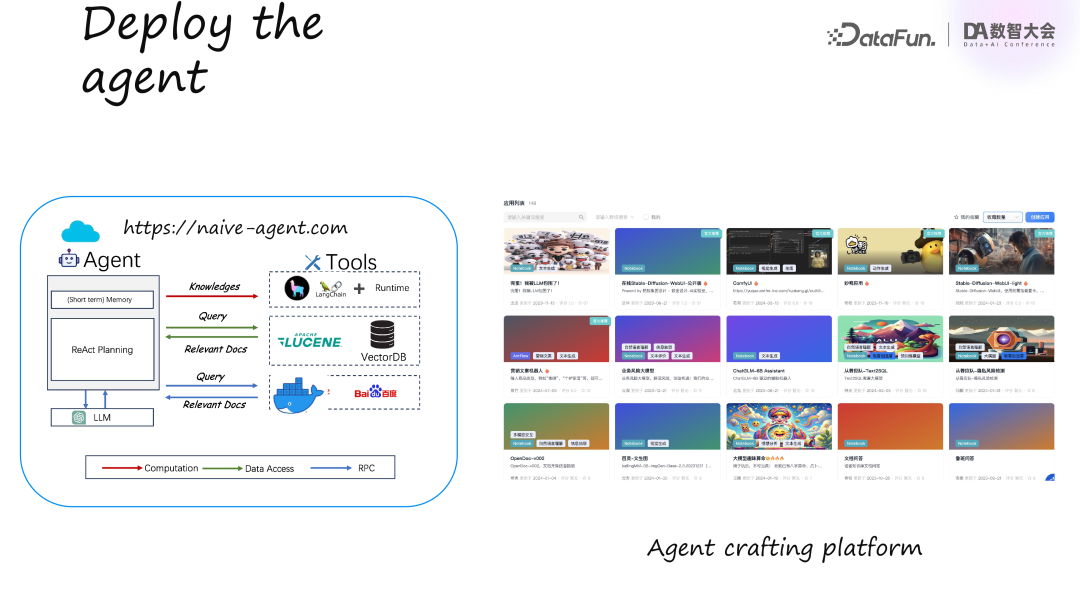
我们来看一个简单的基于 Agent 实现的 RAG 流程。这个 RAG 不同于传统的计算图或工作流,而是通过 Agent 来实现的。
-
首先,Agent 会从用户那里获取任务,例如用户要求从文档中学习知识,提供了文档链接。
-
第二步,模型进入思考阶段,决定如何开展任务。这里可以使用 planning 模块中的算法,如 React 或 Chain of Thought。在这个流程中,我们使用了 React 策略,即思考一步,执行一步。
-
第三步,模型决定采取具体行动。对于 RAG 场景,可以使用工具如 LlamaIndex 或 LangChain 对文档进行解析,或调用 Lucene 和 VectorDB 进行语义检索,甚至进行实时搜索。
-
第四步,将初始思考、选择的行动及其结果作为三元组(triplet)存储到 Memory 中,来指导后续工作。
-
特别需要注意的是,右边的工具分为三类:红色的 LlamaIndex 用于计算(CPU/GPU 密集型),绿色的 DB 和 Lucene 访问为 Disk I/O,蓝色的则是网络访问。Agent 任务中涉及这三种不同的计算任务,传统模式可能只处理 CPU 或 CPU+IO,但在这里,一个单任务可能包含复杂的混合工作负载。
在完成 naive RAG Agent 的实现后,接下来就是部署上线。首先,我们将程序封装成一个服务,放入 Docker 中,然后进行部署。我们的 Agent 平台已经有大约 500 个 Agent,开发者可以在平台上使用画布构建并发布他们的 Agent。上图中就是我们的一些案例。
最初,我们的做法很简单,但很快收到了很多用户抱怨。用户常见的问题包括:不清楚为什么 APP 或 Pod 崩溃、缺乏监控 metrics、没有工作负载监控、无法控制流量等。此外,由于混合工作负载,GPU 利用率通常很低。总结起来,这种简单的做法显然不适合生产环境。因此,我们决定将 Agent 平台分布式化,进行生产化改造。在这个过程中,我们发现场景中确实有许多独特的挑战。
Motivation
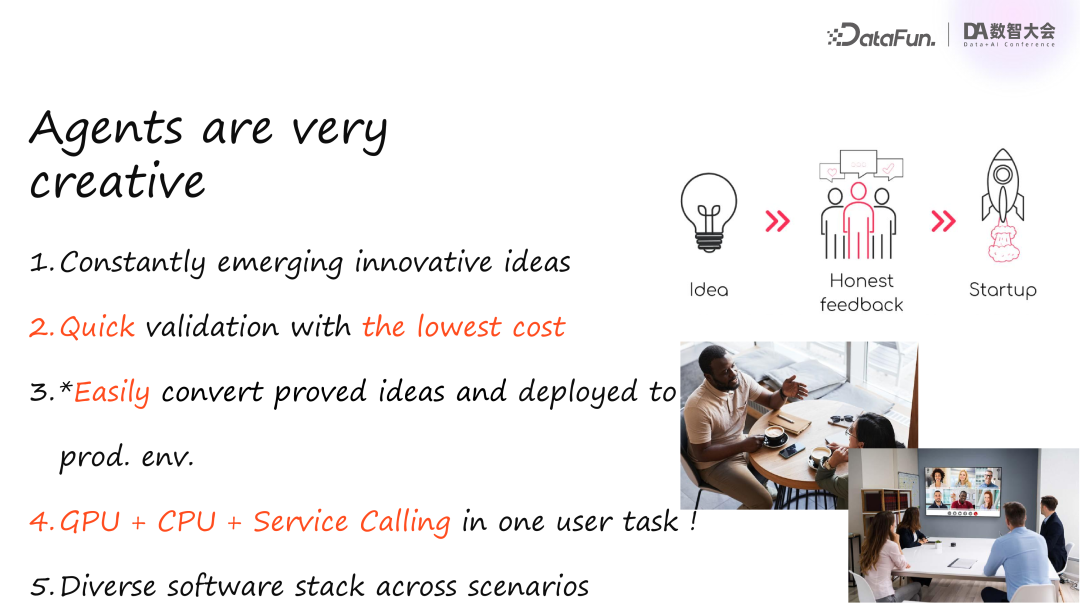
相较于传统计算或服务型 APP,我们认为 Agent 应用具有高度创造性,不断涌现出革命性的创意,这也是近年来大模型和 Agent 概念火热的原因。大家发现这些应用非常有趣,并且持续有新创意涌现,每个创意都需要快速低成本验证,这在创业和商业中尤为重要。
一旦 PoC 验证有效,就希望能迅速部署到线上,但这一步非常困难。上线应用涉及众多模块:服务、数据库、数据来源、分布式框架等,对大公司而言,需要与多个团队合作,小公司虽不需多个团队,但仍需掌握所有技术。因此,PoC 到上线的过程繁琐且漫长。此外,用户任务可能同时涉及 GPU、CPU 和 Service Calling,且 Agent 覆盖不同业务场景,每个场景的技术栈不同,需要大量兼容适配工作。
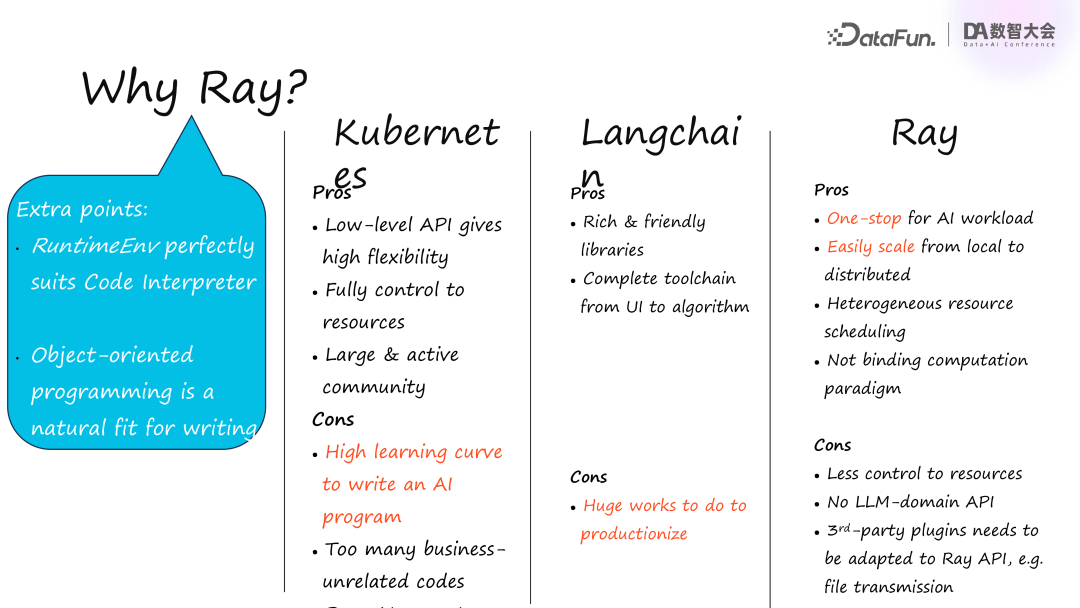
在分布式 Ray 生产化 Agent 过程中,我们对比了三个技术栈层级:底层的 Kubernetes(简称 K8S)、上层的算法库 LangChain 和中间层的 Ray。Ray 之所以居于中间层,是因为它涵盖丰富的 AI 生态,如 Ray Data 用于数据处理和服务化,以及强化学习和训练。Ray 紧贴 K8S,为分布式执行调度提供支持。
Kubernetes 的优势在于底层 API 的灵活性,允许编写各种 CRD 并整合多种硬件,提供资源控制的完整性;但其缺点是从零开发 AI 程序非常复杂。我们与基于 K8S 的团队交流发现,许多机器学习工程师并不熟悉 K8S。在蚂蚁集团,算法工程师离掌握 K8S 还有较远距离,这种学习曲线使得我们不太可能直接让终端用户使用 K8S。此外,Kubernetes 的 AI 生态相对简陋,主要因其重心仍在底层。
LangChain 作为上层算法库,优点在于丰富且易用,类似的 LlamaIndex 库也非常易上手。它甚至提供 UI 功能,可以一站式开发 Agent 或大模型。然而,其缺点是仅为单机 API。在我们上线简易版 LangChain 后,发现面临许多生产化问题,每个问题都需解决。
接下来我们考虑使用 Ray。Ray 的优势在于提供了一站式的工具箱,支持 AI 工作负载的数据处理、训练和推理。Ray 的一个主要功能是轻松将本地代码转为分布式代码,只需简单加注解即可实现远程进程。并且它在异构资源调度方面表现出色,尤其在 CPU 与 GPU 混合的数据处理中性能优于 Spark。Ray 不绑定特定计算范式(如 MapReduce 或图计算),而是采用纯分布式面向对象编程,提供了高度灵活性。
不过,Ray 也有一些不足:在资源管控上不如 K8S 灵活,因为它是在 K8S 之上再加一层;另外,目前 Ray 在大模型上没有特定 API,一些外部组件如文件传输,需要在 Ray API 中额外封装。
综上,我们最终选择了 Ray,同时也考虑了一些额外的加分项。例如,Ray 的 RuntimeEnv 功能提供了运行时沙箱,利用 container 执行用户代码,非常适合大模型场景中的代码解释器。它能够直接启动一个 Docker 容器,而在其他团队中需要额外工作。另一个优势是 Ray 的面向对象编程模式,与 Agent 的工作模式相似。Agent 的个性和配置可以视为对象的静态资源,操作为成员函数,记忆则是运行时状态,因此 Agent 很像一个对象。
决定使用 Ray 后,我们自然开始开发一个基于 Ray 的 Agent 框架。主要考虑点如下:①该框架需提供 Agent 的 API;②利用 Ray 实现从本地代码到支持异构资源的分布式代码的扩展;③在多 Agent 场景中,每个 Agent 都是一个分布式进程,我们需要一个框架来协调这些进程,即所谓的 environment;④要兼容不同的库,如 MetaGPT 和 AutoGen;⑤希望利用 Ray 的沙箱(sandbox)、批处理能力和跨源调度功能。
Design & Impl.
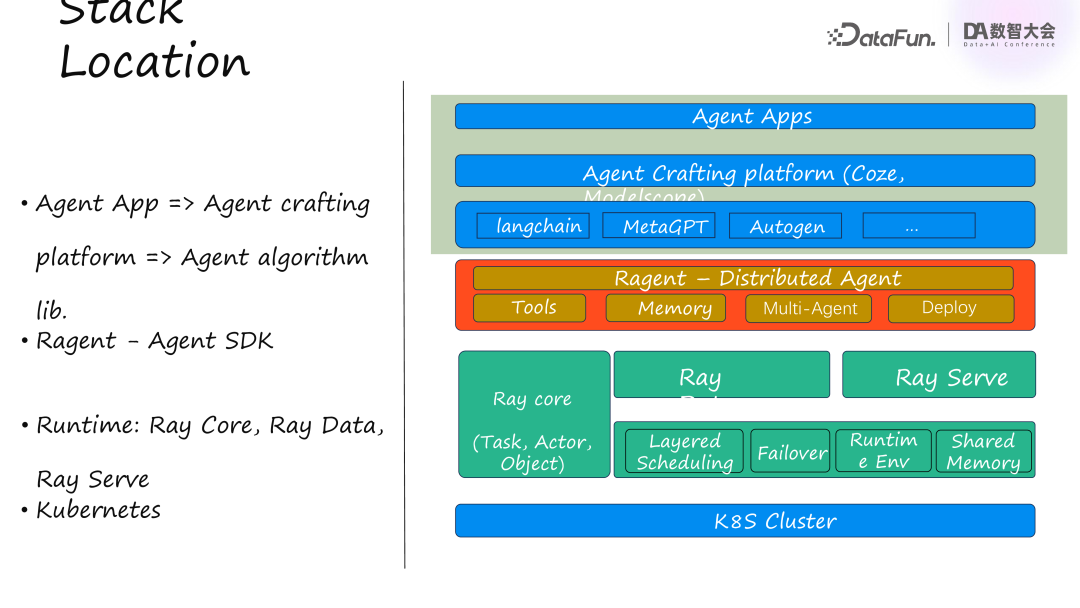
在软件技术栈中,我们使用 Ray 分为以下几层:最上层是业务层,包括开发者已编写的 Agent Apps。其下是 Agent Crafting Platform,这是开发者构建 Agents 的平台。再下一层是算法库,如 LangChain 和 MetaGPT,提供与大模型相关的算法和文档解析功能,这些不在我们的框架实现范围内。
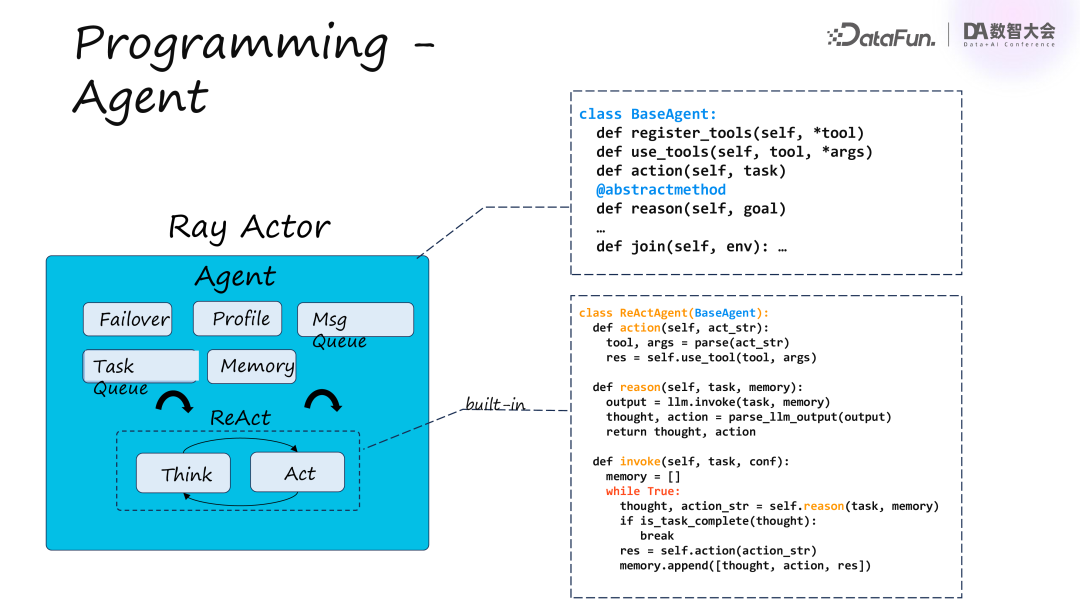
在这三个业务层之下是 Ragent,它提供分布式 Agent SDK 和执行层,支持 Agent 所需的工具、记忆、环境管理、分布式通信及部署等功能。Ragent 不实现具体算法,而是将用户代码分布式化,依赖 Ray 的核心概念如 Task、Actor 和 Object,利用 Ray 的编程原语实现分布式面向对象编程。Ray Data 用于批处理,例如统一清洗和解析用户文档,类似于 Spark。Agent 的服务化通过 reserve 实现。使用 Ray 后,我们获得高编程性能,并具备 Failover(故障转移)能力、分级调度和共享内存的优势。最底层是 K8S,用于资源管理和调度。
使用 Ragent 编写一个 Agent 时,首先要了解 Ragent 提供的 Agent 概念,这是一个具备 Failover 能力的基础单元,并内置消息队列和 Memory。Memory 是 Agent 内部的记忆。由于存在多种 Planning 策略,Ragent 内置了 ReAct 算法,用于重复的 think 和 act 过程。如上图的简化版代码中,通过一个 while True 循环,每次先进行 reasoning(think),获取 thought 和预期执行的 action,然后实际调用 action,持续在循环中执行。
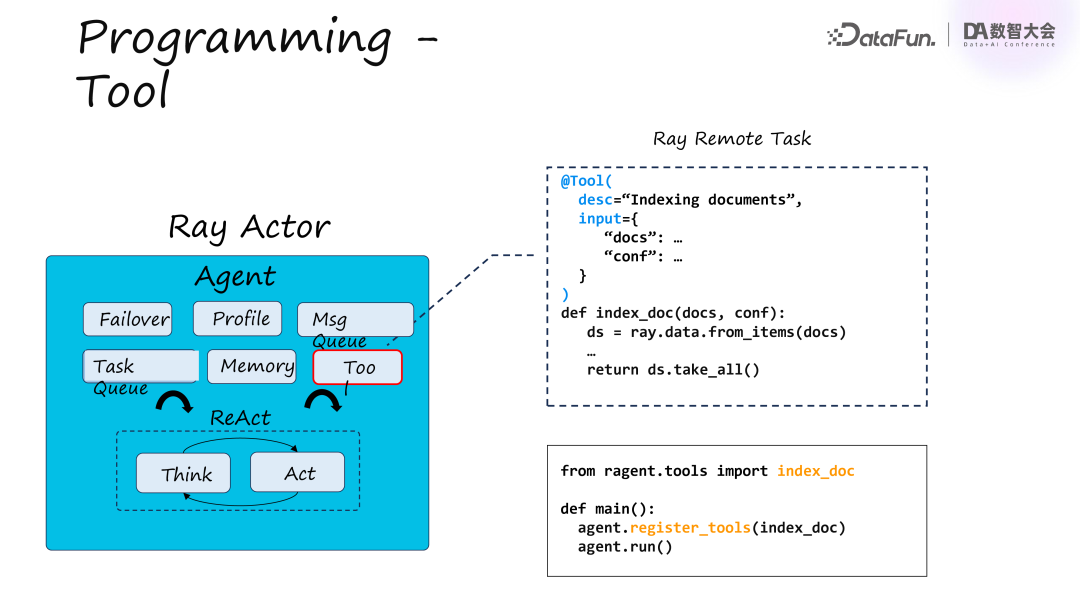
Agent 的能力主要来自于其具备的工具,如文档清洗或制定旅游攻略的能力,这使得 Agent 能够在功能上超越单纯的大模型,因此 Tool 部分至关重要。要为 Agent 定制、加载或注册一个 tool,我们可以通过注解实现。在 Python 代码中,比如对 index_doc 函数输入文档,使用 Ray Data 和 LangChain 进行处理。用 tool 注解这个函数即可将其注册到 Agent 中,使 Agent 理解。注册过程中,需要用自然语言描述其功能、输入输出及用途,类似于编程中的 doc string。注册的每个 tool 会作为 prompt 的一部分输入到大模型,使得整个 Agent 相当于一个 Ray Actor。
实现一个简易版的 RAG Agent 在我们的框架中非常简单,只需几行代码。首先,引入必要的库后,在 main 函数中初始化一个 Agent,使用内置的 ReAct 算法,并指定大模型为 Qwen。在 profile 中赋予静态资源后,为 Agent 注册多个工具,如 Apache Lucene 和 LlamaIndex。我们注册的 action 包括使用 LlamaIndex 进行文档索引,Lucene 用于 Elasticsearch,以及 DB 进行语义搜索,这些工具便可实现一个简单的 RAG。
完成初始化和注册后,Agent 便可与用户交互。用户的第一个 involve 是从 Ray 文档中学习最新功能,此时 Agent 会调用工具,将用户提供的文档索引到 DB 中作为知识的一部分。工具使用 Ray Data 实现,因此在执行阶段,Agent 将其作为 Ray Data 的作业提交,批处理输出到 DB 中每个文档的知识。
接下来,用户可对文档提问,如询问 Ray 最新版本的 Ray Data 功能,此时 Agent 会从 DB 中进行字符和语义检索,经过大模型处理后返回结果。整个过程只需几行代码即可完成一个 RAG Agent,不过这是简易版的。
接下来,我们看一个 Multi-agent 的例子。左边的图是 MetaGPT 的实现,展示了如何利用多个 Agent 构建一个软件公司。每个 Agent 承担不同职责,如产品经理、架构师、代码工程师和测试工程师。对于任务如编写贪吃蛇程序,Agent 按顺序协作。产品经理用工具生成设计图给架构师,架构师再创建技术架构图。工程师根据用户需求编写接口和实现,再交给测试进行 UT,直到程序完成。左图展示了流程,右图是用户交互,比如编写 FlappyBird,此例子被 Ragent 框架分布式化。
在该框架中,我们实现了一个 environment 组件,用于 task 追踪,包含用户任务和每个 Agent 的任务。它构建 workflow,通过 message queue 与 Agent 通信,并保存对话历史。每个 Agent 作为远程进程,由 Agent handler 管理。在代码中,我们先初始化 environment(紫色为 MetaGPT 代码,橙色为框架代码),然后初始化架构师、产品经理和 coder 等 agent,为 MetaGPT 代码进行适配。
初始化四个 Agent 后,将其加入 environment。每个 Agent 描述功能已在 profile 和 system prompt 中定义,注册后 environment 知道各 Agent 职责。目前还需手动指定 Agent 交互顺序,environment 尚不能自动选择。加入后,环境运行应用,如编写 FlappyBird 或贪吃蛇。在实践中,GPT-4 效果较好,能构建设计图和部分可运行代码,但其他模型仍难以实现复杂应用,通常在第一轮生成输出。以上是 Ragent 框架在 Multi-agent 场景的应用。
接下来是我们未来的一些工作。首先是 Agent Mesh。目前,Agent 框架众多,但缺乏统一的通信和流程标准。我们希望通过 Agent Protocol 项目,制定一个协议,整合不同框架,实现类似服务网格的通信环境。右图展示的是我们正在开发的离在线一体架构,这在非 Agent 场景下已实现。由于底层执行层都是 Ray,无论在线还是离线,技术栈相同,我们无需特别定制,能够结合使用。
在 Agent 场景中,文档处理等纯离线操作通过 Ray Data 实现,第一步可用 Ray Data pipeline 完成离线工作。对于单 Agent 或多 Agent 的二三步,可以实现服务化,每个进程用 Agent Protocol 封装,实现互通信。这在 Agent 场景中尚未完成,但在计划中。
我们还需关注底层硬件。目前不需要大量 GPU,但有厂商和开源社区希望支持更多 GPU,如 NPU。以上即是我们的工作计划。
如果大家对我们的工作感兴趣,可以加我的微信,也可以加入中文社区,在社区里面我们可以讨论更多与 Ray 大模型推理相关的工作。