今天分享的是阿里的一个工作:
Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions.
Marco-o1:面向开放的推理模型以获得开放式解决方案。

论文链接:https://arxiv.org/pdf/2411.14405
代码链接:https://github.com/AIDC-AI/Marco-o1
摘要
这篇论文介绍了一个名为 Marco-o1 的大型推理模型,该模型旨在解决开放式推理问题。与传统的大型推理模型专注于具有标准答案的学科(如数学、物理和编程)不同,Marco-o1 更注重于那些没有明确标准答案和难以量化奖励的开放性问题。为了实现这一目标,Marco-o1 采用了思维链微调、蒙特卡洛树搜索、反思机制以及针对复杂现实世界问题解决任务优化的创新推理策略。论文的核心问题是探讨 Marco-o1 模型是否能够有效地推广到更广泛的领域,在这些领域中,标准不明确且奖励难以衡量。
主要方法
Marco-o1采用三种训练集组成。分别是:
-
Open-O1 CoT Dataset (Filtered): 这是 OpenAI o1 模型使用的 CoT 数据集的过滤版本。它包含各种学科(如数学、物理、编程等)的推理问题及其对应的思维链解答。 通过使用这个数据集,Marco-o1 可以学习到 o1 模型的推理模式和策略,并将其应用到更广泛的任务中。 -
Marco-o1 CoT Dataset:这是 Marco-o1 团队专门构建的 CoT 数据集,旨在补充 Open-O1 CoT Dataset 并进一步提升模型的推理能力。该数据集包含更多开放性推理问题,例如需要创造性解决方案或缺乏明确标准的问题。 -
Marco-o1 Instruction Dataset:这是一个指令数据集,用于训练 Marco-o1 理解和执行各种指令的能力。该数据集包含各种类型的指令,例如文本生成、问答、翻译等,以增强模型的通用性和实用性。

其中开放域的CoT数据是相对比较难生成的。正是因为很多开放的场景中,我们很难量化模型的回答准确性或者步骤的准确性,所以很难复现一些数学任务、代码任务等的方法。
本文结合蒙特卡洛树搜索和大语言模型来扩展解决方案空间,并生成用于开放域推理任务的CoT数据集。下面将逐步解释文中提到的关键概念及其应用。
1. MCTS框架与推理状态
在MCTS框架中,每个节点表示一个推理状态,也就是问题解决过程中的某个具体阶段。在每个节点上,模型会基于当前的推理状态做出选择。
-
节点作为推理状态:在此背景下,MCTS中的每个节点代表模型推理过程中的一个特定状态。例如,节点可能表示一个推理步骤或者某个子任务的完成状态。
2. 动作作为LLM的输出
MCTS的每个节点可以通过不同的“动作”来迁移到另一个状态。这里的动作是由LLM生成的输出,也就是模型根据当前推理状态生成的潜在步骤或小步骤。
-
动作作为LLM输出:从每个节点开始,LLM会根据当前的推理状态生成多个可能的输出,这些输出可以看作是下一步推理的潜在选择。例如,在推理任务中,LLM可以生成多个不同的推理路径或候选答案。
3. 回合(Rollout)与奖励计算
在回合(rollout)阶段,LLM会继续进行推理,直到达到一个终态(例如,生成一个完整的答案或者解决方案)。回合的主要目标是模拟推理过程,并计算每个步骤的“奖励”来评价推理路径的质量。
-
回合阶段:LLM会从当前推理状态继续推理,生成更多令牌(token),直到达到最终的终态。这个过程类似于进行一个完整的推理链。
-
奖励计算:奖励分数(reward score)用于评价每个回合中生成的推理路径的质量。奖励分数通过计算每个令牌的置信度分数来获得,最终将所有令牌的置信度分数取平均值,作为回合的总体奖励。
4. 置信度分数与奖励分数
为了解决推理过程中的不确定性和评估不同路径的优劣,本文引入了置信度分数(confidence score)来评价每个生成的令牌的可靠性。
-
置信度分数:对于每个生成的令牌,LLM会计算其对数概率,并与前5个最可能的替代令牌的对数概率进行比较,使用softmax函数将其转化为一个归一化的置信度分数。公式如下:
其中,是第个令牌的置信度分数,是第个令牌的对数概率,是前5个最可能令牌的对数概率。这样,置信度分数反映了当前令牌相对于其他候选令牌的相对概率。
-
奖励分数:所有令牌的置信度分数被平均后,得出整个回合的奖励分数(reward score)。奖励分数的公式为:
其中,是回合中生成的令牌总数,是整个回合的奖励分数。更高的奖励分数表示该推理路径更有信心,可能更准确。
5. 引导MCTS搜索
通过计算每个回合的奖励分数,MCTS能够有效地评估并选择更有前景的推理路径。奖励分数作为一个反馈信号,指导搜索算法向更有信心和可能准确的推理链条靠近。
-
引导MCTS:MCTS利用奖励分数来评估当前路径的质量,选择最有可能的推理路径进行进一步扩展。奖励分数帮助MCTS避免在不太可靠的路径上浪费时间,使其集中于高置信度的推理链。
6. 扩展解决方案空间
结合MCTS和LLM的策略能够显著扩展解决方案空间。MCTS通过多次模拟不同的推理路径(回合),让模型能够探索一个巨大的推理空间,并根据计算出来的置信度分数选择最有可能的路径。
-
解决方案空间扩展:通过多次回合和奖励计算,模型能够生成并选择最有可能成功的推理路径,从而在开放域任务中,模型能够灵活生成各种潜在解决方案,并最终选出最优的推理过程。
除了以上MCTS的常规流程以外,Marco还引入了反思机制。这部分工作探索了通过调整粒度和引入反思机制来提高MCTS框架下推理能力的策略。主要流程包括:
动作粒度调整
-
步骤(Step)作为动作:最初使用较大的推理步骤作为MCTS搜索的动作单元,能够高效探索解决方案空间,但可能遗漏细致的推理路径。 -
迷你步骤(Mini-step)作为动作:将每个动作细分为32或64个令牌,提供更细的粒度,帮助模型探索更精细的推理路径,从而提高解决复杂问题的能力。
反思机制
-
在每次推理结束后,模型通过添加反思短语“Wait! Maybe I made some mistakes! I need to rethink from scratch.”来进行自我反思。 -
该机制促使模型重新评估推理步骤,尤其对复杂问题的解决效果显著,许多原本错误的答案通过反思得到改正。反思机制提升了模型自我修正能力,避免了外部干预。
粒度选择与效率
-
粒度的调整使模型能够在较细的层面探索推理路径,但令牌级别的搜索虽然具有最大灵活性,但计算资源消耗较大,因此在实践中仍存在挑战。
这些策略共同扩展了模型的推理空间,增强了模型解决复杂问题时的推理能力,特别是在细节推理和自我纠错方面。
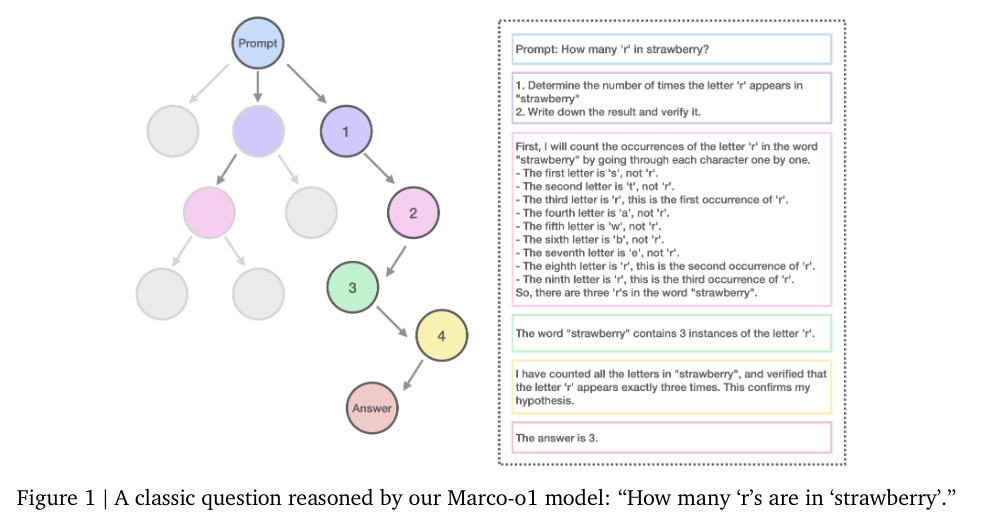
例子

这张图展示了Marco-o1-CoT左侧)和Marco-o1-MCTS (step)(右侧)在解决同一个下载时间计算问题时的表现对比。两者的主要区别在于推理粒度的不同,Marco-o1-MCTS (step)通过步骤级别的细化推理探索更广泛的解决方案空间,最终得出了正确的答案。
问题背景
Carla正在下载一个200GB的文件。通常情况下,她可以以每分钟2GB的速度下载,但下载到40%时,Windows强制安装更新,更新过程需要20分钟。更新完成后,Carla必须重新开始下载文件。我们需要计算她总共需要多少时间来下载这个文件。
左侧:Marco-o1-CoT
Marco-o1-CoT方法使用较大粒度的推理步骤来解决问题,但由于推理粒度较粗,它错过了某些重要的细节,导致推理结果不准确。
正确的推理步骤
-
下载80GB:模型正确地开始推理并计算出前80GB的下载时间,时间为40分钟(80GB ÷ 2GB/min)。 -
重启后下载剩余部分:模型认为剩余的120GB在重新启动后需要60分钟(120GB ÷ 2GB/min)。
错误的推理
-
由于缺少考虑重启过程的20分钟,模型计算的总时间为 60分钟 + 20分钟 = 80分钟,并未考虑重新下载整个200GB文件的情况。
输出
最终,Marco-o1-CoT得出的结论是总共需要120分钟来下载文件,但这个答案显然是错误的。
右侧:Marco-o1-MCTS (step)
Marco-o1-MCTS (step)方法将推理过程分解为更细的步骤,使模型能够更全面地探索解决方案空间,避免了漏掉重要细节,最终得出了正确的答案。
正确的推理步骤
-
下载80GB:模型正确地计算出下载前80GB所需时间为40分钟。 -
重启过程:模型清楚地识别到重启需要20分钟的额外时间。 -
重新下载200GB:模型进一步计算出,重启后重新下载200GB所需的时间为100分钟。
输出
通过细化推理过程,Marco-o1-MCTS (step) 得出了正确的结论:总共需要160分钟来下载整个文件。
-
Marco-o1-CoT方法采用粗粒度的推理步骤,虽然能够快速给出答案,但在细节处理上容易出现遗漏,导致错误的结果。 -
Marco-o1-MCTS (step) 方法通过步骤级别的细化推理,扩展了解决方案空间,避免遗漏重要细节,成功得出正确答案。
相关文章
